Dissect and Prune: Enhancing Robustness in AI-Generated Image Detection
Pith reviewed 2026-06-27 14:15 UTC · model grok-4.3
The pith
Pruning features aligned with inpainted regions reduces bias toward real images in AI-generated content detectors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
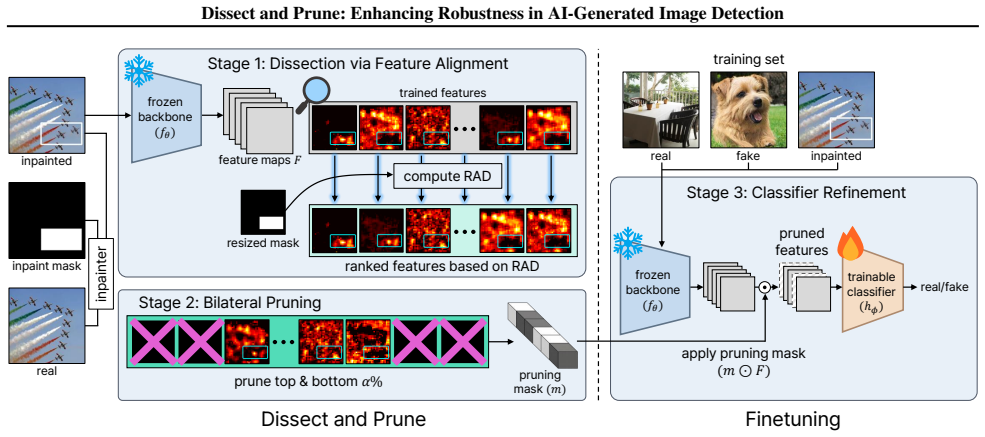
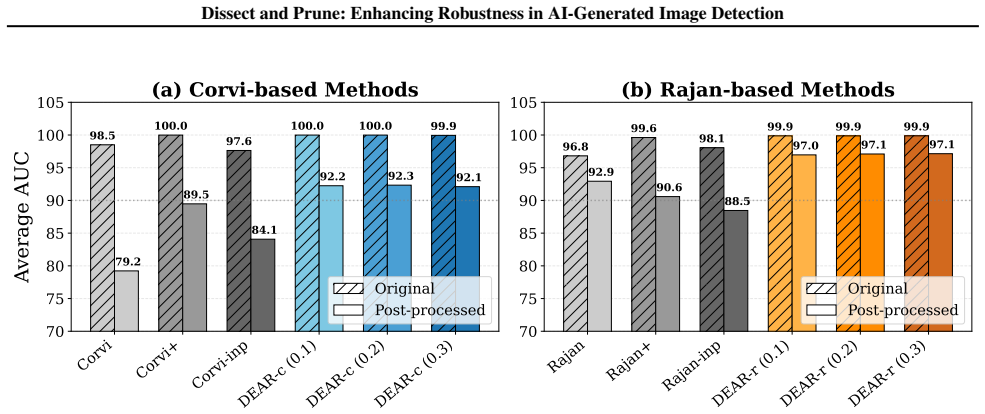
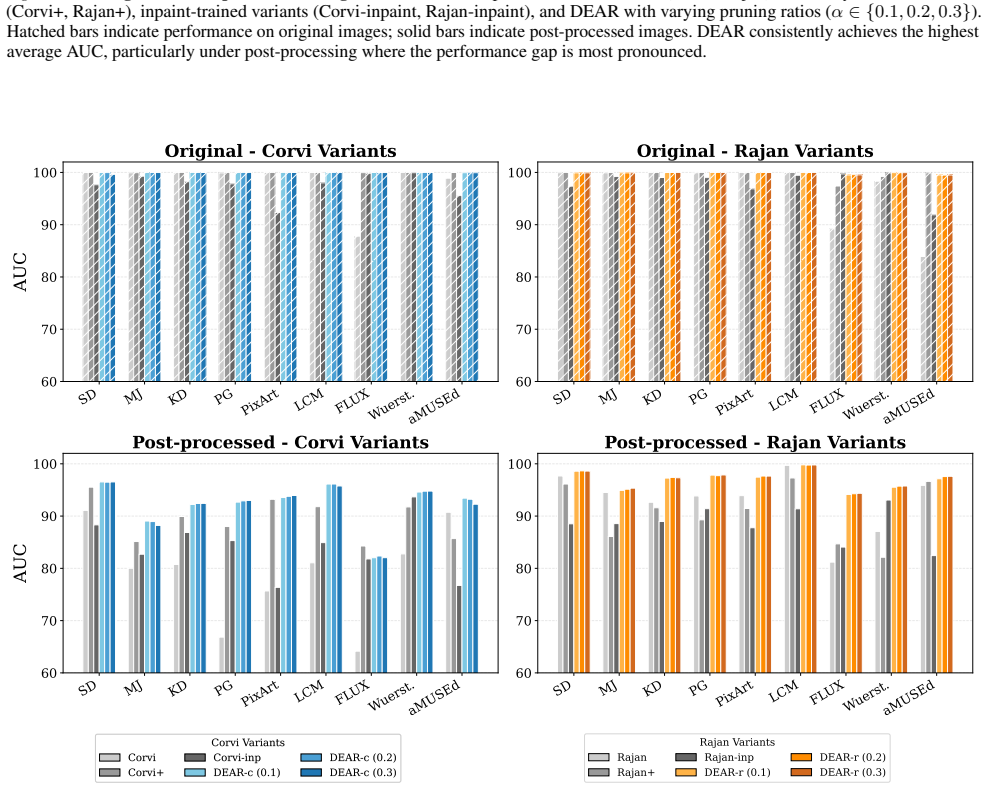
By measuring channel alignment to inpaint masks and pruning activations that match either the inpainted or non-inpainted regions too closely, DEAR retains only those features that encode genuine generative artifacts; the resulting detectors exhibit reduced prediction asymmetry and greater robustness to unseen generators and post-processing operations.
What carries the argument
DEAR (Dissect and Prune), which removes channel activations whose alignment with inpaint masks falls at either extreme, leaving only those aligned with genuine generative artifacts.
If this is right
- Detectors retain sensitivity to generated content even after compression and resizing.
- Performance holds up when tested on generators not seen during training.
- The bias that produces more real-class predictions is reduced.
- Only channels that capture actual generative traces survive the pruning step.
Where Pith is reading between the lines
- Inpainting could serve as a general probe for isolating spurious correlations in other forensic or classification tasks.
- The same alignment measurement might be used to audit training data for hidden biases before model deployment.
- Retraining from scratch with only the retained features might further stabilize performance across domains.
Load-bearing premise
Features that align strongly with inpainted or non-inpainted regions are the ones that become unreliable after post-processing and that hide the real generative signals.
What would settle it
Apply DEAR to an existing detector, then measure whether the false-negative rate on post-processed generated images from an unseen generator remains as high as the original model's rate.
