What Should a Skill Remember? Quality--Cost Trade-offs in Cost-Aware Skill Rewriting for Language Model Agents
Pith reviewed 2026-06-27 16:51 UTC · model grok-4.3
The pith
A learned policy for rewriting skills in language model agents reduces total costs by 7 percent and agent token costs by 6 percent while preserving quality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
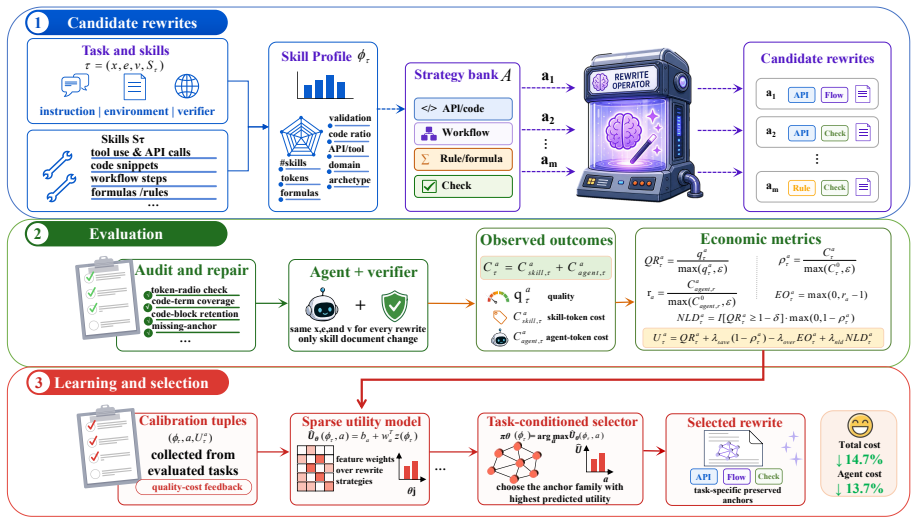
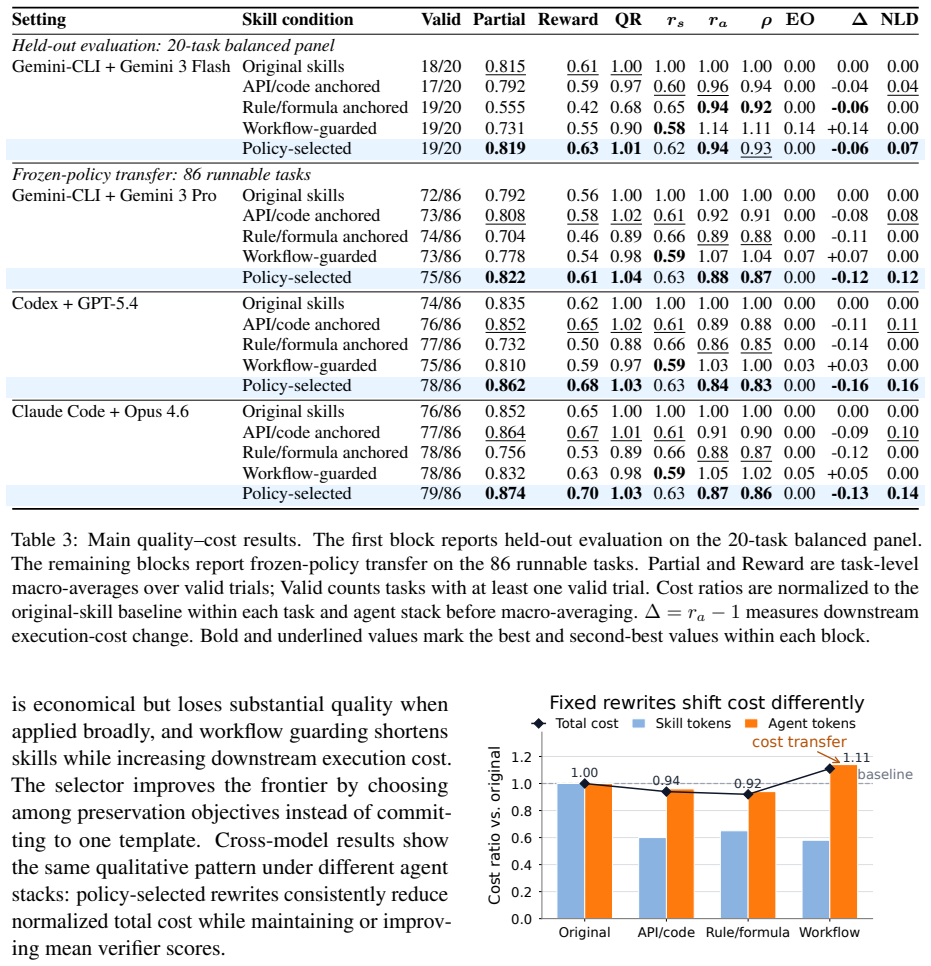
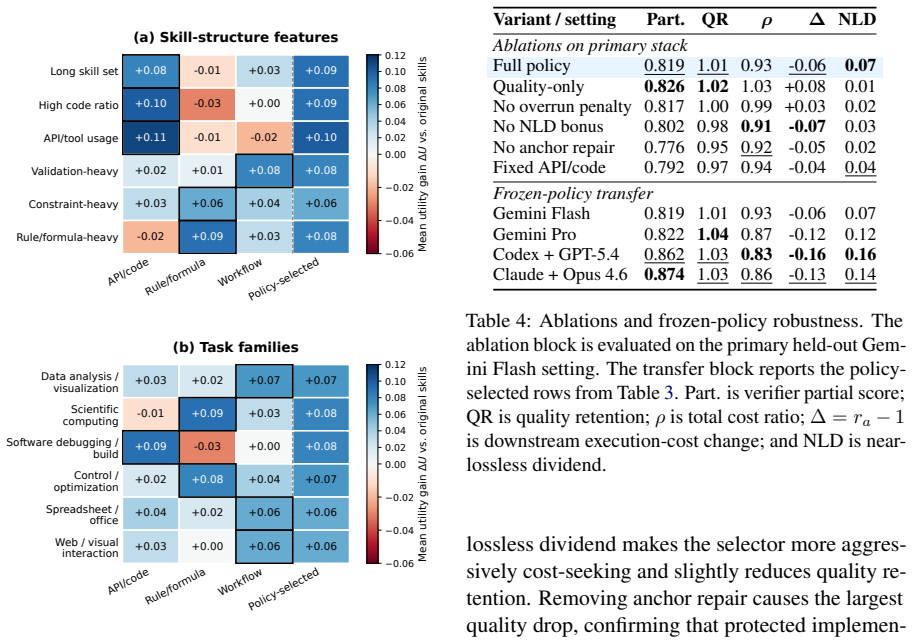
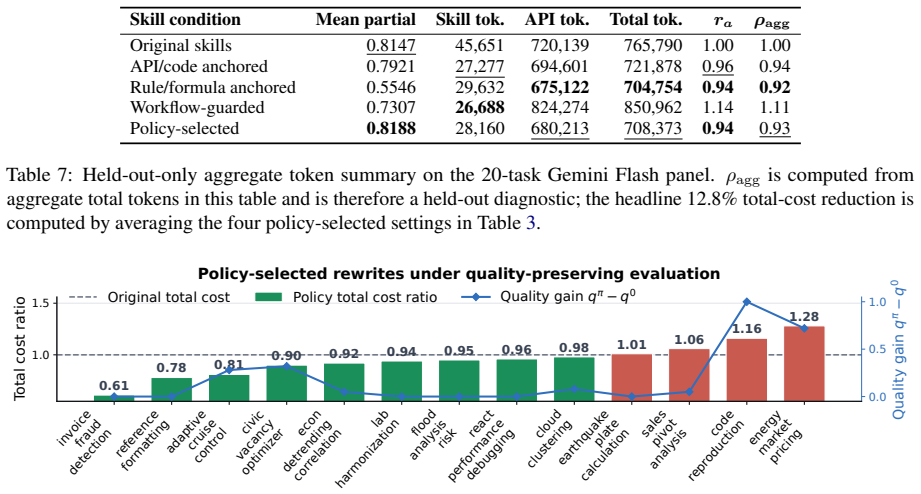
Skill rewriting is studied through an economic lens where shorter skills may raise costs by losing operational anchors. Information-preservation strategies including API/code anchoring, workflow guarding, and rule/formula anchoring produce different quality-cost trade-offs across task families with no single best approach. A learned policy that chooses among these strategies reduces total cost by 7.0 percent and downstream agent-token cost by 6.0 percent in main held-out evaluation, and averages 14.7 percent and 13.7 percent in frozen cross-model transfer, while keeping verifier quality intact.
