Multi-View Speech Representation Learning for Parkinson's Disease Detection Using Context-guided Cross-modal Attention
Pith reviewed 2026-06-27 15:10 UTC · model grok-4.3
The pith
A multi-branch model fuses Log-Mel, MFCC and HuBERT speech features via context-guided cross-modal attention to detect Parkinson's disease at 91.51 percent accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
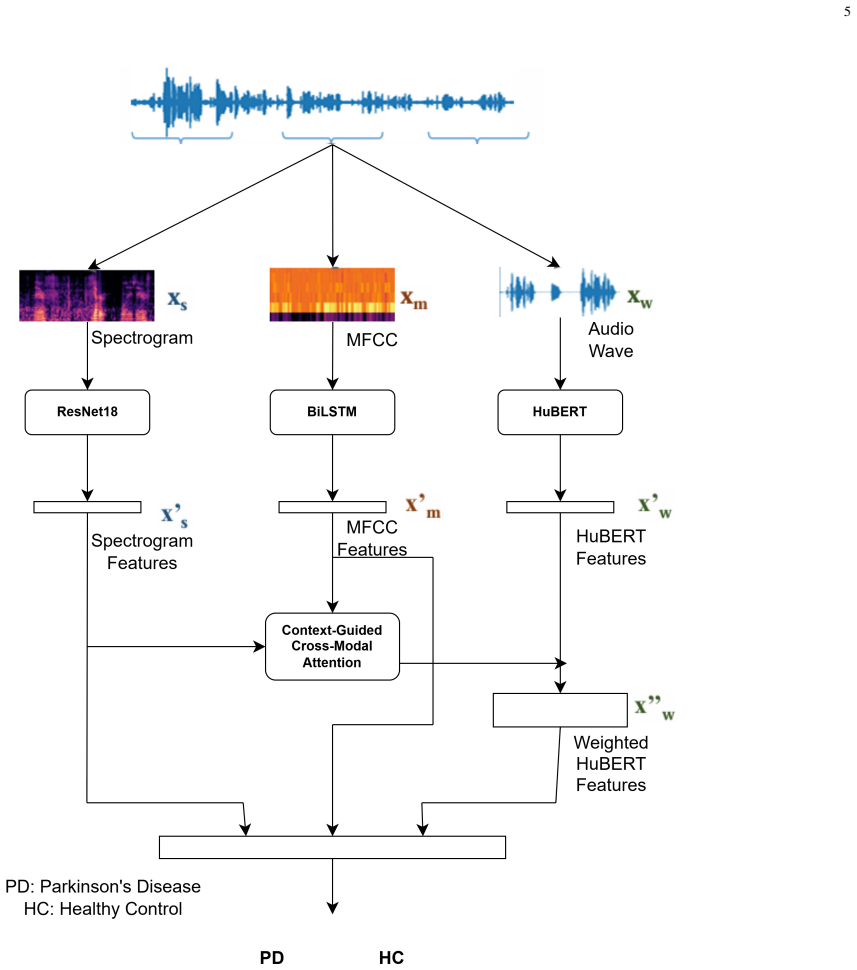
The central claim is that the proposed multi-branch architecture, which integrates heterogeneous speech representations through a context-guided cross-modal attention mechanism that dynamically weights temporal HuBERT embeddings according to acoustic context from the spectrogram and MFCC branches, achieves superior Parkinson's disease detection performance on the PC-GITA corpus under strict speaker-independent validation.
What carries the argument
Context-guided cross-modal attention mechanism that dynamically weights temporal HuBERT embeddings using global acoustic context from the spectrogram and MFCC branches.
If this is right
- Integration of complementary speech modalities improves detection accuracy, F1-score and AUC over single-representation baselines.
- The context-guided attention successfully exploits cross-modal complementarity on the tested data.
- Speaker-independent 5-fold cross-validation supports robustness across different speakers.
- Ablation studies isolate the contribution of both the attention mechanism and the use of multiple representations.
Where Pith is reading between the lines
- The same fusion approach could be tested on speech data from other neurodegenerative conditions that affect voice.
- If performance holds on larger and more diverse corpora, the pipeline could be adapted for mobile screening applications.
- Replacing any of the three input branches with an alternative representation would test whether the reported gains depend on this specific trio.
