What Demonstration Curation Metrics Do to Your Policy
Pith reviewed 2026-06-27 16:00 UTC · model grok-4.3
The pith
Demonstration curation metrics with the highest defect-detection scores produce the worst downstream policies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
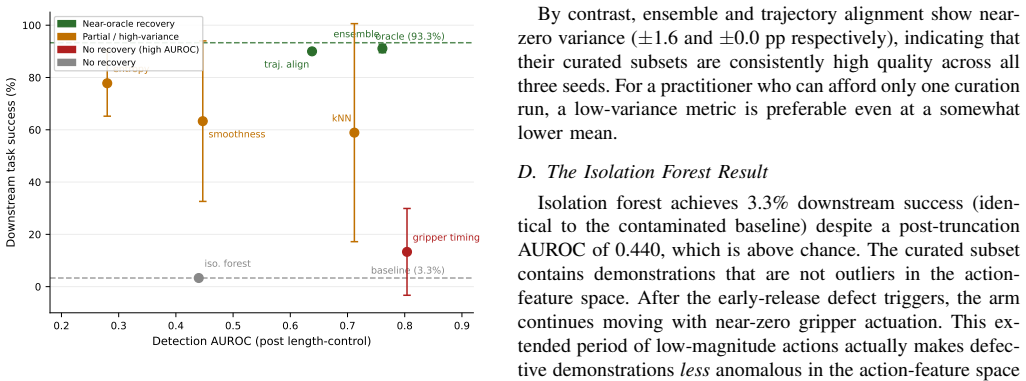
On the LIBERO pick-and-place benchmark with a controlled structural defect of early gripper release during the carry phase, demonstration-curation metrics decouple from policy quality: the metric with the highest defect-detection AUROC of 0.804 produces the worst curated policy at 13.3 percent task success, while a metric with a lower AUROC of 0.638 produces a policy that nearly matches the oracle trained on ground-truth clean data at 90.0 percent versus 93.3 percent.
What carries the argument
The decoupling between a curation metric's defect-detection AUROC and the task success rate of the behavior-cloning policy trained on the filtered demonstrations.
If this is right
- Five of the seven metrics exploit episode length as a trivial proxy for the defect label, inflating reported AUROCs to near-perfect values.
- Any curation benchmark must control for episode length before reporting detection accuracy.
- The contaminated baseline succeeds on only 3.3 percent of rollouts, and the two best curation methods close this gap to within 3 percentage points of the 93.3 percent oracle ceiling.
- Curation methods should be evaluated by the policy they produce, not the defects they flag.
Where Pith is reading between the lines
- Metrics that avoid length proxies may still need direct testing on policy outcomes rather than detection scores alone.
- The same decoupling could appear in other imitation-learning domains whenever data defects affect control differently than they affect length statistics.
- Selecting curation metrics via policy-performance feedback loops on a small held-out set could be a practical next step.
Load-bearing premise
The controlled early-gripper-release defect on this pick-and-place task produces defective episodes whose detection properties generalize to the broader class of real-world training defects that curation methods are intended to handle.
What would settle it
Re-running the same metrics on a different task or defect type where episode length does not correlate with the defect label and checking whether the AUROC-to-policy-success reversal persists.
Figures
read the original abstract
We study whether demonstration-curation metrics that detect defective training episodes also improve the downstream behavior-cloning policy that trains on the curated data. On a contact-rich LIBERO pick-and-place benchmark with a controlled structural defect (early gripper release during the carry phase), we find that the two quantities are sharply decoupled. The metric with the highest defect-detection AUROC (0.804) produces the worst curated policy (13.3% task success), while a metric with a substantially lower AUROC (0.638) produces a policy that nearly matches the oracle trained on ground-truth clean data (90.0% vs. 93.3%). We further show that five of the seven metrics we evaluate exploit episode length as a trivial proxy for the defect label, a confound that inflates reported AUROCs to near-perfect values and disappears once episode length is controlled. Across all conditions, the contaminated baseline succeeds on only 3.3% of rollouts, and the two best curation methods close this to within 3 percentage points of the 93.3% oracle ceiling. Our results argue that curation methods should be evaluated by the policy they produce, not the defects they flag, and that any curation benchmark must control for episode length before reporting detection accuracy. We release the testbed, all metric implementations, and the evaluation pipeline.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript empirically studies demonstration curation metrics on a contact-rich LIBERO pick-and-place task with a single controlled structural defect (early gripper release in the carry phase). It reports that defect-detection AUROC and downstream behavior-cloning policy success are decoupled: the metric with highest AUROC (0.804) yields the lowest curated policy success (13.3%), while a metric with lower AUROC (0.638) reaches 90.0% success (near the 93.3% oracle trained on clean data). Five of seven metrics are shown to exploit episode length as a proxy for the defect label, inflating AUROCs; controlling for length removes the effect. The contaminated baseline achieves only 3.3% success. The authors conclude that curation should be evaluated by resulting policy quality rather than detection AUROC and that benchmarks must control for episode length; they release the testbed, metric implementations, and evaluation pipeline.