What carries the argument
The learned policy selecting among information-preservation strategies for skill rewriting under fixed task instructions, environments, and verifiers.
If this is right
- Distinct strategies benefit different task families.
- Skill design functions as cost-aware operational knowledge engineering.
- The policy maintains quality while lowering costs in both held-out and cross-model settings.
- Verifier quality remains preserved alongside cost reductions.
Where Pith is reading between the lines
- Applying similar selection policies to other reusable components in agent systems could yield comparable savings.
- Testing the approach in dynamic real-world environments with changing instructions might reveal additional trade-offs.
- Combining the policy with real-time cost monitoring could enable adaptive skill management during agent execution.
Load-bearing premise
The information-preservation strategies and SkillsBench evaluation accurately capture the quality-cost trade-offs relevant to real-world deployments of LLM agents.
What would settle it
Running the learned policy on a new benchmark with different task families or models and observing no cost reduction or a drop in verifier quality would falsify the claim.
Figures

read the original abstract
Large language model agents increasingly rely on skills: reusable procedural documents encoding workflows, tool use, implementation patterns, validation checks, and domain rules. Skill rewriting is often treated as prompt compression, but shorter skills can make agents more expensive by removing sparse operational anchors that prevent exploration, debugging, and recovery. We study skill rewriting through this economic lens. Our controlled framework profiles skill structure, rewrites skills using information-preservation strategies, and evaluates the rewrites under fixed task instructions, environments, and verifiers. Experiments on SkillsBench reveal distinct quality--cost trade-offs across strategies: API/code anchoring, workflow guarding, and rule/formula anchoring benefit different task families, with no universally dominant template. In the main held-out evaluation, the learned policy reduces total cost by 7.0% and downstream agent-token cost by 6.0%; in frozen cross-model transfer, the corresponding reductions average 14.7% and 13.7%, while verifier quality is preserved. These results position skill design as cost-aware operational knowledge engineering rather than prompt compression. Resources: https://github.com/1Reminding/Skill_EE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper examines skill rewriting for LLM agents not as prompt compression but through a quality-cost lens. It introduces information-preservation strategies (API/code anchoring, workflow guarding, rule/formula anchoring) that retain sparse operational anchors, profiles skill structure, and trains a policy to select rewrites. On SkillsBench, using fixed instructions, environments, and verifiers, the learned policy yields 7.0% total cost and 6.0% downstream agent-token cost reductions in held-out evaluation; frozen cross-model transfer averages 14.7% and 13.7% reductions while verifier quality is preserved. No single strategy dominates; results position skill design as cost-aware operational knowledge engineering. Code is released.
Significance. If the empirical claims hold under rigorous controls, the work usefully reframes skill engineering as an economic optimization problem rather than pure compression, demonstrates strategy-specific trade-offs across task families, and provides evidence that a learned policy can generalize across models. The GitHub release of resources is a clear strength for reproducibility.
major comments (2)
- [Evaluation framework] Evaluation framework (abstract and § on SkillsBench): the claim that 'verifier quality is preserved' while achieving the stated cost reductions rests on fixed verifiers. These verifiers are not shown to exercise the specific failure modes (exploration, debugging, recovery) that the information-preservation strategies target; if they do not, observed savings may mask unmeasured quality loss, directly undermining the central quality-cost trade-off result.
- [Main results] Main results paragraph: the 7.0%/6.0% and 14.7%/13.7% reductions are reported without reference to baselines, training details for the learned policy, statistical significance, error bars, or variance across runs. This absence makes it impossible to verify whether the gains exceed what could be obtained by post-hoc strategy selection or benchmark-specific fitting.
minor comments (1)
- [Abstract] Abstract: the description of the three information-preservation strategies would benefit from one-sentence operational definitions to allow readers to understand the distinctions before the results.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed comments. We address each major point below and will revise the manuscript to incorporate the suggested improvements for greater rigor and clarity.
read point-by-point responses
-
Referee: [Evaluation framework] Evaluation framework (abstract and § on SkillsBench): the claim that 'verifier quality is preserved' while achieving the stated cost reductions rests on fixed verifiers. These verifiers are not shown to exercise the specific failure modes (exploration, debugging, recovery) that the information-preservation strategies target; if they do not, observed savings may mask unmeasured quality loss, directly undermining the central quality-cost trade-off result.
