SkillResolve-Bench: Measuring and Resolving Same-Capability Ambiguity in Agent Skill Retrieval
Pith reviewed 2026-06-27 11:51 UTC · model grok-4.3
The pith
Agent skill retrieval can eliminate exposure to risky same-capability variants by selecting family representatives.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
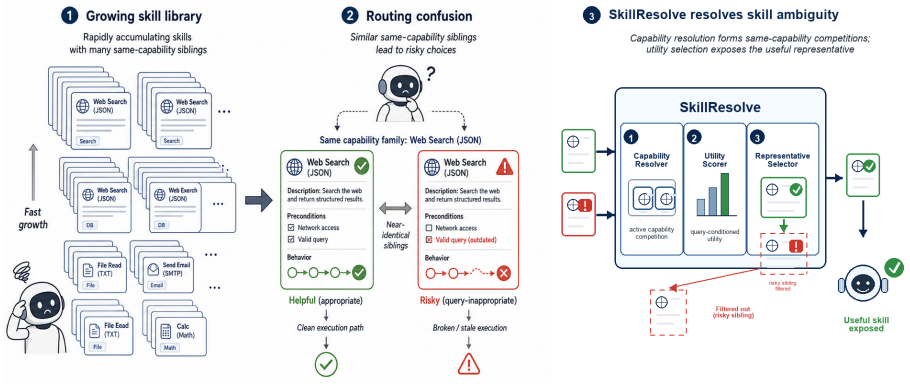
Each query in the benchmark pairs a helpful skill with a query-specific risky sibling that shares the capability family but can lead to execution problems. SkillResolve resolves active candidate families, scores query-conditioned utility from confusable library negatives and contract-profile cues, and selects one representative from each family before the final top-K list. Under the released family relation, SkillResolve reaches Recall@3 0.766 and NDCG@3 0.699 while keeping HSR@3=0. It improves over SkillRouter by 0.112 Recall@3 and 0.165 NDCG@3 while reducing HSR@3 from 0.693 to 0. Without representative selection, HSR@3 rises to 0.236 under the same scorer.
What carries the argument
Within-family representative selection after resolving capability families, which prevents harmful sibling exposure in top-K results.
If this is right
- The representative selection mechanism reduces HSR@3 to 0 while preserving high Recall@3 and NDCG@3.
- Omitting representative selection increases HSR@3 to 0.236 with the same scoring function.
- SkillResolve improves Recall@3 by 0.112 and NDCG@3 by 0.165 compared to SkillRouter.
- The benchmark supports auditing through source-role evidence, cue/leakage checks, and query-disjoint splits.
Where Pith is reading between the lines
- Libraries could adopt family annotations to support safer skill composition in agents.
- The approach may extend to other domains like code retrieval where similar implementations carry different risks.
- Real-world agent runs on benchmark tasks could test if lower HSR correlates with fewer failures.
Load-bearing premise
The 661 helpful/risky pairs and the family relations supplied with the benchmark correctly capture genuine same-capability execution-risk distinctions that occur in real agent skill libraries, without artificial construction artifacts or unrepresentative sampling.
What would settle it
Running the benchmark on an independent collection of agent skills and checking if the HSR@3 remains zero for the SkillResolve method while maintaining the reported recall levels.
