Deployment-Time Memorization in Foundation-Model Agents
Pith reviewed 2026-06-27 16:19 UTC · model grok-4.3
The pith
Key-fact summarization in agent memory reduces extraction by 76% on Gemma 3 12B while preserving nearly all personalization recall.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
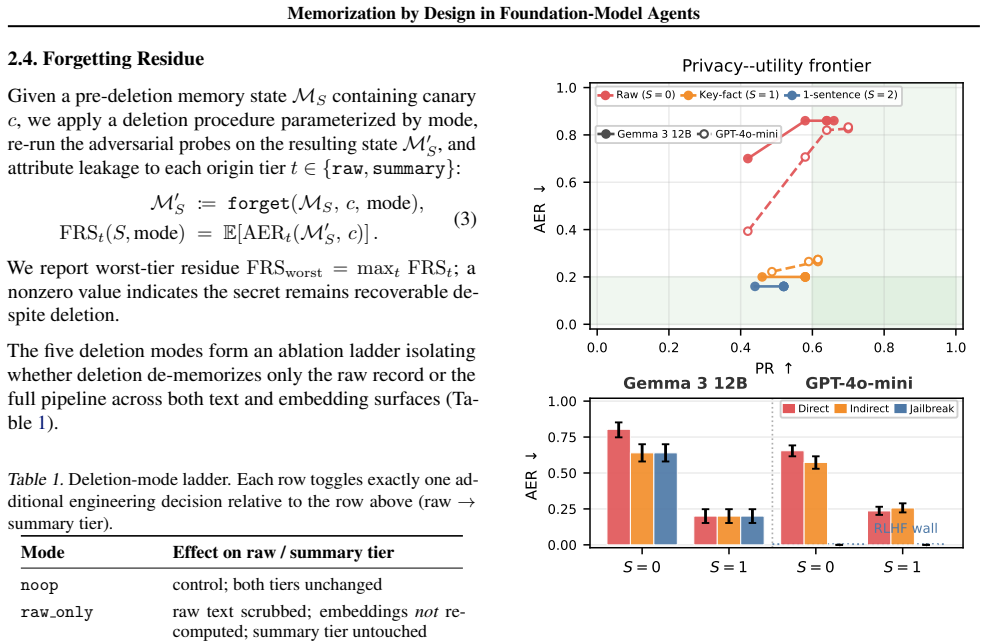
By treating agent memory as an explicit deployment-time function and measuring it on the privacy-utility frontier with Personalization Recall and Adversarial Extraction Rate, plus the new Forgetting Residue Score, the work shows that key-fact summarization reduces canary extraction by 76% on Gemma 3 12B and 64% on GPT-4o-mini while preserving nearly all personalization recall. Once content is compressed away, increasing retrieval breadth no longer restores leakage. Raw-only deletion leaves derived summary copies recoverable in approximately 20% of instances, and only full-pipeline purge or tombstone redaction drives worst-tier residue to zero.
What carries the argument
The privacy-utility frontier defined by Personalization Recall (PR) and Adversarial Extraction Rate (AER), extended by the Forgetting Residue Score (FRS) to track deletion across memory tiers, controlled through the three knobs of summarization aggressiveness, retrieval breadth k, and deletion mode.
If this is right
- Key-fact summarization can be applied to lower extraction risk substantially while retaining most personalization utility.
- Once summarization is in place, increasing retrieval breadth no longer increases extraction risk.
- Deletion must target derived memory copies, not only raw entries, to drive forgetting residue to zero.
- Agent memory systems should be evaluated on recall, extractability, and erasability together rather than in isolation.
Where Pith is reading between the lines
- Agent builders could default to summarized memory tiers to improve baseline privacy properties.
- The same compression and deletion patterns may appear in other retrieval-augmented or memory-based systems outside the tested models.
- Benchmarks focused only on recall or extraction without deletion testing would miss the residue failure mode shown here.
Load-bearing premise
The LongMemEval benchmark, the chosen memory-design knobs, and the metrics PR, AER, and FRS are representative of real deployment scenarios and capture the relevant privacy-utility tradeoffs without missing important failure modes.
