AgenticNav: Zero-Shot Vision-and-Language Navigation as a Tool-Calling Harness
Pith reviewed 2026-06-27 13:33 UTC · model grok-4.3
The pith
AgenticNav lets vision-language models navigate continuous spaces by calling tools for pixel actions, depth, and selective memory recall.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
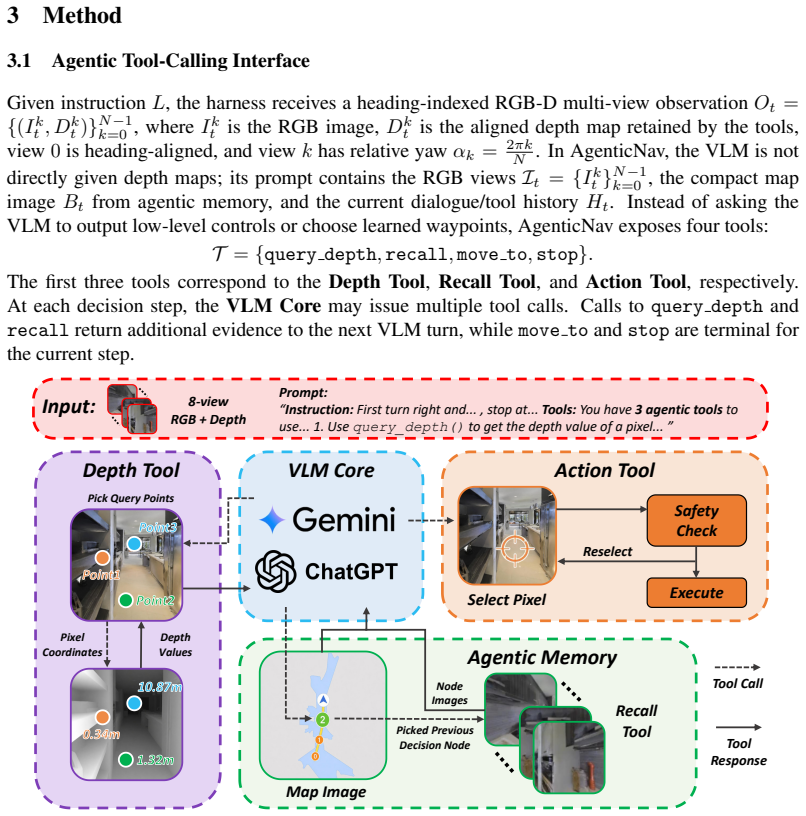
AgenticNav is a lightweight navigation harness that exposes action, depth, and memory as callable tools to a vision-language model. The action tool converts a chosen pixel in an RGB image into executable motion, the depth tool returns metric distance for any requested pixel, and the memory tool supplies a compact trajectory map together with selective recall of past visual observations. This interface replaces waypoint predictors and long textual histories. On the R2R-CE benchmark the method sets new state-of-the-art performance among zero-shot approaches using the same VLM backbone and shows stronger real-world generalization than prior methods.
What carries the argument
The agentic tool-calling harness that turns VLM outputs into direct pixel-based actions, on-demand depth values, and selective recall from a compact map image.
If this is right
- Direct pixel-based action selection removes the restriction that waypoint predictors place on the model's action space.
- On-demand depth queries supply metric information only where the model requests it, avoiding unnecessary depth input.
- The compact map plus selective recall tool keeps memory relevant and prevents prompt overload from long histories.
- The overall harness yields higher success rates on R2R-CE than previous zero-shot methods that share the same VLM.
- Real-world robot trials confirm better zero-shot transfer than waypoint-based baselines.
Where Pith is reading between the lines
- The same tool-exposure pattern could be applied to other embodied tasks such as manipulation or exploration where VLMs currently rely on learned predictors.
- Selective recall from a compact map offers a general way to manage context length in any long-horizon agentic system that uses VLMs.
- If pixel-level action selection proves robust, it may reduce the need to train separate low-level controllers for many navigation domains.
- The design invites experiments that add further tools, such as semantic object queries, to the same harness.
