Listen, Look, and Learn: Learning Without Forgetting through SAM-Audio
Pith reviewed 2026-06-27 13:39 UTC · model grok-4.3
The pith
SAM-Audio priors adapted with audio-guided attention and dual distillation enable audio-visual class-incremental learning without forgetting.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
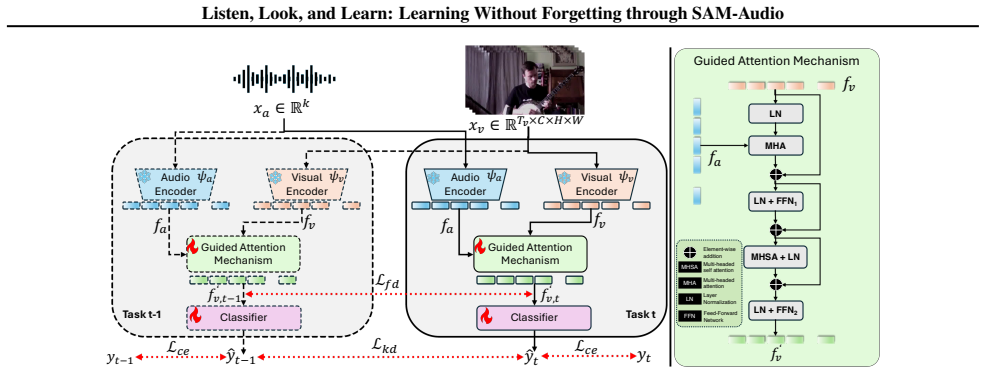
By integrating SAM-Audio's audio-visual priors into the class-incremental setting through a guided attention strategy where audio features contextually guide the visual representations together with dual-level distillation objectives at feature and logit levels, the method consistently outperforms state-of-the-art approaches on audio-visual CIL benchmarks.
What carries the argument
Guided attention strategy in which audio features contextually guide the visual representations, together with dual-level distillation at feature and logit levels.
Load-bearing premise
SAM-Audio's static priors stay effective after adaptation by guided attention and distillation during sequential class arrival, without the adaptation process itself introducing interference or demanding task-specific tuning that was never validated.
What would settle it
Direct evaluation on the audio-visual CIL benchmarks in which the proposed method fails to outperform existing state-of-the-art methods or shows higher rates of forgetting would falsify the central claim.
Figures

read the original abstract
Class-Incremental Learning (CIL) aims to continuously learn new classes without forgetting previously acquired knowledge. While recent CIL advances have spurred significant interest across various modalities, the audio-visual setting remains underexplored. Furthermore, although foundational multimodal models like SAM-Audio encapsulate rich static priors, our empirical analysis reveals that these representations struggle in incremental settings. This work bridges this gap by integrating SAM-Audio's audio-visual priors into the CIL setting. Specifically, we leverage its dense audio and visual representations and employ a novel guided attention strategy where the audio features contextually guide the visual representations. To further mitigate catastrophic forgetting, we introduce dual-level distillation objectives at both the feature and logit levels. Extensive evaluations on audio-visual CIL benchmarks demonstrate that our approach consistently outperforms state-of-the-art methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper addresses class-incremental learning (CIL) in the audio-visual domain, an underexplored setting. It integrates SAM-Audio's dense audio-visual priors into CIL by introducing a guided attention mechanism in which audio features contextually guide visual representations, combined with dual-level distillation (feature-level and logit-level) to mitigate catastrophic forgetting. The central claim, supported by asserted extensive evaluations, is that the resulting method consistently outperforms state-of-the-art approaches on audio-visual CIL benchmarks.
Significance. If the empirical results hold under rigorous controls, the work would be significant for demonstrating how to adapt rich static priors from multimodal foundational models to sequential class arrival without task-specific retuning or interference. The guided attention plus dual distillation strategy offers a concrete, modality-aware response to the observed failure of static priors in incremental settings, potentially influencing continual learning research beyond vision-only or audio-only CIL.
major comments (2)
- [Abstract / Experimental Setup] Abstract and Experimental Setup (inferred from claim of 'extensive evaluations'): the central claim of consistent outperformance lacks any reported details on experimental controls, statistical significance testing, number of runs, or ablation of the guided attention component versus the dual distillation; without these, it is impossible to determine whether the reported gains are load-bearing or attributable to the proposed adaptations.