Load-bearing premise
The three chosen speech representations supply sufficiently complementary pathological information and the context-guided cross-modal attention can reliably exploit that complementarity without introducing spurious correlations on the limited PC-GITA speaker set.
What would settle it
A substantial drop below 91 percent accuracy when the same architecture is evaluated on an independent Parkinson's speech corpus recorded in a different language or under different acoustic conditions.
Figures
read the original abstract
Parkinson's disease (PD) is a progressive neurodegenerative disorder that frequently causes speech impairments associated with hypokinetic dysarthria. As speech production relies on the precise coordination of complex neuromuscular mechanisms, speech analysis has emerged as a promising non-invasive and cost-effective biomarker for early PD detection. Recent deep learning approaches have shown encouraging results; however, most existing methods rely on a single speech representation, potentially overlooking complementary pathological information encoded across different feature spaces. In this work, we propose a multi-branch deep learning framework for automatic PD detection from speech. Each recording is segmented into 5-second chunks and represented using three complementary modalities: Log-Mel spectrograms, MFCCs, and HuBERT embeddings extracted from raw waveforms. The spectrograms are processed using a pre-trained ResNet-18 encoder, MFCC sequences are modeled through a BiLSTM network, and raw speech is encoded using a pre-trained HuBERT model. To effectively integrate these heterogeneous representations, we introduce a context-guided cross-modal attention mechanism that dynamically weights temporal HuBERT embeddings according to the global acoustic context derived from the spectrogram and MFCC branches. Experiments conducted on the publicly available Spanish PC-GITA corpus under strict speaker-independent 5-fold cross-validation demonstrate the effectiveness of the proposed approach. The proposed architecture achieves an accuracy of 91.51%, an F1-score of 91.24%, and an AUC of 95.97%. Furthermore, ablation studies confirm the contribution of both the proposed context-guided cross-modal attention mechanism and the integration of complementary speech representations. These findings highlight the potential of heterogeneous speech modeling for robust and clinically reliable PD detection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a multi-branch deep learning framework for Parkinson's disease detection from speech on the PC-GITA corpus. Recordings are segmented into 5-second chunks and processed via three modalities (Log-Mel spectrograms via pre-trained ResNet-18, MFCC sequences via BiLSTM, and raw waveforms via pre-trained HuBERT). These are fused using a novel context-guided cross-modal attention mechanism that conditions HuBERT temporal embeddings on global context from the other branches. Under speaker-independent 5-fold cross-validation, the model reports 91.51% accuracy, 91.24% F1-score, and 95.97% AUC; ablation studies are stated to confirm the value of the attention mechanism and multi-view integration.
Significance. If the reported gains prove robust rather than artifacts of the small speaker set, the work would demonstrate a concrete advance in heterogeneous speech modeling for clinical biomarker detection. The combination of pre-trained encoders with a context-guided attention fusion is a reasonable architectural choice for exploiting complementary pathological cues across feature spaces.
major comments (3)
- [Abstract] Abstract (experiments paragraph): The headline metrics (91.51% accuracy, 91.24% F1, 95.97% AUC) are presented without any numerical single-modality baselines, simpler fusion baselines, or direct comparisons to prior PD-detection methods evaluated on identical PC-GITA speaker-independent 5-fold splits. This omission prevents assessment of whether the context-guided cross-modal attention supplies a genuine incremental benefit.
- [Abstract] Abstract (ablation studies sentence): Ablation studies are invoked to confirm the contribution of the context-guided cross-modal attention and multi-view integration, yet no numerical ablation results, per-fold variances, or statistical significance tests (e.g., paired t-tests or McNemar) are supplied. Without these, it is impossible to determine whether the attention pathway yields a reliable improvement over the three encoders alone.
- [Abstract] Abstract (experiments paragraph): No per-fold standard deviations, confidence intervals, or error bars accompany the 5-fold CV results. Given that PC-GITA contains only ~100 speakers total (~20 unseen speakers per test fold) and that the attention mechanism introduces additional learned parameters conditioned on global context, the absence of variance reporting leaves open the possibility that the reported performance reflects speaker-specific memorization rather than generalizable pathology detection.
minor comments (1)
- [Abstract] The abstract states that each recording is segmented into 5-second chunks but does not specify overlap, windowing parameters, or how chunk-level predictions are aggregated to recording- or speaker-level decisions.