Load-bearing premise
The vision-language model can interpret the new tools and use them to choose effective navigation actions without the crutches of waypoint predictors or full history accumulation.
What would settle it
An ablation on R2R-CE in which the same VLM backbone is run once with the full tool harness and once with the action tool replaced by a standard waypoint predictor; if the tool version no longer outperforms prior zero-shot baselines, the central claim is falsified.
Figures


read the original abstract
Zero-shot vision-and-language navigation in continuous environments (VLN-CE) has recently become feasible with large vision-language models (VLMs). However, existing methods typically rely on learned waypoint predictors to propose navigable actions. This severely limits the model's action space and fails to leverage depth inputs effectively. Moreover, memory is commonly handled by accumulating long textual or visual histories with substantial irrelevant context, or by retrieving cross-episode experiences, which weakens the zero-shot setting. In this paper, we rethink zero-shot VLN-CE as an agentic interface between the VLM and the environment, and present AgenticNav, a lightweight navigation harness that exposes action, depth, and memory as callable tools. Instead of choosing from predicted waypoints, the action tool allows the VLM to directly select a target pixel in RGB observations, converting it into executable motion. Depth is exposed through an on-demand pixel-depth tool, enabling the VLM to request precise metric distances only where they matter. For memory, AgenticNav provides a compact map image summarizing the historical trajectory, paired with a recall tool that allows the VLM to selectively revisit past visual observations without overwhelming the prompt context. On the R2R-CE benchmark, AgenticNav establishes new state-of-the-art (SOTA) performance among zero-shot methods given the same VLM backbone. Real-world validation further highlights its zero-shot generalization compared to prior methods. Ablations show that our action tool design outperforms traditional waypoint predictors, and that depth tool and agentic memory further contribute to navigation performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces AgenticNav, a lightweight tool-calling harness that reformulates zero-shot VLN-CE as an agentic interface between a VLM and the environment. It replaces learned waypoint predictors with a pixel-selection action tool that converts chosen RGB pixels to motion, adds an on-demand pixel-depth query tool, and implements memory via a compact map image paired with a selective-recall tool. The central empirical claim is that this design yields new state-of-the-art performance on the R2R-CE benchmark among zero-shot methods that use the identical VLM backbone, with supporting real-world validation and ablations that attribute gains to the individual tools.
Significance. If the reported gains are reproducible and statistically supported, the work could meaningfully advance zero-shot navigation by showing that direct, callable tools can outperform auxiliary learned modules while preserving the zero-shot setting. The selective-recall memory mechanism addresses a common context-overload problem in long-horizon VLN and may generalize to other agentic VLM applications.
major comments (3)
- [Abstract] Abstract: the claim that AgenticNav 'establishes new state-of-the-art (SOTA) performance' on R2R-CE is presented without any numerical results (success rate, SPL, NE, etc.), error bars, dataset splits, or references to tables/figures that would allow verification of the magnitude or statistical significance of the improvement over prior zero-shot baselines using the same VLM.
- [Abstract] Abstract: the action tool is described as allowing the VLM to 'directly select a target pixel in RGB observations, converting it into executable motion,' yet no concrete mechanism, camera model, or motion primitive is specified; without this, it is impossible to evaluate whether the tool actually expands the action space beyond the limitations attributed to waypoint predictors.
- [Abstract] Abstract: the ablations are asserted to show that 'our action tool design outperforms traditional waypoint predictors, and that depth tool and agentic memory further contribute,' but no quantitative ablation results, baseline definitions, or section references are supplied, leaving the load-bearing empirical support for the tool-design choices unverified.
minor comments (1)
- [Abstract] The abstract would be clearer if it named the specific VLM backbone used for the reported comparisons.
Simulated Author's Rebuttal
We thank the referee for the constructive comments focused on the abstract. We agree that the abstract should be revised to include key quantitative results, section references, and brief clarifications to make the claims verifiable. We address each point below and will incorporate the changes in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that AgenticNav 'establishes new state-of-the-art (SOTA) performance' on R2R-CE is presented without any numerical results (success rate, SPL, NE, etc.), error bars, dataset splits, or references to tables/figures that would allow verification of the magnitude or statistical significance of the improvement over prior zero-shot baselines using the same VLM.
