Self-supervised Learning Matters: A Simple Ensemble Solution for Micro-Gesture Recognition
Pith reviewed 2026-06-27 17:10 UTC · model grok-4.3
The pith
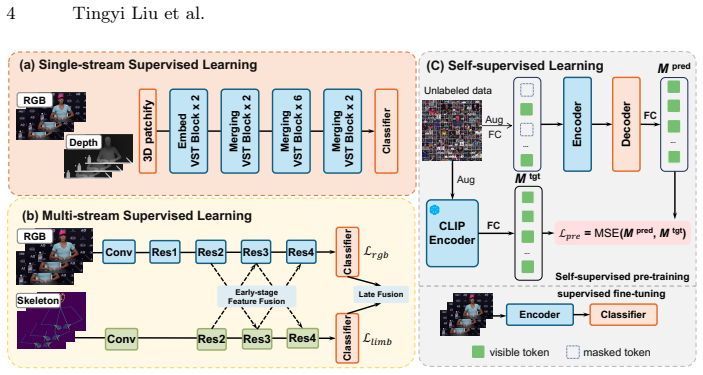
A self-supervised RGB model pretrained on 120K unlabeled clips via masked video modeling raises ensemble top-1 accuracy to 74.419% on the iMiGUE micro-gesture test set.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Pretraining an RGB model on 120K unlabeled clips via masked video modeling and fine-tuning it on iMiGUE produces a 69.224% top-1 accuracy that, when ensembled with prior supervised multi-stream models, yields 74.419% top-1 accuracy and sets a new state of the art 1.206 points above the previous record.
What carries the argument
The self-supervised RGB model pretrained via masked video modeling, used as an additional complementary branch in the multimodal ensemble.
If this is right
- Self-supervised pretraining on unlabeled in-domain video can be added as a low-cost complementary stream without redesigning existing supervised pipelines.
- The 1.206-point gain shows that masked video modeling captures gesture-relevant structure that supervised training on the smaller labeled set misses.
- Ablation studies on ensemble weighting confirm that the self-supervised branch contributes measurably rather than acting as noise.
- The same pretraining recipe can be applied to other fine-grained video tasks that have abundant unlabeled footage but limited labeled examples.
Where Pith is reading between the lines
- If the pretraining corpus were expanded beyond 120K clips or drawn from a broader distribution of gestures, the single-model accuracy and the final ensemble margin could increase further.
- The same masked-video pretraining step might transfer to related tasks such as subtle facial-expression recognition or micro-expression detection that also suffer from label scarcity.
- Because the method requires only standard video encoders and no new architecture, it can be inserted into any existing multi-stream gesture system with minimal engineering cost.
Load-bearing premise
The features obtained from masked video modeling on unlabeled in-domain clips remain complementary to the features already captured by the supervised multi-stream models.
What would settle it
An ablation that replaces the self-supervised branch with either a randomly initialized RGB model or one pretrained on unrelated video data and measures whether the ensemble accuracy falls back to or below the prior state of the art.
Figures
read the original abstract
In this paper, we present XInsight Lab's solution to the micro-gesture classification track of the 4th MiGA Challenge at IJCAI 2026, in which our solution ranked first and achieved a new state-of-the-art result. We propose a multimodal ensemble framework that integrates a self-supervised RGB-based model with supervised multi-stream models from previous solutions. The self-supervised RGB model is pretrained on 120K unlabeled clips via masked video modeling and then fine-tuned on iMiGUE. This simple yet effective RGB baseline achieves 69.224% top-1 accuracy on the iMiGUE test set, demonstrating the benefit of learning transferable representations from unlabeled in-domain videos. By incorporating this model as a complementary branch, the final ensemble reaches 74.419% top-1 accuracy, surpassing the previous state of the art by 1.206 percentage points. Experimental results on iMiGUE, including ablation studies on the ensemble strategy, validate the effectiveness of self-supervised RGB representation learning for micro-gesture recognition.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents XInsight Lab's winning entry to the micro-gesture classification track of the 4th MiGA Challenge. It describes a multimodal ensemble that adds a self-supervised RGB branch—pretrained via masked video modeling on 120K unlabeled in-domain clips and fine-tuned on iMiGUE—to prior supervised multi-stream models. The SSL-only RGB model reaches 69.224% top-1 accuracy; the full ensemble reaches 74.419%, exceeding the previous state of the art by 1.206 percentage points. Ablation studies on ensemble strategy are cited as validation.
