Graph2Idea:Retrieval-Augmented Scientific Idea Generation with Graph-Structured Contexts
Pith reviewed 2026-06-27 16:37 UTC · model grok-4.3
The pith
Converting retrieved papers into a target-centered knowledge graph produces more novel, high-quality and feasible research ideas than flat-text retrieval.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
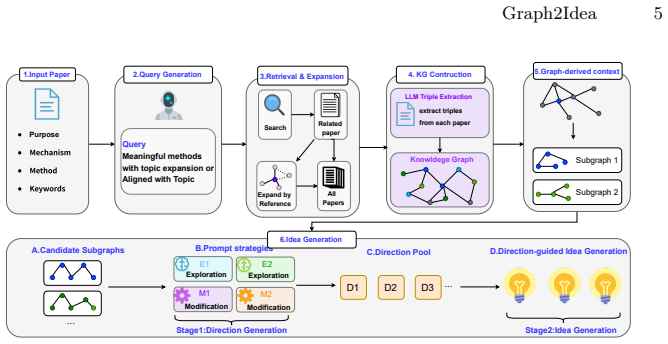
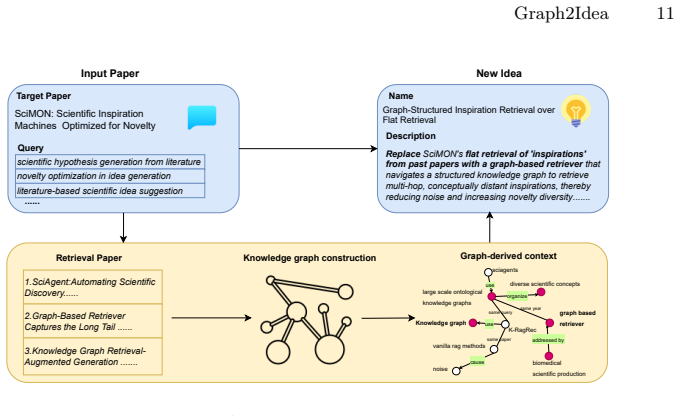
Graph2Idea retrieves papers according to the input topic, transforms them into structured knowledge triples, and dynamically constructs a target-centered knowledge graph to make literature relations explicit. It then extracts compact graph-derived contexts that retain target-relevant relational evidence while reducing noisy textual input. Based on these contexts, a two-stage generation process first identifies promising research directions and then guides the LLM to synthesize candidate ideas from graph-grounded evidence. Experiments on a scientific idea generation benchmark show that Graph2Idea outperforms representative baselines under the automatic evaluation protocol.
What carries the argument
The target-centered knowledge graph, which renders cross-paper relations explicit and supplies compact contexts for the two-stage generation process.
If this is right
- Ideas emerge from traceable recombination of prior findings rather than opaque text blending.
- Compact relational contexts reduce the volume of input while preserving the links needed for synthesis.
- The two-stage process separates direction selection from idea formulation, allowing each step to stay grounded in the graph.
- The framework applies to any research topic where papers can be turned into triples.
- Explicit graphs make it possible to trace which relations contributed to each generated idea.
Where Pith is reading between the lines
- The same graph construction could be applied to tasks such as hypothesis generation or literature summarization.
- If triple extraction quality varies across scientific domains, the performance gain may shrink in fields with less standardized terminology.
- Adding citation edges or temporal ordering to the graph might further strengthen the relational signal.
- Human judges could be asked to rate traceability of the generated ideas back to specific graph paths.
- keywords:[
- idea generation
- knowledge graph
- retrieval-augmented generation
Load-bearing premise
Converting papers into knowledge triples and building the target-centered graph captures the most relevant relations without the extraction step itself introducing bias or dropping important context.
What would settle it
An experiment that generates ideas from the same retrieved papers using only their flat abstracts or summaries and obtains equal or higher automatic scores on novelty, quality and feasibility would falsify the central claim.
