PRISM: Topology-Aware Cross-Modal Imputation for Modality-Deficient Federated Graph Learning
Pith reviewed 2026-06-27 17:33 UTC · model grok-4.3
The pith
PRISM recovers missing-modality semantics from the federation and introduces them into local graph propagation under topology-aware control.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
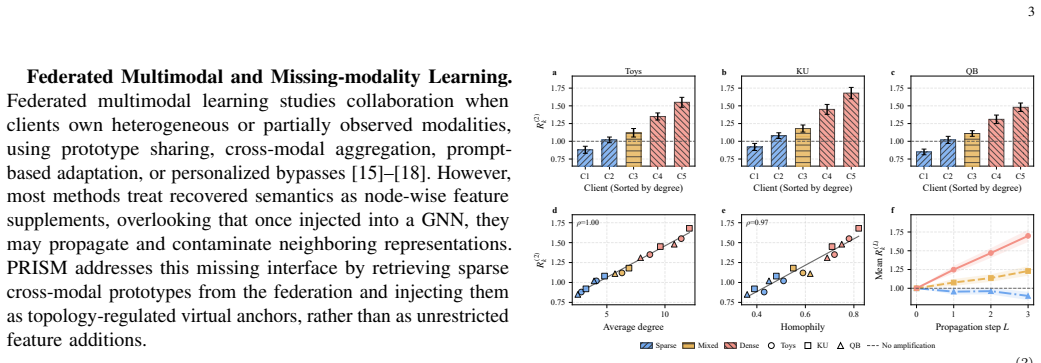
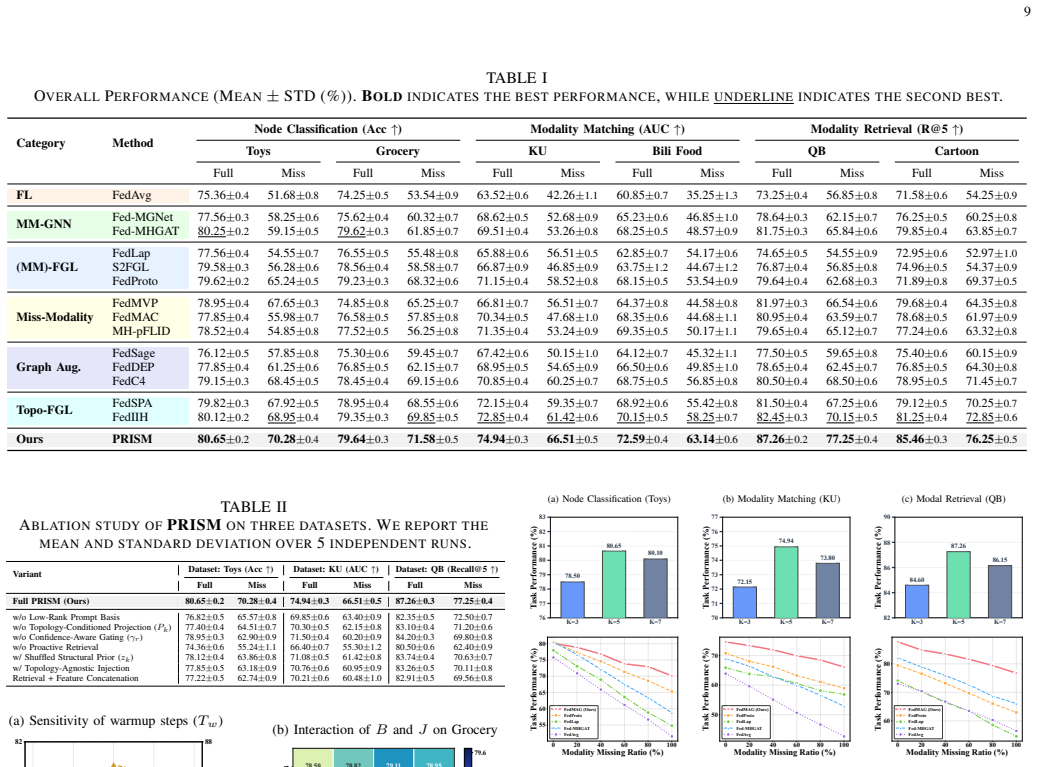
Rather than reconstructing the missing modality solely from local observations, PRISM recovers missing-modality semantics from the federation and introduces them into local graph propagation under topology-aware control. Experiments on six multimodal graph datasets across graph-centric and modality-centric tasks show that PRISM consistently improves modality-deficient clients, outperforming state-of-the-art baselines by 4.48% on average.