Simulated Author's Rebuttal
We thank the referee for these focused comments on the abstract. We address each point below and will revise the abstract to improve self-containment while preserving its length constraints.
read point-by-point responses
-
Referee: [Abstract] Abstract (experiments paragraph): The headline metrics (91.51% accuracy, 91.24% F1, 95.97% AUC) are presented without any numerical single-modality baselines, simpler fusion baselines, or direct comparisons to prior PD-detection methods evaluated on identical PC-GITA speaker-independent 5-fold splits. This omission prevents assessment of whether the context-guided cross-modal attention supplies a genuine incremental benefit.
Authors: The full manuscript reports single-modality and fusion baselines plus prior-work comparisons on the same speaker-independent 5-fold splits in Section 4 and Table 2. To make the abstract self-contained, we will insert concise numerical deltas (e.g., “+4.2% accuracy over best single modality”) into the experiments paragraph. revision: yes
-
Referee: [Abstract] Abstract (ablation studies sentence): Ablation studies are invoked to confirm the contribution of the context-guided cross-modal attention and multi-view integration, yet no numerical ablation results, per-fold variances, or statistical significance tests (e.g., paired t-tests or McNemar) are supplied. Without these, it is impossible to determine whether the attention pathway yields a reliable improvement over the three encoders alone.
Authors: Detailed ablation tables with per-fold means, standard deviations, and McNemar tests appear in Section 4.3. We will add the key numerical ablation deltas and a brief note on significance to the abstract sentence. revision: yes
-
Referee: [Abstract] Abstract (experiments paragraph): No per-fold standard deviations, confidence intervals, or error bars accompany the 5-fold CV results. Given that PC-GITA contains only ~100 speakers total (~20 unseen speakers per test fold) and that the attention mechanism introduces additional learned parameters conditioned on global context, the absence of variance reporting leaves open the possibility that the reported performance reflects speaker-specific memorization rather than generalizable pathology detection.
Authors: We will report per-fold standard deviations and 95% confidence intervals in the revised abstract. The speaker-independent protocol and pre-trained encoders already limit memorization; the added variance numbers will further address this concern. revision: yes
Circularity Check
No significant circularity; empirical result on public corpus
full rationale
The paper describes a multi-branch neural architecture (ResNet-18 on Log-Mel, BiLSTM on MFCC, HuBERT on raw audio) with a context-guided cross-modal attention module, evaluated via speaker-independent 5-fold CV on the public PC-GITA corpus. Reported metrics (91.51% accuracy etc.) are presented as direct empirical measurements rather than derived quantities. No equations, self-definitional loops, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. Ablation studies are invoked only to confirm contribution of components, without reducing the headline result to a tautology. The derivation chain is therefore self-contained as standard supervised learning on held-out speakers.
Axiom & Free-Parameter Ledger
free parameters (1)
- model hyperparameters and attention weights
axioms (2)
- domain assumption Pre-trained ResNet-18, BiLSTM, and HuBERT encoders transfer useful features to the PD-detection task without domain-specific fine-tuning details being required.
- domain assumption Speaker-independent 5-fold cross-validation on PC-GITA is sufficient to demonstrate generalization.
