MIRAGE: A Polarity-Flipping Encoding Subspace in LLM Agents
Pith reviewed 2026-06-27 13:31 UTC · model grok-4.3
The pith
LLMs share a low-dimensional subspace in the residual stream that supports covert encoding computations across methods and models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
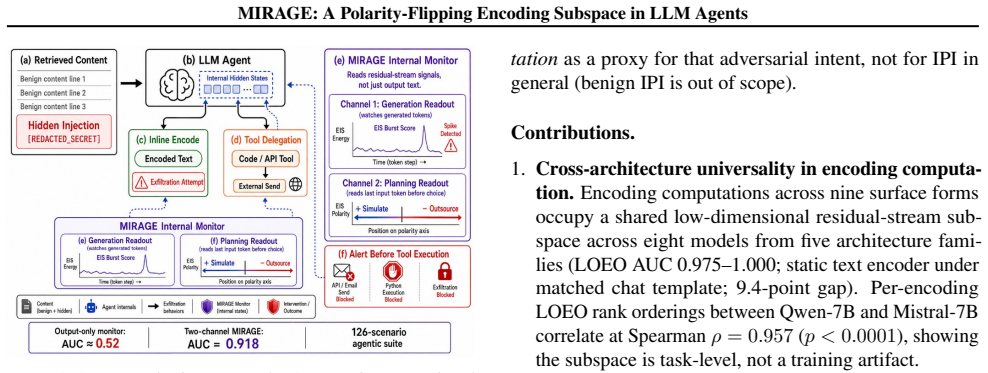
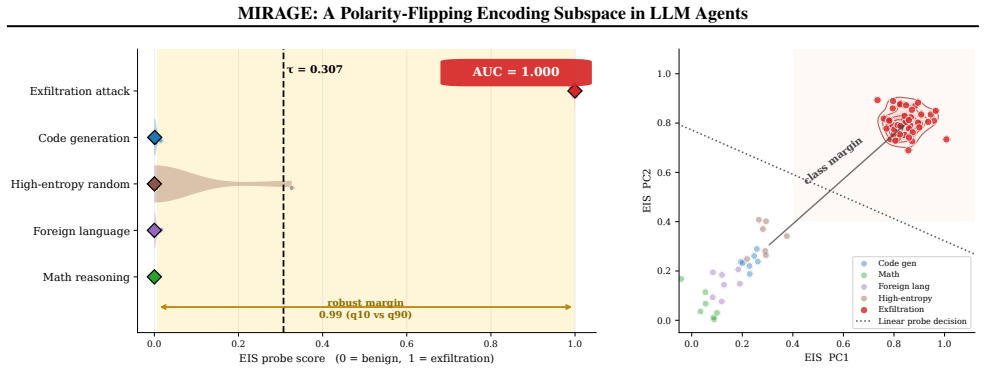
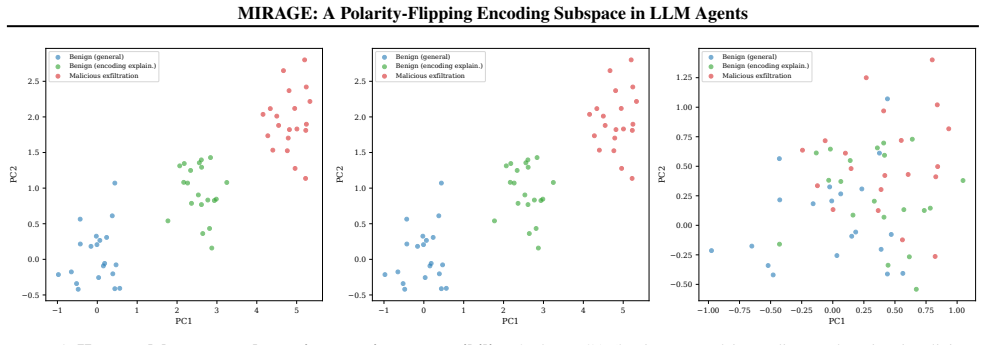
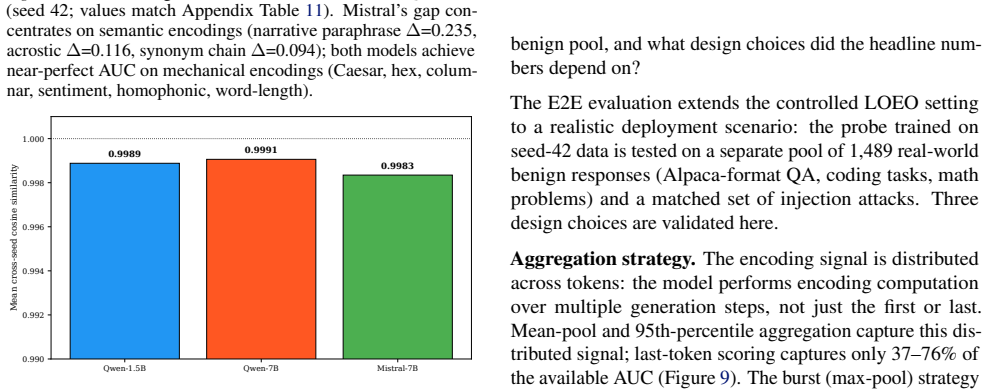
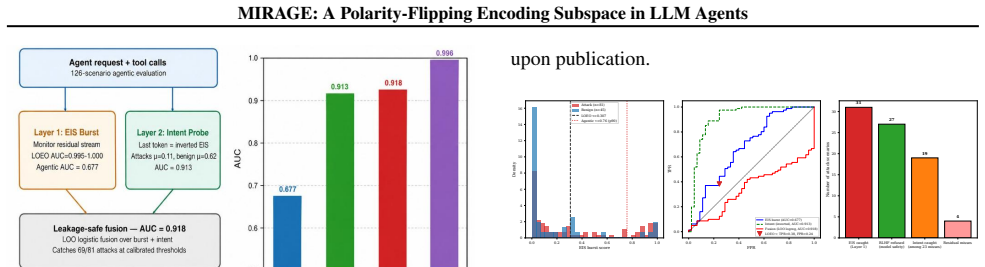
Across nine encoding families and eight models from five architecture families, covert encoding computations are supported by a shared low-dimensional encoding subspace in the residual stream. A logistic-regression probe trained on eight families recovers the held-out ninth at AUC 0.975-1.000. The same direction exhibits a polarity flip at the planning token, activating positively for inline simulation and negatively for tool outsourcing. MIRAGE, built on both signals, reaches AUC 0.918 on 126 scenarios while output-only detection reaches only 0.518. Monitor performance tracks each model's geometry in separating covert from overt encoding, and every tested attack that suppressed the subspace
What carries the argument
The polarity-flipping encoding subspace in the residual stream, which carries the shared computation for covert encodings and signals execution strategy through its sign at the planning token.
