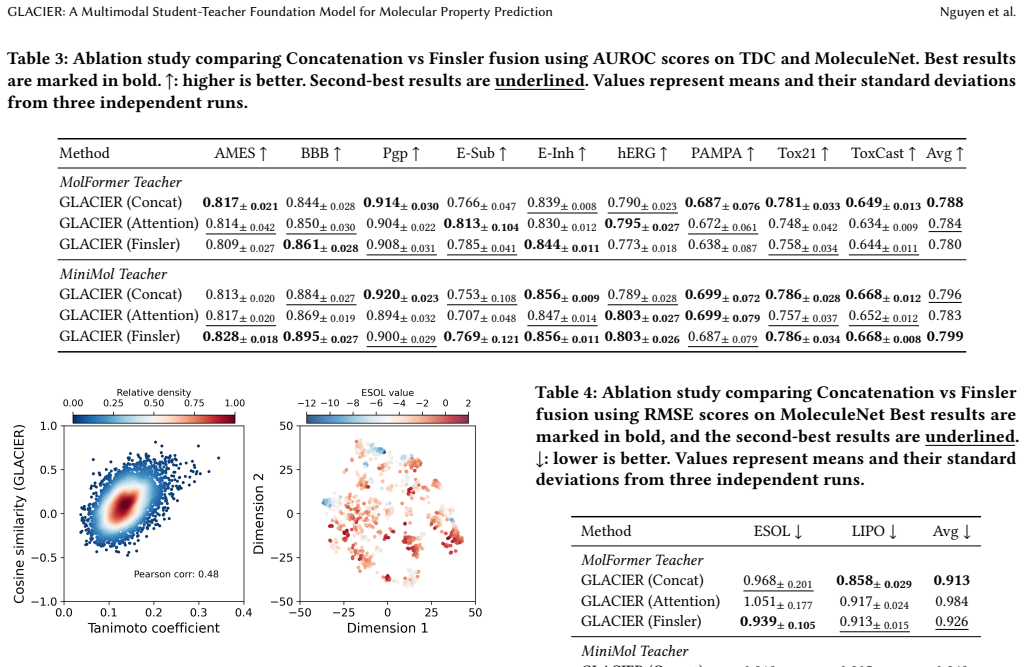
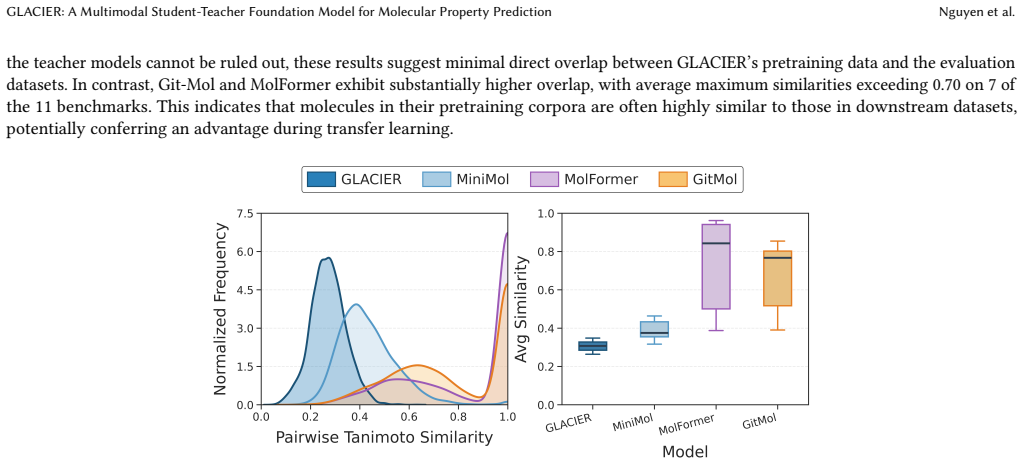
GLACIER: A Multimodal Student-Teacher Foundation Model for Molecular Property Prediction
Pith reviewed 2026-06-27 13:57 UTC · model grok-4.3
The pith
GLACIER integrates three student encoders for graphs, SMILES strings, and descriptors, fuses them with a Finsler-aware module, and distills from teacher models to produce a lightweight predictor with high performance and efficiency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
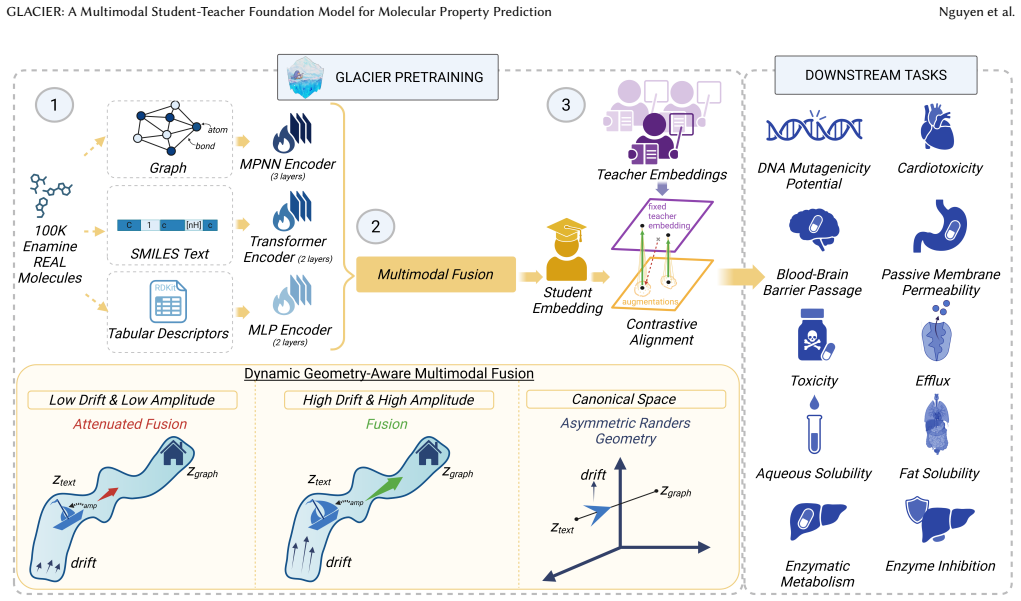
GLACIER is a multimodal student-teacher foundation model that pretrains a message-passing network on molecular graphs, a transformer on SMILES strings, and a multilayer perceptron on physicochemical descriptors, fuses the three modalities with a Finsler geometry-aware module, and distills knowledge from large teacher models such as MiniMol and MolFormer through contrastive learning to produce a single lightweight model that delivers high predictive performance and computational efficiency on molecular property prediction tasks.
What carries the argument
The Finsler geometry-aware fusion module that combines outputs from the three student encoders before contrastive distillation from the teacher models.
If this is right
- GLACIER achieves high predictive performance on complex molecular property tasks.
- The model uses less computation than large unimodal or multimodal baselines at comparable accuracy.
- The pretraining and distillation stages produce embeddings that transfer across different property prediction problems.
- The contrastive learning step transfers useful knowledge from the teachers into the compact student model.
- The framework supports scalability for screening large chemical libraries.
Where Pith is reading between the lines
- The same student-teacher pattern with geometric fusion could be tested on other scientific domains that have multiple data representations, such as protein sequences and structures.
- Replacing the Finsler fusion with simpler averaging or concatenation would provide a direct test of whether that module is necessary for the reported gains.
- Extending the pretraining corpus beyond 100,000 molecules might show whether performance continues to improve or saturates.
- The resulting lightweight model could support molecular design loops that run repeatedly on standard laptops rather than clusters.
Load-bearing premise
The three modalities supply complementary information that the fusion module and contrastive distillation can combine without substantial loss, yielding better efficiency-performance tradeoffs than baselines.