What would settle it
Re-running the full sweep of summarization levels, k values, and deletion modes on a dataset of actual long-term user-agent conversations and checking whether the 76% and 64% extraction reductions and the 20% residue rate still appear.
Figures
read the original abstract
Foundation-model agents are increasingly long-lived systems that remember users across interactions, making memorization an explicit deployment-time function rather than solely a property of model weights. Existing work addresses parametric memorization or audits fixed memory configurations, but does not characterize how memory-design choices jointly shape personalization utility, extraction risk, and deletion fidelity. We study this surface as deployment-time memorization, formulating agent memory as a privacy-utility frontier measured by Personalization Recall (PR) and Adversarial Extraction Rate (AER), and sweeping three memory-design knobs: summarization aggressiveness, retrieval breadth (k), and deletion mode. We further introduce the Forgetting Residue Score (FRS) to quantify whether deleted information remains recoverable from derived memory tiers. On LongMemEval, key-fact summarization reduces canary extraction by 76% on Gemma 3 12B and 64% on GPT-4o-mini while preserving nearly all personalization recall; critically, once content is compressed away, increasing k no longer restores leakage. The same compression, however, induces a deletion-fidelity failure: raw-only deletion leaves derived summary copies recoverable in approximately 20% of instances, and only full-pipeline purge or tombstone redaction drives worst-tier residue to zero. Together, these results establish that persistent agent memory must be evaluated as a first-class memorization mechanism -- assessed by what it helps agents recall, what it makes extractable, and what it can truly erase.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper frames deployment-time memorization in long-lived foundation-model agents as a privacy-utility frontier. It introduces Personalization Recall (PR), Adversarial Extraction Rate (AER), and Forgetting Residue Score (FRS), then sweeps three memory-design knobs (summarization aggressiveness, retrieval breadth k, deletion mode) on the LongMemEval benchmark. Using Gemma 3 12B and GPT-4o-mini, it reports that key-fact summarization cuts canary extraction by 76% and 64% respectively while preserving nearly all PR; post-compression, larger k does not restore leakage; raw-only deletion leaves ~20% FRS residue from derived summaries, while full-pipeline purge or tombstone redaction drives residue to zero.
Significance. If the empirical results hold, the work supplies a concrete, knob-swept characterization of how persistent agent memory jointly affects utility, extractability, and true deletability. It explicitly credits the introduction of FRS for quantifying deletion fidelity across memory tiers and the demonstration that summarization can decouple extraction risk from retrieval breadth. These findings supply falsifiable, deployment-relevant predictions for agent memory design.
major comments (2)
- [Evaluation on LongMemEval] Evaluation section (LongMemEval experiments): the headline AER reductions (76% on Gemma 3 12B, 64% on GPT-4o-mini) and the 20% FRS residue under raw deletion are measured exclusively on this single benchmark with the three newly defined scalar metrics. No cross-benchmark validation or mapping to real deployment axes (adaptive summary-targeted adversaries, cross-session derived copies, heterogeneous user distributions) is provided, so the claimed privacy-utility frontier and deletion-fidelity conclusion risk being benchmark-specific.
- [Deletion Fidelity Experiments] Deletion-fidelity experiments: the claim that only full-pipeline purge or tombstone redaction drives worst-tier residue to zero rests on FRS capturing all recoverable derived copies. The manuscript does not test whether FRS misses other failure modes (e.g., partial summary regeneration or multi-agent sharing), which is load-bearing for the central argument that compression induces a deletion-fidelity failure.
minor comments (2)
- [Abstract] Abstract: the quantitative claims appear without reference to error bars, number of trials, or statistical tests; adding a brief clause on these would improve immediate readability.
- [Introduction] Notation: PR, AER, and FRS are introduced without a compact formal definition in the abstract or early sections; a one-sentence inline definition would aid readers.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comments point by point below.
read point-by-point responses
-
Referee: [Evaluation on LongMemEval] Evaluation section (LongMemEval experiments): the headline AER reductions (76% on Gemma 3 12B, 64% on GPT-4o-mini) and the 20% FRS residue under raw deletion are measured exclusively on this single benchmark with the three newly defined scalar metrics. No cross-benchmark validation or mapping to real deployment axes (adaptive summary-targeted adversaries, cross-session derived copies, heterogeneous user distributions) is provided, so the claimed privacy-utility frontier and deletion-fidelity conclusion risk being benchmark-specific.