What carries the argument
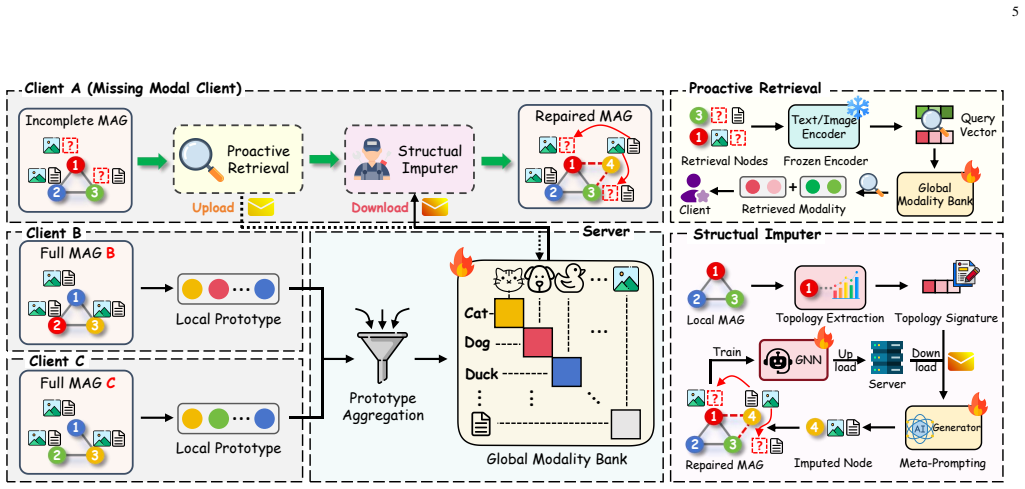
PRISM (Proactive Retrieval and Imputation via Structural Meta-prompting), a topology-aware federated cross-modal imputation framework that retrieves complementary semantics and controls their injection during graph message passing.
If this is right
- Modality-deficient clients receive performance improvements on graph learning tasks.
- Imputation errors are limited in their ability to propagate and amplify through receiving graph topologies.
- The framework applies to both graph-centric and modality-centric tasks across six datasets.
- Average gains of 4.48% are observed over prior state-of-the-art baselines.
Where Pith is reading between the lines
- The same retrieval-plus-control pattern could be tested in federated settings without graphs, such as tabular or sequence data.
- If complementary clients become scarce, selective client sampling or synthetic augmentation might be needed as extensions.
- Topology control might reduce the volume of data exchanged during imputation rounds.
Load-bearing premise
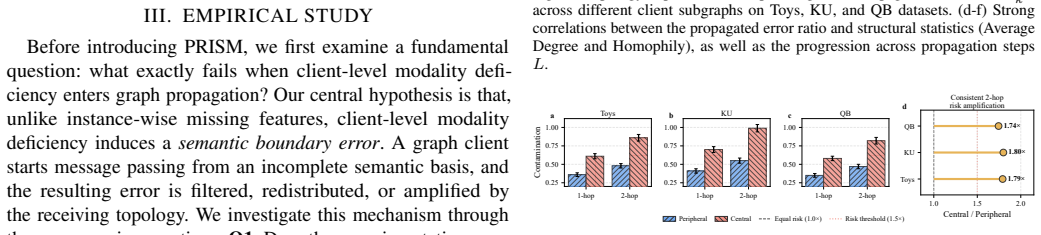
The federation contains clients holding the complementary modality in sufficient quantity and quality, and topology-aware control can stop imputation errors from being filtered, mixed, and amplified during message passing.