- [Methods] Methods (guided attention and distillation description): the assumption that SAM-Audio static priors remain effective after adaptation is load-bearing for the contribution, yet no concrete test (e.g., comparison against frozen SAM-Audio baseline or analysis of interference across incremental steps) is referenced; this leaves open whether the adaptation itself introduces new forgetting that the distillation is merely compensating for.
minor comments (2)
- [Abstract] Abstract: minor grammatical issue ('SAM-Audio encapsulate' should read 'encapsulates').
- [Methods] Notation: the distinction between 'feature-level' and 'logit-level' distillation is introduced without an accompanying equation or diagram reference, reducing immediate clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for greater experimental rigor. We agree that the current presentation of results requires expansion to fully substantiate the claims and will revise accordingly.
read point-by-point responses
-
Referee: [Abstract / Experimental Setup] Abstract and Experimental Setup (inferred from claim of 'extensive evaluations'): the central claim of consistent outperformance lacks any reported details on experimental controls, statistical significance testing, number of runs, or ablation of the guided attention component versus the dual distillation; without these, it is impossible to determine whether the reported gains are load-bearing or attributable to the proposed adaptations.
Authors: We agree that additional details are required. In the revised manuscript we will expand the experimental section to report all results as means and standard deviations over 5 random seeds, include paired t-test p-values against baselines, and add a dedicated ablation table isolating the guided attention mechanism from the dual distillation objectives. These changes will make clear that the reported gains depend on both proposed components. revision: yes
-
Referee: [Methods] Methods (guided attention and distillation description): the assumption that SAM-Audio static priors remain effective after adaptation is load-bearing for the contribution, yet no concrete test (e.g., comparison against frozen SAM-Audio baseline or analysis of interference across incremental steps) is referenced; this leaves open whether the adaptation itself introduces new forgetting that the distillation is merely compensating for.
Authors: This point is well taken. The manuscript does not currently contain an explicit frozen SAM-Audio baseline or step-wise interference analysis. We will add both in the revision: (1) a direct comparison of our adapted model against a frozen SAM-Audio feature extractor within the same CIL protocol, and (2) quantitative metrics (e.g., feature cosine similarity drift and per-step forgetting) demonstrating that adaptation does not introduce additional forgetting beyond what the dual distillation mitigates. revision: yes
Circularity Check
No significant circularity
full rationale
The paper presents an empirical method for audio-visual class-incremental learning that integrates SAM-Audio priors via guided attention and dual distillation, with performance claims resting entirely on benchmark evaluations rather than any mathematical derivation or prediction step. No equations, fitted parameters renamed as predictions, self-definitional constructs, or load-bearing self-citations appear in the provided abstract or description; the central claim of outperformance is externally falsifiable via standard benchmarks and does not reduce to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
J., Javaheripi, M., Kauffmann, P., et al
Abdin, M., Aneja, J., Behl, H., Bubeck, S., Eldan, R., Gunasekar, S., Harrison, M., Hewett, R. J., Javaheripi, M., Kauffmann, P., et al. Phi-4 technical report.arXiv preprint arXiv:2412.08905,
-
[2]
L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F. L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
-
[3]
doi: 10.1109/ICCV48922.2021.00088. Azad, B., Azad, R., Eskandari, S., Bozorgpour, A., Kazer- ouni, A., Rekik, I., and Merhof, D. Foundational models in medical imaging: A comprehensive survey and future vision.arXiv preprint arXiv:2310.18689,
-
[4]
S., Rolnick, D., and Kording, K
Benjamin, A. S., Rolnick, D., and Kording, K. Measur- ing and regularizing networks in function space.arXiv preprint arXiv:1805.08289,
-
[5]
Continual llava: Con- tinual instruction tuning in large vision-language models
Cao, M., Liu, Y ., Liu, Y ., Wang, T., Dong, J., Ding, H., Zhang, X., Reid, I., and Liang, X. Continual llava: Con- tinual instruction tuning in large vision-language models. arXiv preprint arXiv:2411.02564,
-
[6]
Chaudhry, A., Dokania, P. K., Ajanthan, T., and Torr, P. H. S. Riemannian walk for incremental learning: Under- standing forgetting and intransigence. InProceedings of the European Conference on Computer Vision (ECCV), September 2018a. Chaudhry, A., Ranzato, M., Rohrbach, M., and Elhoseiny, M. Efficient lifelong learning with a-gem.arXiv preprint arXiv:18...