Authors: We agree that the abstract would benefit from explicit metrics and references. In the revision we will update the abstract to state the success rate, SPL, and NE achieved on the R2R-CE val-unseen split, note that results are reported with standard deviations across runs, and add a direct reference to Table 1 and Section 4.1, where the full comparison against prior zero-shot methods that use the identical VLM backbone is presented. revision: yes
-
Referee: [Abstract] Abstract: the action tool is described as allowing the VLM to 'directly select a target pixel in RGB observations, converting it into executable motion,' yet no concrete mechanism, camera model, or motion primitive is specified; without this, it is impossible to evaluate whether the tool actually expands the action space beyond the limitations attributed to waypoint predictors.
Authors: The abstract intentionally remains high-level. The concrete implementation—projection of the selected pixel through the camera intrinsics, on-demand depth query for metric scaling, and the resulting motion primitive—is fully specified in Section 3.2. We will add a short parenthetical phrase in the abstract (“via camera projection and depth-guided motion primitive”) to indicate the mechanism without lengthening the text excessively, while retaining the pointer to the method section. revision: partial
-
Referee: [Abstract] Abstract: the ablations are asserted to show that 'our action tool design outperforms traditional waypoint predictors, and that depth tool and agentic memory further contribute,' but no quantitative ablation results, baseline definitions, or section references are supplied, leaving the load-bearing empirical support for the tool-design choices unverified.
Authors: We acknowledge the abstract’s reference to ablations is too terse. The quantitative results, baseline definitions (learned waypoint predictors from prior work), and per-tool contributions are reported in Section 4.3 and Table 3. In the revised abstract we will insert a concise clause (“Ablations in Section 4.3 show the action tool outperforms waypoint predictors, with further gains from the depth tool and agentic memory”) together with the table reference. revision: yes
Circularity Check
No significant circularity; empirical method with benchmark evaluation
full rationale
The paper describes an agentic tool-calling harness for zero-shot VLN-CE, exposing pixel-action, depth, and selective-recall map tools to a VLM. Central claims rest on R2R-CE benchmark results and ablations showing tool utility over waypoint predictors. No equations, fitted parameters, derivations, or self-citation chains are present that reduce any result to inputs by construction. Evaluation is externally falsifiable via standard benchmarks and does not invoke uniqueness theorems or prior author work as load-bearing premises. This is a standard empirical systems contribution with no circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Large vision-language models can effectively utilize tool-calling interfaces for navigation tasks without additional training or fine-tuning.
invented entities (3)
-
Pixel-selection action tool
no independent evidence
-
On-demand pixel-depth tool
no independent evidence
-
Compact map image with recall tool
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Anderson, Q
P. Anderson, Q. Wu, D. Teney, J. Bruce, M. Johnson, N. S ¨underhauf, I. Reid, S. Gould, and A. van den Hengel. Vision-and-language navigation: Interpreting visually-grounded naviga- tion instructions in real environments. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018
2018
-
[2]
Krantz, E
J. Krantz, E. Wijmans, A. Majumdar, D. Batra, and S. Lee. Beyond the nav-graph: Vision-and- language navigation in continuous environments. InProceedings of the European Conference on Computer Vision (ECCV), 2020
2020
-
[3]
Y . Qiao, W. Lyu, H. Wang, Z. Wang, Z. Li, Y . Zhang, M. Tan, and Q. Wu. Open-nav: Exploring zero-shot vision-and-language navigation in continuous environment with open-source llms. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), 2025
2025
-
[4]