What would settle it
Performance gains disappear when the federation is altered to contain no clients with the missing modality, or when the topology-aware control mechanism is disabled while keeping retrieval active.
Figures



read the original abstract
Multimodal federated graph learning (MM-FGL) aims to collaboratively learn from decentralized graphs with text and images. However, real-world clients may not share a common modality basis: a visual-search client may contain image--interaction graphs but no seller descriptions, while a catalog client may provide text but no product images. We refer to this practical setting as client-level modality deficiency. Unlike random instance-wise missingness, a deficient client lacks the local semantic basis needed to reconstruct the absent modality. More importantly, in graph learning, incomplete representations initialize message passing, so imputation errors can be filtered, mixed, and amplified by the receiving topology. To address this gap, we propose \textbf{PRISM} (\textbf{P}roactive \textbf{R}etrieval and \textbf{I}mputation via \textbf{S}tructural \textbf{M}eta-prompting), a topology-aware federated cross-modal imputation framework. Rather than reconstructing the missing modality solely from local observations, PRISM recovers missing-modality semantics from the federation and introduces them into local graph propagation under topology-aware control. Experiments on six multimodal graph datasets across graph-centric and modality-centric tasks show that PRISM consistently improves modality-deficient clients, outperforming state-of-the-art baselines by \textbf{4.48}\% on average.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes PRISM (Proactive Retrieval and Imputation via Structural Meta-prompting), a topology-aware federated cross-modal imputation framework for client-level modality deficiency in multimodal federated graph learning (MM-FGL). Unlike instance-wise missingness, deficient clients lack the local semantic basis for the absent modality (e.g., images or text). PRISM recovers missing-modality semantics from the federation and introduces them into local graph propagation under topology-aware control to mitigate error filtering, mixing, and amplification during message passing. Experiments on six multimodal graph datasets across graph-centric and modality-centric tasks report that PRISM consistently improves modality-deficient clients and outperforms state-of-the-art baselines by 4.48% on average.
Significance. If the empirical results and the topology-aware control mechanism hold, the work addresses a realistic and under-studied setting in MM-FGL where modality availability is heterogeneous across clients rather than randomly missing. The focus on preventing imputation errors from propagating through graph topologies could influence practical federated deployments in visual-search, catalog, or recommendation domains. The central claim is falsifiable via the reported experiments on six datasets.
major comments (1)
- [Abstract] Abstract: the central empirical claim of a 4.48% average improvement is presented without any description of the experimental protocol, baselines, statistical tests, ablation results, client-modality distribution statistics, or dataset characteristics, rendering the data unevaluable against the claim and undermining assessment of the topology-aware control's effectiveness.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback. The concern regarding the abstract is valid and we address it directly below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim of a 4.48% average improvement is presented without any description of the experimental protocol, baselines, statistical tests, ablation results, client-modality distribution statistics, or dataset characteristics, rendering the data unevaluable against the claim and undermining assessment of the topology-aware control's effectiveness.