Figures



read the original abstract
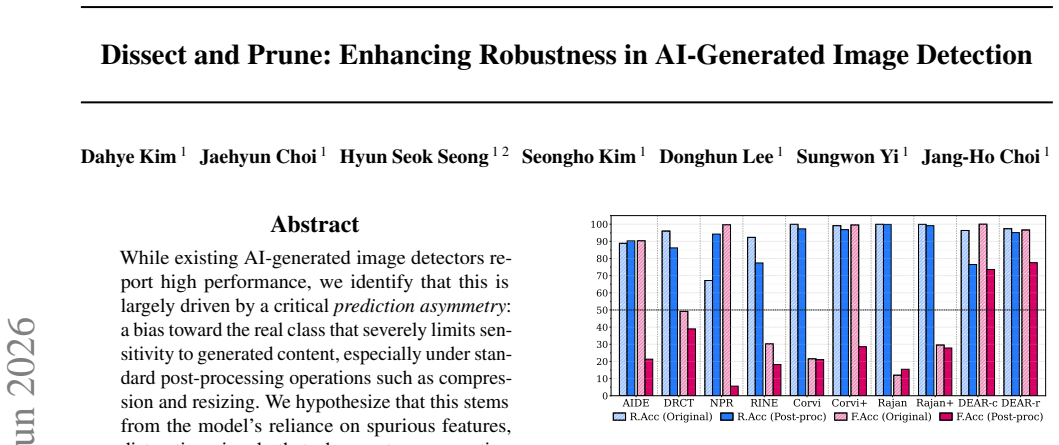
While existing AI-generated image detectors report high performance, we identify that this is largely driven by a critical prediction asymmetry: a bias toward the real class that severely limits sensitivity to generated content, especially under standard post-processing operations such as compression and resizing. We hypothesize that this stems from the model's reliance on spurious features, distracting signals that obscure true generative artifacts. To address this, we propose DEAR (Dissect and Prune), which leverages inpainted images to identify and prune these interfering components. Specifically, we find that features strongly aligned to either inpainted or non-inpainted regions are less robust to post-processing. By measuring the alignment between channel activations and inpaint masks, DEAR removes features at both extremes, retaining only those that capture genuine generative artifacts. Experimental results demonstrate that our approach significantly enhances robustness against unseen generators and post-processing, effectively mitigating the prediction asymmetry. Our code is available at https://github.com/dahyedahye/dear.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper identifies a prediction asymmetry in existing AI-generated image detectors that biases toward the real class and reduces sensitivity to generated images, particularly under post-processing like compression and resizing. It hypothesizes this arises from spurious features and proposes DEAR (Dissect and Prune), which generates inpainted images, measures alignment between channel activations and inpaint masks, prunes channels at both high- and low-alignment extremes, and retains middle channels asserted to capture only genuine generative artifacts. The abstract states that experiments show this significantly enhances robustness to unseen generators and post-processing while mitigating the asymmetry; code is released.
