DarkVGGT: Seeing Through Darkness Using Thermal Geometry without Daylight Tax
Pith reviewed 2026-06-27 13:19 UTC · model grok-4.3
The pith
DarkVGGT recovers accurate 3D scene geometry from RGB-thermal streams in darkness by separating reliable thermal shape cues from reflections.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
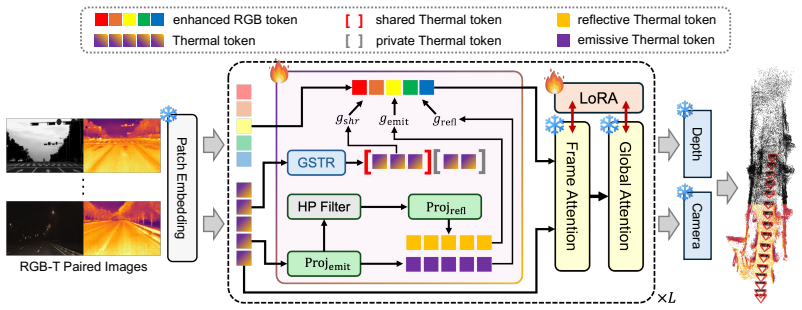
DarkVGGT introduces physics-inspired thermal factorization that extracts emissive-dominant, geometry-consistent thermal cues while isolating sparse reflective residuals, together with geometry-shared thermal routing that isolates modality-invariant geometric structures from thermal-specific patterns and selectively injects reliability-aware structural guidance into the RGB stream, enabling accurate thermal-informed geometry estimation under degraded RGB conditions while largely preserving performance in well-lit environments.
What carries the argument
Physics-inspired thermal factorization paired with geometry-shared thermal routing, which together supply modality-invariant geometric guidance from thermal data to an RGB feed-forward reconstruction pipeline.
If this is right
- Consistent gains in depth accuracy on low-visibility RGB-T benchmarks
- Improved camera-pose estimates under the same degraded conditions
- Performance in well-lit scenes remains close to the RGB-only baseline
- The approach works inside existing feed-forward geometry pipelines without requiring changes to the core network architecture
Where Pith is reading between the lines
- The same factorization idea could be tested on other modality pairs where one channel remains stable when the other degrades, such as radar or event-camera fusion.
- If the routing step proves lightweight, the method might support real-time night-time mapping on mobile robots without extra daylight hardware.
- The separation of emissive versus reflective thermal content might also reduce errors in applications like thermal-based material classification that currently treat the whole image as geometry.
- The framework leaves open whether the same cues remain useful when thermal reflections become dense rather than sparse, a case the current benchmarks do not stress.
Load-bearing premise
Thermal images supply emissive signals that remain geometrically consistent with the scene and can be cleanly separated from reflective parts that would otherwise create ambiguity.
What would settle it
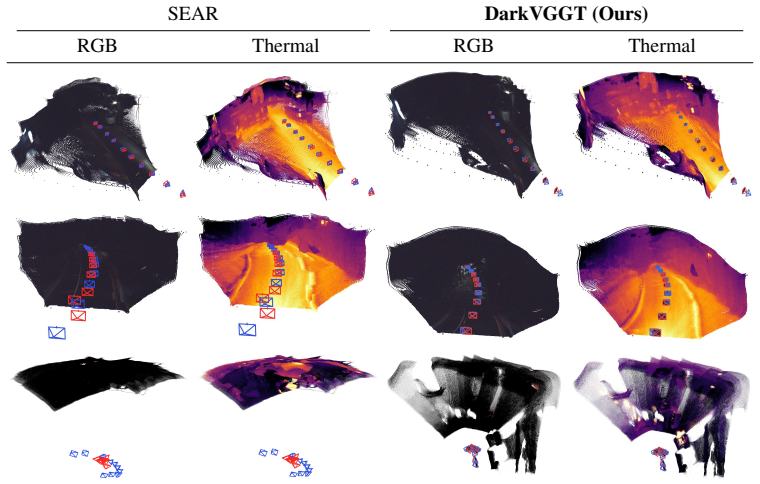
A controlled experiment on low-visibility RGB-T data in which depth and camera-pose accuracy show no gain or a clear drop when the thermal factorization and routing modules are removed compared with a standard RGB-only feed-forward baseline.