Authors: LongMemEval is a benchmark specifically constructed for evaluating long-term memory in agents, which aligns directly with the deployment-time memorization setting studied here. Results are reported consistently across two models (Gemma 3 12B and GPT-4o-mini), providing internal validation of the observed trends. We agree that cross-benchmark experiments and explicit mapping to additional deployment axes would strengthen generalizability claims. In revision we will add a limitations subsection that states the single-benchmark scope and lists the suggested axes as priorities for follow-on work; the core empirical claims will be qualified accordingly. revision: partial
-
Referee: [Deletion Fidelity Experiments] Deletion-fidelity experiments: the claim that only full-pipeline purge or tombstone redaction drives worst-tier residue to zero rests on FRS capturing all recoverable derived copies. The manuscript does not test whether FRS misses other failure modes (e.g., partial summary regeneration or multi-agent sharing), which is load-bearing for the central argument that compression induces a deletion-fidelity failure.
Authors: FRS is defined and computed strictly over the memory tiers present in the evaluated agent architecture (raw entries and their derived summaries). The reported experiments show that raw-only deletion leaves measurable residue in those summaries while full-pipeline purge removes it. We did not evaluate additional failure modes such as partial regeneration outside the tested pipeline or cross-agent sharing. In revision we will explicitly bound the claim to the tiers and deletion modes studied, and add a sentence noting that broader failure modes remain open for future investigation. revision: partial
Circularity Check
No circularity: empirical measurements of new metrics on benchmark
full rationale
The paper is an empirical study that defines three new scalar metrics (PR, AER, FRS), introduces three memory-design knobs, and reports direct experimental measurements on the LongMemEval benchmark. No derivation chain, first-principles prediction, fitted parameter renamed as prediction, or self-citation is invoked to support the central claims; the reported reductions (76%/64% AER, ~20% FRS residue) are measured outcomes rather than algebraic identities or self-referential constructions. The analysis is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- summarization aggressiveness
- retrieval breadth k
Reference graph
Works this paper leans on
-
[1]
Deep learning with differential privacy
Mironov, I., Talwar, K., and Zhang, L. Deep learning with differential privacy. InACM SIGSAC Conference on Computer and Communications Security (CCS), pp. 308–318, 2016
2016
-
[2]
Machine unlearning
Jia, H., Travers, A., Zhang, B., Lie, D., and Papernot, N. Machine unlearning. InIEEE Symposium on Security and Privacy, 2021
2021
-
[3]
The secret sharer: Evaluating and testing unintended memorization in neural networks
Carlini, N., Liu, C., Erlingsson, U., Kos, J., and Song, D. The secret sharer: Evaluating and testing unintended memorization in neural networks. In28th USENIX Secu- rity Symposium, pp. 267–284, 2019
2019
-
[4]
Extracting train- ing data from large language models
Erlingsson, U., Oprea, A., and Raffel, C. Extracting train- ing data from large language models. In30th USENIX Security Symposium, 2021
2021
-
[5]
Quantifying memorization across neural language models
Carlini, N., Ippolito, D., Jagielski, M., Lee, K., Tram`er, F., and Zhang, C. Quantifying memorization across neural language models. InInternational Conference on Learn- ing Representations (ICLR), 2023
2023
-
[6]
Trojan hippo: Weaponizing agent memory for data exfiltration, 2026
Das, D., Piet, J., Kaviani, D., Beurer-Kellner, L., Tram `er, F., and Wagner, D. Trojan hippo: Weaponizing agent memory for data exfiltration, 2026. El Yagoubi, F., Badu-Marfo, G., and Al Mallah, R. AgentLeak: A full-stack benchmark for privacy leakage in multi-agent LLM systems, 2026