What would settle it
A head-to-head benchmark on standard molecular property datasets where GLACIER fails to match the accuracy of its teacher models or other multimodal baselines while using noticeably less compute at inference time would falsify the claim.
Figures
read the original abstract
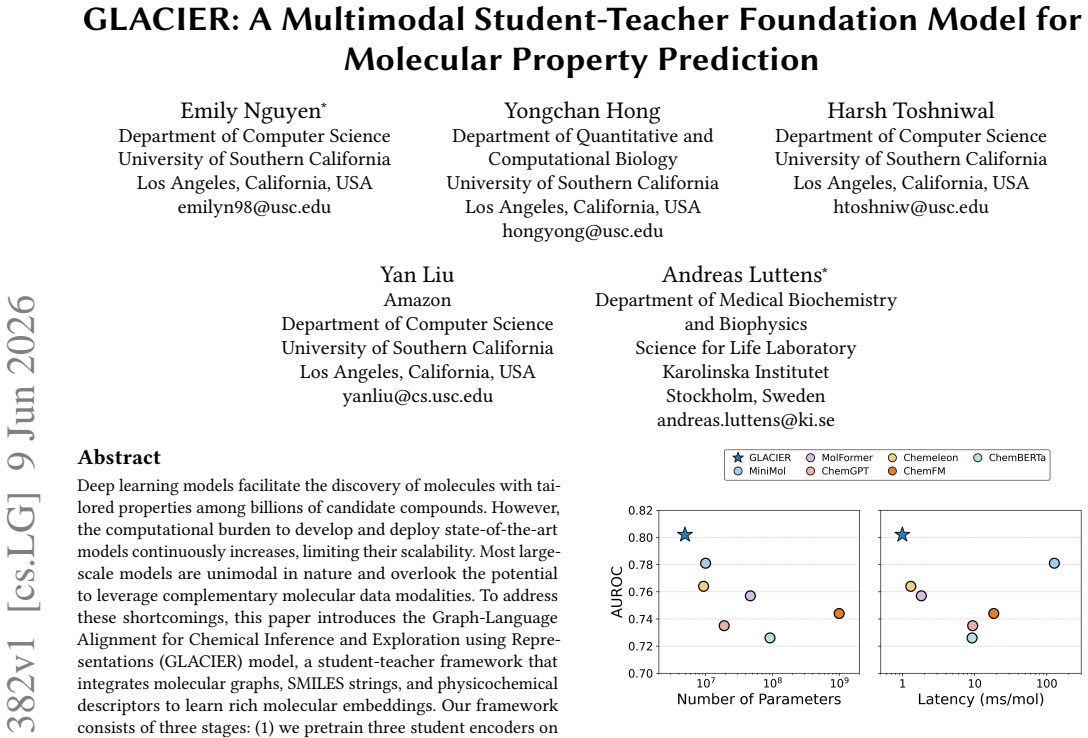
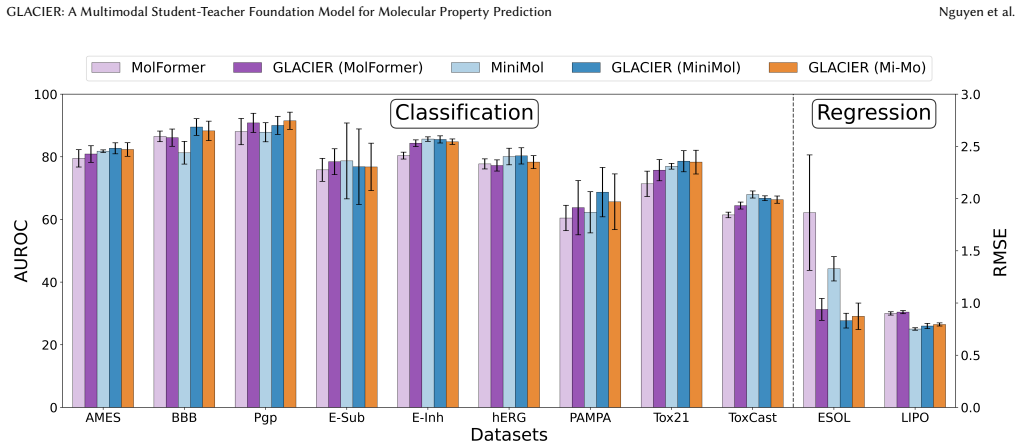
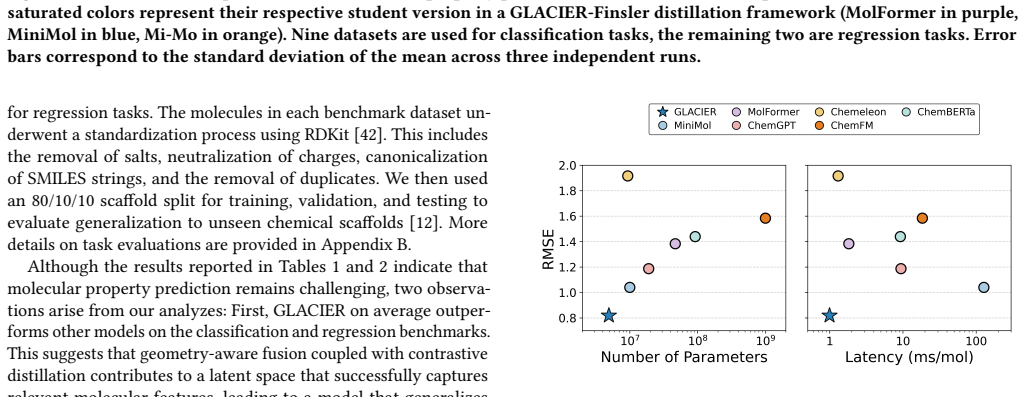
Deep learning models facilitate the discovery of molecules with tailored properties among billions of candidate compounds. However, the computational burden to develop and deploy state-of-the-art models continuously increases, limiting their scalability. Most large-scale models are unimodal in nature and overlook the potential to leverage complementary molecular data modalities. To address these shortcomings, this paper introduces the Graph-Language Alignment for Chemical Inference and Exploration using Representations (GLACIER) model, a student-teacher framework that integrates molecular graphs, SMILES strings, and physicochemical descriptors to learn rich molecular embeddings. Our framework consists of three stages: (1) we pretrain three student encoders on 100,000 drug-like molecules: a message-passing neural network for molecular graphs, a transformer-based encoder for SMILES strings, and a multilayer perceptron for physicochemical descriptors, (2) we fuse these student modalities using a novel Finsler geometry-aware module, and (3) distill complementary knowledge from large teacher models, including MiniMol and MolFormer, into a single lightweight model via contrastive learning. We demonstrate that GLACIER is a robust framework that delivers high predictive performance and computational efficiency in complex molecular property prediction tasks. Our code is publicly available at https://github.com/eemokey/glacier.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces GLACIER, a student-teacher multimodal framework for molecular property prediction. It pretrains three student encoders (MPNN on molecular graphs, transformer on SMILES strings, MLP on physicochemical descriptors) using 100,000 drug-like molecules, fuses the resulting modalities via a novel Finsler geometry-aware module, and applies contrastive distillation from large teacher models (MiniMol and MolFormer) to produce a single lightweight student model. The paper asserts that this yields a robust framework with high predictive performance and computational efficiency on complex molecular property prediction tasks, with code released publicly.