Authors: We agree that the abstract would benefit from additional context to support the central claim. In the revised manuscript, we will update the abstract to include a brief description of the experimental setup, including the six multimodal graph datasets used, the state-of-the-art baselines compared against, and the tasks (graph-centric and modality-centric). We will also note that the improvement is observed consistently for modality-deficient clients. Full details on statistical tests, ablations, and client-modality distributions are provided in the experimental section (Section 4), but we will incorporate key highlights into the abstract where space permits. This revision will make the empirical claim more evaluable while maintaining the abstract's conciseness. revision: yes
Circularity Check
No significant circularity identified
full rationale
The abstract and reader's assessment contain no equations, derivations, or load-bearing mathematical steps, so no reduction of predictions to fitted inputs or self-definitional claims can be exhibited. The method is presented as an empirical framework whose performance gains rest on external assumptions about modality distribution across clients rather than any internal chain that collapses to its own inputs by construction. Without visible self-citation load-bearing premises or ansatz smuggling, the proposal remains self-contained against the provided text.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Mobiclique: Middleware for mobile social networking
Anna-Kaisa Pietiläinen, Earl Oliver, Jason LeBrun, George Varghese, and Christophe Diot. Mobiclique: Middleware for mobile social networking. InProceedings of the 2nd ACM Workshop on Online Social Networks, pages 49–54, 2009
2009
-
[2]
Lane, Kristóf Fodor, Ronald Peterson, Hong Lu, Mirco Musolesi, Shane B
Emiliano Miluzzo, Nicholas D. Lane, Kristóf Fodor, Ronald Peterson, Hong Lu, Mirco Musolesi, Shane B. Eisenman, Xiao Zheng, and Andrew T. Campbell. Sensing meets mobile social networks: The design, implementation and evaluation of the cenceme application. InProceedings of the 6th ACM Conference on Embedded Networked Sensor Systems, pages 337–350, 2008
2008
-
[3]
Barnes, and Mehdi Boukhechba
Guimin Dong, Mingyue Tang, Zhiyuan Wang, Jiechao Gao, Sikun Guo, Lihua Cai, Robert Gutierrez, Bradford Campbell, Laura E. Barnes, and Mehdi Boukhechba. Graph neural networks in iot: A survey.ACM Transactions on Sensor Networks, 19(2):1–50, 2023
2023
-
[4]
Diffusion convolutional recurrent neural network: Data-driven traffic forecasting
Yaguang Li, Rose Yu, Cyrus Shahabi, and Yan Liu. Diffusion convolutional recurrent neural network: Data-driven traffic forecasting. InInternational Conference on Learning Representations, 2018
2018
-
[5]
V2x-vit: Vehicle-to-everything cooperative perception with vision transformer
Runsheng Xu, Hao Xiang, Zhengzhong Tu, Xin Xia, Ming-Hsuan Yang, and Jiaqi Ma. V2x-vit: Vehicle-to-everything cooperative perception with vision transformer. InEuropean Conference on Computer Vision, pages 107–124, 2022
2022
-
[6]
Where2comm: Communication-efficient collaborative perception via spatial confidence maps
Yue Hu, Shaoheng Fang, Zixing Lei, Yiqi Zhong, and Siheng Chen. Where2comm: Communication-efficient collaborative perception via spatial confidence maps. InAdvances in Neural Information Processing Systems, 2022
2022
-
[7]
Yan Wang, Xin Wang, Hongmei Yang, et al. Mhagnn: A novel framework for wearable sensor-based human activity recognition combining multi- head attention and graph neural networks.IEEE Transactions on Instrumentation and Measurement, 72:1–14, 2023
2023
-
[8]
When graph meets multimodal: benchmarking and meditating on multimodal attributed graph learning
