STEDiff: Strengthening Text Embedding for Text-to-Image Alignment in Diffusion Model
Pith reviewed 2026-06-27 13:49 UTC · model grok-4.3
The pith
A training-free method strengthens text embeddings to improve semantic alignment in diffusion-based image generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
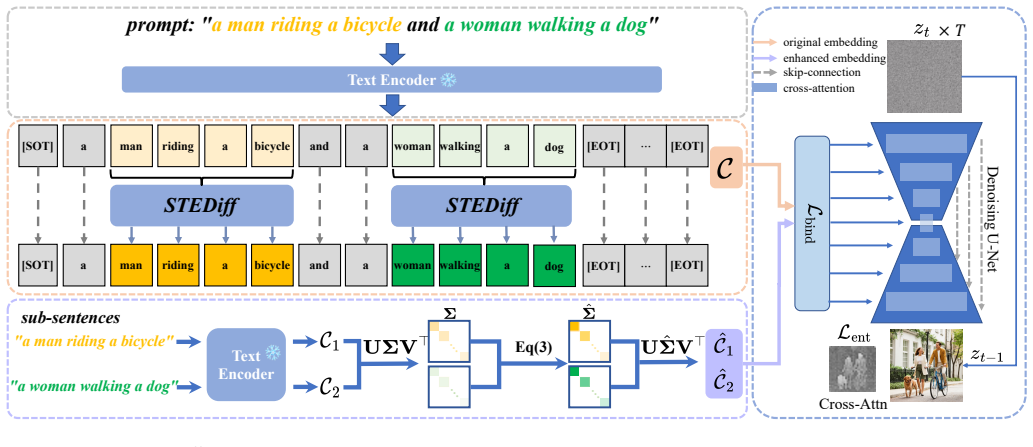
STEDiff enhances semantic representations in the text-embedding space by leveraging the [EOT] token to strengthen the relevant semantics of sub-sentences and replacing the corresponding tokens in the original prompt, while incorporating a novel semantic enhancement loss to enforce spatial constraints that map each entity's semantics to its respective image region.
What carries the argument
The [EOT] token used to strengthen sub-sentence semantics in the text embedding, combined with token replacement and a semantic enhancement loss for spatial constraints.
If this is right
- The method notably improves semantic consistency and generation integrity in complex scenarios on T2I-CompBench.
- It serves as a computationally efficient alternative to fine-tuning or layout priors.
- The spatial constraints in the loss ensure precise mapping of entity semantics to image regions.
Where Pith is reading between the lines
- The embedding adjustment could integrate into existing diffusion pipelines for handling more intricate prompts at inference time.
- The technique might apply to other text-conditioned generation tasks beyond images.
- Testing on additional benchmarks could reveal whether the approach generalizes across different model architectures.
Load-bearing premise
Directly strengthening sub-sentence semantics via the [EOT] token and applying the semantic enhancement loss will produce precise entity-to-region mappings in the generated image without introducing new artifacts or requiring any model adaptation.
What would settle it
If images generated from complex prompts on T2I-CompBench still show missing objects or incorrect attribute bindings after applying the STEDiff embedding changes, the claim of improved alignment would be falsified.