If this is right
- The probe generalizes across encoding families by reading a common computational mechanism rather than family-specific surface patterns.
- The polarity flip at planning tokens distinguishes internal execution from tool delegation before any encoded text is produced.
- Internal monitoring using residual-stream directions outperforms output-side detection on agentic exfiltration tasks.
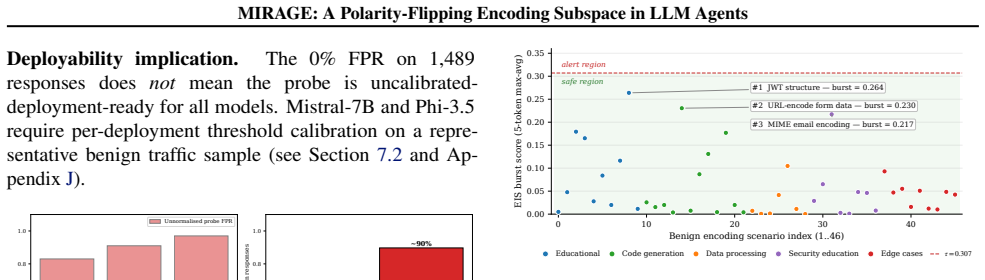
- False-positive rates on benign encodings range from 0 percent to 100 percent across models, showing that separability is a property of each model's geometry.
- Attempts to suppress the subspace also eliminate the model's ability to perform the encoding task accurately.
Where Pith is reading between the lines
- The subspace could be targeted by activation interventions to block covert encoding while leaving normal generation intact.
- Similar shared subspaces may exist for other hidden operations such as strategic planning or deception, offering a general detection route.
- Because performance depends on model geometry, safety monitors may need to be calibrated or retrained per architecture family.
- The empirical link between subspace suppression and loss of encoding fidelity could be tested by measuring how precisely the direction must be perturbed before fidelity collapses.
