ArtiFact: A Large-Scale Multi-Modal Cultural Heritage Dataset
Pith reviewed 2026-06-27 14:17 UTC · model grok-4.3
The pith
ArtiFact supplies 651045 museum records as a benchmark where current multi-modal systems fail on subtle cultural errors and ambiguous queries.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
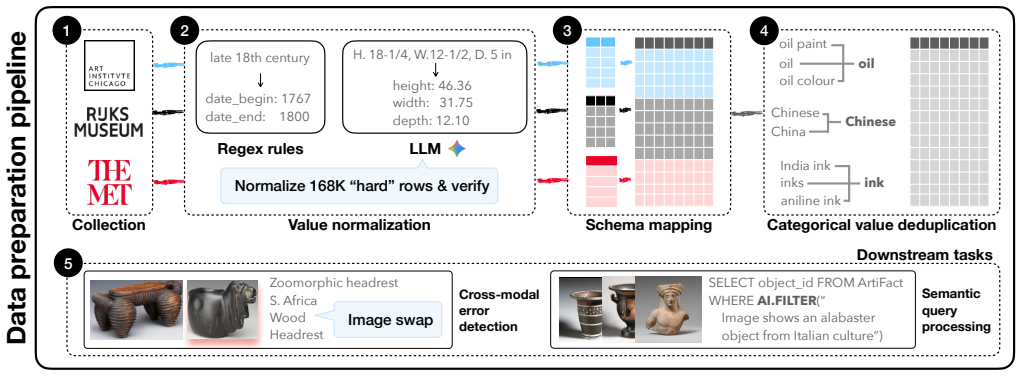
ArtiFact is a multi-modal cultural heritage dataset of 651045 records collected from the Metropolitan Museum of Art, the Art Institute of Chicago, and the Rijksmuseum; when seven categories of errors are injected into 130209 of those records, reliably detecting subtle domain-specific errors such as material anachronisms and temporal shifts remains an open challenge, and current semantic query systems likewise struggle with queries involving cultural proximity, ambiguous object types, and historically contingent terminology.
What carries the argument
The curated taxonomy of seven error categories injected into 130209 records, which is used to evaluate cross-modal error detection on subtle domain-specific inconsistencies.
If this is right
- Multi-modal data integration methods must be extended to handle domain-specific inconsistencies that standard cleaning techniques miss.
- Semantic query processors require additional mechanisms for historical and cultural context when object types or terminology are ambiguous.
- Data quality assessment for heritage collections needs evaluation suites that go beyond generic error models.
Where Pith is reading between the lines
- The dataset could be used to compare new multi-modal architectures against existing ones on a shared, publicly available collection.
- Extending the error taxonomy or adding further museums would allow researchers to test whether the observed difficulties generalize beyond the current scope.
Load-bearing premise
The seven error categories and the way they are injected into the records accurately capture the kinds of subtle, real-world domain-specific errors that occur in cultural heritage collections.
What would settle it
A controlled test in which state-of-the-art multi-modal systems detect all seven injected error types, including material anachronisms and temporal shifts, at high precision and recall across the 130209 records would undermine the claim that detection remains an open challenge.
Figures

read the original abstract
Multi-modal data management has emerged as a central research topic in the database community, spanning data integration, semantic query processing, and data quality assessment. Despite this growing interest, the community lacks large-scale, real-world datasets combining tables, text, and images. We present ArtiFact, a multi-modal cultural heritage dataset of 651045 museum records collected from the Metropolitan Museum of Art, the Art Institute of Chicago, and the Rijksmuseum. We demonstrate the utility of ArtiFact through two downstream tasks. For cross-modal error detection, we introduce a curated taxonomy of seven error categories injected into 130209 records and show that reliably detecting subtle domain-specific errors such as material anachronisms and temporal shifts remain an open challenge. For semantic query processing, we show that current systems struggle with queries involving cultural proximity, ambiguous object types, and historically contingent terminology. Our results position ArtiFact as a challenging benchmark for multi-modal data management research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents ArtiFact, a multi-modal cultural heritage dataset of 651045 museum records sourced from the Metropolitan Museum of Art, the Art Institute of Chicago, and the Rijksmuseum. It demonstrates utility via two tasks: (1) cross-modal error detection using a curated taxonomy of seven error categories injected into 130209 records, where current systems fail on subtle domain-specific errors such as material anachronisms and temporal shifts; and (2) semantic query processing, where systems struggle with cultural proximity, ambiguous object types, and historically contingent terminology. The paper positions ArtiFact as a challenging benchmark for multi-modal data management research.