Pith/arXiv arXiv 1902
-
[7]
Continual learning via neural pruning.arXiv preprint arXiv:1903.04476,
Golkar, S., Kagan, M., and Cho, K. Continual learning via neural pruning.arXiv preprint arXiv:1903.04476,
Pith/arXiv arXiv 1903
-
[8]
Taming modality entanglement in continual audio-visual segmentation
Hong, Y ., Yang, Q., Zhang, T., Wang, Z., Fu, Z., Ding, K., Fan, B., and Xiang, S. Taming modality entanglement in continual audio-visual segmentation. CoRR, abs/2510.17234,
-
[9]
Towards Universal Unsupervised Anomaly Detection in Medical Imaging 2024
doi: 10.48550/ARXIV . 2510.17234. URLhttps://doi.org/10.48550/ arXiv.2510.17234. Hou, S., Pan, X., Loy, C. C., Wang, Z., and Lin, D. Learn- ing a unified classifier incrementally via rebalancing. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 831–839,
work page internal anchor Pith review doi:10.48550/arxiv
-
[11]
Continual audio-visual sound separation
Pian, W., Nan, Y ., Deng, S., Mo, S., Guo, Y ., and Tian, Y . Continual audio-visual sound separation. In Globersons, A., Mackey, L., Belgrave, D., Fan, A., Paquet, U., Tom- czak, J. M., and Zhang, C. (eds.),Advances in Neural In- formation Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC,...
2024
-
[12]
Qi, Z., Tang, Y .-P., Meng, L., Yu, H., Li, X., and Meng, X. Class-wise balancing data replay for federated class- incremental learning.arXiv preprint arXiv:2507.07712,
-
[13]
doi: 10.1109/CVPR.2017.587. Shi, B., Tjandra, A., Hoffman, J., Wang, H., Wu, Y .-C., Gao, L., Richter, J., Le, M., Vyas, A., Chen, S., Fe- ichtenhofer, C., Doll ´ar, P., Hsu, W.-N., and Lee, A. Sam audio: Segment anything in audio
-
[14]
Sun, Y ., Si, Y ., Zhu, C., Zhang, K., Shui, Z., Ding, B., Lin, T., and Yang, L
URL https://arxiv.org/abs/2512.18099. Sun, Y ., Si, Y ., Zhu, C., Zhang, K., Shui, Z., Ding, B., Lin, T., and Yang, L. Cpathagent: An agent-based foundation model for interpretable high-resolution pathology image analysis mimicking pathologists’ diagnostic logic.arXiv preprint arXiv:2505.20510,
-
[15]
Yadav, S., Gupta, A., and Jerripothula, K. R. Samwave: Adapting segment anything model to difficult tasks. In36th British Machine Vision Confer- ence 2025, BMVC 2025, Sheffield, UK, Novem- ber 24-27,
2025
-
[16]
URL https: //bmva-archive.org.uk/bmvc/2025/ assets/papers/Paper_698/paper.pdf
BMV A, 2025a. URL https: //bmva-archive.org.uk/bmvc/2025/ assets/papers/Paper_698/paper.pdf. Yadav, S., Gupta, A., and Jerripothula, K. R. Samwave: Wavelet-driven feature enrichment for effective adap- tation of segment anything model.arXiv preprint arXiv:2507.20186, 2025b. Yao, Y ., Liu, S., Song, H., Qu, D., Chen, Q., Ding, Y ., Zhao, B., Wang, Z., Li, ...