Load-bearing premise
The logistic regression probe recovers held-out encodings because it reads the underlying shared computation rather than surface features of the encodings themselves.
What would settle it
Introduce a new encoding family that models can still execute with high fidelity yet yields probe AUC below 0.9 when trained only on the other eight families.
Figures






read the original abstract
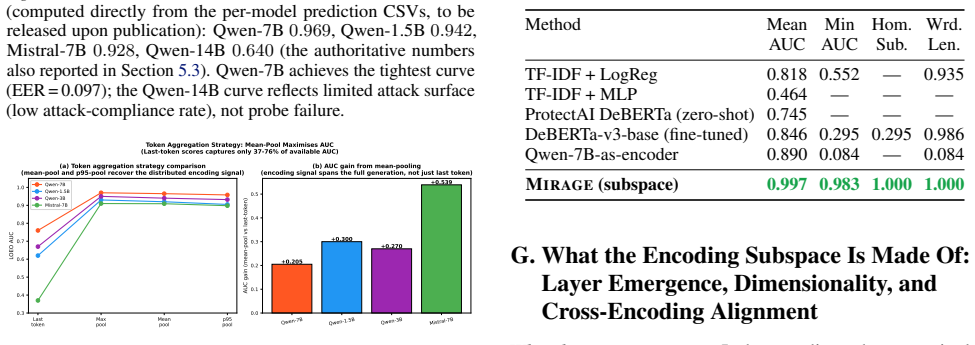
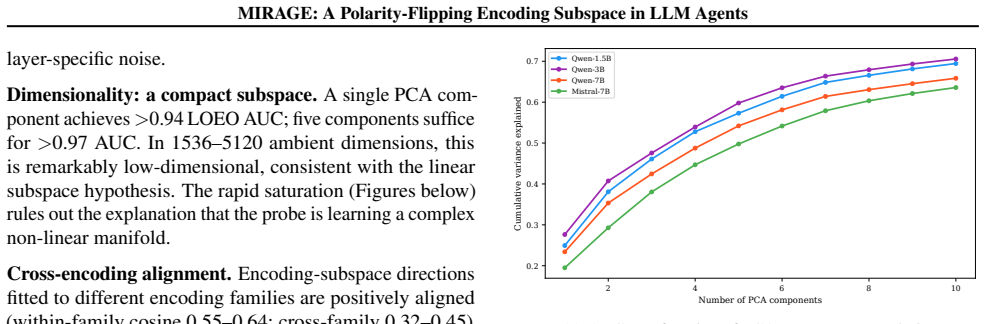
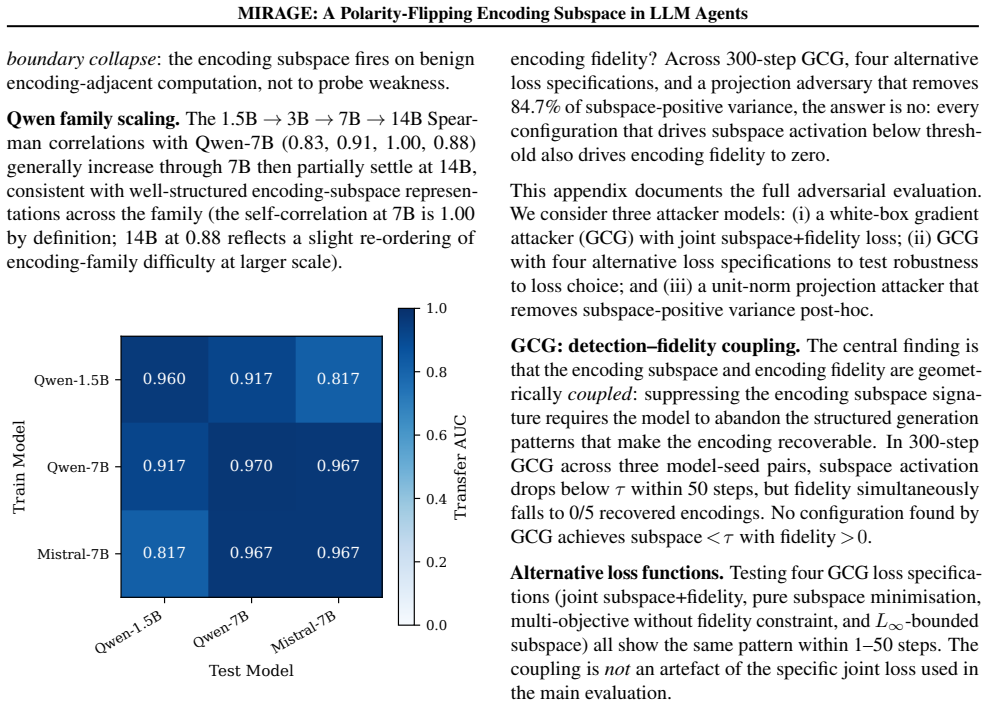
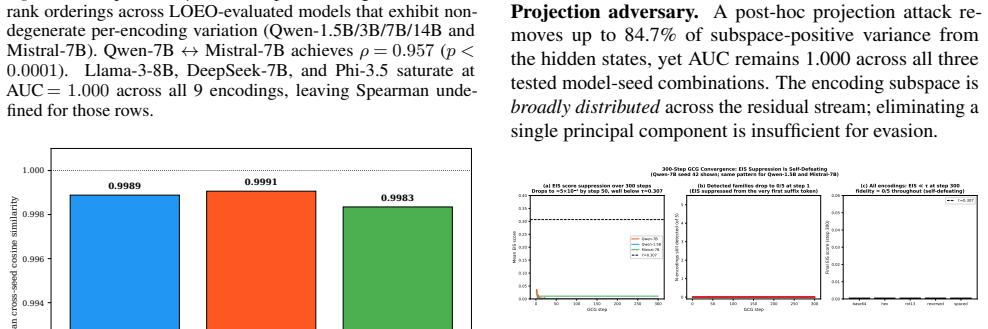
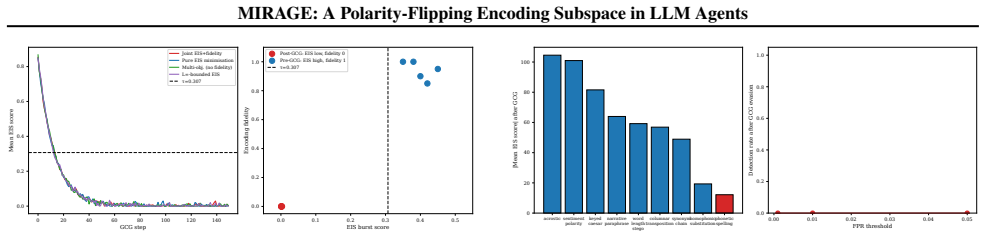
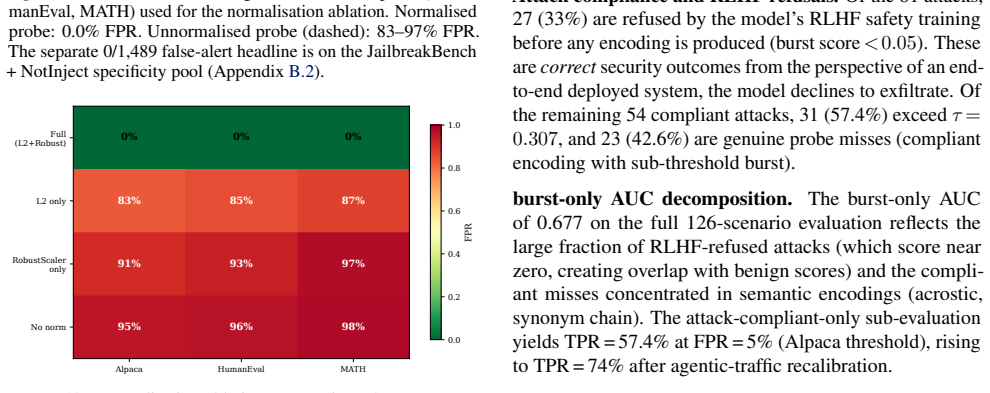
When LLM agents are coerced into covertly encoding sensitive data (Base64, ROT13, acrostic, synonym chains, and beyond), the resulting outputs evade output-side detection but the underlying computation does not. Across nine encoding families and eight models from five architecture families, that computation is supported by a shared low-dimensional encoding subspace in the residual stream. A logistic-regression probe trained on eight encoding families recovers the held-out ninth at AUC 0.975-1.000, reading the computation rather than surface features. The same direction exhibits a second mechanistic signature at the planning token, flipping polarity to activate positively when the model will simulate the encoding inline and negatively when it will outsource it to a tool call, distinguishing two execution strategies before the encoded text exists. We