Figures





read the original abstract
Recent feed-forward 3D reconstruction methods have demonstrated strong performance and flexibility in efficient end-to-end scene geometry estimation from image streams. However, their reliance on visible-light appearance makes them vulnerable in dark and low-visibility environments, where RGB cues are severely degraded and geometric evidence becomes ambiguous. To address this challenge, we propose DarkVGGT, an RGB-T feed-forward geometry framework that uses physics-aware thermal modeling for robust 3D estimation in low-light scenes. DarkVGGT introduces two complementary modules. First, physics-inspired thermal factorization extracts emissive-dominant, geometry-consistent thermal cues while isolating sparse reflective residuals that may introduce geometric ambiguity. Second, geometry-shared thermal routing isolates modality-invariant geometric structures from thermal-specific patterns, selectively injecting reliability-aware structural guidance into the RGB stream. Together, these components enable accurate thermal-informed geometry estimation under degraded RGB conditions while largely preserving performance in well-lit environments. Experiments on low-visibility RGB-T benchmarks demonstrate consistent improvements in both depth and camera pose estimation over existing feed-forward geometry baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes DarkVGGT, an RGB-T feed-forward 3D geometry estimation framework for low-light scenes. It introduces two modules: (1) physics-inspired thermal factorization to extract emissive-dominant, geometry-consistent thermal cues while isolating reflective residuals, and (2) geometry-shared thermal routing to isolate modality-invariant structures and inject reliability-aware guidance into the RGB stream. The central claim is that these components enable accurate thermal-informed geometry estimation under degraded RGB conditions while largely preserving performance in well-lit environments, supported by experiments showing consistent improvements in depth and camera pose estimation over feed-forward baselines on low-visibility RGB-T benchmarks.
Significance. If the claims hold with rigorous validation, the work would address a practical limitation of current feed-forward 3D reconstruction methods by incorporating thermal data in a physics-aware manner without incurring a performance penalty in normal lighting. The emphasis on modality-invariant geometric structures and selective guidance injection could inform future multi-modal vision systems for robotics and autonomous navigation in challenging conditions.
major comments (1)
- [Abstract] Abstract: The claim that 'experiments on low-visibility RGB-T benchmarks demonstrate consistent improvements in both depth and camera pose estimation over existing feed-forward geometry baselines' is presented without any quantitative results, error bars, dataset specifications, baseline names, ablation studies, or implementation details. This absence renders the central claim unverifiable and load-bearing for the paper's contribution.
Simulated Author's Rebuttal
We thank the referee for the detailed review and constructive comment on the abstract. We address the point below and outline the planned revision.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that 'experiments on low-visibility RGB-T benchmarks demonstrate consistent improvements in both depth and camera pose estimation over existing feed-forward geometry baselines' is presented without any quantitative results, error bars, dataset specifications, baseline names, ablation studies, or implementation details. This absence renders the central claim unverifiable and load-bearing for the paper's contribution.
Authors: We agree that the abstract presents the central claim at a high level without the specific quantitative details, dataset names, baselines, or error metrics that would allow immediate verification. Although the full manuscript contains these elements in the Experiments section (including benchmark names, baseline comparisons, and ablation results), the referee is correct that the abstract itself does not make the claim self-contained. To resolve this, we will revise the abstract in the next version to include concise quantitative highlights (e.g., average depth error reductions and pose accuracy gains on the cited low-visibility RGB-T benchmarks relative to the named feed-forward baselines), while preserving its brevity. This change directly addresses the concern without altering the manuscript's technical content. revision: yes
Circularity Check
No significant circularity identified
full rationale
The provided abstract and description introduce two modules (physics-inspired thermal factorization and geometry-shared thermal routing) at a high level but contain no equations, derivations, fitting procedures, predictions, or self-citations that could form a load-bearing chain. No step reduces by construction to its inputs, as there are no mathematical claims or parameter fits presented. The reader's assessment of 2.0 aligns with the absence of any derivation content. The central assertions are descriptive proposals supported by (unshown) experiments rather than self-referential results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Thermal images can be factored into emissive-dominant geometry-consistent cues and sparse reflective residuals using physics-inspired modeling.