Figures





read the original abstract
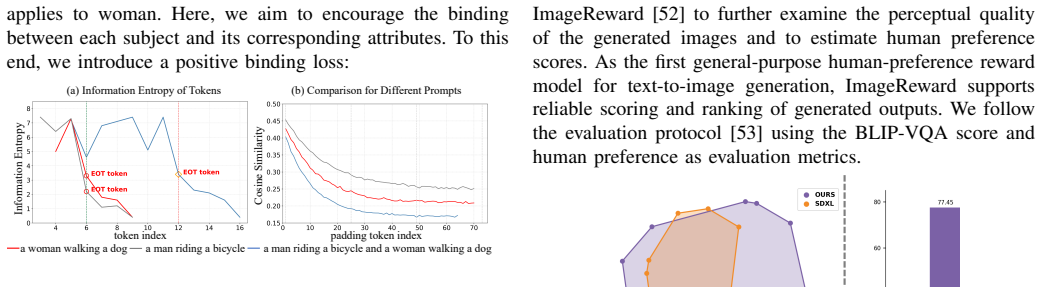
Although pretrained text-to-image (T2I) generation models can produce high-quality images, they often fail to faithfully reflect the semantic intent of complex prompts due to stochastic noise and inherent model limitations. This issue frequently manifests as the model overlooking specific objects or failing to correctly bind attributes to their corresponding entities, a challenge referred to as semantic alignment. Unlike existing approaches that rely on computationally expensive fine-tuning or labor-intensive layout priors, we propose STEDiff, a training-free method designed to enhance semantic representations directly within the text-embedding space. Specifically, we introduce a method that primarily leverages the [EOT] token to strengthen the relevant semantics of sub-sentences and then replaces the corresponding tokens in the original prompt. Furthermore, a novel semantic enhancement loss is incorporated to enforce spatial constraints, ensuring that the semantics of each entity are precisely mapped to their respective image regions. Extensive quantitative and qualitative evaluations on the T2I-CompBench demonstrate that our method notably improves semantic consistency and generation integrity in complex scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes STEDiff, a training-free method to improve semantic alignment in pretrained text-to-image diffusion models for complex prompts. It strengthens sub-sentence semantics by leveraging the [EOT] token to enhance relevant embeddings and replaces tokens in the original prompt, then applies a novel semantic enhancement loss to enforce spatial constraints that map each entity's semantics to corresponding image regions. Quantitative and qualitative results on T2I-CompBench are reported to show gains in semantic consistency and generation integrity.
Significance. A training-free embedding-space intervention that reliably produces precise entity-to-region bindings would be a useful, low-cost addition to the T2I alignment literature. However, the central mechanism (how a purely token-level loss translates semantic signals into spatially accurate denoising trajectories without explicit cross-attention or image-space terms) is not shown to be load-bearing or robust; if the loss reduces to implicit model behavior, the claimed improvements would not generalize beyond the evaluated benchmark.
major comments (1)
- [Abstract] Abstract: the claim that the semantic enhancement loss 'ensures that the semantics of each entity are precisely mapped to their respective image regions' is not supported by any described dependence on cross-attention maps, positional encodings, or image-space terms. Without such dependence, the loss cannot be guaranteed to produce the required spatial bindings from embedding modifications alone.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the semantic enhancement loss 'ensures that the semantics of each entity are precisely mapped to their respective image regions' is not supported by any described dependence on cross-attention maps, positional encodings, or image-space terms. Without such dependence, the loss cannot be guaranteed to produce the required spatial bindings from embedding modifications alone.
Authors: We agree that the abstract wording overstates the mechanism. The semantic enhancement loss is applied to the strengthened embeddings to encourage spatial consistency, but the manuscript does not describe explicit dependence on cross-attention maps, positional encodings, or image-space terms; any spatial effect arises implicitly through the diffusion process. We will revise the abstract to replace 'ensures that the semantics of each entity are precisely mapped' with 'encourages improved mapping of entity semantics to image regions' and will similarly qualify the claim in the main text. The reported gains on T2I-CompBench remain as empirical evidence. revision: yes
Circularity Check
No circularity: training-free embedding edits and external benchmark evaluation remain independent of fitted inputs or self-citation chains
full rationale