Significance. If the reported gain is attributable to the self-supervised branch rather than to the addition of an extra RGB stream, the work supplies concrete evidence that masked-video pretraining on unlabeled in-domain data can improve ensemble performance on fine-grained micro-gesture tasks. The numbers are obtained on an independent challenge test set and the approach is simple enough to be reproducible.
major comments (1)
- [Abstract] Abstract: the headline claim that the SSL RGB model supplies complementary signals (and is therefore responsible for the +1.206 pp gain) is not supported by any reported number for the supervised-only ensemble accuracy or by any diversity metric (prediction disagreement, feature correlation) between the SSL branch and the other streams. The abstract states that ablation studies on ensemble strategy exist, yet the provided text contains none of the required quantities.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract and the recommendation for major revision. We address the point below and will update the manuscript to strengthen the supporting evidence for our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claim that the SSL RGB model supplies complementary signals (and is therefore responsible for the +1.206 pp gain) is not supported by any reported number for the supervised-only ensemble accuracy or by any diversity metric (prediction disagreement, feature correlation) between the SSL branch and the other streams. The abstract states that ablation studies on ensemble strategy exist, yet the provided text contains none of the required quantities.
Authors: We agree that the abstract's headline claim would be more robust if accompanied by the accuracy of the supervised-only ensemble and explicit diversity metrics. The reported +1.206 pp improvement is measured against the previous state of the art (73.213%), which was achieved by supervised multi-stream models; our ensemble augments those models with the SSL RGB branch. The full paper contains ablation studies on ensemble strategy, but these do not yet include the exact supervised-only ensemble accuracy or diversity statistics. We will revise the abstract for precision and expand the experiments section with a table reporting ensemble performance both with and without the SSL branch, plus prediction-disagreement statistics between branches. revision: yes
Circularity Check
No circularity: empirical accuracies measured on independent challenge test set
full rationale
The paper reports top-1 accuracies (69.224% for the SSL RGB model, 74.419% for the ensemble) directly on the iMiGUE test set from the MiGA Challenge. Pretraining uses 120K unlabeled clips and fine-tuning uses the training split; the final metric is an external benchmark score with no fitted parameters, equations, or self-citations that reduce the reported gain to a tautology by construction. Ablation studies on ensemble strategy are referenced as external validation. This is a standard empirical ML result with no load-bearing derivation that collapses to its inputs.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Rethinking the Role of Feature Engineering and Learning Strategies in Few-Shot Hidden Emotion Recognition
A competition-winning multi-modal model for hidden emotion recognition integrates static and dynamic pose features via cross-attention and MIL pooling while noting representation collapse in vision foundation models o...
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2408.03097 (2024)
Chen, G., Wang, F., Li, K., Wu, Z., Fan, H., Yang, Y., Wang, M., Guo, D.: Pro- totype learning for micro-gesture classification. arXiv preprint arXiv:2408.03097 (2024)
arXiv 2024
-
[2]
Chen, H., Schuller, B.W., Adeli, E., Zhao, G.: The 3rd challenge on human behav- ior analysis for emotion understanding (miga) 2025: From recognition to emotion understanding (2025) Self-supervised Learning Matters 9
2025
