Explicit Representation Alignment for Multimodal Sentiment Analysis
Pith reviewed 2026-06-27 16:54 UTC · model grok-4.3
The pith
Converting images to text descriptions aligns modality representations and outperforms complex fusion in multimodal sentiment analysis.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
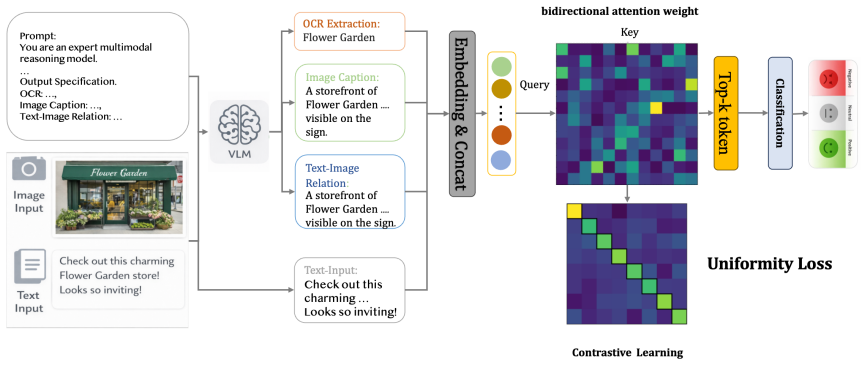
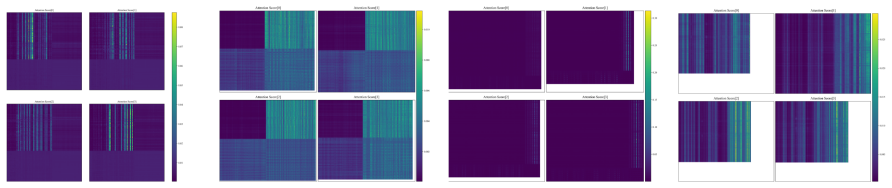
Representation misalignment between independently pretrained modality encoders is the primary bottleneck limiting multimodal affective analysis. Projecting visual content into a shared linguistic space via VLM-generated textual descriptions enables effective text-centric reasoning, and combining this with semantic token selection plus batch-level uniformity regularization produces more dispersed, stable features that mitigate noise and yield state-of-the-art performance.
What carries the argument
VLM-based projection of visual content into structured textual descriptions that creates a shared linguistic space, combined with semantic token selection and batch-level uniformity regularization to stabilize the global feature space.
If this is right
- Alignment before fusion is more important than fusion complexity for effective multimodal learning.
- Text-centric models that project all modalities into language space can achieve state-of-the-art results on sentiment and emotion tasks.
- The method outperforms both strong unimodal and multimodal baselines across multiple benchmarks.
- Representation alignment plays a critical role in multimodal affective learning.
Where Pith is reading between the lines
- The same pre-fusion alignment strategy could be tested on other multimodal tasks such as visual question answering where modality mismatch is also common.
- Improvements in future vision-language models would directly raise the ceiling of this approach without changes to the fusion architecture.
- The batch-level uniformity objective might transfer to other multimodal settings to encourage more stable feature spaces even without VLM descriptions.
- Future model design should prioritize explicit pre-fusion alignment steps over increasingly elaborate fusion modules.
Load-bearing premise
That VLM-generated textual descriptions of visual content are accurate enough for sentiment tasks and that the token selection plus uniformity regularization reliably removes any introduced noise.
What would settle it
Replace the VLM-generated descriptions with random or deliberately inaccurate text while keeping the rest of the pipeline fixed and measure whether the performance advantage over strong baselines disappears on the same benchmarks.