Significance. A rigorously documented large-scale multi-modal dataset drawn from real museum collections would address a clear gap in resources for database research on data quality, integration, and semantic processing. The reported scale (651045 records, 130209 with injected errors) and multi-institutional sourcing offer potential for reproducible experimentation if construction details and error validation are supplied.
major comments (3)
- [Abstract] Abstract: The central claim that 'reliably detecting subtle domain-specific errors such as material anachronisms and temporal shifts remain an open challenge' depends on the seven-category taxonomy producing errors whose difficulty and prevalence match real museum data, yet no validation (expert review of injected vs. natural errors, comparison to known museum quality reports, or inter-annotator agreement) is described.
- [Abstract] Abstract: The dataset construction is described only at the level of record counts and source institutions; no methods are supplied for collection, multi-modal alignment of tables/text/images, deduplication, or quality control on the full 651045 records, preventing assessment of whether ArtiFact faithfully represents cultural heritage data.
- [Abstract] Abstract: The semantic query processing demonstration states that current systems 'struggle' with specified query types but reports neither quantitative metrics, baselines, nor task definitions, so the strength of this supporting evidence for the benchmark claim cannot be evaluated.
minor comments (1)
- [Abstract] The abstract would benefit from explicit numerical results (e.g., precision/recall on error detection or query success rates) rather than qualitative statements alone.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We will revise the abstract to better convey the supporting details from the full manuscript while preserving its brevity. Below we respond to each major comment.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'reliably detecting subtle domain-specific errors such as material anachronisms and temporal shifts remain an open challenge' depends on the seven-category taxonomy producing errors whose difficulty and prevalence match real museum data, yet no validation (expert review of injected vs. natural errors, comparison to known museum quality reports, or inter-annotator agreement) is described.
Authors: The taxonomy was developed through iterative consultation with curators at the three source museums to reflect documented data-quality issues in cultural-heritage collections. While a formal inter-annotator study comparing injected versus naturally occurring errors was not conducted for this release, the categories align with published museum quality reports. We will revise the abstract to state the expert-curation basis and add a short paragraph in the main text describing the taxonomy development process. revision: yes
-
Referee: [Abstract] Abstract: The dataset construction is described only at the level of record counts and source institutions; no methods are supplied for collection, multi-modal alignment of tables/text/images, deduplication, or quality control on the full 651045 records, preventing assessment of whether ArtiFact faithfully represents cultural heritage data.
Authors: Section 3 of the full manuscript details the collection pipeline (REST API queries per institution), multi-modal alignment via persistent object identifiers, deduplication using unique IDs plus title+date fuzzy matching, and quality-control steps including schema conformance and image-availability checks. We will expand the abstract with a one-sentence summary of these steps and ensure the section heading is referenced. revision: yes
-
Referee: [Abstract] Abstract: The semantic query processing demonstration states that current systems 'struggle' with specified query types but reports neither quantitative metrics, baselines, nor task definitions, so the strength of this supporting evidence for the benchmark claim cannot be evaluated.
Authors: Section 5 defines the semantic-query task (500 hand-crafted queries across the three difficulty axes), specifies the evaluation protocol, and reports precision@10 and recall@10 for two baseline retrievers. We will revise the abstract to include the key quantitative result and a pointer to the task definition. revision: yes
Circularity Check
No circularity: dataset construction and task demonstration paper with no derivations or predictions
full rationale
The paper presents a collected multi-modal dataset from public museum sources and demonstrates two tasks via error injection and query examples. No equations, fitted parameters, predictions, or derivation chains exist. The taxonomy of error categories is presented as a curation choice for the benchmark, not derived from or equivalent to the observed results. No self-citations are load-bearing for any claim. The construction is self-contained as a resource paper; failure of external systems on the injected errors is reported as an empirical observation rather than a constructed equivalence.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The 651045 records collected from the three museums form a representative sample of multi-modal cultural heritage data suitable for benchmarking.