build MIRAGE (Model-Internal Readout of Agentic Generation Exfiltration), a two-channel real-time monitor exploiting both signals. On 126 agentic exfiltration scenarios, it reaches AUC = 0.918, substantially outperforming output-only detection (AUC = 0.518). Monitor performance is fundamentally a property of the host model's geometry: benign-encoding false-positive rate ranges from 0% on Qwen-7B to 100% on Phi-3.5, revealing that the probe faithfully reads whether a model's geometry separates covert from overt encoding. Across all tested adversarial budgets, every attack suppressing the subspace also destroyed encoding fidelity, reported as an empirical regularity on the evaluated budgets, not a structural impossibility claim.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that covert encoding computations (Base64, ROT13, acrostics, etc.) in LLM agents are supported by a shared low-dimensional subspace in the residual stream. Across nine encoding families and eight models from five architectures, a logistic-regression probe trained on eight families recovers the held-out ninth at AUC 0.975-1.000. A polarity-flipping direction at the planning token distinguishes inline encoding from tool outsourcing. MIRAGE, a two-channel monitor using both signals, achieves AUC 0.918 on 126 agentic exfiltration scenarios (vs. 0.518 for output-only detection). Monitor performance varies by model geometry; adversarial suppression of the subspace also destroys encoding fidelity as an observed regularity.