-
[3]
International Journal of Computer Vision131(6), 1346–1366 (2023)
Chen, H., Shi, H., Liu, X., Li, X., Zhao, G.: Smg: A micro-gesture dataset to- wards spontaneous body gestures for emotional stress state analysis. International Journal of Computer Vision131(6), 1346–1366 (2023)
2023
-
[4]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Duan, H., Zhao, Y., Chen, K., Lin, D., Dai, B.: Revisiting skeleton-based action recognition. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 2969–2978 (2022)
2022
-
[5]
In: Proceedings of the 33rd ACM International Conference on Multimedia
Gu, J., Li, K., Wang, F., Wei, Y., Wu, Z., Fan, H., Wang, M.: Motion matters: Motion-guided modulation network for skeleton-based micro-action recognition. In: Proceedings of the 33rd ACM International Conference on Multimedia. pp. 5461–5470 (2025)
2025
-
[6]
arXiv preprint arXiv:2507.08344 (2025)
Gu, J., Wang, F., Li, K., Wei, Y., Wu, Z., Guo, D.: Mm-gesture: towards precise micro-gesture recognition through multimodal fusion. arXiv preprint arXiv:2507.08344 (2025)
arXiv 2025
-
[7]
IEEE Transactions on Circuits and Systems for Video Technology34(7), 6238–6252 (2024)
Guo, D., Li, K., Hu, B., Zhang, Y., Wang, M.: Benchmarking micro-action recog- nition: Dataset, methods, and applications. IEEE Transactions on Circuits and Systems for Video Technology34(7), 6238–6252 (2024)
2024
-
[8]
In: Proceedings of the 32nd ACM International Conference on Multimedia
Guo, D., Li, X., Li, K., Chen, H., Hu, J., Zhao, G., Yang, Y., Wang, M.: Mac 2024: Micro-action analysis grand challenge. In: Proceedings of the 32nd ACM International Conference on Multimedia. pp. 11304–11305 (2024)
2024
-
[9]
In: Proceedings of the AAAI conference on artificial intelligence
Guo, T., Liu, H., Chen, Z., Liu, M., Wang, T., Ding, R.: Contrastive learning from extremely augmented skeleton sequences for self-supervised action recognition. In: Proceedings of the AAAI conference on artificial intelligence. vol. 36, pp. 762–770 (2022)
2022
-
[10]
IEEE Transactions on Circuits and Systems for Video Technology32(10), 7120–7132 (2022)
Hao, Y., Wang, S., Cao, P., Gao, X., Xu, T., Wu, J., He, X.: Attention in attention: Modeling context correlation for efficient video classification. IEEE Transactions on Circuits and Systems for Video Technology32(10), 7120–7132 (2022)
2022
-
[11]
In: Proceedings of the ieee/cvf conference on computer vision and pattern recognition
Hao, Y., Zhang, H., Ngo, C.W., He, X.: Group contextualization for video recog- nition. In: Proceedings of the ieee/cvf conference on computer vision and pattern recognition. pp. 928–938 (2022)
2022
-
[12]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
He, K., Chen, X., Xie, S., Li, Y., Dollár, P., Girshick, R.: Masked autoencoders are scalable vision learners. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 16000–16009 (2022)
2022
-
[13]
MiGA@ IJCAI (2025)
Hu, X., Pu, C., Li, Y., Xu, Y., Xie, K., Miao, Q.: Enhancing micro-gesture clas- sification via global-aware importance estimation in vision transformer. MiGA@ IJCAI (2025)
2025
-
[14]
In: MiGA@ IJCAI (2023)
Huang, H., Guo, X., Peng, W., Xia, Z.: Micro-gesture classification based on en- semble hypergraph-convolution transformer. In: MiGA@ IJCAI (2023)
2023
-
[15]
In: MiGA@ IJCAI (2024)
Huang, H., Wang, Y., Linghu, K., Xia, Z.: Multi-modal micro-gesture classification via multi-scale heterogeneous ensemble network. In: MiGA@ IJCAI (2024)
2024
-
[16]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Li, K., Gu, J., Wang, F., Wu, Z., Fan, H., Guo, D.: Ma-bench: Towards fine- grained micro-action understanding. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 20118–20128 (June 2026)
2026
-
[17]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Li, K., Guo, D., Chen, G., Fan, C., Xu, J., Wu, Z., Fan, H., Wang, M.: Prototypical calibrating ambiguous samples for micro-action recognition. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 39, pp. 4815–4823 (2025)