Significance. If the reported decoupling is robust, the work would usefully redirect curation research in imitation learning toward direct policy evaluation over proxy detection metrics. The concrete numbers (AUROC-policy mismatch, near-oracle recovery by two methods, and the episode-length confound) are actionable, and the open release of code and testbed enables verification and extension. The result is internally consistent with the single-defect setup but its broader prescriptive claim depends on stability across defect classes.
major comments (1)
- [experimental results] The central prescriptive claim—that curation methods 'should be evaluated by the policy they produce' and that 'any curation benchmark must control for episode length'—rests on results from one controlled defect (early gripper release during carry) on one LIBERO task. The relative ranking of metrics by AUROC versus policy impact may not be stable for other defect signatures (sensor noise, perceptual failures, incomplete sub-trajectories). Section on experimental results (and abstract): additional defect classes are needed to support the general recommendation.
minor comments (2)
- [abstract and methods] The abstract states that five of seven metrics exploit episode length but does not name the metrics or show the controlled-length AUROC table; adding an explicit table or subsection listing all seven metrics and their length-controlled AUROCs would improve clarity.
- [results] The success-rate numbers (13.3%, 90.0%, 93.3%, 3.3%) are reported without error bars or statistical tests; including standard errors or significance tests across the N rollouts would strengthen the decoupling claim.
Simulated Author's Rebuttal
We thank the referee for the constructive review. We address the major comment point by point below.
read point-by-point responses
-
Referee: [experimental results] The central prescriptive claim—that curation methods 'should be evaluated by the policy they produce' and that 'any curation benchmark must control for episode length'—rests on results from one controlled defect (early gripper release during carry) on one LIBERO task. The relative ranking of metrics by AUROC versus policy impact may not be stable for other defect signatures (sensor noise, perceptual failures, incomplete sub-trajectories). Section on experimental results (and abstract): additional defect classes are needed to support the general recommendation.
Authors: We agree that the experiments use a single controlled defect type on one task, which limits the strength of the general prescriptive recommendation. The study deliberately employs this isolated structural defect to demonstrate the AUROC-policy decoupling and length confound in a reproducible way. We will revise the abstract and experimental results section to explicitly qualify the claims as applying to this defect class, state that the relative metric rankings may vary for other signatures, and add a limitations paragraph noting the need for future validation across additional defect types. This is a partial revision, as we cannot collect new data for additional defect classes within the revision timeline but can clarify scope and limitations in the text. revision: partial
Circularity Check
No circularity; purely empirical evaluation of metrics vs. policy outcomes
full rationale
The paper reports experimental results on a LIBERO pick-and-place task with one controlled defect type. It measures defect-detection AUROC for seven metrics and separately measures task success of behavior-cloning policies trained on data curated by each metric. These quantities are computed from distinct held-out rollouts against an oracle (ground-truth clean data) and a contaminated baseline. No equations, fitted parameters renamed as predictions, self-citations, or ansatzes appear in the provided text; the central claim of decoupling is an observed empirical pattern, not a reduction to its own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A robust and sensitive metric for quantifying move- ment smoothness,
S. Balasubramanian, A. Melendez-Calderon, and E. Bur- det, “A robust and sensitive metric for quantifying move- ment smoothness,”IEEE Trans. Biomed. Eng., vol. 59, no. 8, pp. 2126–2136, 2012
2012
-
[2]
ALVINN: An autonomous land vehi- cle in a neural network,
D. A. Pomerleau, “ALVINN: An autonomous land vehi- cle in a neural network,” inAdvances in Neural Infor- mation Processing Systems, 1989
1989
-
[3]
A reduction of imitation learning and structured prediction to no-regret online learning,
S. Ross, G. Gordon, and D. Bagnell, “A reduction of imitation learning and structured prediction to no-regret online learning,” inProc. AISTATS, 2011
2011
-
[4]
Learning fine-grained bimanual manipulation with low-cost hard- ware,
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn, “Learning fine-grained bimanual manipulation with low-cost hard- ware,” inProc. RSS, 2023
2023
-
[5]
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Open X-Embodiment Collaboration, “Open X- Embodiment: Robotic learning datasets and RT-X models,” arXiv:2310.08864, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
DROID: A large-scale in-the-wild robot manipulation dataset,
A. Khazatsky et al., “DROID: A large-scale in-the-wild robot manipulation dataset,” inProc. RSS, 2024
2024
-
[7]
LeRobot: An open-source library for end-to-end robot learning,
R. Cadene et al., “LeRobot: An open-source library for end-to-end robot learning,” inProc. ICLR, 2026
2026
-
[8]
What matters in learning from offline human demonstrations for robot manipulation,
A. Mandlekar et al., “What matters in learning from offline human demonstrations for robot manipulation,” inProc. CoRL, 2021
2021
-
[9]
Isolation forest,
F. T. Liu, K. M. Ting, and Z.-H. Zhou, “Isolation forest,” inProc. IEEE ICDM, 2008
2008
-
[10]
LIBERO: Benchmarking knowledge trans- fer in lifelong robot learning,
B. Liu et al., “LIBERO: Benchmarking knowledge trans- fer in lifelong robot learning,” inProc. NeurIPS, 2023
2023
-
[11]
robosuite: A Modular Simulation Framework and Benchmark for Robot Learning
Yuke Zhu, J. Wong, A. Mandlekar, R. Mart ´ın-Mart´ın, A. Joshi, K. Lin, A. Maddukuri, S. Nasiriany, and Yifeng Zhu, “robosuite: A modular simulation framework and benchmark for robot learning,” arXiv:2009.12293, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2009
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.