Reference graph
Works this paper leans on
-
[1]
Infrared thermographic measurement of the surface temperature and emissivity of glossy materials.Journal of Building Physics, 41(6):533–546, 2018
Petr Alexa, Jaroslav Solaˇr, Filip ˇCmiel, Pavel Valíˇcek, and Miroslava Kadulová. Infrared thermographic measurement of the surface temperature and emissivity of glossy materials.Journal of Building Physics, 41(6):533–546, 2018
2018
-
[2]
A survey on 3d object detection methods for autonomous driving applications.IEEE Transactions on Intelligent Transportation Systems, 20(10):3782–3795, 2019
Eduardo Arnold, Omar Y Al-Jarrah, Mehrdad Dianati, Saber Fallah, David Oxtoby, and Alex Mouzakitis. A survey on 3d object detection methods for autonomous driving applications.IEEE Transactions on Intelligent Transportation Systems, 20(10):3782–3795, 2019
2019
-
[3]
RGB-D and thermal sensor fusion: A systematic literature review.IEEE Access, 11:82410–82442, 2023
Martin Brenner, Napoleon H Reyes, Teo Susnjak, and Andre LC Barczak. RGB-D and thermal sensor fusion: A systematic literature review.IEEE Access, 11:82410–82442, 2023
2023
-
[4]
MUSt3R: Multi-view network for stereo 3D reconstruction
Yohann Cabon, Lucas Stoffl, Leonid Antsfeld, Gabriela Csurka, Boris Chidlovskii, Jerome Revaud, and Vincent Leroy. MUSt3R: Multi-view network for stereo 3D reconstruction. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1050–1060, 2025
2025
-
[5]
Infrared thermography for convective heat transfer measurements.Experiments in fluids, 49(6):1187–1218, 2010
Giovanni Maria Carlomagno and Gennaro Cardone. Infrared thermography for convective heat transfer measurements.Experiments in fluids, 49(6):1187–1218, 2010
2010
-
[6]
Thermal3D-GS: Physics-induced 3D gaussians for thermal infrared novel-view synthesis
Qian Chen, Shihao Shu, and Xiangzhi Bai. Thermal3D-GS: Physics-induced 3D gaussians for thermal infrared novel-view synthesis. InEuropean Conference on Computer Vision, 2024
2024
-
[7]
Hoonhee Cho, Jae-Young Kang, Giwon Lee, Hyemin Yang, Heejun Park, Seokwoo Jung, and Kuk-Jin Yoon. Vr-drive: Viewpoint-robust end-to-end driving with feed-forward 3d gaussian splatting.arXiv preprint arXiv:2510.23205, 2025
arXiv 2025
-
[8]
MASt3R-SfM: A fully-integrated solution for unconstrained structure-from-motion
Bardienus Pieter Duisterhof, Lojze Zust, Philippe Weinzaepfel, Vincent Leroy, Yohann Cabon, and Jerome Revaud. MASt3R-SfM: A fully-integrated solution for unconstrained structure-from-motion. In2025 International Conference on 3D Vision (3DV), pages 1–10. IEEE, 2025
2025
-
[9]
Infrared camera geometric calibration: A review and a precise thermal radiation checkerboard target.Sensors, 23(7):3479, 2023
Ahmed ElSheikh, Bassam A Abu-Nabah, Mohammad O Hamdan, and Gui-Yun Tian. Infrared camera geometric calibration: A review and a precise thermal radiation checkerboard target.Sensors, 23(7):3479, 2023
2023
-
[10]
More: Motion-aware feed-forward 4d reconstruction transformer.arXiv preprint arXiv:2603.05078, 2026
Juntong Fang, Zequn Chen, Weiqi Zhang, Donglin Di, Xuancheng Zhang, Chengmin Yang, and Yu-Shen Liu. More: Motion-aware feed-forward 4d reconstruction transformer.arXiv preprint arXiv:2603.05078, 2026
arXiv 2026
-
[11]
Pedestrian detection in low-light conditions: A comprehensive survey.Image and Vision Computing, 148:105106, 2024
Bahareh Ghari, Ali Tourani, Asadollah Shahbahrami, and Georgi Gaydadjiev. Pedestrian detection in low-light conditions: A comprehensive survey.Image and Vision Computing, 148:105106, 2024
2024
-
[12]
Dark3R: Learning structure from motion in the dark.arXiv preprint arXiv:2603.05330, 2026