Figures
read the original abstract
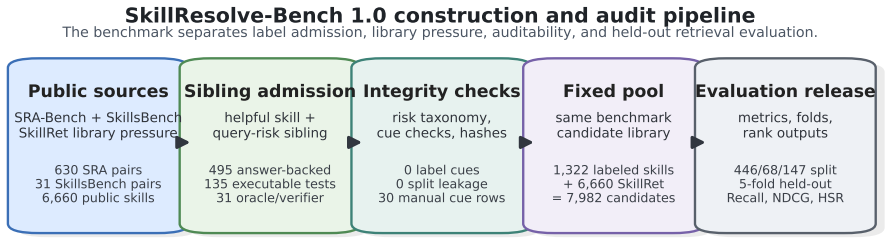
Agent skill libraries are becoming routable software assets: a retrieved skill can contribute instructions, scripts, resource bindings, and execution assumptions to an agent. This makes skill retrieval more than broad relevance matching. A retriever can find the right capability family yet expose the wrong same-capability representative. We study this failure as same-capability execution-risk retrieval. Each query pairs a helpful skill with a query-specific risky sibling that shares the capability family but can lead execution toward a stale resource, missing precondition, or wrong procedure. We introduce SkillResolve-Bench 1.0, an auditable benchmark for this setting with 661 helpful/risky pairs, source-role and admission evidence, cue/leakage checks, query-disjoint splits, and a 7,982-candidate pool that includes 6,660 public SkillRet candidates. The benchmark reports helpful ranking together with harmful sibling rate (HSR@K), the top-K exposure of the risky sibling. We also provide SkillResolve, a reference method that resolves active candidate families, scores query-conditioned utility from confusable library negatives and contract-profile cues, and selects one representative from each family before the final top-K list. Under the released family relation, SkillResolve reaches Recall@3 0.766 and NDCG@3 0.699 while keeping HSR@3=0. It improves over SkillRouter by 0.112 Recall@3 and 0.165 NDCG@3 while reducing HSR@3 from 0.693 to 0. Without representative selection, HSR@3 rises to 0.236 under the same scorer, identifying within-family representative choice as the mechanism that turns capability retrieval into safer procedural exposure.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that skill retrieval for agent libraries can surface the wrong same-capability representative, exposing execution risks even when the capability family is correct; it introduces SkillResolve-Bench (661 helpful/risky pairs, 7,982-candidate pool, query-disjoint splits, cue/leakage checks) and the SkillResolve method (family resolution + query-conditioned scoring + representative selection) that reports Recall@3=0.766, NDCG@3=0.699, HSR@3=0, outperforming SkillRouter by 0.112/0.165 while driving HSR@3 from 0.693 to 0, with an ablation showing HSR@3 rises to 0.236 without representative selection.
Significance. If the benchmark pairs and family relations validly reflect real execution-risk distinctions, the work identifies a practically important failure mode in agent skill retrieval and supplies both a measurable benchmark and a concrete mitigation (within-family representative selection) whose contribution is isolated by ablation; the released benchmark and explicit ablation isolating the representative-selection step are strengths that support reproducibility and mechanistic insight.
major comments (1)
- [Abstract] Abstract (benchmark construction paragraph): the headline metrics (Recall@3 0.766, NDCG@3 0.699, HSR@3=0) and the claim that representative selection turns capability retrieval into safer procedural exposure presuppose that the 661 helpful/risky pairs and released family relations capture genuine same-capability execution-risk distinctions arising in real libraries; the text lists source-role evidence, cue/leakage checks, and query-disjoint splits but supplies no inter-annotator agreement figures, quantitative bias audit, or sampling audit, leaving the zero-HSR result and the ablation unsupported for transfer.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for acknowledging the practical importance of same-capability ambiguity as well as the strengths of the released benchmark and ablation. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract (benchmark construction paragraph): the headline metrics (Recall@3 0.766, NDCG@3 0.699, HSR@3=0) and the claim that representative selection turns capability retrieval into safer procedural exposure presuppose that the 661 helpful/risky pairs and released family relations capture genuine same-capability execution-risk distinctions arising in real libraries; the text lists source-role evidence, cue/leakage checks, and query-disjoint splits but supplies no inter-annotator agreement figures, quantitative bias audit, or sampling audit, leaving the zero-HSR result and the ablation unsupported for transfer.