invented entities (1)
-
context-guided cross-modal attention mechanism
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Parkinson disease,
S. Zafar and S. S. Yaddanapudi, “Parkinson disease,” inStatPearls. StatPearls Publishing, 2023
2023
-
[2]
Parkinson’s disease: mechanisms and models,
W. Dauer and S. Przedborski, “Parkinson’s disease: mechanisms and models,”Neuron, vol. 39, no. 6, pp. 889–909, 2003. 10
2003
-
[3]
Hypokinetic dysarthria in parkinson’s disease: A narrative review,
M. S. Atalaret al., “Hypokinetic dysarthria in parkinson’s disease: A narrative review,”Journal of Communication Disorders, 2023
2023
-
[4]
Parkinson’s disease-associated dysarthria: preva- lence, impact and management strategies,
G. Moya-Gal ´eet al., “Parkinson’s disease-associated dysarthria: preva- lence, impact and management strategies,”Research and Reviews in Parkinsonism, 2019
2019
-
[5]
Laryngeal motor cortex and control of speech in humans,
K. Simonyan and B. Horwitz, “Laryngeal motor cortex and control of speech in humans,”The Neuroscientist, vol. 17, no. 2, pp. 197–208, 2011
2011
-
[6]
Neurobiology of speech production,
P. Tremblay, I. Deschamps, and V . L. Gracco, “Neurobiology of speech production,” inNeurobiology of Language. Academic Press, 2015
2015
-
[7]
From prodromal stages to clinical trials: The promise of speech biomarkers in parkinson’s disease,
J. Ruszet al., “From prodromal stages to clinical trials: The promise of speech biomarkers in parkinson’s disease,”Neuroscience and Biobe- havioral Reviews, 2024
2024
-
[8]
Evaluation of speech-based digital biomarkers: Review and recommendations,
J. Robinet al., “Evaluation of speech-based digital biomarkers: Review and recommendations,”Digital Biomarkers, 2020
2020
-
[9]
New Spanish speech corpus database for the analysis of people suffering from Parkinson’s disease,
J. R. Orozco-Arroyave, J. D. Arias-Londo ˜no, J. F. Vargas-Bonilla, M. C. Gonz ´alez-R´ativa, and E. N ¨oth, “New Spanish speech corpus database for the analysis of people suffering from Parkinson’s disease,” inProceedings of the Ninth International Conference on Language Resources and Evaluation (LREC’14), N. Calzolari, K. Choukri, T. Declerck, H. Loftss...
2014
-
[10]
On the inter-dataset generalization of machine learning approaches to parkin- son’s disease detection from voice,
M. Hire ˇs, P. Drot ´ar, N. Pah, Q. C. Ngo, and D. K. Kumar, “On the inter-dataset generalization of machine learning approaches to parkin- son’s disease detection from voice,”International Journal of Medical Informatics, vol. 179, p. 105237, 2023
2023
-
[11]
A comparative and explain- able study of machine learning models for early detection of parkinson’s disease using spectrograms,
H. Zebidi, Z. BenMessaoud, and M. Frikha, “A comparative and explain- able study of machine learning models for early detection of parkinson’s disease using spectrograms,” inProceedings of the 14th International Conference on Pattern Recognition Applications and Methods - Volume 1: ICPRAM, INSTICC. SciTePress, 2025, pp. 272–282
2025
-
[12]
Phonemes based detection of Parkinson’s disease for telehealth applications,
N. D. Pah, M. A. Motin, and D. K. Kumar, “Phonemes based detection of Parkinson’s disease for telehealth applications,”Scientific Reports, vol. 12, no. 1, p. 9687, 2022
2022
-
[13]
The detection of parkinson’s disease from speech using voice source information,
N. Narendra, B. Schuller, and P. Alku, “The detection of parkinson’s disease from speech using voice source information,”IEEE/ACM Trans- actions on Audio, Speech, and Language Processing, vol. 29, pp. 1925– 1936, 2021
1925
-
[14]
Syllable level features for Parkinson’s disease detection from speech,
S. Hovsepyan and M. Magimai.-Doss, “Syllable level features for Parkinson’s disease detection from speech,” inICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Pro- cessing (ICASSP), 2024, pp. 11 416–11 420
2024
-
[15]
A pilot study for speech assessment to detect the severity of Parkinson’s disease: An ensemble approach,
G. C. Oliveira, N. D. Pah, Q. C. Ngo, A. Yoshida, N. B. Gomes, J. P. Papa, and D. Kumar, “A pilot study for speech assessment to detect the severity of Parkinson’s disease: An ensemble approach,”Computers in Biology and Medicine, vol. 185, p. 109565, 2025
2025
-
[16]
An algorithm for Parkinson’s disease speech classification based on isolated words analysis,
F. Amato, L. Borz `ı, G. Olmo, and J. R. Orozco-Arroyave, “An algorithm for Parkinson’s disease speech classification based on isolated words analysis,”Health Information Science and Systems, vol. 9, no. 1, p. 32, 2021