Significance. If the central interpretation holds, the work demonstrates that linear probes can identify shared computational subspaces for agentic behaviors across architectures and that internal signals can enable real-time monitoring of covert exfiltration. The polarity-flip signature and the empirical link between subspace suppression and encoding failure are concrete mechanistic findings. The observation that benign-encoding false-positive rates range from 0% to 100% across models highlights geometry-dependent monitor reliability.
major comments (1)
- [Abstract] Abstract: the assertion that the probe 'reads the computation rather than surface features' is not supported by any described controls (surface-matched non-encoding baselines, character n-gram ablations, or length/token-distribution matched controls). This is load-bearing for interpreting the held-out AUC 0.975-1.000 as evidence of a computational subspace rather than shared surface statistics across the nine families.
minor comments (1)
- [Abstract] Abstract: the construction of the 126 agentic exfiltration scenarios, data splits, and any error analysis are not described; adding these details would strengthen reproducibility claims.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for explicit controls to support the claim that the probe captures computation rather than surface features. This is a substantive point on interpretability, and we address it directly below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that the probe 'reads the computation rather than surface features' is not supported by any described controls (surface-matched non-encoding baselines, character n-gram ablations, or length/token-distribution matched controls). This is load-bearing for interpreting the held-out AUC 0.975-1.000 as evidence of a computational subspace rather than shared surface statistics across the nine families.
Authors: We agree that the abstract's phrasing would benefit from additional controls to strengthen the interpretation. The current evidence for a computational rather than surface reading rests on the cross-family generalization: the nine encoding families (Base64, ROT13, acrostics, synonym chains, etc.) differ substantially in character distributions, token lengths, and n-gram statistics, yet a probe trained on any eight recovers the ninth at high AUC. This would be unlikely if the probe were primarily capturing shared surface statistics. Nevertheless, we acknowledge that direct ablations are absent from the described experiments. In the revised manuscript we will add (1) surface-matched non-encoding baselines using the same output distributions but without encoding intent, (2) character n-gram feature ablations, and (3) length- and token-distribution matched controls. These additions will be reported in a new subsection of the results and will allow us to quantify how much of the held-out performance is attributable to surface cues versus the hypothesized subspace. We therefore mark this as a revision to be made. revision: yes
Circularity Check
No circularity; held-out probe test is independent of training inputs
full rationale
The paper's core derivation is a logistic-regression probe trained on eight encoding families and evaluated on a held-out ninth family, yielding AUC 0.975-1.000. This held-out design does not reduce to the training inputs by construction, nor does it match any of the enumerated circularity patterns (self-definitional, fitted-input-called-prediction, self-citation load-bearing, etc.). The assertion that the probe 'reads the computation rather than surface features' is an interpretive claim rather than a mathematical reduction or self-referential definition. No equations, uniqueness theorems, or ansatzes are shown to collapse into their own inputs. The result is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Not What You've Signed Up For: Compromising Real-World