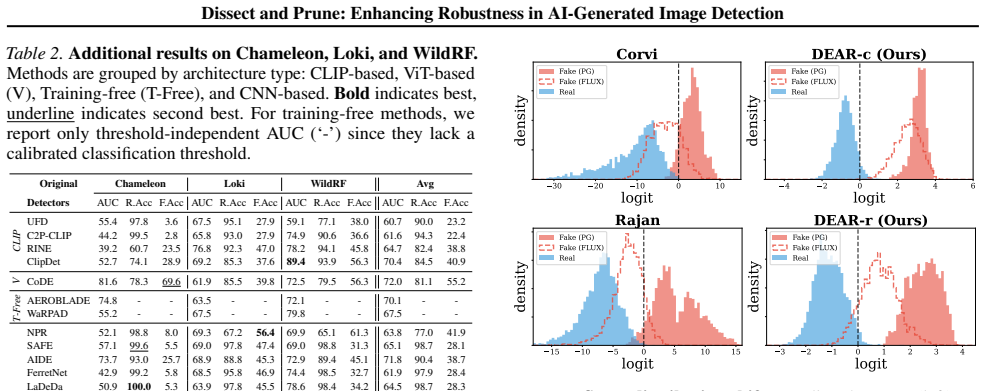
Significance. If the central claims are substantiated with quantitative evidence, the approach could provide a practical, inpainting-based pruning technique to improve detector robustness by isolating features less tied to specific post-processing or inpainting signals. The release of code is a strength for reproducibility. However, without metrics or validation against established artifact signatures, the significance for the broader field of generative image detection remains unclear.
major comments (3)
- [Abstract] Abstract: The central claim that 'experimental results demonstrate that our approach significantly enhances robustness' and 'effectively mitigating the prediction asymmetry' is presented without any quantitative metrics, dataset sizes, baseline comparisons, statistical tests, or details on alignment threshold selection. This information is load-bearing for assessing whether the robustness gains are real and general.
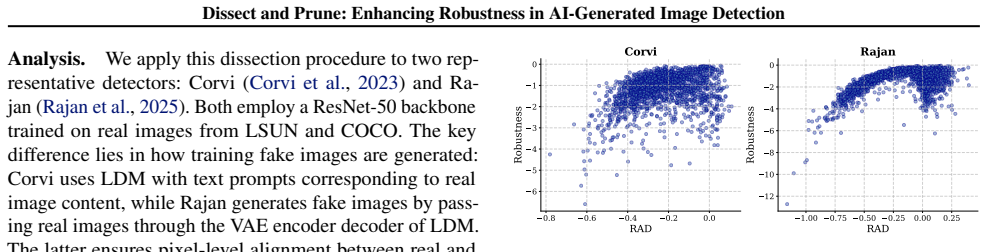
- [DEAR description] Paragraph describing DEAR: The pruning rule rests on the assumption that 'features strongly aligned to either inpainted or non-inpainted regions are less robust to post-processing' and that retained middle channels capture 'genuine generative artifacts,' yet no independent verification is described that links retained channels to documented artifact types such as spectral anomalies, upsampling traces, or frequency-domain patterns from prior GAN/CNN detection literature.