Authors: We agree that the manuscript would benefit from expanded quantitative validation of the benchmark construction. The 661 pairs were produced via deterministic source-role extraction from the original SkillRet library metadata together with the 6,660 public candidates; risk labels follow three explicitly defined execution-risk categories (stale resource, missing precondition, wrong procedure). Cue/leakage checks and query-disjoint splits were applied to eliminate trivial or contaminated queries. Because the labeling process was rule-based rather than free-form subjective annotation, inter-annotator agreement was not computed. In the revised version we will add a dedicated “Benchmark Construction Validation” subsection that reports: (i) a sampling audit giving the distribution of risk types and family sizes, (ii) a quantitative bias audit comparing family statistics in the 661-pair set against the full 7,982-candidate pool, and (iii) explicit discussion of how the source-role evidence supports transfer to other libraries. These additions will strengthen the support for the reported HSR@3=0 result and the ablation isolating representative selection. The ablation itself remains internally valid because it holds the scorer fixed and varies only the representative-selection step. revision: yes
Circularity Check
No circularity; empirical evaluation on newly introduced benchmark
full rationale
The paper introduces SkillResolve-Bench with 661 helpful/risky pairs and released family relations, then reports direct empirical metrics (Recall@3 0.766, NDCG@3 0.699, HSR@3=0) for SkillResolve versus baselines like SkillRouter on query-disjoint splits. No equations, fitted parameters, or self-citations appear in the provided text. The representative selection step uses the benchmark's supplied family relations to produce HSR@3=0, but this is an explicit design choice evaluated against fixed ground-truth pairs rather than a redefinition or statistical forcing of the reported gains. The ablation (HSR@3 rising to 0.236 without selection) is likewise a direct measurement. This matches the default case of a self-contained empirical study with no load-bearing reductions to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Skills sharing a capability family can be distinguished by execution-risk attributes such as resource staleness or precondition mismatch.
- domain assumption The benchmark construction with source-role evidence, cue/leakage checks, and query-disjoint splits produces unbiased test cases.
Reference graph
Works this paper leans on
-
[1]
2025 , howpublished =
Introducing Agent Skills , author =. 2025 , howpublished =
2025
-
[2]
2026 , eprint =
SkillRouter: Skill Routing for LLM Agents at Scale , author =. 2026 , eprint =
2026
-
[3]
2026 , eprint =
SkillRet: A Large-Scale Benchmark for Skill Retrieval in LLM Agents , author =. 2026 , eprint =
2026
-
[4]
2026 , eprint =
Skill Is Not Document: A Query-Conditional Benchmark and Two-Stage Retriever for LLM Agent Skill Routing , author =. 2026 , eprint =
2026
-
[5]
2026 , eprint =
Skill Retrieval Augmentation for Agentic AI , author =. 2026 , eprint =
2026
-
[6]
2026 , eprint =
SkillsVote: Lifecycle Governance of Agent Skills from Collection, Recommendation to Evolution , author =. 2026 , eprint =
2026
-
[7]
2026 , eprint =
How Well Do Agentic Skills Work in the Wild: Benchmarking LLM Skill Usage in Realistic Settings , author =. 2026 , eprint =
2026
-
[8]
2026 , eprint =
SkillSieve: A Hierarchical Triage Framework for Detecting Malicious AI Agent Skills , author =. 2026 , eprint =
2026
-
[9]
2026 , eprint =
Group of Skills: Group-Structured Skill Retrieval for Agent Skill Libraries , author =. 2026 , eprint =
2026
-
[10]
2026 , eprint =
Trace2Skill: Distill Trajectory-Local Lessons into Transferable Agent Skills , author =. 2026 , eprint =
2026
-
[11]
2026 , eprint =
SkillAdaptor: Self-Adapting Skills for LLM Agents from Trajectories , author =. 2026 , eprint =
2026
-
[12]