2025
-
[18]
In: Proceedings of the 31st ACM International Conference on Multimedia
Li, K., Guo, D., Chen, G., Liu, F., Wang, M.: Data augmentation for human behavior analysis in multi-person conversations. In: Proceedings of the 31st ACM International Conference on Multimedia. pp. 9516–9520 (2023)
2023
-
[19]
arXiv preprint arXiv:2307.10624 (2023) 10 Tingyi Liu et al
Li, K., Guo, D., Chen, G., Peng, X., Wang, M.: Joint skeletal and semantic embed- ding loss for micro-gesture classification. arXiv preprint arXiv:2307.10624 (2023) 10 Tingyi Liu et al
arXiv 2023
-
[20]
In: Proceedings of the 33rd ACM International Conference on Multimedia
Li, K., Guo, D., Li, X., Chen, H., Liu, P., Wang, F., Hu, J., Zhao, G., Wang, M.: Mac 2025: The 2nd micro-action analysis grand challenge. In: Proceedings of the 33rd ACM International Conference on Multimedia. pp. 14216–14221 (2025)
2025
-
[21]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Li, K., Liu, P., Guo, D., Wang, F., Wu, Z., Fan, H., Wang, M.: Mmad: Multi-label micro-action detection in videos. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 13225–13236 (2025)
2025
-
[22]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Li, L., Wang, M., Ni, B., Wang, H., Yang, J., Zhang, W.: 3d human action rep- resentation learning via cross-view consistency pursuit. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 4741–4750 (2021)
2021
-
[23]
In: Proceed- ings of the 31st ACM International Conference on Multimedia
Li, Q., Huang, X., Wan, Z., Hu, L., Wu, S., Zhang, J., Shan, S., Wang, Z.: Data- efficient masked video modeling for self-supervised action recognition. In: Proceed- ings of the 31st ACM International Conference on Multimedia. pp. 2723–2733 (2023)
2023
-
[24]
In: Proceedings of the 28th ACM international conference on multimedia
Lin, L., Song, S., Yang, W., Liu, J.: Ms2l: Multi-task self-supervised learning for skeleton based action recognition. In: Proceedings of the 28th ACM international conference on multimedia. pp. 2490–2498 (2020)
2020
-
[25]
arXiv preprint arXiv:2507.09512 (2025)
Liu, P., Li, K., Wang, F., Wei, Y., She, J., Guo, D.: Online micro-gesture recog- nition using data augmentation and spatial-temporal attention. arXiv preprint arXiv:2507.09512 (2025)
arXiv 2025
-
[26]
arXiv preprint arXiv:2407.04490 (2024)
Liu, P., Wang, F., Li, K., Chen, G., Wei, Y., Tang, S., Wu, Z., Guo, D.: Micro-gesture online recognition using learnable query points. arXiv preprint arXiv:2407.04490 (2024)
arXiv 2024
-
[27]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Liu, X., Shi, H., Chen, H., Yu, Z., Li, X., Zhao, G.: imigue: An identity-free video dataset for micro-gesture understanding and emotion analysis. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10631– 10642 (2021)
2021
-
[28]
Liu, Z., Lin, Y., Cao, Y., Hu, H., Wei, Y., Zhang, Z., Lin, S., Guo, B.: Swin transformer:Hierarchicalvisiontransformerusingshiftedwindows.In:Proceedings of the IEEE/CVF international conference on computer vision. pp. 10012–10022 (2021)
2021
-
[29]
In: Proceedings of the IEEE/CVF conference on computer vision and pat- tern recognition
Liu, Z., Ning, J., Cao, Y., Wei, Y., Zhang, Z., Lin, S., Hu, H.: Video swin trans- former. In: Proceedings of the IEEE/CVF conference on computer vision and pat- tern recognition. pp. 3202–3211 (2022)
2022
-
[30]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Mao, Y., Deng, J., Zhou, W., Fang, Y., Ouyang, W., Li, H.: Masked motion predic- tors are strong 3d action representation learners. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 10181–10191 (2023)
2023
-
[31]
In: Chinese Conference on Pattern Recognition and Computer Vision (PRCV)
Shang, T., Hao, Y., Pei, M., Li, K., Ben, H., Wang, S.: Cross-modal feature en- hancement and contrastive alignment for micro-gesture recognition. In: Chinese Conference on Pattern Recognition and Computer Vision (PRCV). pp. 203–217. Springer (2025)