Hao Yan, Chaozhuo Li, Jun Yin, Zhigang Yu, Weihao Han, Mingzheng Li, Zhengxin Zeng, Hao Sun, and Senzhang Wang. When graph meets multimodal: benchmarking and meditating on multimodal attributed graph learning. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V . 2, pages 5842–5853, 2025
2025
-
[9]
Xunkai Li, Yuming Ai, Yinlin Zhu, Haodong Lu, Yi Zhang, Guohao Fu, Bowen Fan, Qiangqiang Dai, Rong-Hua Li, and Guoren Wang. Mm- openfgl: A comprehensive benchmark for multimodal federated graph learning.arXiv preprint arXiv:2601.22416, 2026
arXiv 2026
-
[10]
Chaoyang He, Keshav Balasubramanian, Emir Ceyani, Carl Yang, Han Xie, Lichao Sun, Lifang He, Liangwei Yang, Philip S Yu, Yu Rong, et al. Fedgraphnn: A federated learning system and benchmark for graph neural networks.arXiv preprint arXiv:2104.07145, 2021
arXiv 2021
-
[11]
Xunkai Li, Yinlin Zhu, Boyang Pang, Guochen Yan, Yeyu Yan, Zening Li, Zhengyu Wu, Wentao Zhang, Rong-Hua Li, and Guoren Wang. Openfgl: A comprehensive benchmark for federated graph learning.arXiv preprint arXiv:2408.16288, 2024
arXiv 2024
-
[12]
Graphmae: Self-supervised masked graph autoencoders
Zhenyu Hou, Xiao Liu, Yukuo Cen, Yuxiao Dong, Hongxia Yang, Chunjie Wang, and Jie Tang. Graphmae: Self-supervised masked graph autoencoders. InProceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 594–604, 2022
2022
-
[13]
Multimodal heterogeneous graph attention network
Xiangen Jia, Min Jiang, Yihong Dong, Feng Zhu, Haocai Lin, Yu Xin, and Huahui Chen. Multimodal heterogeneous graph attention network. Neural Computing and Applications, 35(4):3357–3372, 2023
2023
-
[14]
Mgnet: Learning correspondences via multiple graphs
Dai Luanyuan, Xiaoyu Du, Hanwang Zhang, and Jinhui Tang. Mgnet: Learning correspondences via multiple graphs. InProceedings of the AAAI conference on Artificial Intelligence, volume 38, pages 3945–3953, 2024
2024
-
[15]
Fedproto: Federated prototype learning across heterogeneous clients
Yue Tan, Guodong Long, Lu Liu, Tianyi Zhou, Qinghua Lu, Jing Jiang, and Chengqi Zhang. Fedproto: Federated prototype learning across heterogeneous clients. InProceedings of the AAAI conference on artificial intelligence, volume 36, pages 8432–8440, 2022. 12
2022
-
[16]
Fedmac: Tackling partial-modality missing in federated learning with cross-modal aggregation and contrastive regularization
Manh Duong Nguyen, Trung Thanh Nguyen, Huy Hieu Pham, Trong Nghia Hoang, Phi Le Nguyen, and Thanh Trung Huynh. Fedmac: Tackling partial-modality missing in federated learning with cross-modal aggregation and contrastive regularization. In2024 22nd International Symposium on Network Computing and Applications (NCA), pages 278–
-
[17]
Fedmvp: Federated multimodal visual prompt tuning for vision-language models
Mainak Singha, Subhankar Roy, Sarthak Mehrotra, Ankit Jha, Moloud Abdar, Biplab Banerjee, and Elisa Ricci. Fedmvp: Federated multimodal visual prompt tuning for vision-language models. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 17869–17878, 2025
2025
-
[18]
Mh-pflgb: Model heterogeneous personalized federated learning via global bypass for medical image analysis
Luyuan Xie, Manqing Lin, ChenMing Xu, Tianyu Luan, Zhipeng Zeng, Wenjun Qian, Cong Li, Yuejian Fang, Qingni Shen, and Zhonghai Wu. Mh-pflgb: Model heterogeneous personalized federated learning via global bypass for medical image analysis. InInternational Conference on Medical Image Computing and Computer-Assisted Intervention, pages 534–545. Springer, 2024
2024
-
[19]
Subgraph federated learning with missing neighbor generation
Ke Zhang, Carl Yang, Xiaoxiao Li, Lichao Sun, and Siu Ming Yiu. Subgraph federated learning with missing neighbor generation. In Advances in Neural Information Processing Systems, volume 34, pages 6671–6682, 2021
2021
-
[20]
Deep efficient private neighbor generation for subgraph federated learning
Ke Zhang, Lichao Sun, Bolin Ding, Siu Ming Yiu, and Carl Yang. Deep efficient private neighbor generation for subgraph federated learning. arXiv preprint arXiv:2401.04336, 2024