The paper describes a training-free procedure that strengthens sub-sentence semantics via the [EOT] token, token replacement, and a novel semantic enhancement loss to enforce spatial constraints in embedding space. No equations or steps reduce a claimed prediction to a fitted parameter by construction, no load-bearing self-citations are invoked to justify uniqueness or ansatzes, and the quantitative results are reported against the external T2I-CompBench benchmark rather than internal data splits. The derivation chain therefore consists of explicit, externally verifiable modifications to existing diffusion-model components without tautological closure.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
ediff-i: Text-to-image diffu- sion models with an ensemble of expert denoisers,
Y . Balaji, S. Nah, X. Huang, A. Vahdat, J. Song, Q. Zhang, K. Kreis, M. Aittala, T. Aila, S. Laine,et al., “ediff-i: Text-to-image diffu- sion models with an ensemble of expert denoisers,”arXiv preprint arXiv:2211.01324, 2022
Pith/arXiv arXiv 2022
-
[2]
Zero-shot text-to-image generation,
A. Ramesh, M. Pavlov, G. Goh, S. Gray, C. V oss, A. Radford, M. Chen, and I. Sutskever, “Zero-shot text-to-image generation,” inInternational conference on machine learning, pp. 8821–8831, Pmlr, 2021
2021
-
[3]
Photorealistic text-to-image diffusion models with deep language understanding,
C. Saharia, W. Chan, S. Saxena, L. Li, J. Whang, E. L. Denton, K. Ghasemipour, R. Gontijo Lopes, B. Karagol Ayan, T. Salimans, et al., “Photorealistic text-to-image diffusion models with deep language understanding,”Advances in neural information processing systems, vol. 35, pp. 36479–36494, 2022
2022
-
[4]
Hierarchical text-conditional image generation with clip latents,
A. Ramesh, P. Dhariwal, A. Nichol, C. Chu, and M. Chen, “Hierarchical text-conditional image generation with clip latents,”arXiv preprint arXiv:2204.06125, vol. 1, no. 2, p. 3, 2022
Pith/arXiv arXiv 2022
-
[5]
One stone with two birds: A null-text- null frequency-aware diffusion models for text-guided image inpainting,
H. Liu, Y . Wang, and M. Wang, “One stone with two birds: A null-text- null frequency-aware diffusion models for text-guided image inpainting,” inThe Thirty-ninth Annual Conference on Neural Information Process- ing Systems, 2025
2025
-
[6]
Structure matters: Tackling the semantic discrepancy in diffusion models for image inpaint- ing,
H. Liu, Y . Wang, B. Qian, M. Wang, and Y . Rui, “Structure matters: Tackling the semantic discrepancy in diffusion models for image inpaint- ing,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8038–8047, 2024
2024
-
[7]
Progressive learning with multi-scale attention network for cross-domain vehicle re-identification,
Y . Wang, J. Peng, H. Wang, and M. Wang, “Progressive learning with multi-scale attention network for cross-domain vehicle re-identification,” Science China Information Sciences, vol. 65, no. 6, p. 160103, 2022
2022
-
[8]
Divide & bind your attention for improved generative semantic nursing,
Y . Li, M. Keuper, D. Zhang, and A. Khoreva, “Divide & bind your attention for improved generative semantic nursing,”arXiv preprint arXiv:2307.10864, 2023
arXiv 2023
-
[9]
Sdxl: Improving latent diffusion models for high-resolution image synthesis,
D. Podell, Z. English, K. Lacey, A. Blattmann, T. Dockhorn, J. M ¨uller, J. Penna, and R. Rombach, “Sdxl: Improving latent diffusion models for high-resolution image synthesis,”arXiv preprint arXiv:2307.01952, 2023
Pith/arXiv arXiv 2023
-
[10]
Scaling rectified flow transformers for high-resolution image synthesis,
P. Esser, S. Kulal, A. Blattmann, R. Entezari, J. M ¨uller, H. Saini, Y . Levi, D. Lorenz, A. Sauer, F. Boesel,et al., “Scaling rectified flow transformers for high-resolution image synthesis,” inForty-first international conference on machine learning, 2024
2024
-
[11]
Linguistic binding in diffusion models: Enhancing attribute correspondence through attention map alignment,
R. Rassin, E. Hirsch, D. Glickman, S. Ravfogel, Y . Goldberg, and G. Chechik, “Linguistic binding in diffusion models: Enhancing attribute correspondence through attention map alignment,”Advances in Neural Information Processing Systems, vol. 36, pp. 3536–3559, 2023
2023
-
[12]
Expressive text-to-image generation with rich text,