2021
-
[17]
Multilingual evaluation of interpretable biomarkers to represent language and speech patterns in parkinson’s disease,
A. Favaro, L. Moro-Vel ´azquez, A. Butala, and N. Dehak, “Multilingual evaluation of interpretable biomarkers to represent language and speech patterns in parkinson’s disease,”Frontiers in Neurology, vol. 14, p. 1142642, 2023
2023
-
[18]
Robust and language-independent acoustic features in Parkinson’s disease,
S. Scimeca, F. Amato, G. Olmo, F. Asci, A. Suppa, G. Costantini, and G. Saggio, “Robust and language-independent acoustic features in Parkinson’s disease,”Frontiers in Neurology, vol. 14, p. 1198058, 2023
2023
-
[19]
Automatic detection of parkinsonian speech using wavelet scattering features,
M. Kiran Reddy and P. Alku, “Automatic detection of parkinsonian speech using wavelet scattering features,”JASA Express Letters, vol. 5, no. 5, p. 055202, 05 2025. [Online]. Available: https: //doi.org/10.1121/10.0036660
-
[20]
Exemplar-based sparse representations for detection of Parkinson’s disease from speech,
M. K. Reddy and P. Alku, “Exemplar-based sparse representations for detection of Parkinson’s disease from speech,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 31, pp. 1386–1396, 2023
2023
-
[21]
Assessing Parkinson’s Disease from Speech Using Fisher Vectors,
J. V . E. L ´opez, J. R. Orozco-Arroyave, and G. Gosztolya, “Assessing Parkinson’s Disease from Speech Using Fisher Vectors,” inInterspeech 2019, 2019, pp. 3063–3067
2019
-
[22]
High-resolution superlet trans- form based techniques for Parkinson’s disease detection using speech signal,
K. Bhatt, N. Jayanthi, and M. Kumar, “High-resolution superlet trans- form based techniques for Parkinson’s disease detection using speech signal,”Applied Acoustics, vol. 214, p. 109657, 2023
2023
-
[23]
Supervised speech representation learning for Parkinson’s disease classification,
P. Janbakhshi and I. Kodrasi, “Supervised speech representation learning for Parkinson’s disease classification,” in14th ITG Conference on Speech Communication. VDE, 2021, pp. 1–5
2021
-
[24]
A Spectrogram-Based Deep Feature Assisted Computer-Aided Diagnostic System for Parkinson’s Disease,
L. Zahid, M. Maqsood, M. Y . Durrani, M. Bakhtyar, J. Baber, H. Jamal, I. Mehmood, and O.-Y . Song, “A Spectrogram-Based Deep Feature Assisted Computer-Aided Diagnostic System for Parkinson’s Disease,” IEEE Access, vol. 8, pp. 35 482–35 495, 2020
2020
-
[25]
Towards a Corpus (and Language)-Independent Screening of Parkinson’s disease from voice and speech through domain adaptation,
E. J. Ibarra, J. D. Arias-Londo ˜no, M. Za ˜nartu, and J. I. Godino- Llorente, “Towards a Corpus (and Language)-Independent Screening of Parkinson’s disease from voice and speech through domain adaptation,” Bioengineering, vol. 10, no. 11, p. 1316, 2023
2023
-
[26]
Transfer learning helps to improve the accuracy to classify patients with different speech disorders in different languages,
J. C. V ´asquez-Correa, C. D. Rios-Urrego, T. Arias-Vergara, M. Schuster, J. Rusz, E. N ¨oth, and J. R. Orozco-Arroyave, “Transfer learning helps to improve the accuracy to classify patients with different speech disorders in different languages,”Pattern Recognition Letters, vol. 150, pp. 272– 279, 2021
2021
-
[27]
Time Series Classification of Raw Voice Waveforms for Parkinson’s Disease Detec- tion Using Generative Adversarial Network-Driven Data Augmentation,
M. Rey-Paredes, C. J. P ´erez, and A. Mateos-Caballero, “Time Series Classification of Raw Voice Waveforms for Parkinson’s Disease Detec- tion Using Generative Adversarial Network-Driven Data Augmentation,” IEEE Open Journal of the Computer Society, vol. 6, pp. 72–84, 2025
2025
-
[28]
V oice classification in parkinson’s disease: A deep learning approach using transformers and error rate metrics,
B. Perrone, F. Amato, and G. Olmo, “V oice classification in parkinson’s disease: A deep learning approach using transformers and error rate metrics,”Biomedical Signal Processing and Control, vol. 113, p. 108954, 2026. [Online]. Available: https://www.sciencedirect.com/ science/article/pii/S174680942501465X
2026
-
[29]
T. Zeng, Y . Ye, Y . Zeng, J. Shi, Y . Huang, B. Ding, K. Chipusu, and J. Huang, “Physiological classification of parkinson’s disease severity using multimodal speech biomarkers with a hybrid cnn- mamba framework,”Frontiers in Physiology, vol. V olume 17 - 2026, 2026. [Online]. Available: https://www.frontiersin.org/journals/ physiology/articles/10.3389/f...