Figures
read the original abstract
Generating novel, feasible, and high-quality research ideas is an important yet challenging task in scientific discovery. Recent Large Language Model (LLM)-based methods often ground idea generation with retrieved literature, but the retrieved evidence is usually provided as flat text, such as titles, abstracts, or summaries. Such flat contexts may contain redundant or weakly relevant information, while making cross-paper relations among problems, methods, mechanisms, and findings difficult to identify and trace. To address this challenge, we propose Graph2Idea, a knowledge graph-guided framework for retrieval-augmented scientific idea generation.Graph2Idea first retrieves papers according to the input topic, transforms them into structured knowledge triples, and dynamically constructs a target-centered knowledge graph to make literature relations explicit. It then extracts compact graph-derived contexts that retain target-relevant relational evidence while reducing noisy textual input. Based on these contexts, a two-stage generation process first identifies promising research directions and then guides the LLM to synthesize candidate ideas from graph-grounded evidence. Experiments on a scientific idea generation benchmark show that Graph2Idea outperforms representative baselines under the automatic evaluation protocol. Compared with the strongest baseline scores, it improves Novelty from 0.45 to 0.52, Quality from 0.24 to 0.29, and Feasibility from 0.22 to 0.28. These results suggest that graph-structured evidence helps LLMs generate research ideas through more explicit, compact, and traceable recombination of prior scientific knowledge.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Graph2Idea, a retrieval-augmented framework for scientific idea generation. It retrieves relevant papers on an input topic, converts them into knowledge triples, dynamically builds a target-centered knowledge graph to expose cross-paper relations, extracts compact graph-derived contexts, and employs a two-stage LLM process (identifying promising directions then synthesizing ideas) to produce novel, high-quality, feasible research ideas. Experiments on a scientific idea generation benchmark report that Graph2Idea outperforms baselines, raising automatic scores for Novelty (0.45→0.52), Quality (0.24→0.29), and Feasibility (0.22→0.28).
Significance. If the empirical gains are robust, the work demonstrates that explicit graph-structured contexts can improve LLM-based recombination of scientific knowledge over flat-text retrieval, offering a concrete mechanism for reducing noise and making relations traceable. The two-stage generation process and dynamic graph construction are positive design choices that could generalize to other retrieval-augmented scientific tasks.
major comments (2)
- [Experiments] Experiments section: the central outperformance claim rests on automatic metric gains (Novelty 0.45→0.52 etc.), yet the evaluation protocol, LLM-as-judge prompts, embedding similarity details, and any correlation to human ratings are not reported. Without these, it is impossible to determine whether the deltas arise from the graph contexts or from surface features of the generated output.
- [Method] Method section on graph construction: the assumption that paper-to-triple extraction plus target-centered graph assembly preserves the most relevant cross-paper relations while eliminating noise lacks supporting ablations or sensitivity analysis. The reported improvements could be driven by the extraction heuristics rather than the graph structure itself.
minor comments (2)
- [Abstract] The abstract and introduction use slightly inconsistent phrasing for the framework name and components; standardize terminology across the paper.
- [Experiments] Baseline descriptions in the experiments could include more detail on how flat-text contexts were constructed for fair comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to incorporate additional details and analyses.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the central outperformance claim rests on automatic metric gains (Novelty 0.45→0.52 etc.), yet the evaluation protocol, LLM-as-judge prompts, embedding similarity details, and any correlation to human ratings are not reported. Without these, it is impossible to determine whether the deltas arise from the graph contexts or from surface features of the generated output.
Authors: We agree that the evaluation details were insufficiently reported, which hinders assessment of whether gains derive from the graph contexts. The original submission described the overall automatic evaluation protocol and benchmark but omitted the precise LLM-as-judge prompts, embedding model and similarity computation details, and any human correlation analysis. In the revised manuscript we will expand the Experiments section with the full protocol, exact judge prompts, embedding specifications, and any available correlation results to clarify the source of the reported improvements. revision: yes
-
Referee: [Method] Method section on graph construction: the assumption that paper-to-triple extraction plus target-centered graph assembly preserves the most relevant cross-paper relations while eliminating noise lacks supporting ablations or sensitivity analysis. The reported improvements could be driven by the extraction heuristics rather than the graph structure itself.