S. Ge, T. Park, J.-Y . Zhu, and J.-B. Huang, “Expressive text-to-image generation with rich text,” inProceedings of the IEEE/CVF International Conference on Computer Vision, pp. 7545–7556, 2023
2023
-
[13]
Switchable online knowledge distillation,
B. Qian, Y . Wang, H. Yin, R. Hong, and M. Wang, “Switchable online knowledge distillation,” inEuropean Conference on Computer Vision, pp. 449–466, Springer, 2022
2022
-
[14]
Adaptive data-free quantiza- tion,
B. Qian, Y . Wang, R. Hong, and M. Wang, “Adaptive data-free quantiza- tion,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 7960–7968, 2023
2023
-
[15]
Unpacking the gap box against data-free knowledge distillation,
Y . Wang, B. Qian, H. Liu, Y . Rui, and M. Wang, “Unpacking the gap box against data-free knowledge distillation,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 46, no. 9, pp. 6280–6291, 2024
2024
-
[16]
Comat: Aligning text-to-image diffusion model with image- to-text concept matching,
D. Jiang, G. Song, X. Wu, R. Zhang, D. Shen, Z. Zong, Y . Liu, and H. Li, “Comat: Aligning text-to-image diffusion model with image- to-text concept matching,”Advances in Neural Information Processing Systems, vol. 37, pp. 76177–76209, 2024
2024
-
[17]
Ella: Equip diffusion models with llm for enhanced semantic alignment,
X. Hu, R. Wang, Y . Fang, B. Fu, P. Cheng, and G. Yu, “Ella: Equip diffusion models with llm for enhanced semantic alignment,”arXiv preprint arXiv:2403.05135, 2024
Pith/arXiv arXiv 2024
-
[18]
Ranni: Taming text-to-image diffusion for accurate instruction following,
Y . Feng, B. Gong, D. Chen, Y . Shen, Y . Liu, and J. Zhou, “Ranni: Taming text-to-image diffusion for accurate instruction following,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 4744–4753, 2024
2024
-
[19]
Few- shot referring video single-and multi-object segmentation via cross- modal affinity with instance sequence matching,
H. Liu, G. Li, M. Gao, X. Zhen, F. Zheng, and Y . Wang, “Few- shot referring video single-and multi-object segmentation via cross- modal affinity with instance sequence matching,”International Journal of Computer Vision, vol. 133, no. 8, pp. 5610–5628, 2025
2025
-
[20]
Pixart-σ: Weak-to-strong training of diffusion transformer for 4k text-to-image generation,
J. Chen, C. Ge, E. Xie, Y . Wu, L. Yao, X. Ren, Z. Wang, P. Luo, H. Lu, and Z. Li, “Pixart-σ: Weak-to-strong training of diffusion transformer for 4k text-to-image generation,” inEuropean Conference on Computer Vision, pp. 74–91, Springer, 2024
2024
-
[21]
Boxdiff: Text-to-image synthesis with training-free box-constrained diffusion,
J. Xie, Y . Li, Y . Huang, H. Liu, W. Zhang, Y . Zheng, and M. Z. Shou, “Boxdiff: Text-to-image synthesis with training-free box-constrained diffusion,” inProceedings of the IEEE/CVF International Conference on Computer Vision, pp. 7452–7461, 2023
2023
-
[22]
Grounded text-to-image synthesis with attention refocusing,
Q. Phung, S. Ge, and J.-B. Huang, “Grounded text-to-image synthesis with attention refocusing,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 7932–7942, 2024
2024
-
[23]
L. Lian, B. Li, A. Yala, and T. Darrell, “Llm-grounded diffusion: Enhancing prompt understanding of text-to-image diffusion models with large language models,”arXiv preprint arXiv:2305.13655, 2023
arXiv 2023
-
[24]
Llm blueprint: Enabling text-to-image generation with complex and detailed prompts,
H. Gani, S. F. Bhat, M. Naseer, S. Khan, and P. Wonka, “Llm blueprint: Enabling text-to-image generation with complex and detailed prompts,” arXiv preprint arXiv:2310.10640, 2023
arXiv 2023
-
[25]
Rethinking data-free quan- tization as a zero-sum game,
B. Qian, Y . Wang, R. Hong, and M. Wang, “Rethinking data-free quan- tization as a zero-sum game,” inProceedings of the AAAI conference on artificial intelligence, vol. 37, pp. 9489–9497, 2023
2023
-
[26]
Token merging for training- free semantic binding in text-to-image synthesis,
T. Hu, L. Li, J. van de Weijer, H. Gao, F. Shahbaz Khan, J. Yang, M.-M. Cheng, K. Wang, and Y . Wang, “Token merging for training- free semantic binding in text-to-image synthesis,”Advances in Neural Information Processing Systems, vol. 37, pp. 137646–137672, 2024
2024
-
[27]
A cat is a cat (not a dog!): Unraveling information mix-ups in text-to-image encoders through causal analysis and embedding optimization,