- domain assumption The seven error categories and their injection into 130209 records constitute a valid test of subtle domain-specific errors.
Reference graph
Works this paper leans on
-
[1]
Ilyas, Mourad Ouzzani, Paolo Papotti, Michael Stonebraker, and Nan Tang
Ziawasch Abedjan, Xu Chu, Dong Deng, Raul Castro Fernandez, Ihab F. Ilyas, Mourad Ouzzani, Paolo Papotti, Michael Stonebraker, and Nan Tang. 2016. De- tecting Data Errors: Where are we and what needs to be done?Proceedings of the VLDB Endowment9, 12 (2016)
2016
-
[2]
Art Institute of Chicago. 2025. Art Institute of Chicago API. https://api.artic. edu/docs/
2025
-
[3]
Xu Chu, Ihab F Ilyas, and Paolo Papotti. 2013. Discovering denial constraints. Proceedings of the VLDB Endowment6, 13 (2013), 1498–1509
2013
-
[4]
JSON-LD format. [n. d.]. JSON for Linking Data. https://json-ld.org
-
[5]
Noa Garcia and George Vogiatzis. 2018. How to Read Paintings: Semantic Art Understanding with Multi-Modal Retrieval. arXiv:1810.09617 [cs.CV] https: //arxiv.org/abs/1810.09617
Pith/arXiv arXiv 2018
-
[6]
Antonios Georgakopoulos, Paul Groth, and Lise Stork. 2026. Ranking-Guided Autoregressive Modeling for Multimodal Tabular Anomaly Detection. (2026)
2026
-
[7]
Sara Ghaboura, Ketan More, Ritesh Thawkar, Wafa Alghallabi, Omkar Thawakar, Fahad Shahbaz Khan, Hisham Cholakkal, Salman Khan, and Rao Muhammad Anwer. 2025. Time Travel: A Comprehensive Benchmark to Evaluate LMMs on Historical and Cultural Artifacts. arXiv:2502.14865 [cs.CV] https://arxiv.org/ abs/2502.14865
arXiv 2025
-
[8]
Amirata Ghorbani and James Zou. 2019. Data shapley: Equitable valuation of data for machine learning. InInternational conference on machine learning. PMLR, 2242–2251
2019
-
[9]
Hang Hua, Jing Shi, Kushal Kafle, Simon Jenni, Daoan Zhang, John Collomosse, Scott Cohen, and Jiebo Luo. 2024. FineMatch: Aspect-Based Fine-Grained Image and Text Mismatch Detection and Correction. InComputer Vision – ECCV 2024: 18th European Conference, Milan, Italy, September 29–October 4, 2024, Proceedings, Part IX(Milan, Italy). Springer-Verlag, Berli...
2024
-
[10]
IIIF Consortium. 2025. International Image Interoperability Framework. https: //iiif.io/
2025
-
[11]
Sebastian Jäger and Felix Biessmann. 2024. From Data Imputation to Data Clean- ing — Automated Cleaning of Tabular Data Improves Downstream Predictive Performance. InProceedings of The 27th International Conference on Artificial Intelligence and Statistics (Proceedings of Machine Learning Research, Vol. 238), Sanjoy Dasgupta, Stephan Mandt, and Yingzhen L...
2024
-
[12]
Shixin Jiang, Jiafeng Liang, Jiyuan Wang, Xuan Dong, Heng Chang, Weijiang Yu, Jinhua Du, Ming Liu, and Bing Qin. 2025. From Specific-MLLMs to Omni- MLLMs: A Survey on MLLMs Aligned with Multi-modalities. InFindings of the Association for Computational Linguistics: ACL 2025, Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar (Eds.)...