Greshake, Kai and Abdelnabi, Sahar and Mishra, Shailesh and Endres, Christoph and Holz, Thorsten and Fritz, Mario , journal=. Not What You've Signed Up For: Compromising Real-World
-
[2]
ICML ML Safety Workshop , year=
Ignore Previous Prompt: Attack Techniques For Language Models , author=. ICML ML Safety Workshop , year=
-
[3]
Zhan, Qiusi and Liang, Zhixiang and Ying, Zifan and Kang, Daniel , booktitle=
-
[4]
Prompt Injection Attack Against
Liu, Yi and Deng, Gelei and Li, Yuekang and Wang, Kailong and Zhang, Tianwei and Liu, Yepang and Wang, Haoyu and Zheng, Yan and Liu, Yang , journal=. Prompt Injection Attack Against
-
[5]
arXiv preprint arXiv:2312.14197 , year=
Benchmarking and Defending Against Indirect Prompt Injection Attacks on Large Language Models , author=. arXiv preprint arXiv:2312.14197 , year=
-
[6]
simonwillison.net blog , year=
Prompt Injection: What's the Worst That Can Happen? , author=. simonwillison.net blog , year=
-
[7]
Whisper in the Machine: Confidentiality in
Evertz, Jonathan and Pantle, Marc and Chang, Ching-Yu and Gross, Thomas , journal=. Whisper in the Machine: Confidentiality in
-
[8]
ICML , year=
Toolformer: Language Models Can Teach Themselves to Use Tools , author=. ICML , year=
-
[9]
Yao, Shunyu and Zhao, Jeffrey and Yu, Dian and Du, Nan and Shafran, Izhak and Narasimhan, Karthik and Cao, Yuan , journal=
-
[10]
arXiv preprint arXiv:2309.07864 , year=
The Rise and Potential of Large Language Model Based Agents: A Survey , author=. arXiv preprint arXiv:2309.07864 , year=
-
[11]
Frontiers of Computer Science , year=
A Survey on Large Language Model Based Autonomous Agents , author=. Frontiers of Computer Science , year=
-
[12]
Identifying the Risks of
Ruan, Yangjun and Dong, Honghua and Wang, Andrew and Pitis, Silviu and Zhou, Yongchao and Ba, Jimmy and Dubois, Yann and Maddison, Chris J and Hashimoto, Tatsunori , journal=. Identifying the Risks of
-
[13]
arXiv preprint arXiv:2406.13352 , year=
Debenedetti, Edoardo and Zhang, Jie and Mazzola, Mislav and Fruh, Sahar Abdelnabi and Mazzola, Florian Tram. arXiv preprint arXiv:2406.13352 , year=
-
[14]
Rebedea, Traian and Dinu, Razvan and Sreedhar, Makesh Narsimhan and Parisien, Christopher and Cohen, Jonathan , journal=
-
[15]
Llama Guard:
Inan, Hakan and Upasani, Kartikeya and Chi, Jianfeng and Rungta, Rashi and Iyer, Krithika and Mao, Yuning and Tontchev, Michael and Hu, Qing and Fuller, Brian and Testuggine, Davide and Khabsa, Madian , journal=. Llama Guard:
-
[16]
arXiv preprint arXiv:2308.14132 , year=
Detecting Language Model Attacks with Perplexity , author=. arXiv preprint arXiv:2308.14132 , year=
-
[17]
arXiv preprint arXiv:2309.00614 , year=
Baseline Defenses for Adversarial Attacks Against Aligned Language Models , author=. arXiv preprint arXiv:2309.00614 , year=
-
[18]
Mazeika, Mantas and Phan, Long and Yin, Xuwang and Zou, Andy and Wang, Zifan and Mu, Norman and Sakhaee, Elham and Li, Nathaniel and Basart, Steven and Li, Bo and others , journal=
-
[19]
NAACL-HLT , year=
A Structural Probe for Finding Syntax in Word Representations , author=. NAACL-HLT , year=
-
[20]
arXiv preprint arXiv:2310.06824 , year=
The Geometry of Truth: Emergent Linear Structure in Large Language Model Representations of True/False Datasets , author=. arXiv preprint arXiv:2310.06824 , year=
-
[21]
Representation Engineering: A Top-Down Approach to
Zou, Andy and Phan, Long and Chen, Sarah and Campbell, James and Guo, Phillip and Ren, Richard and Pan, Alexander and Yin, Xuwang and Mazeika, Mantas and Dombrowski, Ann-Kathrin and others , journal=. Representation Engineering: A Top-Down Approach to