Authors: We agree this is a substantive concern that merits explicit treatment. While the verifiers assess end-to-end task success (which requires the agent to perform exploration, debugging, and recovery when anchors are present), we did not provide a dedicated breakdown of how each verifier exercises these modes. In the revision we will add a new analysis subsection with concrete examples of verifier failures triggered by missing operational anchors, thereby directly linking the information-preservation strategies to the measured quality preservation. revision: yes
-
Referee: [Main results] Main results paragraph: the 7.0%/6.0% and 14.7%/13.7% reductions are reported without reference to baselines, training details for the learned policy, statistical significance, error bars, or variance across runs. This absence makes it impossible to verify whether the gains exceed what could be obtained by post-hoc strategy selection or benchmark-specific fitting.
Authors: We acknowledge that the reported figures require additional context to allow independent verification. The revision will expand the main results section to include (i) explicit baselines such as random strategy selection and oracle post-hoc selection, (ii) full training details and hyperparameters for the learned policy, (iii) statistical significance tests, (iv) error bars, and (v) variance across multiple random seeds. These additions will clarify that the observed gains exceed simpler alternatives. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper reports empirical results from profiling skill structures, applying information-preservation strategies, and evaluating rewrites on SkillsBench using held-out data with fixed instructions, environments, and verifiers. No equations, self-definitional mappings, fitted parameters renamed as independent predictions, or load-bearing self-citations are present in the abstract or description. The learned policy's cost reductions (7.0%/6.0% main, 14.7%/13.7% transfer) are presented as measured outcomes on an external benchmark rather than derived by construction from the inputs. This is a standard empirical ML evaluation setup that remains self-contained against the reported metrics.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2023 , url =
Yao, Shunyu and Zhao, Jeffrey and Yu, Dian and Du, Nan and Shafran, Izhak and Narasimhan, Karthik and Cao, Yuan , booktitle =. 2023 , url =
2023
-
[2]
Advances in Neural Information Processing Systems , year =
Reflexion: Language Agents with Verbal Reinforcement Learning , author =. Advances in Neural Information Processing Systems , year =
-
[3]
2024 , url =
Liu, Xiao and Yu, Hao and Zhang, Hanchen and Xu, Yifan and Lei, Xuanyu and Lai, Hanyu and Gu, Yu and Ding, Hangliang and Men, Kaiwen and Yang, Kejuan and Zhang, Shudan and Deng, Xiang and Zeng, Aohan and Du, Zhengxiao and Zhang, Chenhui and Shen, Sheng and Zhang, Tianjun and Su, Yu and Sun, Huan and Huang, Minlie and Dong, Yuxiao and Tang, Jie , booktitle...
2024
-
[4]
Zhou, Shuyan and Xu, Frank F. and Zhu, Hao and Zhou, Xuhui and Lo, Robert and Sridhar, Abishek and Cheng, Xianyi and Ou, Tianyue and Bisk, Yonatan and Fried, Daniel and Alon, Uri and Neubig, Graham , booktitle =. 2024 , url =
2024
-
[5]
and Yang, John and Wettig, Alexander and Yao, Shunyu and Pei, Kexin and Press, Ofir and Narasimhan, Karthik , booktitle =
Jimenez, Carlos E. and Yang, John and Wettig, Alexander and Yao, Shunyu and Pei, Kexin and Press, Ofir and Narasimhan, Karthik , booktitle =. 2024 , url =
2024
-
[6]
International Conference on Learning Representations , year =
-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains , author =. International Conference on Learning Representations , year =
-
[7]
and Wettig, Alexander and Lieret, Kilian and Yao, Shunyu and Narasimhan, Karthik and Press, Ofir , booktitle =
Yang, John and Jimenez, Carlos E. and Wettig, Alexander and Lieret, Kilian and Yao, Shunyu and Narasimhan, Karthik and Press, Ofir , booktitle =. 2024 , url =
2024
-
[8]
Transactions on Machine Learning Research , year =
Voyager: An Open-Ended Embodied Agent with Large Language Models , author =. Transactions on Machine Learning Research , year =
-
[9]
LLML ingua: Compressing Prompts for Accelerated Inference of Large Language Models
Jiang, Huiqiang and Wu, Qianhui and Lin, Chin-Yew and Yang, Yuqing and Qiu, Lili , booktitle =. 2023 , address =. doi:10.18653/v1/2023.emnlp-main.825 , url =