-
[13]
Saehan Jo and Immanuel Trummer. 2024. ThalamusDB: Approximate Query Processing on Multi-Modal Data.Proc. ACM Manag. Data2, 3 (2024), 186. doi:10. 1145/3654989
2024
-
[14]
Bojan Karlaš, David Dao, Matteo Interlandi, Sebastian Schelter, Wentao Wu, and Ce Zhang. 2023. Data Debugging with Shapley Importance over Machine Learning Pipelines. InThe Twelfth International Conference on Learning Repre- sentations
2023
-
[15]
Barrie Kersbergen, Olivier Sprangers, Bojan Karlaš, Maarten de Rijke, and Se- bastian Schelter. 2025. Scalable Data Debugging for Neighborhood-based Rec- ommendation with Data Shapley Values. InProceedings of the Nineteenth ACM Conference on Recommender Systems (RecSys ’25). Association for Computing Machinery, New York, NY, USA, 441–450. doi:10.1145/3705...
-
[16]
Sanjay Krishnan, Jiannan Wang, Eugene Wu, Michael J. Franklin, and Ken Gold- berg. 2016. ActiveClean: interactive data cleaning for statistical modeling.Proc. VLDB Endow.9, 12 (Aug. 2016), 948–959. doi:10.14778/2994509.2994514
-
[17]
2002.The Open Archives Initiative Protocol for Metadata Harvesting
Carl Lagoze, Herbert Van de Sompel, Michael Nelson, and Simeon Warner. 2002.The Open Archives Initiative Protocol for Metadata Harvesting. Tech- nical Report. Open Archives Initiative. http://www.openarchives.org/OAI/ openarchivesprotocol.html
2002
-
[18]
Jiale Lao, Andreas Zimmerer, Olga Ovcharenko, Tianji Cong, Matthew Russo, Gerardo Vitagliano, Michael Cochez, Fatma Özcan, Gautam Gupta, Thibaud Hottelier, H. V. Jagadish, Kris Kissel, Sebastian Schelter, Andreas Kipf, and Im- manuel Trummer. 2025. SemBench: A Benchmark for Semantic Query Processing Engines. arXiv:2511.01716 [cs.DB] https://arxiv.org/abs/...
arXiv 2025
-
[19]
Chunwei Liu, Matthew Russo, Michael Cafarella, Lei Cao, Peter Baile Chen, Zui Chen, Michael Franklin, Tim Kraska, Samuel Madden, Rana Shahout, and Gerardo Vitagliano. 2025. Palimpzest: Optimizing AI-Powered Analytics with Declarative Query Processing. InProceedings of the Conference on Innovative Database Research (CIDR)(2025)
2025
-
[20]
Mohammad Mahdavi and Ziawasch Abedjan. 2020. Baran: Effective error cor- rection via a unified context representation and transfer learning.Proceedings of the VLDB Endowment (PVLDB)13, 11 (2020), 1948–1961
2020
-
[21]
Mohammad Mahdavi, Ziawasch Abedjan, Raul Castro Fernandez, Samuel Mad- den, Mourad Ouzzani, Michael Stonebraker, and Nan Tang. 2019. Raha: A Configuration-Free Error Detection System. InProceedings of the 2019 Inter- national Conference on Management of Data (SIGMOD ’19). 865–882
2019
-
[22]
Arijit Maji, Raghvendra Kumar, Akash Ghosh, et al. 2025. DRISHTIKON: A Mul- timodal Multilingual Benchmark for Testing Language Models’ Understanding on Indian Culture. arXiv:2509.19274 [cs.CL] https://arxiv.org/abs/2509.19274
arXiv 2025
-
[23]
Curtis Northcutt, Lu Jiang, and Isaac Chuang. 2021. Confident learning: Esti- mating uncertainty in dataset labels.Journal of Artificial Intelligence Research70 (2021), 1373–1411
2021
-
[24]