- [Experiments] Experiments section (implied by abstract claims): The post-processing robustness results and claims about unseen generators lack any reported details on experimental protocol, number of images, choice of inpainting method, or how thresholds are chosen, preventing assessment of whether gains are an artifact of the specific inpainter rather than a general purification of the detector.
minor comments (1)
- [Abstract] The abstract could more precisely define 'prediction asymmetry' and briefly indicate the scale of the experiments even if full numbers appear later.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment point-by-point below, proposing revisions to strengthen the manuscript where the concerns are valid.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'experimental results demonstrate that our approach significantly enhances robustness' and 'effectively mitigating the prediction asymmetry' is presented without any quantitative metrics, dataset sizes, baseline comparisons, statistical tests, or details on alignment threshold selection. This information is load-bearing for assessing whether the robustness gains are real and general.
Authors: We agree that the abstract would be strengthened by including key quantitative results. In the revised version, we will add specific metrics such as accuracy improvements under post-processing (e.g., compression and resizing), reduction in prediction asymmetry, dataset sizes, and baseline comparisons from our experiments. Threshold selection details will also be summarized. revision: yes
-
Referee: [DEAR description] Paragraph describing DEAR: The pruning rule rests on the assumption that 'features strongly aligned to either inpainted or non-inpainted regions are less robust to post-processing' and that retained middle channels capture 'genuine generative artifacts,' yet no independent verification is described that links retained channels to documented artifact types such as spectral anomalies, upsampling traces, or frequency-domain patterns from prior GAN/CNN detection literature.
Authors: The pruning criterion is motivated by empirical robustness tests showing that extreme-alignment channels degrade under post-processing. The manuscript does not include direct, independent verification mapping retained channels to specific prior artifact signatures. We will add a discussion section in the revision referencing established artifact literature (e.g., spectral and frequency patterns) to better contextualize our retained features, while noting that end-to-end gains on unseen generators serve as the primary validation. revision: partial
-
Referee: [Experiments] Experiments section (implied by abstract claims): The post-processing robustness results and claims about unseen generators lack any reported details on experimental protocol, number of images, choice of inpainting method, or how thresholds are chosen, preventing assessment of whether gains are an artifact of the specific inpainter rather than a general purification of the detector.
Authors: The full manuscript reports the experimental protocol, including dataset sizes, the specific inpainting method, threshold selection via alignment score distributions, and evaluation on multiple post-processing operations and unseen generators. We will expand the Experiments section in the revision to make these details more explicit and add a sensitivity analysis on inpainter choice to demonstrate generality. revision: yes
Circularity Check
No circularity: experimental pruning validated by external benchmarks
full rationale
The paper presents DEAR as a heuristic channel-pruning procedure that measures activation-mask alignment on inpainted images and retains middle-ranked channels; robustness gains are reported via direct experiments on unseen generators and post-processing. No equations, fitted parameters, or self-citations are shown to reduce the central claim to its own inputs by construction. The method is self-contained against external test sets and does not invoke uniqueness theorems or rename known results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Network dissection: Quantifying interpretability of deep visual representations , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[2]
arXiv preprint arXiv:1811.10597 , year=
Gan dissection: Visualizing and understanding generative adversarial networks , author=. arXiv preprint arXiv:1811.10597 , year=
-
[3]
ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
On the detection of synthetic images generated by diffusion models , author=. ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2023 , organization=
2023
-
[4]
The Thirteenth International Conference on Learning Representations , year=
Aligned Datasets Improve Detection of Latent Diffusion-Generated Images , author=. The Thirteenth International Conference on Learning Representations , year=
-
[5]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Rethinking the up-sampling operations in cnn-based generative network for generalizable deepfake detection , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[6]
Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V
Improving synthetic image detection towards generalization: An image transformation perspective , author=. Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 1 , pages=
-
[7]
arXiv preprint arXiv:2406.19435 , year=
A sanity check for ai-generated image detection , author=. arXiv preprint arXiv:2406.19435 , year=
-
[8]
arXiv preprint arXiv:2509.20890 , year=
FerretNet: Efficient Synthetic Image Detection via Local Pixel Dependencies , author=. arXiv preprint arXiv:2509.20890 , year=
-
[9]
arXiv preprint arXiv:2406.09398 , year=
Real-time deepfake detection in the real-world , author=. arXiv preprint arXiv:2406.09398 , year=
-
[10]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Towards universal fake image detectors that generalize across generative models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[11]