2025
-
[32]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Thoker, F.M., Jiang, L., Zhao, C., Ghanem, B.: Smile: Infusing spatial and motion semantics in masked video learning. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 8438–8449 (2025)
2025
-
[33]
Advances in neural infor- mation processing systems35, 10078–10093 (2022)
Tong, Z., Song, Y., Wang, J., Wang, L.: Videomae: Masked autoencoders are data- efficient learners for self-supervised video pre-training. Advances in neural infor- mation processing systems35, 10078–10093 (2022)
2022
-
[34]
arXiv preprint arXiv:2605.17179 (2026) Self-supervised Learning Matters 11
Wang,C.,Chen,H.,Wei,H.,Yang,Y.,Chen,Y.,Zhao,G.:imigue-3k:Alarge-scale benchmark for micro-gesture analysis with self-supervised learning. arXiv preprint arXiv:2605.17179 (2026) Self-supervised Learning Matters 11
Pith/arXiv arXiv 2026
-
[35]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Wang, F., Guo, D., Li, K., Wang, M.: Eulermormer: Robust eulerian motion mag- nification via dynamic filtering within transformer. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 38, pp. 5345–5353 (2024)
2024
-
[36]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Wang, F., Guo, D., Li, K., Zhong, Z., Wang, M.: Frequency decoupling for mo- tion magnification via multi-level isomorphic architecture. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 18984– 18994 (2024)
2024
-
[37]
In: Companion Proceedings of the ACM on Web Conference 2025
Wang, F., Li, K., Nie, Y., Duan, Z., Zou, P., Wu, Z., Wang, Y., Wei, Y.: Exploiting ensemble learning for cross-view isolated sign language recognition. In: Companion Proceedings of the ACM on Web Conference 2025. pp. 2453–2457 (2025)
2025
-
[38]
In: Proceedings of the ACM Web Conference 2026
Wang, F., Yang, J., Chen, J., Liu, Y., Li, K., Wei, Y., Guo, D., Wang, M.: Xin- sight: Integrative stage-consistent psychological counseling support agents for dig- ital well-being. In: Proceedings of the ACM Web Conference 2026. pp. 9297–9308 (2026)
2026
-
[39]
In: Proceed- ings of the IEEE/CVF conference on computer vision and pattern recognition
Wang, L., Huang, B., Zhao, Z., Tong, Z., He, Y., Wang, Y., Wang, Y., Qiao, Y.: Videomae v2: Scaling video masked autoencoders with dual masking. In: Proceed- ings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 14549–14560 (2023)
2023
-
[40]
IEEE Transactions on Affective Computing pp
Wang,R.,Li,K.,Tong,A.,Xu,J.,Guo,D.,Wang,M.:Gaitemotionrecognitionvia uncertainty-oriented class discriminative learning. IEEE Transactions on Affective Computing pp. 1–14 (2026)
2026
-
[41]
Machine Intelligence Research23(2), 308–330 (2026)
Wang, T., Lin, X., Xu, Y., Ye, Q., Guo, D., Escalera, S., Khoriba, G., Yu, Z.: Micro- gesture recognition: A comprehensive survey of datasets, methods, and challenges. Machine Intelligence Research23(2), 308–330 (2026)
2026
-
[42]
In: MiGA@ IJCAI (2024)
Wang, Y., Dong, Z., Li, P., Liu, Y.: A multimodal micro-gesture classification model based on clip. In: MiGA@ IJCAI (2024)
2024
-
[43]
arXiv preprint arXiv:2602.08057 (2026)
Wang, Y., Liu, H., Xu, T., Shi, C., Xing, H.: Weak to strong: Vlm-based pseudo- labeling as a weakly supervised training strategy in multimodal video-based hidden emotion understanding tasks. arXiv preprint arXiv:2602.08057 (2026)
arXiv 2026
-
[44]
IEEE Trans- actions on Affective Computing (2025)
Xia, Z., Huang, H., Chen, H., Feng, X., Zhao, G.: Hybrid-supervised hypergraph- enhanced transformer for micro-gesture based emotion recognition. IEEE Trans- actions on Affective Computing (2025)
2025
-
[45]
arXiv preprint arXiv:2506.12848 (2025)
Xu, H., Cheng, L., Wang, Y., Tang, S., Zhong, Z.: Towards fine-grained emo- tion understanding via skeleton-based micro-gesture recognition. arXiv preprint arXiv:2506.12848 (2025)
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.