arXiv 2025
-
[17]
Yi, H., Xu, W., Qin, Z., Chen, X., Wu, X., Li, K., and Lao, Q. idpa: Instance decoupled prompt attention for incremental medical object detection.arXiv preprint arXiv:2506.00406,
-
[18]
doi: 10.1109/TPAMI. 2024.3445770. 7 Listen, Look, and Learn: Learning Without Forgetting through SAM-Audio A. Related Works Class-Incremental Learning.The task of Class- Incremental Learning (CIL) targets to learn new classes continuously while preserving knowledge of previously learned classes (Jung et al., 2020; Hou et al., 2019; Kang et al., 2022; Wang...
-
[19]
Exemplar/Memory Replay-based methods (Ahn et al., 2021; Chaudhry et al., 2018b; 2019; Channappayya et al., 2023; Chen et al.,
help the model preserve previously learned knowledge across incremental steps by minimizing the Kullback-Leibler divergence between the output probability distributions of the previous and current models. Exemplar/Memory Replay-based methods (Ahn et al., 2021; Chaudhry et al., 2018b; 2019; Channappayya et al., 2023; Chen et al.,
2021
-
[20]
Architecture-based methods (Golkar et al., 2019; Hung et al., 2019; Li et al.,
assume that a small size of memory is accessible to store examples from old tasks/classes. Architecture-based methods (Golkar et al., 2019; Hung et al., 2019; Li et al.,
2019
-
[21]
Foundational Multimodal Learning.Multimodal foun- dation models (Radford et al., 2021; Achiam et al., 2023; Abdin et al.,
hold incremental modules to in- crease the capacity of the model to handle new tasks/classes. Foundational Multimodal Learning.Multimodal foun- dation models (Radford et al., 2021; Achiam et al., 2023; Abdin et al.,
2021
-
[22]
have demonstrated remarkable efficacy across diverse applications—ranging from low-level vision tasks (Yadav et al., 2025a; Zhang et al., 2024; Wu et al.,
2024
-
[23]
Benefiting from large-scale pretraining, these architectures excel at captur- ing complex cross-modal semantic associations
and agent-based reason- ing (Sun et al., 2025)—by aligning and binding different modalities within a joint embedding space. Benefiting from large-scale pretraining, these architectures excel at captur- ing complex cross-modal semantic associations. A promi- nent example is the Segment Anything Model for Audio (SAM-Audio) (Shi et al., 2025), which leverage...
2025
-
[24]
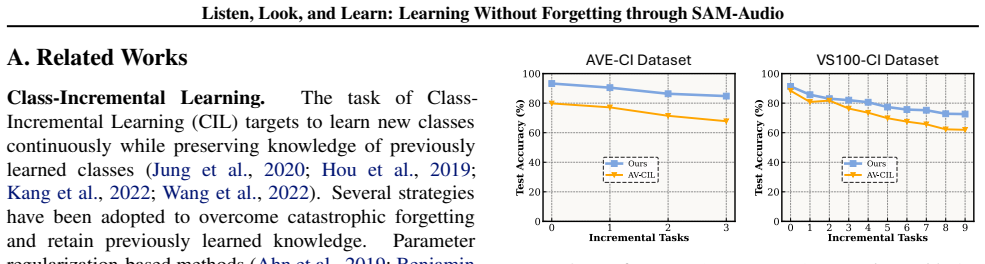
From the plots, we observe that our proposed approach consistently outperforms A V-CIL across all the incremental tasks in both benchmark datasets
on A VE- CI and VS100-CI at individual incremental steps. From the plots, we observe that our proposed approach consistently outperforms A V-CIL across all the incremental tasks in both benchmark datasets. To further assess the robustness of our proposed approach, we perform an additional experiment on different class- incremental tasks. Following (Pian e...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.