Authors: We acknowledge that dedicated ablations would more directly isolate the contribution of the target-centered graph assembly from the upstream triple extraction heuristics. While the existing comparisons against flat-text baselines provide indirect support for structured contexts, we did not include explicit variants that hold extraction fixed and vary only the graph assembly step. We will add such sensitivity analyses and ablations to the revised manuscript to strengthen the evidence that the relational graph structure itself drives the gains. revision: yes
Circularity Check
No significant circularity; empirical claims rest on independent benchmark evaluation
full rationale
The paper describes a retrieval-augmented framework that converts papers to triples, builds a target-centered graph, extracts contexts, and performs two-stage LLM generation. Its central claim is empirical outperformance (Novelty 0.45→0.52 etc.) on an external scientific idea generation benchmark under an automatic protocol. No equations, fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations appear in the provided text. The evaluation metrics and benchmark are external to the method's internal definitions, so the reported gains do not reduce to the inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Papers can be accurately transformed into structured knowledge triples that capture relations among problems, methods, mechanisms, and findings without substantial loss or distortion.
Reference graph
Works this paper leans on
-
[1]
Aksitov, R., Miryoosefi, S., Li, Z., Li, D., Babayan, S., Kopparapu, K., Fisher, Z., Guo, R., Prakash, S., Srinivasan, P., Zaheer, M., Yu, F., Kumar, S.: Rest meets react: Self-improvement for multi-step reasoning llm agent (2023),https: //arxiv.org/abs/2312.10003
arXiv 2023
-
[2]
Baek, J., Jauhar, S.K., Cucerzan, S., Hwang, S.J.: ResearchAgent: Iterative Research Idea Generation over Scientific Literature with Large Language Models. In: Chiruzzo, L., Ritter, A., Wang, L. (eds.) Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Vo...
-
[3]
In: Proceedings of the 20th International Conference on Scientometrics & Informetrics (2025)
Chen, S., Zhang, C.: Enhancing Research Idea Generation through Combinatorial Innovation and Multi-Agent Iterative Search Strategies. In: Proceedings of the 20th International Conference on Scientometrics & Informetrics (2025)
2025
-
[4]
Cheng, R., Liu, J., Zheng, Y., Ni, F., Du, J., Mao, H., Zhang, F., Wang, B., Hao, J.: Dualrag: A dual-process approach to integrate reasoning and retrieval for multi-hop question answering (2025),https://arxiv.org/abs/2504.18243
arXiv 2025
-
[5]
Technical report, DeepSeek-AI (2026), https://huggingface.co/ deepseek-ai/DeepSeek-V4-Pro/blob/main/DeepSeek_V4.pdf
DeepSeek-AI: DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence. Technical report, DeepSeek-AI (2026), https://huggingface.co/ deepseek-ai/DeepSeek-V4-Pro/blob/main/DeepSeek_V4.pdf
2026
-
[6]
Fire, M., Guestrin, C.: Over-optimization of academic publishing metrics: Observing goodhart’s law in action (2018),https://arxiv.org/abs/1809.07841 Graph2Idea 13
Pith/arXiv arXiv 2018
-
[7]
Gao, X., Zhang, Z., Liu, T., Fu, Y.: Goai: Enhancing ai students’ learning paths and idea generation via graph of ai ideas (2025),https://arxiv.org/abs/2503.08549
arXiv 2025
-
[8]
SSRN Electronic Journal (2023),https://api.semanticscholar.org/CorpusID:260467886
Girotra, K., Meincke, L., Terwiesch, C., Ulrich, K.T.: Ideas are dimes a dozen: Large language models for idea generation in innovation. SSRN Electronic Journal (2023),https://api.semanticscholar.org/CorpusID:260467886