-
[10]
L ong LLML ingua: Accelerating and Enhancing LLM s in Long Context Scenarios via Prompt Compression
Jiang, Huiqiang and Wu, Qianhui and Luo, Xufang and Li, Dongsheng and Lin, Chin-Yew and Yang, Yuqing and Qiu, Lili , booktitle =. 2024 , address =. doi:10.18653/v1/2024.acl-long.91 , url =
-
[11]
Automatic Prompt Optimization with ``Gradient Descent'' and Beam Search , author =. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages =. 2023 , address =. doi:10.18653/v1/2023.emnlp-main.494 , url =
-
[12]
2023 , url =
Fernando, Chrisantha and Banarse, Dylan Sunil and Michalewski, Henryk and Osindero, Simon and Rockt. 2023 , url =
2023
-
[13]
International Conference on Learning Representations , year =
Khattab, Omar and Singhvi, Arnav and Maheshwari, Paridhi and Zhang, Zhiyuan and Santhanam, Keshav and. International Conference on Learning Representations , year =
-
[14]
Equipping Agents for the Real World with Agent Skills , year =
-
[15]
Skills in ChatGPT , year =
-
[16]
2023 , url =
Schick, Timo and Dwivedi-Yu, Jane and Dessi, Roberto and Raileanu, Roberta and Lomeli, Maria and Hambro, Eric and Zettlemoyer, Luke and Cancedda, Nicola and Scialom, Thomas , booktitle =. 2023 , url =
2023
-
[17]
2024 , url =
Qin, Yujia and Liang, Shihao and Ye, Yining and Zhu, Kunlun and Yan, Lan and Lu, Yaxi and Lin, Yankai and Cong, Xin and Tang, Xiangru and Qian, Bill and Zhao, Sihan and Hong, Lauren and Tian, Runchu and Xie, Ruobing and Zhou, Jie and Gerstein, Mark and Li, Dahai and Liu, Zhiyuan and Sun, Maosong , booktitle =. 2024 , url =
2024
-
[18]
API -Bank: A Comprehensive Benchmark for Tool-Augmented LLM s
Li, Minghao and Zhao, Yingxiu and Yu, Bowen and Song, Feifan and Li, Hangyu and Yu, Haiyang and Li, Zhoujun and Huang, Fei and Li, Yongbin , booktitle =. 2023 , address =. doi:10.18653/v1/2023.emnlp-main.187 , url =
-
[19]
Transactions of the Association for Computational Linguistics , volume =
Lost in the Middle: How Language Models Use Long Contexts , author =. Transactions of the Association for Computational Linguistics , volume =. 2024 , doi =
2024
-
[20]
arXiv preprint arXiv:2602.12430 , year =
Agent Skills for Large Language Models: Architecture, Acquisition, Security, and the Path Forward , author =. arXiv preprint arXiv:2602.12430 , year =
-
[21]
2023 , url =
Chen, Lingjiao and Zaharia, Matei and Zou, James , journal =. 2023 , url =
2023
-
[22]
International Conference on Learning Representations , year =
Large Language Model Cascades with Mixture of Thought Representations for Cost-Efficient Reasoning , author =. International Conference on Learning Representations , year =
-
[23]
International Conference on Learning Representations , year =
In-context Autoencoder for Context Compression in a Large Language Model , author =. International Conference on Learning Representations , year =
-
[24]
2026 , howpublished =
Agent Skills Overview , author =. 2026 , howpublished =
2026
-
[25]
LLML ingua-2: Data Distillation for Efficient and Faithful Task-Agnostic Prompt Compression
Pan, Zhuoshi and Wu, Qianhui and Jiang, Huiqiang and Xia, Menglin and Luo, Xufang and Zhang, Jue and Lin, Qingwei and R. Findings of the Association for Computational Linguistics: ACL 2024 , pages =. 2024 , address =. doi:10.18653/v1/2024.findings-acl.57 , url =
-
[26]
Prompt Compression for Large Language Models: A Survey , author =. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies , pages =. 2025 , address =. doi:10.18653/v1/2025.naacl-long.368 , url =
-
[27]
Cost-Aware Contrastive Routing for
Shirkavand, Reza and Gao, Shangqian and Yu, Peiran and Huang, Heng , journal =. Cost-Aware Contrastive Routing for. 2025 , url =
2025
-
[28]
Reducing Cost of
Xiao, Yuan-An and Gao, Pengfei and Peng, Chao and Xiong, Yingfei , journal =. Reducing Cost of. 2026 , doi =
2026
-
[29]
Jiang, Yanna and Li, Delong and Deng, Haiyu and Ma, Baihe and Wang, Xu and Wang, Qin and Yu, Guangsheng , year =. 2602.20867 , archivePrefix =
-
[30]
Li, Xiangyi and Chen, Wenbo and Liu, Yimin and Zheng, Shenghan and Chen, Xiaokun and He, Yifeng and Li, Yubo and You, Bingran and Shen, Haotian and Sun, Jiankai and Wang, Shuyi and Zeng, Qunhong and Wang, Di and Zhao, Xuandong and Wang, Yuanli and Ben Chaim, Roey and Di, Zonglin and Gao, Yipeng and He, Junwei and He, Yizhuo and Jing, Liqiang and Kong, Luy...