Figures

read the original abstract
Multimodal affective analysis aims to understand human sentiment and emotion by jointly modeling heterogeneous modalities such as text and images. However, multimodal models often fail to consistently outperform strong text-only baselines, with performance varying significantly across fusion strategies. In this work, we identify representation misalignment between independently pretrained modality encoders as a key bottleneck for effective multimodal learning, and show through controlled experiments that alignment prior to fusion is often more important than fusion complexity. To address this issue, we propose a unified multimodal affective analysis framework that leverages vision-language models (VLMs) to convert visual content into structured textual descriptions, projecting heterogeneous modalities into a shared linguistic space and enabling interpretable text-centric reasoning. To further improve robustness, we introduce a hybrid learning strategy that combines semantic token selection with a batch-level uniformity regularization objective, encouraging a more dispersed and stable global feature space while mitigating noise introduced by VLM-generated descriptions. Experiments on multiple multimodal sentiment and emotion benchmarks show that our method consistently outperforms strong unimodal and multimodal baselines, achieving state-of-the-art performance. Our analysis further highlights the critical role of representation alignment in multimodal affective learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that representation misalignment between independently pretrained modality encoders is a key bottleneck for effective multimodal affective analysis. It argues, via controlled experiments, that alignment prior to fusion matters more than fusion complexity. The proposed framework converts visual content to structured textual descriptions via VLMs to enable text-centric reasoning in a shared linguistic space, augmented by semantic token selection and batch-level uniformity regularization to handle noise. Experiments on multiple sentiment and emotion benchmarks are said to yield consistent outperformance of strong baselines and state-of-the-art results.
Significance. If the causal claims hold, the work would shift emphasis in multimodal affective computing toward explicit pre-fusion alignment rather than ever-more-complex fusion modules, while the VLM-based text projection could improve interpretability. Reproducible code or parameter-free derivations are not mentioned.
major comments (2)
- [Abstract] Abstract: the central claim that representation misalignment is the key bottleneck and that the VLM projection plus uniformity regularization reduces it is supported only by downstream accuracy gains; no pre-/post-alignment diagnostics (cosine similarity, CCA, or CKA between modality embeddings on matched samples) are reported, so performance improvements could arise from the text-centric pipeline or generic regularization instead.
- [Abstract] Abstract / Experiments: the controlled experiments purporting to show that alignment prior to fusion is more important than fusion complexity supply no details on how fusion complexity was varied, what controls were used, or any statistical tests; without these, the comparative conclusion cannot be verified.
minor comments (1)
- [Abstract] Abstract: dataset names, sizes, and any ablation or statistical significance results are omitted, hindering assessment of the SOTA claims.
Simulated Author's Rebuttal
We thank the referee for their insightful comments, which help us clarify and strengthen the presentation of our work on explicit representation alignment for multimodal sentiment analysis. We respond to the major comments point-by-point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that representation misalignment is the key bottleneck and that the VLM projection plus uniformity regularization reduces it is supported only by downstream accuracy gains; no pre-/post-alignment diagnostics (cosine similarity, CCA, or CKA between modality embeddings on matched samples) are reported, so performance improvements could arise from the text-centric pipeline or generic regularization instead.
Authors: We acknowledge that the manuscript relies on downstream task performance to support the alignment claims without reporting direct pre- and post-alignment metrics such as cosine similarity or CKA. While the controlled experiments and consistent SOTA results across benchmarks provide indirect evidence, we agree that explicit diagnostics would more directly validate the misalignment reduction. In the revised manuscript, we will add these analyses, including cosine similarity and CKA scores computed on matched samples before and after the VLM projection and uniformity regularization. revision: yes
-
Referee: [Abstract] Abstract / Experiments: the controlled experiments purporting to show that alignment prior to fusion is more important than fusion complexity supply no details on how fusion complexity was varied, what controls were used, or any statistical tests; without these, the comparative conclusion cannot be verified.