Andrew Y Guo, Anagh Malik, SaiKiran Tedla, Yutong Dai, Yiqian Qin, Zach Salehe, Benjamin Attal, Sotiris Nousias, Kyros Kutulakos, and David B Lindell. Dark3R: Learning structure from motion in the dark.arXiv preprint arXiv:2603.05330, 2026
arXiv 2026
-
[13]
Yubin Guo, Haobo Jiang, Xinlei Qi, Jin Xie, Cheng-Zhong Xu, and Hui Kong. Unsupervised visible- light images guided cross-spectrum depth estimation from dual-modality cameras.arXiv preprint arXiv:2205.00257, 2022
arXiv 2022
-
[14]
Dˆ 2ust3r: Enhancing 3d reconstruction with 4d pointmaps for dynamic scenes.arXiv e-prints, pages arXiv–2504, 2025
Jisang Han, Honggyu An, Jaewoo Jung, Takuya Narihira, Junyoung Seo, Kazumi Fukuda, Chaehyun Kim, Sunghwan Hong, Yuki Mitsufuji, and Seungryong Kim. Dˆ 2ust3r: Enhancing 3d reconstruction with 4d pointmaps for dynamic scenes.arXiv e-prints, pages arXiv–2504, 2025. 10
2025
-
[15]
Mariam Hassan, Florent Forest, Olga Fink, and Malcolm Mielle. ThermoNeRF: Joint RGB and ther- mal novel view synthesis for building facades using multimodal neural radiance fields.arXiv preprint arXiv:2403.12154, 2024
arXiv 2024
-
[16]
DarkFeat: Noise-robust feature detector and descriptor for extremely low-light RAW images
Yuze He, Yubin Hu, Wang Zhao, Jisheng Li, Yong-Jin Liu, Yuxing Han, and Jiangtao Wen. DarkFeat: Noise-robust feature detector and descriptor for extremely low-light RAW images. InProceedings of the AAAI conference on artificial intelligence, volume 37, pages 826–834, 2023
2023
-
[17]
LoRA: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. LoRA: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
2022
-
[18]
Wiley New York, 1996
Frank P Incropera, David P DeWitt, Theodore L Bergman, Adrienne S Lavine, et al.Fundamentals of heat and mass transfer, volume 6. Wiley New York, 1996
1996
-
[19]
Gustav Kirchhoff. I. on the relation between the radiating and absorbing powers of different bodies for light and heat.The London, Edinburgh, and Dublin Philosophical Magazine and Journal of Science, 20 (130):1–21, 1860
-
[20]
Minseong Kweon, Janghyun Kim, Ukcheol Shin, and Jinsun Park. MrGS: Multi-modal radiance fields with 3D gaussian splatting for RGB-Thermal novel view synthesis.arXiv preprint arXiv:2511.22997, 2025
arXiv 2025
-
[21]
Multi-modal depth estimation from misaligned thermal and RGB images
Byeongjun Kwon and Munchurl Kim. Multi-modal depth estimation from misaligned thermal and RGB images. InProceedings of the Korean Institute of Broadcast and Media Engineers Summer Conference, pages 912–915, 2024
2024
-
[22]
ViViD++: Vision for visibility dataset.IEEE Robotics and Automation Letters, 7(3):6282–6289, 2022
Alex Junho Lee, Younggun Cho, Young-sik Shin, Ayoung Kim, and Hyun Myung. ViViD++: Vision for visibility dataset.IEEE Robotics and Automation Letters, 7(3):6282–6289, 2022
2022
-
[23]
Grounding image matching in 3D with MASt3R
Vincent Leroy, Yohann Cabon, and Jérôme Revaud. Grounding image matching in 3D with MASt3R. In European conference on computer vision, pages 71–91. Springer, 2024
2024
-
[24]
Chen, Zhenyu Li, Guang Shi, Jiashi Feng, and Bingyi Kang
Haotong Lin, Sili Chen, Jun Hao Liew, Donny Y . Chen, Zhenyu Li, Guang Shi, Jiashi Feng, and Bingyi Kang. Depth Anything 3: Recovering the visual space from any views.arXiv preprint arXiv:2511.10647, 2025
Pith/arXiv arXiv 2025
-
[25]
Thermalnerf: Thermal radiance fields
Yvette Y Lin, Xin-Yi Pan, Sara Fridovich-Keil, and Gordon Wetzstein. Thermalnerf: Thermal radiance fields. In2024 IEEE International Conference on Computational Photography (ICCP), pages 1–12. IEEE, 2024
2024
-
[26]