Curtis G Northcutt, Anish Athalye, and Jonas Mueller. 2021. Pervasive label errors in test sets destabilize machine learning benchmarks.NeurIPS(2021)
2021
-
[25]
Northcutt, Lu Jiang, and Isaac L
Curtis G. Northcutt, Lu Jiang, and Isaac L. Chuang. 2021. Confident Learning: Es- timating Uncertainty in Dataset Labels.Journal of Artificial Intelligence Research (JAIR)70 (2021), 1373–1411
2021
-
[26]
The Metropolitan Museum of Art. 2025. Female musician with harp. https: //www.metmuseum.org/art/collection/search/44804
2025
-
[27]
The Metropolitan Museum of Art. 2025. Seated Musician. https://www. metmuseum.org/art/collection/search/73218
2025
-
[28]
Olga Ovcharenko, Matthias Boehm, and Sebastian Schelter. 2026. SemPipes – Optimizable Semantic Data Operators for Tabular Machine Learning Pipelines. arXiv:2602.05134 [cs.LG] https://arxiv.org/abs/2602.05134
arXiv 2026
-
[29]
Olga Ovcharenko and Sebastian Schelter. 2025. Towards Cross-Modal Error Detection with Tables and Images. arXiv:2510.12383 [cs.LG] https://arxiv.org/ abs/2510.12383
arXiv 2025
-
[30]
Liana Patel, Siddharth Jha, Melissa Pan, Harshit Gupta, Parth Asawa, Carlos Guestrin, and Matei Zaharia. 2025. Semantic Operators and Their Optimization: Enabling LLM-Based Data Processing with Accuracy Guarantees in LOTUS.Proc. VLDB Endow.18, 11 (July 2025), 4171–4184. doi:10.14778/3749646.3749685
-
[31]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandeep Agarwal, Girish Sastry, Amanda Askell, Pami Mishkin, Jack Clark, et al
-
[32]
arXiv:2103.00020 [cs.CV] https://arxiv.org/abs/2103.00020
Learning Transferable Visual Models from Natural Language Supervision. arXiv:2103.00020 [cs.CV] https://arxiv.org/abs/2103.00020
-
[33]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. 2021. Learning Transferable Visual Models From Natural Language Supervision. InProceedings of the 38th In- ternational Conference on Machine Learning (Proceedings of Machi...
2021
-
[34]
Luis Rei, Dunja Mladenic, Mareike Dorozynski, Franz Rottensteiner, Thomas Schleider, Raphaël Troncy, Jorge Sebastián Lozano, and Mar Gaitán Salvatella
-
[35]
Multimodal metadata assignment for cultural heritage artifacts.Multimedia Systems29, 2 (Nov. 2022), 847–869. doi:10.1007/s00530-022-01025-2
-
[36]
Ilyas, and Christopher Ré
Theodoros Rekatsinas, Xu Chu, Ihab F. Ilyas, and Christopher Ré
-
[37]
arXiv:1702.00820 [cs.DB] https://arxiv.org/abs/1702.00820
HoloClean: Holistic Data Repairs with Probabilistic Inference. arXiv:1702.00820 [cs.DB] https://arxiv.org/abs/1702.00820
-
[38]
Rijksmuseum. 2025. Rijksmuseum API. https://data.rijksmuseum.nl/
2025
-
[39]
Sebastian Schelter, Dustin Lange, Philipp Schmidt, Meltem Celikel, Felix Biess- mann, and Andreas Grafberger. 2018. Automating large-scale data quality verifi- cation.Proc. VLDB Endow.11, 12 (Aug. 2018), 1781–1794. doi:10.14778/3229863. 3229867
-
[40]
Bhuiyan Sanjid Shafique, Ashmal Vayani, Muhammad Maaz, et al. 2025. ViMUL- Bench: A Culturally-diverse Multilingual Multimodal Video Benchmark & Model. arXiv:2506.07032 [cs.CL] https://arxiv.org/abs/2506.07032
arXiv 2025
-
[41]