Proceedings of the AAAI Conference on Artificial Intelligence , year=
C2p-clip: Injecting category common prompt in clip to enhance generalization in deepfake detection , author=. Proceedings of the AAAI Conference on Artificial Intelligence , year=
-
[12]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Raising the bar of ai-generated image detection with clip , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[13]
European Conference on Computer Vision , pages=
Leveraging representations from intermediate encoder-blocks for synthetic image detection , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[14]
International Conference on Machine Learning (ICML) , year=
Effort: Efficient orthogonal modeling for generalizable ai-generated image detection , author=. International Conference on Machine Learning (ICML) , year=
-
[15]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
A bias-free training paradigm for more general ai-generated image detection , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[16]
arXiv preprint arXiv:2505.14359 , year=
Dual Data Alignment Makes AI-Generated Image Detector Easier Generalizable , author=. arXiv preprint arXiv:2505.14359 , year=
-
[17]
Forty-first International Conference on Machine Learning , year=
Drct: Diffusion reconstruction contrastive training towards universal detection of diffusion generated images , author=. Forty-first International Conference on Machine Learning , year=
-
[18]
European Conference on Computer Vision , pages=
Contrasting deepfakes diffusion via contrastive learning and global-local similarities , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[19]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Aeroblade: Training-free detection of latent diffusion images using autoencoder reconstruction error , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[20]
arXiv preprint arXiv:2511.14030 , year=
Training-free Detection of AI-generated images via Cropping Robustness , author=. arXiv preprint arXiv:2511.14030 , year=
-
[21]
arXiv preprint arXiv:1506.03365 , year=
Lsun: Construction of a large-scale image dataset using deep learning with humans in the loop , author=. arXiv preprint arXiv:1506.03365 , year=
-
[22]
European conference on computer vision , pages=
Microsoft coco: Common objects in context , author=. European conference on computer vision , pages=. 2014 , organization=
2014
-
[23]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
High-resolution image synthesis with latent diffusion models , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[24]
arXiv preprint arXiv:2111.11431 , year=
Redcaps: Web-curated image-text data created by the people, for the people , author=. arXiv preprint arXiv:2111.11431 , year=
-
[25]
2024 , howpublished=
Black Forest Labs , title=. 2024 , howpublished=
2024
-
[26]
arXiv preprint arXiv:2310.03502 , year=
Kandinsky: an improved text-to-image synthesis with image prior and latent diffusion , author=. arXiv preprint arXiv:2310.03502 , year=
-
[27]
5: Three insights towards enhancing aesthetic quality in text-to-image generation , author=
Playground v2. 5: Three insights towards enhancing aesthetic quality in text-to-image generation , author=. arXiv preprint arXiv:2402.17245 , year=
-
[28]
Junsong Chen and Jincheng YU and Chongjian GE and Lewei Yao and Enze Xie and Zhongdao Wang and James Kwok and Ping Luo and Huchuan Lu and Zhenguo Li , booktitle=
-
[29]
arXiv preprint arXiv:2310.04378 , year=
Latent consistency models: Synthesizing high-resolution images with few-step inference , author=. arXiv preprint arXiv:2310.04378 , year=
-
[30]
The Twelfth International Conference on Learning Representations , year=
W\"urstchen: An Efficient Architecture for Large-Scale Text-to-Image Diffusion Models , author=. The Twelfth International Conference on Learning Representations , year=
-
[31]
arXiv preprint arXiv:2401.01808 , year=
amused: An open muse reproduction , author=. arXiv preprint arXiv:2401.01808 , year=
-
[32]
ICLR , year=
LOKI: A Comprehensive Synthetic Data Detection Benchmark using Large Multimodal Models , author=. ICLR , year=
-
[33]
Advances in neural information processing systems , volume=
Denoising diffusion probabilistic models , author=. Advances in neural information processing systems , volume=
-
[34]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Scalable diffusion models with transformers , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[35]
arXiv preprint arXiv:2210.02747 , year=
Flow matching for generative modeling , author=. arXiv preprint arXiv:2210.02747 , year=
-
[36]
Proceedings of the AAAI Conference on Artificial Intelligence , year=
Frequency-aware deepfake detection: Improving generalizability through frequency space domain learning , author=. Proceedings of the AAAI Conference on Artificial Intelligence , year=
-
[37]
arXiv preprint arXiv:2505.12335 , year=
Is Artificial Intelligence Generated Image Detection a Solved Problem? , author=. arXiv preprint arXiv:2505.12335 , year=
-
[38]
Forty-second International Conference on Machine Learning , year=
Stay-Positive: A Case for Ignoring Real Image Features in Fake Image Detection , author=. Forty-second International Conference on Machine Learning , year=
-
[39]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Automatic correction of internal units in generative neural networks , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[40]
for now , author=
CNN-generated images are surprisingly easy to spot... for now , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[41]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Deep residual learning for image recognition , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[42]
IEEE Transactions on image processing , volume=