X. Shi, Z. Li, W. Lyu, J. Xia, F. Dayoub, Y . Qiao, and Q. Wu. Smartway: Enhanced waypoint prediction and backtracking for zero-shot vision-and-language navigation. InProceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2025
2025
-
[5]
G. Dai, S. Wang, Z. Wang, G.-S. Xie, Y . Yang, J. Pan, Q. Sun, and X. Shu. History to fu- ture: Evolving agent with experience and thought for zero-shot vision-and-language naviga- tion. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2026
2026
-
[6]
Fried, R
D. Fried, R. Hu, V . Cirik, A. Rohrbach, J. Andreas, L.-P. Morency, T. Berg-Kirkpatrick, K. Saenko, D. Klein, and T. Darrell. Speaker-follower models for vision-and-language navi- gation. InAdvances in Neural Information Processing Systems (NeurIPS), 2018
2018
-
[7]
C.-Y . Ma, Z. Wu, G. AlRegib, C. Xiong, and Z. Kira. The regretful agent: Heuristic-aided navigation through progress estimation. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019
2019
-
[8]
F. Zhu, Y . Zhu, X. Chang, and X. Liang. Vision-language navigation with self-supervised auxiliary reasoning tasks. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2020
2020
-
[9]
W. Hao, C. Li, X. Li, L. Carin, and J. Gao. Towards learning a generic agent for vision-and- language navigation via pre-training. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2020
2020
-
[10]
Guhur, M
P.-L. Guhur, M. Tapaswi, S. Chen, I. Laptev, and C. Schmid. Airbert: In-domain pretraining for vision-and-language navigation. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2021
2021
-
[11]
Z. Wang, J. Li, Y . Hong, Y . Wang, Q. Wu, M. Bansal, S. Gould, H. Tan, and Y . Qiao. Scaling data generation in vision-and-language navigation. InProceedings of the IEEE/CVF Interna- tional Conference on Computer Vision (ICCV), 2023
2023
-
[12]
Krantz, A
J. Krantz, A. Gokaslan, D. Batra, S. Lee, and O. Maksymets. Waypoint models for instruction- guided navigation in continuous environments. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2021
2021
-
[13]
Y . Hong, Z. Wang, Q. Wu, and S. Gould. Bridging the gap between learning in discrete and continuous environments for vision-and-language navigation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022
2022
-
[14]
Chen, P.-L
S. Chen, P.-L. Guhur, M. Tapaswi, C. Schmid, and I. Laptev. Think global, act local: Dual- scale graph transformer for vision-and-language navigation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022. 9
2022
-
[15]
D. An, Y . Qi, Y . Li, Y . Huang, L. Wang, T. Tan, and J. Shao. Bevbert: Multimodal map pre-training for language-guided navigation. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023
2023
-
[16]
D. An, H. Wang, W. Wang, Z. Wang, Y . Huang, K. He, and L. Wang. Etpnav: Evolving topological planning for vision-language navigation in continuous environments.IEEE Trans- actions on Pattern Analysis and Machine Intelligence (TPAMI), 47(7), 2025
2025
-
[17]
Z. Wang, X. Li, J. Yang, Y . Liu, and S. Jiang. Gridmm: Grid memory map for vision-and- language navigation. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023
2023
-
[18]
Zheng, S
D. Zheng, S. Huang, L. Zhao, Y . Zhong, and L. Wang. Towards learning a generalist model for embodied navigation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[19]
Zhang, K
J. Zhang, K. Wang, R. Xu, G. Zhou, Y . Hong, X. Fang, Q. Wu, Z. Zhang, and H. Wang. Navid: Video-based vlm plans the next step for vision-and-language navigation. InProceedings of Robotics: Science and Systems (RSS), 2024
2024
-
[20]
Cheng, Y
A.-C. Cheng, Y . Ji, Z. Yang, Z. Gongye, X. Zou, J. Kautz, E. Biyik, H. Yin, S. Liu, and X. Wang. Navila: Legged robot vision-language-action model for navigation. InProceedings of Robotics: Science and Systems (RSS), 2025
2025
-
[21]
Ichter, A
B. Ichter, A. Brohan, Y . Chebotar, C. Finn, K. Hausman, A. Herzog, D. Ho, J. Ibarz, A. Ir- pan, E. Jang, R. Julian, D. Kalashnikov, S. Levine, Y . Lu, C. Parada, K. Rao, P. Sermanet, A. T. Toshev, V . Vanhoucke, F. Xia, T. Xiao, P. Xu, M. Yan, N. Brown, M. Ahn, O. Cortes, N. Sievers, C. Tan, S. Xu, D. Reyes, J. Rettinghouse, J. Quiambao, P. Pastor, L. Lu...