C.-Y . Chen, C. Tseng, L.-W. Tsao, and H.-H. Shuai, “A cat is a cat (not a dog!): Unraveling information mix-ups in text-to-image encoders through causal analysis and embedding optimization,”Advances in Neural Information Processing Systems, vol. 37, pp. 57944–57969, 2024
2024
-
[28]
Delving globally into texture and structure for image inpainting,
H. Liu, Y . Wang, M. Wang, and Y . Rui, “Delving globally into texture and structure for image inpainting,” inProceedings of the 30th ACM International Conference on Multimedia, pp. 1270–1278, 2022
2022
-
[29]
T2i-compbench: A comprehensive benchmark for open-world compositional text-to- image generation,
K. Huang, K. Sun, E. Xie, Z. Li, and X. Liu, “T2i-compbench: A comprehensive benchmark for open-world compositional text-to- image generation,”Advances in Neural Information Processing Systems, vol. 36, pp. 78723–78747, 2023
2023
-
[30]
High- resolution image synthesis with latent diffusion models,
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High- resolution image synthesis with latent diffusion models,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 10684–10695, 2022
2022
-
[31]
Diffusion models beat gans on image synthesis,
P. Dhariwal and A. Nichol, “Diffusion models beat gans on image synthesis,”Advances in neural information processing systems, vol. 34, pp. 8780–8794, 2021
2021
-
[32]
Flux.1 kontext: Flow matching for in-context image generation and editing in latent space,
B. F. Labs, S. Batifol, A. Blattmann, F. Boesel, S. Consul, C. Diagne, T. Dockhorn, J. English, Z. English, P. Esser, S. Kulal, K. Lacey, Y . Levi, C. Li, D. Lorenz, J. M ¨uller, D. Podell, R. Rombach, H. Saini, A. Sauer, and L. Smith, “Flux.1 kontext: Flow matching for in-context image generation and editing in latent space,” 2025
2025
-
[33]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” Advances in neural information processing systems, vol. 33, pp. 6840– 6851, 2020
2020
-
[34]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark,et al., “Learning transferable visual models from natural language supervision,” inInternational conference on machine learning, pp. 8748–8763, PmLR, 2021
2021
-
[35]
Classifier-free diffusion guidance,
J. Ho and T. Salimans, “Classifier-free diffusion guidance,”arXiv preprint arXiv:2207.12598, 2022
Pith/arXiv arXiv 2022
-
[36]
Be yourself: Bounded attention for multi-subject text-to-image generation,
O. Dahary, O. Patashnik, K. Aberman, and D. Cohen-Or, “Be yourself: Bounded attention for multi-subject text-to-image generation,” inEuro- pean Conference on Computer Vision, pp. 432–448, Springer, 2024
2024
-
[37]
Phased consistency models,
F.-Y . Wang, Z. Huang, A. Bergman, D. Shen, P. Gao, M. Lingelbach, K. Sun, W. Bian, G. Song, Y . Liu,et al., “Phased consistency models,” Advances in neural information processing systems, vol. 37, pp. 83951– 84009, 2024
2024
-
[38]
Rethinking the spa- tial inconsistency in classifier-free diffusion guidance,
D. Shen, G. Song, Z. Xue, F.-Y . Wang, and Y . Liu, “Rethinking the spa- tial inconsistency in classifier-free diffusion guidance,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 9370–9379, 2024
2024
-
[39]
Plug-and-play diffu- sion features for text-driven image-to-image translation,
N. Tumanyan, M. Geyer, S. Bagon, and T. Dekel, “Plug-and-play diffu- sion features for text-driven image-to-image translation,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 1921–1930, 2023
1921
-
[40]
Compositional text-to-image synthesis with attention map control of diffusion models,
R. Wang, Z. Chen, C. Chen, J. Ma, H. Lu, and X. Lin, “Compositional text-to-image synthesis with attention map control of diffusion models,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 38, pp. 5544–5552, 2024
2024
-
[41]
Instancediffusion: Instance-level control for image generation,
X. Wang, T. Darrell, S. S. Rambhatla, R. Girdhar, and I. Misra, “Instancediffusion: Instance-level control for image generation,” inPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 6232–6242, 2024
2024
-
[42]
Mastering text-to-image diffusion: Recaptioning, planning, and generating with multimodal llms,