Active contours without edges , author=. IEEE Transactions on image processing , volume=. 2001 , publisher=
2001
-
[43]
Nature Machine Intelligence , volume=
Shortcut learning in deep neural networks , author=. Nature Machine Intelligence , volume=. 2020 , publisher=
2020
-
[44]
ECCV , year=
Fake or JPEG? Revealing Common Biases in Generated Image Detection Datasets , author=. ECCV , year=
-
[45]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
FreqDebias: Towards Generalizable Deepfake Detection via Consistency-Driven Frequency Debiasing , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[46]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
From Specificity to Generality: Revisiting Generalizable Artifacts in Detecting Face Deepfakes , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[47]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Dire for diffusion-generated image detection , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[48]
Luo, Yunpeng and Du, Junlong and Yan, Ke and Ding, Shouhong , booktitle=. Lare\^
-
[49]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Fakeinversion: Learning to detect images from unseen text-to-image models by inverting stable diffusion , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[50]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Fire: Robust detection of diffusion-generated images via frequency-guided reconstruction error , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[51]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Forgery-aware adaptive transformer for generalizable synthetic image detection , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[52]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Semantic Discrepancy-aware Detector for Image Forgery Identification , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[53]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Aigi-holmes: Towards explainable and generalizable ai-generated image detection via multimodal large language models , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[54]
Advances in Neural Information Processing Systems , volume=
Breaking semantic artifacts for generalized ai-generated image detection , author=. Advances in Neural Information Processing Systems , volume=
-
[55]
Advances in Neural Information Processing Systems , volume=
Breaking latent prior bias in detectors for generalizable aigc image detection , author=. Advances in Neural Information Processing Systems , volume=
-
[56]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Towards universal ai-generated image detection by variational information bottleneck network , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[57]
Advances in Neural Information Processing Systems , volume=
MLEP: Multi-granularity Local Entropy Patterns for Generalized AI-generated Image Detection , author=. Advances in Neural Information Processing Systems , volume=
-
[58]
Forty-second International Conference on Machine Learning , year=
PiD: Generalized AI-Generated Images Detection with Pixelwise Decomposition Residuals , author=. Forty-second International Conference on Machine Learning , year=
-
[59]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Any-resolution ai-generated image detection by spectral learning , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[60]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Learning on gradients: Generalized artifacts representation for gan-generated images detection , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[61]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
LOTA: Bit-Planes Guided AI-Generated Image Detection , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[62]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Forensic self-descriptions are all you need for zero-shot detection, open-set source attribution, and clustering of ai-generated images , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[63]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Beyond Generation: A Diffusion-based Low-level Feature Extractor for Detecting AI-generated Images , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[64]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
ForgeLens: Data-Efficient Forgery Focus for Generalizable Forgery Image Detection , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[65]
Advances in neural information processing systems , volume=
Genimage: A million-scale benchmark for detecting ai-generated image , author=. Advances in neural information processing systems , volume=
-
[66]
Advances in neural information processing systems , volume=
Seeing is not always believing: Benchmarking human and model perception of ai-generated images , author=. Advances in neural information processing systems , volume=
-
[67]
Advances in Neural Information Processing Systems , volume=
Df40: Toward next-generation deepfake detection , author=. Advances in Neural Information Processing Systems , volume=
-
[68]
Advances in Neural Information Processing Systems , volume=
Semi-truths: A large-scale dataset of ai-augmented images for evaluating robustness of ai-generated image detectors , author=. Advances in Neural Information Processing Systems , volume=
-
[69]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Community forensics: Using thousands of generators to train fake image detectors , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[70]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Bridging the Gap Between Ideal and Real-world Evaluation: Benchmarking AI-Generated Image Detection in Challenging Scenarios , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[71]
The Twelfth International Conference on Learning Representations (ICLR) , year =
Podell, Dustin and English, Zion and Lacey, Kyle and Blattmann, Andreas and Dockhorn, Tim and M. The Twelfth International Conference on Learning Representations (ICLR) , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.