-
[31]
2026 , eprint =
A Comprehensive Survey on Agent Skills: Taxonomy, Techniques, and Applications , author =. 2026 , eprint =
2026
-
[32]
How Well Do Agentic Skills Work in the Wild: Benchmarking
Liu, Yujian and Ji, Jiabao and An, Li and Jaakkola, Tommi and Zhang, Yang and Chang, Shiyu , year =. How Well Do Agentic Skills Work in the Wild: Benchmarking. 2604.04323 , archivePrefix =
-
[33]
Zhong, Shanshan and Lu, Yi and Ning, Jingjie and Wan, Yibing and Feng, Lihan and Ao, Yuyi and Ribeiro, Leonardo F. R. and Dreyer, Markus and Ammirati, Sean and Xiong, Chenyan , year =. 2604.20087 , archivePrefix =
-
[34]
and Kadous, M
Ong, Isaac and Almahairi, Amjad and Wu, Vincent and Chiang, Wei-Lin and Wu, Tianhao and Gonzalez, Joseph E. and Kadous, M. Waleed and Stoica, Ion , booktitle =. 2025 , url =
2025
-
[35]
doi: 10.18653/v1/2023.emnlp-main.391
Compressing Context to Enhance Inference Efficiency of Large Language Models , author =. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages =. 2023 , address =. doi:10.18653/v1/2023.emnlp-main.391 , url =
-
[36]
Yuan, Zhenlong and Qu, Xiangyan and Qian, Chengxuan and Chen, Rui and Tang, Jing and Sun, Lei and Chu, Xiangxiang and Zhang, Dapeng and Wang, Yiwei and Cai, Yujun and Li, Shuo , booktitle =. Video-. 2026 , url =
2026
-
[37]
AutoDrive-
Yuan, Zhenlong and Qian, Chengxuan and Tang, Jing and Chen, Rui and Song, Zijian and Sun, Lei and Chu, Xiangxiang and Cai, Yujun and Zhang, Dapeng and Li, Shuo , booktitle =. AutoDrive-. 2026 , url =
2026
-
[38]
2025 , doi =
Yuan, Zhenlong and Luo, Jinguo and Shen, Fei and Li, Zhaoxin and Liu, Cong and Mao, Tianlu and Wang, Zhaoqi , booktitle =. 2025 , doi =
2025
-
[39]
2024 , doi =
Yuan, Zhenlong and Cao, Jiakai and Wang, Zhaoqi and Li, Zhaoxin , journal =. 2024 , doi =
2024
-
[40]
2024 , doi =
Chen, Yinda and Liu, Che and Liu, Xiaoyu and Arcucci, Rossella and Xiong, Zhiwei , booktitle =. 2024 , doi =
2024
-
[41]
Proceedings of the Thirty-Second International Joint Conference on Artificial Intelligence , pages =
Self-Supervised Neuron Segmentation with Multi-Agent Reinforcement Learning , author =. Proceedings of the Thirty-Second International Joint Conference on Artificial Intelligence , pages =. 2023 , doi =
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.