Authors: We agree that the current manuscript lacks sufficient detail on the controlled experiments comparing alignment to fusion complexity. To address this, the revision will include a dedicated section or appendix describing the fusion variants tested (e.g., early vs. late fusion, simple MLP vs. transformer-based fusion with increasing depth), the exact controls for isolating alignment effects, and results with statistical significance testing (e.g., McNemar's test or bootstrap confidence intervals). This will allow verification of the conclusion that pre-fusion alignment is more impactful. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper advances an empirical framework for multimodal sentiment analysis by proposing VLM-based projection into text space plus uniformity regularization, then evaluates it via accuracy on standard benchmarks. No equations, derivations, or fitted parameters are described that could reduce to self-definition or rename inputs as predictions. Claims about misalignment as a bottleneck rest on controlled experiments whose outcomes are externally falsifiable on held-out datasets rather than on any self-citation chain or ansatz smuggled via prior work. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
The common neural bases between sexual de- sire and love: a multilevel kernel density fmri analy- sis.The journal of sexual medicine, 9(4):1048–1054. Santiago Castro, Devamanyu Hazarika, Verónica Pérez- Rosas, Roger Zimmermann, Rada Mihalcea, and Soujanya Poria. 2019. Towards multimodal sarcasm detection (an _obviously_ perfect paper).arXiv preprint arXiv...
Pith/arXiv arXiv 2019
-
[2]
InPacific-Asia conference on knowledge discovery and data mining, pages 785–
Fusion-extraction network for multimodal 9 sentiment analysis. InPacific-Asia conference on knowledge discovery and data mining, pages 785–
-
[3]
Dhruv Khattar, Jaipal Singh Goud, Manish Gupta, and Vasudeva Varma
Springer. Dhruv Khattar, Jaipal Singh Goud, Manish Gupta, and Vasudeva Varma. 2019. Mvae: Multimodal varia- tional autoencoder for fake news detection. InThe world wide web conference, pages 2915–2921. Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, and 1 others. 2024. Llava- onevision:...
Pith/arXiv arXiv 2019
-
[4]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, and 1 others
The desire model: Cross-modal emotion anal- ysis and expression for robots.Information Process- ing Society of Japan, 5(4). Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, and 1 others
-
[5]
Qiang Lu, Xia Sun, Yunfei Long, Xiaodi Zhao, Wang Zou, Jun Feng, and Xuxin Wang
Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437. Qiang Lu, Xia Sun, Yunfei Long, Xiaodi Zhao, Wang Zou, Jun Feng, and Xuxin Wang. 2025a. Multimodal dual perception fusion framework for multimodal affective analysis.Information Fusion, 115:102747. Qiang Lu, Xia Sun, Yunfei Long, Xiaodi Zhao, Wang Zou, Jun Feng, and Xuxin Wang. 2025b. Multimoda...
Pith/arXiv arXiv 2019
-
[6]
Kimi-vl technical report.arXiv preprint arXiv:2504.07491. Qwen Team. 2025. Qwen2.5-vl technical report.arXiv preprint arXiv:2502.13923. Yuan Tian, Nan Xu, Ruike Zhang, and Wenji Mao
Pith/arXiv arXiv 2025
-
[7]
InProceedings of the 61st Annual Meeting of the Association for Compu- tational Linguistics (Volume 1: Long Papers), pages 2468–2480
Dynamic routing transformer network for mul- timodal sarcasm detection. InProceedings of the 61st Annual Meeting of the Association for Compu- tational Linguistics (Volume 1: Long Papers), pages 2468–2480. Baode Wang, Biao Wu, Weizhen Li, Meng Fang, Zuming Huang, Jun Huang, Haozhe Wang, Yan- jie Liang, Ling Chen, Wei Chu, and Yuan Qi
-
[8]
Changsong Wen, Guoli Jia, and Jufeng Yang
Infinity parser: Layout aware reinforcement learning for scanned document parsing.Preprint, arXiv:2506.03197. Changsong Wen, Guoli Jia, and Jufeng Yang. 2023. Dip: Dual incongruity perceiving network for sar- casm detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recog- nition, pages 2540–2550. 10 Biao Wu, Meng Fang, Ling ...