Mukul Singh, José Cambronero, Sumit Gulwani, Vu Le, Carina Negreanu, Arjun Radhakrishna, and Gust Verbruggen. 2025. DataVinci: Learning Syntactic and Semantic String Repairs.Proc. ACM Manag. Data3, 1, Article 27 (Feb. 2025), 26 pages. doi:10.1145/3709677
-
[42]
Gjorgji Strezoski and Marcel Worring. 2017. OmniArt: Multi-task Deep Learning for Artistic Data Analysis. arXiv:1708.00684 [cs.MM] https://arxiv.org/abs/1708. 00684
Pith/arXiv arXiv 2017
-
[43]
The Metropolitan Museum of Art. 2025. The Met Open Access API. https: //metmuseum.github.io/
2025
-
[44]
Matthias Urban and Carsten Binnig. 2024. ELEET: Efficient Learned Query Execution over Text and Tables.Proc. VLDB Endow.17, 13 (Sept. 2024), 4867–4880. doi:10.14778/3704965.3704989
-
[45]
Ashmal Vayani, Dinura Dissanayake, Hasindri Watawana, et al. 2025. All Lan- guages Matter: Evaluating LMMs on Culturally Diverse 100 Languages. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). arXiv:2411.16508 [cs.CV] https://arxiv.org/abs/2411.16508
arXiv 2025
-
[46]
Jiachen T Wang and Ruoxi Jia. 2023. Data banzhaf: A robust data valuation frame- work for machine learning. InInternational Conference on Artificial Intelligence and Statistics. PMLR, 6388–6421
2023
-
[47]
Steven Euijong Whang, Yuji Roh, Hwanjun Song, and Jae-Gil Lee. 2023. Data collection and quality challenges in deep learning: a data-centric AI perspective. The VLDB Journal32, 4 (Jan. 2023), 791–813. doi:10.1007/s00778-022-00775-9 5
-
[48]
Moritz Wilke and Erhard Rahm. 2021. Towards Multi-Modal Entity Resolution for Product Matching. InGvDB. https://api.semanticscholar.org/CorpusID: 235222280
2021
-
[49]
Qianqi Yan, Yue Fan, Hongquan Li, Shan Jiang, Yang Zhao, Xinze Guan, Ching-Chen Kuo, and Xin Eric Wang. 2025. Multimodal Inconsistency Reasoning (MMIR): A New Benchmark for Multimodal Reasoning Models. arXiv:2502.16033 [cs.CL] https://arxiv.org/abs/2502.16033
arXiv 2025
-
[50]
Xiang Yue, Tianyu Zheng, Yuansheng Ni, Yubo Wang, Kai Zhang, Shengbang Tong, Yuxuan Sun, Botao Yu, Ge Zhang, Huan Sun, Yu Su, Wenhu Chen, Graham Neubig, and MMMU Team. 2025. MMMU-Pro: A More Robust Multi-discipline Multimodal Understanding Benchmark. arXiv:2409.02813 [cs.CL]
Pith/arXiv arXiv 2025
-
[51]
Haoran Zhang, Aparna Balagopalan, Nassim Oufattole, Hyewon Jeong, Yan Wu, Jiacheng Zhu, and Marzyeh Ghassemi. 2024. LEMoN: Label Error Detection using Multimodal Neighbors. arXiv:2407.18941 [cs.CV] https://arxiv.org/abs/ 2407.18941
arXiv 2024
-
[52]
Jian Zhang, Junyi Guo, Junyi Yuan, Huanda Lu, Yanlin Zhou, Fangyu Wu, Qiufeng Wang, and Dongming Lu. 2025. LLM-Driven Completeness and Consistency Evaluation for Cultural Heritage Data Augmentation in Cross-Modal Retrieval. InProceedings of the 2025 Annual Conference of the Nations of the Association for Computational Linguistics (ACL)
2025
-
[53]
Zihao Zhu, Mingda Zhang, Shaokui Wei, Bingzhe Wu, and Baoyuan Wu. 2024. VDC: Versatile Data Cleanser based on Visual-Linguistic Inconsistency by Multi- modal Large Language Models. arXiv:2309.16211 [cs.CV] https://arxiv.org/abs/ 2309.16211 6
arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.