Humans as light bulbs: 3D human reconstruction from thermal reflection
Ruoshi Liu and Carl V ondrick. Humans as light bulbs: 3D human reconstruction from thermal reflection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12531– 12542, 2023
2023
-
[27]
Hao Lu, Tianshuo Xu, Wenzhao Zheng, Yunpeng Zhang, Wei Zhan, Dalong Du, Masayoshi Tomizuka, Kurt Keutzer, and Yingcong Chen. Drivingrecon: Large 4d gaussian reconstruction model for autonomous driving.arXiv preprint arXiv:2412.09043, 2024
arXiv 2024
-
[28]
ThermalGaussian: Thermal 3D gaussian splatting.arXiv preprint arXiv:2409.07200, 2024
Rongfeng Lu, Hangyu Chen, Zunjie Zhu, Yuhang Qin, Ming Lu, Le Zhang, Chenggang Yan, and Anke Xue. ThermalGaussian: Thermal 3D gaussian splatting.arXiv preprint arXiv:2409.07200, 2024
arXiv 2024
-
[29]
Vggt-slam: Dense rgb slam optimized on the sl (4) manifold.arXiv preprint arXiv:2505.12549, 2025
Dominic Maggio, Hyungtae Lim, and Luca Carlone. Vggt-slam: Dense rgb slam optimized on the sl (4) manifold.arXiv preprint arXiv:2505.12549, 2025
Pith/arXiv arXiv 2025
-
[30]
Parv Maheshwari, Jay Karhade, Yogesh Chawla, Isaiah Adu, Florian Heisen, Andrew Porco, Andrew Jong, Yifei Liu, Santosh Pitla, Sebastian Scherer, et al. AnyThermal: Towards learning universal representations for thermal perception.arXiv preprint arXiv:2602.06203, 2026
arXiv 2026
-
[31]
Academic press, 2021
Michael F Modest and Sandip Mazumder.Radiative heat transfer. Academic press, 2021
2021
-
[32]
Mast3r-slam: Real-time dense slam with 3d reconstruction priors
Riku Murai, Eric Dexheimer, and Andrew J Davison. Mast3r-slam: Real-time dense slam with 3d reconstruction priors. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 16695–16705, 2025
2025
-
[33]
Directional reflectance and emissivity of an opaque surface.Applied optics, 4(7): 767–775, 1965
Fred E Nicodemus. Directional reflectance and emissivity of an opaque surface.Applied optics, 4(7): 767–775, 1965
1965
-
[34]
DINOv2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193, 2023
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. DINOv2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193, 2023. 11
Pith/arXiv arXiv 2023
-
[35]
Infrared thermal imaging: Fundamentals, research and applications.European Journal of Physics, 32(5):1431, 2011
Gorazd Planinsic. Infrared thermal imaging: Fundamentals, research and applications.European Journal of Physics, 32(5):1431, 2011
2011
-
[36]
Vision transformers for dense prediction
René Ranftl, Alexey Bochkovskiy, and Vladlen Koltun. Vision transformers for dense prediction. In Proceedings of the IEEE/CVF international conference on computer vision, pages 12179–12188, 2021
2021
-
[37]
Yinrui Ren, Jinjing Zhu, Kanghao Chen, Zhuoxiao Li, Jing Ou, Zidong Cao, Tongyan Hua, Peilun Shi, Yingchun Fu, Wufan Zhao, et al. EventVGGT: Exploring cross-modal distillation for consistent event-based depth estimation.arXiv preprint arXiv:2603.09385, 2026
arXiv 2026
-
[38]
Ali M Reza. Realization of the contrast limited adaptive histogram equalization (clahe) for real-time image enhancement.Journal of VLSI signal processing systems for signal, image and video technology, 38(1): 35–44, 2004
2004
-
[39]
Structure-from-motion revisited
Johannes L Schonberger and Jan-Michael Frahm. Structure-from-motion revisited. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 4104–4113, 2016
2016
-
[40]
Pixelwise view selection for unstructured multi-view stereo
Johannes L Schönberger, Enliang Zheng, Jan-Michael Frahm, and Marc Pollefeys. Pixelwise view selection for unstructured multi-view stereo. InEuropean conference on computer vision, pages 501–518. Springer, 2016
2016
-