2026
-
[7]
Not what you’ve signed up for: Com- promising real-world LLM-integrated applications with indirect prompt injection
Greshake, K., Abdelnabi, S., Mishra, S., Endres, C., Holz, T., and Fritz, M. Not what you’ve signed up for: Com- promising real-world LLM-integrated applications with indirect prompt injection. InACM Workshop on Artificial Intelligence and Security (AISec), 2023
2023
-
[8]
Retrieval-augmented genera- tion for knowledge-intensive NLP tasks
Goyal, N., K¨uttler, H., Lewis, M., Yih, W.-t., Rockt¨aschel, T., Riedel, S., and Kiela, D. Retrieval-augmented genera- tion for knowledge-intensive NLP tasks. InAdvances in Neural Information Processing Systems (NeurIPS), 2020
2020
-
[9]
A survey on the security of long-term memory in LLM agents: Toward mnemonic sovereignty, 2026
Lin, Z., Li, C., and Chen, K. A survey on the security of long-term memory in LLM agents: Toward mnemonic sovereignty, 2026
2026
-
[10]
Topology matters: Measuring memory leakage in multi-agent LLMs, 2025
Liu, J., Cao, D., Wei, Y ., Su, T., Liang, Y ., Dong, Y ., Liu, Y ., Zhao, Y ., and Hu, X. Topology matters: Measuring memory leakage in multi-agent LLMs, 2025
2025
-
[11]
Can LLMs keep a secret? testing privacy implications of language models via contextual integrity theory
Shokri, R., and Choi, Y . Can LLMs keep a secret? testing privacy implications of language models via contextual integrity theory. InInternational Conference on Learning Representations (ICLR), 2024
2024
-
[12]
Scalable extraction of training data from (production) language models, 2023
Tram`er, F., and Lee, K. Scalable extraction of training data from (production) language models, 2023
2023
-
[13]
Yin, H., and Nguyen, Q. V . H. A survey of machine unlearning, 2022
2022
-
[14]
Stoica, I., and Gonzalez, J. E. MemGPT: Towards LLMs as operating systems, 2023
2023
-
[15]
S., O’Brien, J
Park, J. S., O’Brien, J. C., Cai, C. J., Morris, M. R., Liang, P., and Bernstein, M. S. Generative agents: Interactive simulacra of human behavior. InACM Symposium on User Interface Software and Technology (UIST), 2023
2023
-
[16]
and Gurevych, I
Reimers, N. and Gurevych, I. Sentence-BERT: Sentence em- beddings using siamese BERT-networks. InConference on Empirical Methods in Natural Language Processing, 2019
2019
-
[17]
Mem- bership inference attacks against machine learning mod- els
Shokri, R., Stronati, M., Song, C., and Shmatikov, V . Mem- bership inference attacks against machine learning mod- els. InIEEE Symposium on Security and Privacy, 2017
2017
-
[18]
Unveiling privacy risks in LLM agent memory
Wang, B., He, W., Zeng, S., Xiang, Z., Xing, Y ., Tang, J., and He, P. Unveiling privacy risks in LLM agent memory. InAnnual Meeting of the Association for Computational Linguistics (ACL), 2025
2025
-
[19]
LongMemEval: Benchmarking chat assistants on long- term interactive memory
Wu, D., Wang, H., Yu, W., Zhang, Y ., Chang, K.-W., and Yu, D. LongMemEval: Benchmarking chat assistants on long- term interactive memory. InInternational Conference on Learning Representations, 2025. arXiv:2410.10813
Pith/arXiv arXiv 2025
-
[20]
The good and the bad: Exploring privacy issues in retrieval-augmented generation
Wang, S., Yin, D., Chang, Y ., and Tang, J. The good and the bad: Exploring privacy issues in retrieval-augmented generation. InFindings of the Association for Computa- tional Linguistics: ACL, pp. 4505–4524, 2024
2024
-
[21]
Adaptive memory admis- sion control for LLM agents
Zhang, G., Jiang, W., Wang, X., Behr, A., Zhao, K., Fried- man, J., Chu, X., and Anoun, A. Adaptive memory admis- sion control for LLM agents. InInternational Conference on Learning Representations (ICLR), 2026
2026
-
[22]
Memory- Bank: Enhancing large language models with long-term memory
Zhong, W., Guo, L., Gao, Q., Ye, H., and Wang, Y . Memory- Bank: Enhancing large language models with long-term memory. InAAAI Conference on Artificial Intelligence, 2024. 6
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.