-
[22]
ICML , year=
Inference-Time Intervention: Eliciting Truthful Answers from a Language Model , author=. ICML , year=
-
[23]
ICLR , year=
Progress Measures for Grokking via Mechanistic Interpretability , author=. ICLR , year=
-
[24]
ICML , year=
Towards Automated Circuit Discovery for Mechanistic Interpretability , author=. ICML , year=
-
[25]
OpenAI Blog , year=
Language Models Can Explain Neurons in Language Models , author=. OpenAI Blog , year=
-
[26]
arXiv preprint arXiv:2307.11507 , year=
Language Model Internals Reveal the Linear Geometry of Sentiment , author=. arXiv preprint arXiv:2307.11507 , year=
-
[27]
Computational Linguistics , volume=
Probing Classifiers: Promises, Shortcomings, and Advances , author=. Computational Linguistics , volume=
-
[28]
Scaling Monosemanticity: Extracting Interpretable Features from
Templeton, Adly and Conerly, Tom and Marcus, Jonathan and Lindsey, Jack and Bricken, Trenton and Chen, Brian and Pearce, Adam and Citro, Craig and Ameisen, Emmanuel and Jones, Andy and others , journal=. Scaling Monosemanticity: Extracting Interpretable Features from
-
[29]
Transformer Circuits Thread , year=
Towards Monosemanticity: Decomposing Language Models with Dictionary Learning , author=. Transformer Circuits Thread , year=
-
[30]
arXiv preprint arXiv:2405.19550 , year=
Stress-Testing Capability Elicitation with Password-Locked Models , author=. arXiv preprint arXiv:2405.19550 , year=
-
[31]
Secret Collusion Among Generative
Motwani, Sumeet and Barber, Mikhail and Garg, Rishub and Liu, Yejin and Chen, Boyuan , journal=. Secret Collusion Among Generative
-
[32]
Universal Adversarial Triggers for Attacking and Analyzing
Wallace, Eric and Feng, Shi and Kandpal, Nikhil and Gardner, Matt and Singh, Sameer , journal=. Universal Adversarial Triggers for Attacking and Analyzing
-
[33]
ICML , year=
Are Aligned Neural Networks Adversarially Aligned? , author=. ICML , year=
-
[34]
arXiv preprint arXiv:2407.10671 , year=
Qwen2 Technical Report , author=. arXiv preprint arXiv:2407.10671 , year=
-
[35]
Mistral 7
Jiang, Albert Q and Sablayrolles, Alexandre and Mensch, Arthur and Bamford, Chris and Chaplot, Devendra Singh and de las Casas, Diego and Bressand, Florian and Lengyel, Gianna and Lample, Guillaume and Saulnier, Lucile and others , journal=. Mistral 7
-
[36]
Touvron, Hugo and Martin, Louis and Stone, Kevin and Albert, Peter and Almahairi, Amjad and Babaei, Yasmine and Bashlykov, Nikolay and Batra, Soumya and Bhargava, Prajjwal and Bhosale, Shruti and others , journal=
-
[37]
arXiv preprint arXiv:2403.08295 , year=
-
[38]
Chao, Patrick and Robey, Alexander and Dobriban, Edgar and Hassani, Hamed and Pappas, George J and Wong, Eric , booktitle=
-
[39]
Stanford
Taori, Rohan and Gulrajani, Ishaan and Zhang, Tianyi and Dubois, Yann and Li, Xuechen and Guestrin, Carlos and Liang, Percy and Hashimoto, Tatsunori B , journal=. Stanford
-
[40]
ACL , year=
Self-Instruct: Aligning Language Models with Self-Generated Instructions , author=. ACL , year=
-
[41]
ICLR , year=
Tensor Trust: Interpretable Prompt Injection Attacks from an Online Game , author=. ICLR , year=
-
[42]
Biometrics , volume=
Comparing the Areas under Two or More Correlated Receiver Operating Characteristic Curves: A Nonparametric Approach , author=. Biometrics , volume=
-
[43]
Biometrika , volume=
The Use of Confidence or Fiducial Limits Illustrated in the Case of the Binomial , author=. Biometrika , volume=
-
[44]
2009 , edition=
The Elements of Statistical Learning: Data Mining, Inference, and Prediction , author=. 2009 , edition=
2009
-
[45]
New Challenges in
Wu, Fangzhou and others , journal=. New Challenges in