[41]
A multi-view stereo benchmark with high-resolution images and multi- camera videos
Thomas Schops, Johannes L Schonberger, Silvano Galliani, Torsten Sattler, Konrad Schindler, Marc Pollefeys, and Andreas Geiger. A multi-view stereo benchmark with high-resolution images and multi- camera videos. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 3260–3269, 2017
2017
-
[42]
3D reconstruction in robotics: A comprehensive review
Dharmendra Selvaratnam and Dena Bazazian. 3D reconstruction in robotics: A comprehensive review. Computers & Graphics, 130:104256, 2025
2025
-
[43]
Self-supervised depth and ego-motion esti- mation for monocular thermal video using multi-spectral consistency loss.IEEE Robotics and Automation Letters, 7(2):1103–1110, 2021
Ukcheol Shin, Kyunghyun Lee, Seokju Lee, and In So Kweon. Self-supervised depth and ego-motion esti- mation for monocular thermal video using multi-spectral consistency loss.IEEE Robotics and Automation Letters, 7(2):1103–1110, 2021
2021
-
[44]
Deep depth estimation from thermal image
Ukcheol Shin, Jinsun Park, and In So Kweon. Deep depth estimation from thermal image. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023
2023
-
[45]
Bridging spectral-wise and multi-spectral depth estimation via geometry-guided contrastive learning
Ukcheol Shin, Kyunghyun Lee, and Jean Oh. Bridging spectral-wise and multi-spectral depth estimation via geometry-guided contrastive learning. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 6299–6305. IEEE, 2025
2025
-
[46]
Vsevolod Skorokhodov, Chenghao Xu, Shuo Sun, Olga Fink, and Malcolm Mielle. SEAR: Simple and efficient adaptation of visual geometric transformers for RGB+Thermal 3D reconstruction.arXiv preprint arXiv:2603.18774, 2026
arXiv 2026
-
[47]
RoFormer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. RoFormer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
2024
-
[48]
Masked depth modeling for spatial perception.arXiv preprint arXiv:2601.17895, 2026
Bin Tan, Changjiang Sun, Xiage Qin, Hanat Adai, Zelin Fu, Tianxiang Zhou, Han Zhang, Yinghao Xu, Xing Zhu, Yujun Shen, et al. Masked depth modeling for spatial perception.arXiv preprint arXiv:2601.17895, 2026
arXiv 2026
-
[49]
Highly accurate geometric calibration for infrared cameras using inexpensive calibration targets.Measurement, 112:105–116, 2017
R Usamentiaga, DF Garcia, C Ibarra-Castanedo, and X Maldague. Highly accurate geometric calibration for infrared cameras using inexpensive calibration targets.Measurement, 112:105–116, 2017
2017
-
[50]
Infrared thermography for temperature measurement and non-destructive testing.Sensors, 14(7):12305– 12348, 2014
Rubén Usamentiaga, Pablo Venegas, Jon Guerediaga, Laura Vega, Julio Molleda, and Francisco G Bulnes. Infrared thermography for temperature measurement and non-destructive testing.Sensors, 14(7):12305– 12348, 2014
2014
-
[51]
3D reconstruction with spatial memory
Hengyi Wang and Lourdes Agapito. 3D reconstruction with spatial memory. In2025 International Conference on 3D Vision (3DV), pages 78–89. IEEE, 2025
2025
-
[52]
VGGT: Visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. VGGT: Visual geometry grounded transformer. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5294–5306, 2025
2025
-
[53]
DUSt3R: Geometric 3D vision made easy
Shuzhe Wang, Vincent Leroy, Yohann Cabon, Boris Chidlovskii, and Jerome Revaud. DUSt3R: Geometric 3D vision made easy. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 20697–20709, 2024. 12
2024
-
[54]
EAG3R: Event-augmented 3D geometry estimation for dynamic and extreme-lighting scenes