2023
-
[9]
Guo, S., Shariatmadari, A.H., Xiong, G., Huang, A., Xie, E., Bekiranov, S., Zhang, A.: Ideabench: Benchmarking large language models for research idea generation (2024),https://arxiv.org/abs/2411.02429
arXiv 2024
-
[10]
Knowledgegraphs.ACM Computing Surveys, 54(4):1–37, 2021
Hogan, A., Blomqvist, E., Cochez, M., D’amato, C., Melo, G.D., Gutierrez, C., Kirrane, S., Gayo, J.E.L., Navigli, R., Neumaier, S., Ngomo, A.C.N., Polleres, A., Rashid, S.M., Rula, A., Schmelzeisen, L., Sequeda, J., Staab, S., Zimmermann, A.: Knowledge graphs. ACM Comput. Surv.54(4) (Jul 2021).https://doi.org/10. 1145/3447772,https://doi.org/10.1145/3447772
-
[11]
Hope, T., Downey, D., Etzioni, O., Weld, D.S., Horvitz, E.: A computational inflection for scientific discovery (2023),https://arxiv.org/abs/2205.02007
arXiv 2023
-
[12]
Design Initiative for a 10 TeV pCM Wakefield Collider,
Hu, X., Fu, H., Wang, J., Wang, Y., Li, Z., Xu, R., Lu, Y., Jin, Y., Pan, L., Lan, Z.: Nova: An Iterative Planning and Search Approach to Enhance Novelty and Diversity of LLM Generated Ideas (Oct 2024).https://doi.org/10.48550/arXiv. 2410.14255,http://arxiv.org/abs/2410.14255, arXiv:2410.14255 [cs]
work page internal anchor Pith review doi:10.48550/arxiv 2024
-
[13]
Sage Publications
Karim;, T.X.M.: A knowledge recombination perspective of innovation: Review and new research directions. Sage Publications
-
[14]
Kumar, S., Ghosal, T., Goyal, V., Ekbal, A.: Can large language models unlock novel scientific research ideas? (2025),https://arxiv.org/abs/2409.06185
arXiv 2025
-
[15]
Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Küttler, H., Lewis, M., tau Yih, W., Rocktäschel, T., Riedel, S., Kiela, D.: Retrieval-augmented generation for knowledge-intensive nlp tasks (2021),https://arxiv.org/abs/2005. 11401
2021
-
[16]
arXiv preprint arXiv:2410.13185 , year =
Li, L., Xu, W., Guo, J., Zhao, R., Li, X., Yuan, Y., Zhang, B., Jiang, Y., Xin, Y., Dang, R., Zhao, D., Rong, Y., Feng, T., Bing, L.: Chain of Ideas: Revolutionizing Research Via Novel Idea Development with LLM Agents (Oct 2024). https://doi.org/10.48550/arXiv.2410.13185, http://arxiv.org/abs/ 2410.13185, arXiv:2410.13185 [cs]
-
[17]
The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery
Lu, C., Lu, C., Lange, R.T., Foerster, J., Clune, J., Ha, D.: The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery (Sep 2024). https://doi.org/10.48550/arXiv.2408.06292, http://arxiv.org/abs/ 2408.06292, arXiv:2408.06292 [cs]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2408.06292 2024
-
[18]
Luo, Z., Yang, Z., Xu, Z., Yang, W., Du, X.: Llm4sr: A survey on large language models for scientific research (2025),https://arxiv.org/abs/2501.04306
arXiv 2025
-
[19]
In: Proceedings of the 41st International Conference on Machine Learning
Ma, P., Wang, T.H., Guo, M., Sun, Z., Tenenbaum, J.B., Rus, D., Gan, C., Matusik, W.: Llm and simulation as bilevel optimizers: a new paradigm to advance physical scientific discovery. In: Proceedings of the 41st International Conference on Machine Learning. ICML’24, JMLR.org (2024)
2024
-
[20]
Meincke, L., Mollick, E.R., Terwiesch, C.: Prompting Diverse Ideas: Increasing AI Idea Variance (Jan 2024).https://doi.org/10.48550/arXiv.2402.01727, http: //arxiv.org/abs/2402.01727, arXiv:2402.01727 [cs]
-
[21]
OpenAI, Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F.L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., Avila, R., Babuschkin, I., Balaji, S., Balcom, V., Baltescu, P., Bao, H., Bavarian, M., Belgum, J., Bello, I., Berdine, J., Bernadett-Shapiro, G., Berner, C., Bogdonoff, L., Boiko, O., Boyd, M., Brakman, A.L., Brockman, ...