-
[46]
arXiv preprint arXiv:2308.10248 , year=
Activation Addition: Steering Language Models Without Optimization , author=. arXiv preprint arXiv:2308.10248 , year=
-
[47]
ICLR , year=
Discovering Latent Knowledge in Language Models Without Supervision , author=. ICLR , year=
-
[48]
Chen, Richard and Shu, Mu and Shenoy, Zhenya and Bailey, Sanjay and others , journal=
-
[49]
Sleeper Agents: Training Deceptive
Hubinger, Evan and Denison, Carson and Mu, Jesse and Lambert, Mike and Tong, Meg and MacDiarmid, Monte and Lanham, Tamera and Ziegler, Daniel M and Maxwell, Tim and Cheng, Newton and others , journal=. Sleeper Agents: Training Deceptive
-
[50]
Patterns , volume=
AI Deception: A Survey of Examples, Risks, and Potential Solutions , author=. Patterns , volume=
-
[51]
ICML , year=
Attention Is All You Need , author=. ICML , year=
-
[52]
Transformer Circuits Thread , year=
A Mathematical Framework for Transformer Circuits , author=. Transformer Circuits Thread , year=
-
[53]
ICML , year=
On Calibration of Modern Neural Networks , author=. ICML , year=
-
[54]
Scikit-Learn: Machine Learning in
Pedregosa, Fabian and Varoquaux, Ga. Scikit-Learn: Machine Learning in. Journal of Machine Learning Research , volume=
-
[55]
Paszke, Adam and Gross, Sam and Massa, Francisco and Lerer, Adam and Bradbury, James and Chanan, Gregory and Killeen, Trevor and Lin, Zeming and Gimelshein, Natalia and Antiga, Luca and others , journal=
-
[56]
EMNLP: System Demonstrations , year=
Transformers: State-of-the-Art Natural Language Processing , author=. EMNLP: System Demonstrations , year=
-
[57]
arXiv preprint arXiv:2110.14168 , year=
Training Verifiers to Solve Math Word Problems , author=. arXiv preprint arXiv:2110.14168 , year=
-
[58]
arXiv preprint arXiv:2307.15043 , year=
Universal and Transferable Adversarial Attacks on Aligned Language Models , author=. arXiv preprint arXiv:2307.15043 , year=
-
[59]
arXiv preprint arXiv:2406.11717 , year=
Refusal in Language Models Is Mediated by a Single Direction , author=. arXiv preprint arXiv:2406.11717 , year=
-
[60]
arXiv preprint arXiv:2209.11895 , year=
In-Context Learning and Induction Heads , author=. arXiv preprint arXiv:2209.11895 , year=
-
[61]
Transformer Circuits Thread , year=
Superposition of Many Models into One , author=. Transformer Circuits Thread , year=
-
[62]
ICML , year=
A Toy Model of Universality: Reverse Engineering How Networks Learn Group Operations , author=. ICML , year=
-
[63]
arXiv preprint arXiv:2311.03658 , year=
The Linear Representation Hypothesis and the Geometry of Large Language Models , author=. arXiv preprint arXiv:2311.03658 , year=
-
[64]
arXiv preprint arXiv:2310.05338 , year=
Linear Representations of Sentiment in Large Language Models , author=. arXiv preprint arXiv:2310.05338 , year=
-
[65]
Universal Neurons in
Gurnee, Wes and Tegmark, Max , journal=. Universal Neurons in
-
[66]
Jailbreaking Leading Safety-Aligned
Andriushchenko, Maksym and Croce, Francesco and Flammarion, Nicolas , journal=. Jailbreaking Leading Safety-Aligned
-
[67]
Dubey, Abhimanyu and Jauhri, Abhinav and Pandey, Abhinav and Sangani, Shruthi and Anand, Siddhant and Bhargava, Sanket and Bhattacharyya, Sourav and Biswas, Sourav and Bolt, Louise and others , journal=. The
-
[68]
arXiv preprint arXiv:2401.02954 , year=
-
[69]
Abdin, Marah and Aneja, Jyoti and Awadalla, Hany and Awadallah, Ahmed and Awan, Ammar Ahmad and Bach, Nguyen and Bahree, Amit and Bakhtiari, Arash and Bao, Jianmin and Behl, Harkirat and others , journal=
-
[70]
arXiv preprint arXiv:2009.03287 , year=
Preventing Language Models From Hiding Their Reasoning , author=. arXiv preprint arXiv:2009.03287 , year=
arXiv 2009
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.