2023
-
[22]
C. H. Song, J. Wu, C. Washington, B. M. Sadler, W.-L. Chao, and Y . Su. LLM-Planner: Few- shot grounded planning for embodied agents with large language models. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), October 2023
2023
-
[23]
P. Chen, X. Sun, H. Zhi, R. Zeng, T. H. Li, G. Liu, M. Tan, and C. Gan.A 2Nav: Action-aware zero-shot robot navigation by exploiting vision-and-language ability of foundation models,
- [24]
-
[25]
G. Zhou, Y . Hong, and Q. Wu. Navgpt: Explicit reasoning in vision-and-language navigation with large language models. InProceedings of the AAAI Conference on Artificial Intelligence (AAAI), volume 38, 2024
2024
-
[26]
Y . Long, X. Li, W. Cai, and H. Dong. Discuss before moving: Visual language navigation via multi-expert discussions. InProceedings of the IEEE International Conference on Robotics and Automation (ICRA), 2024
2024
-
[27]
J. Chen, B. Lin, R. Xu, Z. Chai, X. Liang, and K.-Y . Wong. MapGPT: Map-guided prompting with adaptive path planning for vision-and-language navigation. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL), Volume 1: Long Pa- pers. Association for Computational Linguistics, 2024
2024
-
[28]
Y . Long, W. Cai, H. Wang, G. Zhan, and H. Dong. Instructnav: Zero-shot system for generic instruction navigation in unexplored environment. InProceedings of The 8th Conference on Robot Learning (CoRL), volume 270 ofProceedings of Machine Learning Research. PMLR, 2025. 10
2025
- [29]
-
[30]
Huang, F
W. Huang, F. Xia, T. Xiao, H. Chan, J. Liang, P. Florence, A. Zeng, J. Tompson, I. Mordatch, Y . Chebotar, P. Sermanet, T. Jackson, N. Brown, L. Luu, S. Levine, K. Hausman, and B. Ichter. Inner monologue: Embodied reasoning through planning with language models. InProceed- ings of The 6th Conference on Robot Learning (CoRL), volume 205 ofProceedings of Ma...
2023
-
[31]
Liang, W
J. Liang, W. Huang, F. Xia, P. Xu, K. Hausman, B. Ichter, P. Florence, and A. Zeng. Code as policies: Language model programs for embodied control. InProceedings of the IEEE International Conference on Robotics and Automation (ICRA), 2023
2023
-
[32]
D. Shah, B. Osinski, B. Ichter, and S. Levine. Lm-nav: Robotic navigation with large pre- trained models of language, vision, and action. InProceedings of The 6th Conference on Robot Learning (CoRL), volume 205 ofProceedings of Machine Learning Research. PMLR, 2023
2023
-
[33]
Rajvanshi, K
A. Rajvanshi, K. Sikka, X. Lin, B. Lee, H.-P. Chiu, and A. Velasquez. Saynav: Grounding large language models for dynamic planning to navigation in new environments. InProceedings of the International Conference on Automated Planning and Scheduling (ICAPS), volume 34, 2024
2024
-
[34]
Driess, F
D. Driess, F. Xia, M. S. M. Sajjadi, C. Lynch, A. Chowdhery, B. Ichter, A. Wahid, J. Tompson, Q. Vuong, T. Yu, W. Huang, Y . Chebotar, P. Sermanet, D. Duckworth, S. Levine, V . Vanhoucke, K. Hausman, M. Toussaint, K. Greff, A. Zeng, I. Mordatch, and P. Florence. PaLM-e: An embodied multimodal language model. InProceedings of the 40th International Confere...
2023
-
[35]
Chandaka, G
B. Chandaka, G. X. Wang, H. Chen, H. Che, A. J. Zhai, and S. Wang. Human-like navigation in a world built for humans. InProceedings of the 9th Conference on Robot Learning (CoRL), 2025. 11
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.