Pith/arXiv arXiv 2024
-
[22]
Peng, B., Zhu, Y., Liu, Y., Bo, X., Shi, H., Hong, C., Zhang, Y., Tang, S.: Graph retrieval-augmented generation: A survey (2024),https://arxiv.org/abs/2408. 08921
2024
-
[23]
URL https: //doi.org/10.1038/s41586-023-06924-6
Romera-Paredes, B., Barekatain, M., Novikov, A., Balog, M., Kumar, M.P., Dupont, E., Ruiz, F.J.R., Ellenberg, J.S., Wang, P., Fawzi, O., Kohli, P., Fawzi, A.: Math- ematical discoveries from program search with large language models. Nature 625(7995), 468–475 (Jan 2024).https://doi.org/10.1038/s41586-023-06924-6, https://www.nature.com/articles/s41586-023-06924-6
-
[24]
Shahhosseini, F., Marioriyad, A., Momen, A., Baghshah, M.S., Rohban, M.H., Javanmard, S.H.: Large language models for scientific idea generation: A creativity- centered survey (2026),https://arxiv.org/abs/2511.07448
arXiv 2026
-
[25]
In: The Thirteenth International Conference on Learning Representations (2025),https://openreview.net/forum? id=M23dTGWCZy
Si, C., Yang, D., Hashimoto, T.: Can LLMs generate novel research ideas? a large- scale human study with 100+ NLP researchers. In: The Thirteenth International Conference on Learning Representations (2025),https://openreview.net/forum? id=M23dTGWCZy
2025
-
[26]
Sternlicht, N., Hope, T.: Chimera: A knowledge base of scientific idea recombinations for research analysis and ideation (2026),https://arxiv.org/abs/2505.20779
Pith/arXiv arXiv 2026
-
[27]
In: Che, W., Nabende, J., Shutova, E., Pilehvar, M.T
Su, H., Chen, R., Tang, S., Yin, Z., Zheng, X., Li, J., Qi, B., Wu, Q., Li, H., Ouyang, W., Torr, P., Zhou, B., Dong, N.: Many Heads Are Better Than One: Improved Scientific Idea Generation by A LLM-Based Multi-Agent System. In: Che, W., Nabende, J., Shutova, E., Pilehvar, M.T. (eds.) Proceedings of the 63rd Annual Meeting of the Association for Computati...
2025
-
[28]
Tang, J., Xia, L., Li, Z., Huang, C.: Ai-researcher: Autonomous scientific innovation (2025),https://arxiv.org/abs/2505.18705
arXiv 2025
-
[29]
Trivedi, H., Balasubramanian, N., Khot, T., Sabharwal, A.: Interleaving retrieval with chain-of-thought reasoning for knowledge-intensive multi-step questions (2023), https://arxiv.org/abs/2212.10509
Pith/arXiv arXiv 2023
-
[30]
Nature 620, 47–60 (2023),https://api.semanticscholar.org/CorpusID:260384616
Wang, H., Fu, T., Du, Y., Gao, W., Huang, K., Liu, Z., Chandak, P., Liu, S., Katwyk, P.V., Deac, A., Anandkumar, A., Bergen, K.J., Gomes, C.P., Ho, S., Kohli, P., Lasenby, J., Leskovec, J., Liu, T.Y., Manrai, A.K., Marks, D.S., Ramsundar, B., Song, L., Sun, J., Tang, J., Velickovic, P., Welling, M., Zhang, L., Coley, C.W., Bengio, Y., Zitnik, M.: Scientif...
2023
-
[31]
Wang, W., Wei, F., Dong, L., Bao, H., Yang, N., Zhou, M.: Minilm: Deep self- attention distillation for task-agnostic compression of pre-trained transformers (2020),https://arxiv.org/abs/2002.10957
arXiv 2020
-
[32]
In: Taniguchi, T., Leung, C.S.A., Kozuno, T., Yoshimoto, J., Mahmud, M., Doborjeh, M., Doya, K
Wang, Z., Peng, B., Tu, H., Li, X.: Entity similarity rag: Enhancing llm answers with precise knowledge graph retrieval. In: Taniguchi, T., Leung, C.S.A., Kozuno, T., Yoshimoto, J., Mahmud, M., Doborjeh, M., Doya, K. (eds.) Neural Information Processing. pp. 229–243. Springer Nature Singapore, Singapore (2026)
2026
-
[33]
Wei, J., Wang, X., Schuurmans, D., Bosma, M., Ichter, B., Xia, F., Chi, E., Le, Q., Zhou, D.: Chain-of-thought prompting elicits reasoning in large language models (2023),https://arxiv.org/abs/2201.11903
Pith/arXiv arXiv 2023
-
[34]
Yao, S., Yu, D., Zhao, J., Shafran, I., Griffiths, T.L., Cao, Y., Narasimhan, K.: Tree of thoughts: Deliberate problem solving with large language models (2023), https://arxiv.org/abs/2305.10601
Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.