arXiv 2023
-
[9]
Automotive-env: Benchmarking multimodal agents in vehicle interface systems.Preprint, arXiv:2509.21143. An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, and 1 others
-
[10]
Kaicheng Yang, Hua Xu, and Kai Gao
Qwen3 technical report.arXiv preprint arXiv:2505.09388. Kaicheng Yang, Hua Xu, and Kai Gao. 2020. Cm-bert: Cross-modal bert for text-audio sentiment analysis. InProceedings of the 28th ACM international con- ference on multimedia, pages 521–528. AmirAli Bagher Zadeh, Paul Pu Liang, Soujanya Poria, Erik Cambria, and Louis-Philippe Morency. 2018. Multimodal...
Pith/arXiv arXiv 2020
-
[11]
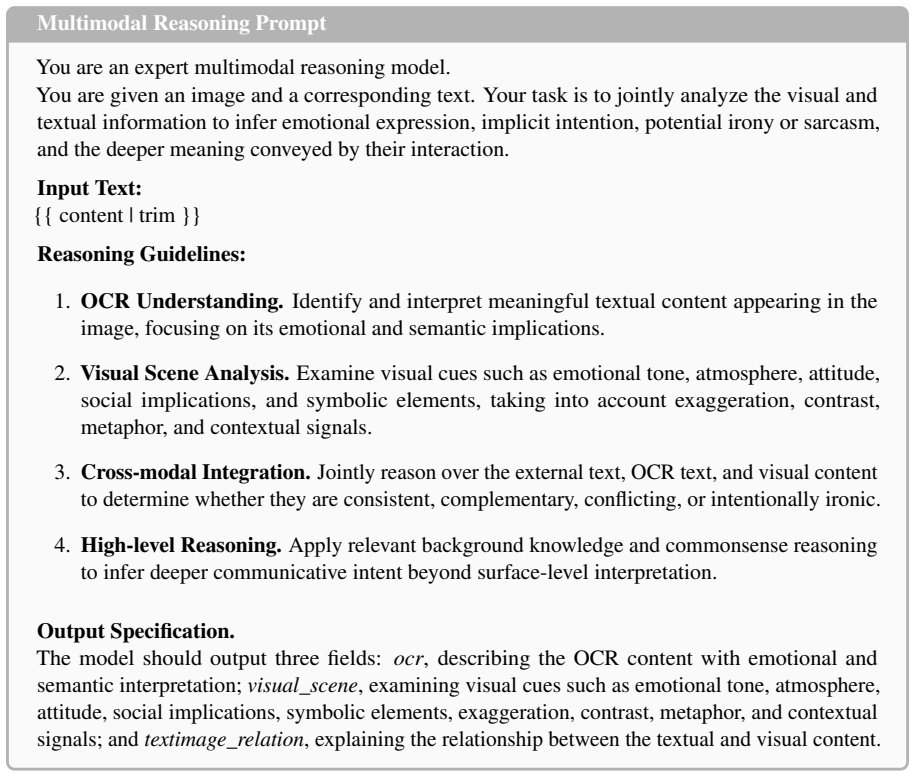
OCR Understanding.Identify and interpret meaningful textual content appearing in the image, focusing on its emotional and semantic implications
-
[12]
Visual Scene Analysis.Examine visual cues such as emotional tone, atmosphere, attitude, social implications, and symbolic elements, taking into account exaggeration, contrast, metaphor, and contextual signals
-
[13]
Cross-modal Integration.Jointly reason over the external text, OCR text, and visual content to determine whether they are consistent, complementary, conflicting, or intentionally ironic
-
[14]
Output Specification
High-level Reasoning.Apply relevant background knowledge and commonsense reasoning to infer deeper communicative intent beyond surface-level interpretation. Output Specification. The model should output three fields:ocr, describing the OCR content with emotional and semantic interpretation;visual_scene, examining visual cues such as emotional tone, atmosp...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.