Xiaoshan Wu, Yifei Yu, Xiaoyang Lyu, Yihua Huang, Bo Wang, Baoheng Zhang, Zhongrui Wang, and Xiaojuan Qi. EAG3R: Event-augmented 3D geometry estimation for dynamic and extreme-lighting scenes. arXiv preprint arXiv:2512.00771, 2025
arXiv 2025
-
[55]
A text-centered shared-private framework via cross-modal prediction for multimodal sentiment analysis
Yang Wu, Zijie Lin, Yanyan Zhao, Bing Qin, and Li-Nan Zhu. A text-centered shared-private framework via cross-modal prediction for multimodal sentiment analysis. InFindings of the association for computational linguistics: ACL-IJCNLP 2021, pages 4730–4738, 2021
2021
-
[56]
Jiuhong Xiao, Roshan Nayak, Ning Zhang, Daniel Tortei, and Giuseppe Loianno. ThermalGen: Style- disentangled flow-based generative models for RGB-to-Thermal image translation.arXiv preprint arXiv:2509.24878, 2025
arXiv 2025
-
[57]
Fast3r: Towards 3d reconstruction of 1000+ images in one forward pass
Jianing Yang, Alexander Sax, Kevin J Liang, Mikael Henaff, Hao Tang, Ang Cao, Joyce Chai, Franziska Meier, and Matt Feiszli. Fast3r: Towards 3d reconstruction of 1000+ images in one forward pass. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 21924–21935, 2025
2025
-
[58]
Sizhe Yang, Linning Xu, Hao Li, Juncheng Mu, Jia Zeng, Dahua Lin, and Jiangmiao Pang. Robo3r: Enhanc- ing robotic manipulation with accurate feed-forward 3d reconstruction.arXiv preprint arXiv:2602.10101, 2026
Pith/arXiv arXiv 2026
-
[59]
ScanNet++: A high-fidelity dataset of 3D indoor scenes
Chandan Yeshwanth, Yueh-Cheng Liu, Matthias Nießner, and Angela Dai. ScanNet++: A high-fidelity dataset of 3D indoor scenes. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 12–22, 2023
2023
-
[60]
STheReO: Stereo thermal dataset for research in odometry and mapping
Seungsang Yun, Minwoo Jung, Jeongyun Kim, Sangwoo Jung, Younghun Cho, Myung-Hwan Jeon, Giseop Kim, and Ayoung Kim. STheReO: Stereo thermal dataset for research in odometry and mapping. In2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 3857–3864. IEEE, 2022
2022
-
[61]
MonST3R: A simple approach for estimating geometry in the presence of motion
Junyi Zhang, Charles Herrmann, Junhwa Hur, Varun Jampani, Trevor Darrell, Forrester Cole, Deqing Sun, and Ming-Hsuan Yang. MonST3R: A simple approach for estimating geometry in the presence of motion. arXiv preprint arXiv:2410.03825, 2024
Pith/arXiv arXiv 2024
-
[62]
Multimodal fusion on low-quality data: A comprehensive survey.Information Fusion, page 104437, 2026
Qingyang Zhang, Yake Wei, Zongbo Han, Huazhu Fu, Xi Peng, Qinghua Hu, Cheng Deng, Cai Xu, Jie Wen, Di Hu, et al. Multimodal fusion on low-quality data: A comprehensive survey.Information Fusion, page 104437, 2026
2026
-
[63]
FLARE: Feed-forward geometry, appearance and camera estimation from uncalibrated sparse views
Shangzhan Zhang, Jianyuan Wang, Yinghao Xu, Nan Xue, Christian Rupprecht, Xiaowei Zhou, Yujun Shen, and Gordon Wetzstein. FLARE: Feed-forward geometry, appearance and camera estimation from uncalibrated sparse views. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 21936–21947, 2025
2025
-
[64]
MonoTher-Depth: Enhancing thermal depth estimation via confidence-aware distillation.IEEE Robotics and Automation Letters, 10(3):2830–2837, 2025
Xingxing Zuo, Nikhil Ranganathan, Connor Lee, Georgia Gkioxari, and Soon-Jo Chung. MonoTher-Depth: Enhancing thermal depth estimation via confidence-aware distillation.IEEE Robotics and Automation Letters, 10(3):2830–2837, 2025. 13 A Technical appendices and supplementary material A.1 DarkVGGT: detailed methodology LoRA and camera tokens.After loading the...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.