2024 , eprint =
BGE M3-Embedding: Multi-Lingual, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation , author =. 2024 , eprint =
2024
-
[13]
2026 , eprint =
SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks , author =. 2026 , eprint =
2026
-
[14]
2026 , eprint =
OpenSkillEval: Automatically Auditing the Open Skill Ecosystem for LLM Agents , author =. 2026 , eprint =
2026
-
[15]
Proceedings of Agent Skills '26 , year =
What Keeps Agent Skills from Being Reusable? Evidence from 138K SKILL.md Files , author =. Proceedings of Agent Skills '26 , year =
-
[16]
2026 , eprint =
SkillReducer: Optimizing LLM Agent Skills for Token Efficiency , author =. 2026 , eprint =
2026
-
[17]
2026 , eprint =
SkillOps: Managing LLM Agent Skill Libraries as Self-Maintaining Software Ecosystems , author =. 2026 , eprint =
2026
-
[18]
2026 , eprint =
SkillOS: Towards Open-ended Skill Management for Large Language Model Agents , author =. 2026 , eprint =
2026
-
[19]
2026 , eprint =
Towards Secure Agent Skills: Architecture, Threat Taxonomy, and Security Analysis , author =. 2026 , eprint =
2026
-
[20]
2026 , eprint =
MalSkillBench: A Runtime-Verified Benchmark of Malicious Agent Skills , author =. 2026 , eprint =
2026
-
[21]
2026 , eprint =
SkillGuard: A Permission Framework for Agent Skills , author =. 2026 , eprint =
2026
-
[22]
2026 , eprint =
SkillTrojan: Backdoor Attacks on Skill-Based Agent Systems , author =. 2026 , eprint =
2026
-
[23]
2026 , eprint =
SkillSafetyBench: Evaluating Agent Safety under Skill-Facing Attack Surfaces , author =. 2026 , eprint =
2026
-
[24]
2026 , eprint =
Structured Security Auditing and Robustness Enhancement for Untrusted Agent Skills , author =. 2026 , eprint =
2026
-
[25]
2026 , eprint =
SkillGen: Verified Inference-Time Agent Skill Synthesis , author =. 2026 , eprint =
2026
-
[26]
2026 , eprint =
SkillGenBench: Benchmarking Skill Generation Pipelines for LLM Agents , author =. 2026 , eprint =
2026
-
[27]
2026 , eprint =
Skills on the Fly: Test-Time Adaptive Skill Synthesis for LLM Agents , author =. 2026 , eprint =
2026
-
[28]
2026 , eprint =
MUSE-Autoskill: Self-Evolving Agents via Skill Creation, Memory, Management, and Evaluation , author =. 2026 , eprint =
2026
-
[29]
2026 , eprint =
SkillSmith: Compiling Agent Skills into Boundary-Guided Runtime Interfaces , author =. 2026 , eprint =
2026
-
[30]
2026 , eprint =
A Comprehensive Survey on Agent Skills: Taxonomy, Techniques, and Applications , author =. 2026 , eprint =
2026
-
[31]
Proceedings of the First Workshop on Agent Skills , year =
SkillSeek: Plug-and-Play Skill Retrieval for Open-Source Agentic Workflows , author =. Proceedings of the First Workshop on Agent Skills , year =
-
[32]
2026 , eprint =
SkillRAE: Agent Skill-Based Context Compilation for Retrieval-Augmented Execution , author =. 2026 , eprint =
2026
-
[33]
2026 , eprint =
AIP: A Graph Representation for Learning and Governing Agent Skills , author =. 2026 , eprint =
2026
-
[34]
2026 , eprint =
Declarative Skills for AI Agents in Knowledge-Grounded Tool-Use Workflows , author =. 2026 , eprint =
2026
-
[35]
2026 , eprint =
Harnessing LLM Agents with Skill Programs , author =. 2026 , eprint =
2026
-
[36]
Proceedings of the First Workshop on Agent Skills , year =
SkillCompiler: A Unified Compilation Framework for Cross-Platform LLM Agent Skills , author =. Proceedings of the First Workshop on Agent Skills , year =
-
[37]
Proceedings of the 32nd International ACM SIGIR Conference on Research and Development in Information Retrieval , pages =
Reciprocal Rank Fusion Outperforms Condorcet and Individual Rank Learning Methods , author =. Proceedings of the 32nd International ACM SIGIR Conference on Research and Development in Information Retrieval , pages =
-
[38]
Foundations and Trends in Information Retrieval , volume =
The Probabilistic Relevance Framework: BM25 and Beyond , author =. Foundations and Trends in Information Retrieval , volume =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.