-
[30]
Interpretable speech features vs. DNN embed- dings: What to use in the automatic assessment of Parkinson’s disease in multi-lingual scenarios,
A. Favaro, Y .-T. Tsai, A. Butala, T. Thebaud, J. Villalba, N. Dehak, and L. Moro-Vel´azquez, “Interpretable speech features vs. DNN embed- dings: What to use in the automatic assessment of Parkinson’s disease in multi-lingual scenarios,”Computers in Biology and Medicine, vol. 166, p. 107559, 2023
2023
-
[31]
Ranking pre-trained speech embeddings in Parkinson’s disease detection: Does Wav2Vec 2.0 outperform its 1.0 version across speech modes and lan- guages?
O. Klempir, A. Skryjova, A. Tichopad, and R. Krupicka, “Ranking pre-trained speech embeddings in Parkinson’s disease detection: Does Wav2Vec 2.0 outperform its 1.0 version across speech modes and lan- guages?”Computational and Structural Biotechnology Journal, vol. 27, pp. 2584–2601, 2025
2025
-
[32]
Unveiling interpretability in self-supervised speech representations for Parkinson’s diagnosis,
D. Gimeno-G ´omez, C. Botelho, A. Pompili, A. Abad, and C.-D. Mart´ınez-Hinarejos, “Unveiling interpretability in self-supervised speech representations for Parkinson’s diagnosis,”IEEE Journal of Selected Topics in Signal Processing, vol. 19, no. 5, pp. 717–730, 2025
2025
-
[33]
Automatic classification of Parkinson’s disease using wav2vec embeddings at phoneme, syllable, and word levels,
J. D. Gallo-Aristiz ´abal, D. Escobar-Grisales, C. D. R´ıos-Urrego, E. N¨oth, and J. R. Orozco-Arroyave, “Automatic classification of Parkinson’s disease using wav2vec embeddings at phoneme, syllable, and word levels,” inText, Speech, and Dialogue (TSD 2024), ser. Lecture Notes in Computer Science, vol. 15049. Springer, Cham, 2024
2024
-
[34]
Exploiting foundation models and speech enhancement for Parkinson’s disease detection from speech in real-world operative conditions,
M. La Quatra, M. F. Turco, T. Svendsen, G. Salvi, J. R. Orozco- Arroyave, and S. M. Siniscalchi, “Exploiting foundation models and speech enhancement for Parkinson’s disease detection from speech in real-world operative conditions,” inInterspeech 2024. ISCA, 2024, pp. 1405–1409
2024
-
[35]
Evaluating the usefulness of non-diagnostic speech data for developing Parkinson’s disease classifiers,
T. Y . Zhong, E. Janse, C. Tejedor-Garcia, L. t. Bosch, and M. Larson, “Evaluating the usefulness of non-diagnostic speech data for developing Parkinson’s disease classifiers,” inInterspeech 2025. ISCA, 2025, pp. 3738–3742
2025
-
[36]
Bilingual dual-head deep model for parkinson’s disease detection from speech,
M. La Quatra, J. R. Orozco-Arroyave, and M. S. Siniscalchi, “Bilingual dual-head deep model for parkinson’s disease detection from speech,” inICASSP 2025 - 2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2025, pp. 1–5
2025
-
[37]
Automatic parkinson’s disease detection from speech: Layer selection vs adaptation of foundation models,
T. Purohit, B. Ruvolo, J. R. Orozco-Arroyave, and M. Magimai.-Doss, “Automatic parkinson’s disease detection from speech: Layer selection vs adaptation of foundation models,” inICASSP 2025 - 2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2025, pp. 1–5
2025
-
[38]
Beyond bilinear: Generalized multimodal factorized high-order pooling for visual question answering,
Z. Yu, J. Yu, C. Xiang, J. Fan, and D. Tao, “Beyond bilinear: Generalized multimodal factorized high-order pooling for visual question answering,” IEEE TNNLS, 2018
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.