L. Yang, Z. Yu, C. Meng, M. Xu, S. Ermon, and B. Cui, “Mastering text-to-image diffusion: Recaptioning, planning, and generating with multimodal llms,” inForty-first International Conference on Machine Learning, 2024
2024
-
[43]
Mulan: Multimodal-llm agent for progressive and interactive multi-object diffu- sion,
S. Li, R. Wang, C.-J. Hsieh, M. Cheng, and T. Zhou, “Mulan: Multimodal-llm agent for progressive and interactive multi-object diffu- sion,”arXiv preprint arXiv:2402.12741, 2024
arXiv 2024
-
[44]
Attend-and- excite: Attention-based semantic guidance for text-to-image diffusion models,
H. Chefer, Y . Alaluf, Y . Vinker, L. Wolf, and D. Cohen-Or, “Attend-and- excite: Attention-based semantic guidance for text-to-image diffusion models,”ACM transactions on Graphics (TOG), vol. 42, no. 4, pp. 1– 10, 2023
2023
-
[45]
H. Seo, J. Bang, H. Lee, J. Lee, B. H. Lee, and S. Y . Chun, “Geometrical properties of text token embeddings for strong semantic binding in text- to-image generation,”arXiv preprint arXiv:2503.23011, 2025
arXiv 2025
-
[46]
Uncovering the text embedding in text-to-image diffusion models,
H. Yu, H. Luo, F. Wang, and F. Zhao, “Uncovering the text embedding in text-to-image diffusion models,”arXiv preprint arXiv:2404.01154, 2024
arXiv 2024
-
[47]
Core: Context-regularized text embedding learning for text-to-image personalization,
F. Wu, Y . Pang, J. Zhang, L. Pang, J. Yin, B. Zhao, Q. Li, and X. Mao, “Core: Context-regularized text embedding learning for text-to-image personalization,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, pp. 8377–8385, 2025
2025
-
[48]
Get what you want, not what you don’t: Image content suppression for text-to-image diffusion models,
S. Li, J. van de Weijer, T. Hu, F. S. Khan, Q. Hou, Y . Wang, and J. Yang, “Get what you want, not what you don’t: Image content suppression for text-to-image diffusion models,”arXiv preprint arXiv:2402.05375, 2024
arXiv 2024
-
[49]
Training-free structured diffusion guidance for compositional text-to-image synthesis,
W. Feng, X. He, T.-J. Fu, V . Jampani, A. Akula, P. Narayana, S. Basu, X. E. Wang, and W. Y . Wang, “Training-free structured diffusion guidance for compositional text-to-image synthesis,”arXiv preprint arXiv:2212.05032, 2022
arXiv 2022
-
[50]
Weighted nuclear norm minimization with application to image denoising,
S. Gu, L. Zhang, W. Zuo, and X. Feng, “Weighted nuclear norm minimization with application to image denoising,” inProceedings of the IEEE conference on computer vision and pattern recognition, pp. 2862– 2869, 2014
2014
-
[51]
A mathematical theory of communication,
C. E. Shannon, “A mathematical theory of communication,”The Bell system technical journal, vol. 27, no. 3, pp. 379–423, 1948
1948
-
[52]
Imagereward: Learning and evaluating human preferences for text-to- image generation,
J. Xu, X. Liu, Y . Wu, Y . Tong, Q. Li, M. Ding, J. Tang, and Y . Dong, “Imagereward: Learning and evaluating human preferences for text-to- image generation,” 2023
2023
-
[53]
Detail++: Training-free detail enhancer for text-to-image diffusion models,
L. Chen, J. Wang, Z. Pan, B. Zhu, X. Yang, and C. Zhang, “Detail++: Training-free detail enhancer for text-to-image diffusion models,”arXiv preprint arXiv:2507.17853, 2025
Pith/arXiv arXiv 2025
-
[54]
Enhanc- ing semantic fidelity in text-to-image synthesis: Attention regulation in diffusion models,
Y . Zhang, T. T. Tzun, L. W. Hern, T. Sim, and K. Kawaguchi, “Enhanc- ing semantic fidelity in text-to-image synthesis: Attention regulation in diffusion models,” 2024
2024
-
[55]
Linguistic binding in diffusion models: Enhancing attribute correspondence through attention map alignment,
R. Rassin, E. Hirsch, D. Glickman, S. Ravfogel, Y . Goldberg, and G. Chechik, “Linguistic binding in diffusion models: Enhancing attribute correspondence through attention map alignment,” 2024
2024
-
[56]
spacy 2: Natural language understanding with bloom embeddings, convolutional neural networks and incremental parsing,
M. Honnibal, “spacy 2: Natural language understanding with bloom embeddings, convolutional neural networks and incremental parsing,” (No Title), 2017
2017
-
[57]
Play- ground v2
D. Li, A. Kamko, A. Sabet, E. Akhgari, L. Xu, and S. Doshi, “Play- ground v2.”
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.