arXiv 2024
-
[21]
Rethinking client-oriented federated graph learning
Zekai Chen, Xunkai Li, Yinlin Zhu, Rong-Hua Li, and Guoren Wang. Rethinking client-oriented federated graph learning. InProceedings of the 34th ACM International Conference on Information and Knowledge Management, pages 393–402, 2025
2025
-
[22]
Subgraph federated learning via spectral methods.arXiv preprint arXiv:2510.25657, 2025
Javad Aliakbari, Johan Östman, Ashkan Panahi, et al. Subgraph federated learning via spectral methods.arXiv preprint arXiv:2510.25657, 2025
arXiv 2025
-
[23]
S2fgl: Spatial spectral federated graph learning.arXiv preprint arXiv:2507.02409, 2025
Zihan Tan, Suyuan Huang, Guancheng Wan, Wenke Huang, He Li, and Mang Ye. S2fgl: Spatial spectral federated graph learning.arXiv preprint arXiv:2507.02409, 2025
arXiv 2025
-
[24]
Ninerec: A benchmark dataset suite for evaluating transferable recommendation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
Jiaqi Zhang, Yu Cheng, Yongxin Ni, Yunzhu Pan, Zheng Yuan, Junchen Fu, Youhua Li, Jie Wang, and Fajie Yuan. Ninerec: A benchmark dataset suite for evaluating transferable recommendation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
2024
-
[25]
Fast unfolding of communities in large networks.Journal of statistical mechanics: theory and experiment, 2008(10):P10008, 2008
Vincent D Blondel, Jean-Loup Guillaume, Renaud Lambiotte, and Etienne Lefebvre. Fast unfolding of communities in large networks.Journal of statistical mechanics: theory and experiment, 2008(10):P10008, 2008
2008
-
[26]
Communication-efficient learning of deep networks from decentralized data
Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Aguera y Arcas. Communication-efficient learning of deep networks from decentralized data. InArtificial intelligence and statistics, pages 1273–1282. Pmlr, 2017
2017
-
[27]
Fedspa: Generalizable federated graph learning under homophily heterogeneity
Zihan Tan, Guancheng Wan, Wenke Huang, He Li, Guibin Zhang, Carl Yang, and Mang Ye. Fedspa: Generalizable federated graph learning under homophily heterogeneity. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 15464–15475, 2025
2025
-
[28]
Modeling inter-intra heterogeneity for graph federated learning
Wentao Yu, Shuo Chen, Yongxin Tong, Tianlong Gu, and Chen Gong. Modeling inter-intra heterogeneity for graph federated learning. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 22236–22244, 2025
2025
-
[29]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
2021
-
[30]
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weis- senborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929, 2020
Pith/arXiv arXiv 2010
-
[31]
Thomas N Kipf and Max Welling. Semi-supervised classification with graph convolutional networks.arXiv preprint arXiv:1609.02907, 2016
Pith/arXiv arXiv 2016
-
[32]
Graph attention networks.arXiv preprint arXiv:1710.10903, 2017
Petar Veliˇckovi´c, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Lio, and Yoshua Bengio. Graph attention networks.arXiv preprint arXiv:1710.10903, 2017
Pith/arXiv arXiv 2017
-
[33]
Inductive representation learning on large graphs.Advances in neural information processing systems, 30, 2017
Will Hamilton, Zhitao Ying, and Jure Leskovec. Inductive representation learning on large graphs.Advances in neural information processing systems, 30, 2017
2017
-
[34]
How powerful are graph neural networks?arXiv preprint arXiv:1810.00826, 2018
Keyulu Xu, Weihua Hu, Jure Leskovec, and Stefanie Jegelka. How powerful are graph neural networks?arXiv preprint arXiv:1810.00826, 2018. Zekai Chenis currently pursuing his Master’s degree in Computer Science at Beijing Institute of Technology under the supervision of Professor Rong-Hua Li. He obtained his Bachelor degree in Computer Science from the same...
Pith/arXiv arXiv 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.