Significance. If the performance and efficiency claims are substantiated, the work could be significant for scalable molecular modeling by demonstrating effective multimodal integration and knowledge distillation that improves tradeoffs over unimodal baselines. The public code release at https://github.com/eemokey/glacier is a clear strength supporting potential reproducibility.
major comments (2)
- [Abstract] Abstract: The central claim that GLACIER 'delivers high predictive performance and computational efficiency' supplies no quantitative results, error bars, baselines, ablation studies, parameter/FLOP counts, inference times, or dataset statistics, which is load-bearing for assessing whether the three-stage framework (pretraining, Finsler fusion, contrastive distillation) actually integrates complementary signals without loss or outperforms existing methods.
- [Abstract] Abstract: No mathematical formulation, equations, or implementation details are given for the Finsler geometry-aware fusion module or the contrastive distillation objective, preventing evaluation of whether these components validly combine the graph MPNN, SMILES transformer, and descriptor MLP encoders as asserted.
minor comments (1)
- [Abstract] Abstract: The full acronym expansion for GLACIER is provided but the connection between 'Graph-Language Alignment for Chemical Inference and Exploration using Representations' and the three described modalities could be made more explicit for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight opportunities to strengthen the abstract. We agree that the abstract should better substantiate its claims with quantitative evidence and will revise it to include key results while preserving its concise nature. We address each point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that GLACIER 'delivers high predictive performance and computational efficiency' supplies no quantitative results, error bars, baselines, ablation studies, parameter/FLOP counts, inference times, or dataset statistics, which is load-bearing for assessing whether the three-stage framework (pretraining, Finsler fusion, contrastive distillation) actually integrates complementary signals without loss or outperforms existing methods.
Authors: We agree that the abstract would benefit from quantitative support. In the revised manuscript, we will add specific metrics to the abstract, including predictive performance (e.g., MAE or RMSE on standard benchmarks with error bars), comparisons to unimodal baselines, ablation results on the fusion and distillation stages, model size (parameters), computational efficiency (FLOPs and inference time), and dataset details (e.g., 100k pretraining molecules and downstream task statistics). These values are already reported with full experimental details in the results and methods sections of the full paper; the revision will highlight the most salient ones in the abstract to directly address the load-bearing claims. revision: yes
-
Referee: [Abstract] Abstract: No mathematical formulation, equations, or implementation details are given for the Finsler geometry-aware fusion module or the contrastive distillation objective, preventing evaluation of whether these components validly combine the graph MPNN, SMILES transformer, and descriptor MLP encoders as asserted.
Authors: Abstracts are typically high-level summaries and do not contain equations. However, to improve evaluability, the revised abstract will include a concise textual description of the Finsler fusion (geometry-aware integration of the three student modalities) and contrastive distillation (from MiniMol and MolFormer teachers). The full mathematical formulations, loss functions, and implementation details for both components are provided in the methods section of the manuscript (including the Finsler metric definition and the contrastive objective). We will ensure these sections are clearly cross-referenced and, if space allows, add a brief parenthetical reference to the key equations in the abstract. revision: yes
Circularity Check
No circularity: empirical ML framework with no derivation chain or self-referential predictions
full rationale
The paper presents GLACIER as a multimodal student-teacher architecture with three stages: pretraining separate encoders on graphs/SMILES/descriptors, Finsler-aware fusion, and contrastive distillation from teachers like MiniMol/MolFormer. No equations, first-principles derivations, or 'predictions' are claimed that reduce to fitted inputs by construction. Performance and efficiency claims are presented as experimental outcomes rather than mathematical necessities. No self-citation load-bearing steps, uniqueness theorems, or ansatzes appear in the abstract or described framework. This is a standard empirical architecture paper whose central claims are falsifiable via benchmarks and do not collapse to self-definition.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Michael Hay, David W. Thomas, John L. Craighead, Celia Economides, and Jesse Rosenthal. Clinical development success rates for investigational drugs.Nat Biotechnol, 32:40–51, 2014. https://doi.org/10.1038/nbt.2786
-
[2]
Wouters, Martin Mckee, and Jeroen Luyten
Olivier J. Wouters, Martin Mckee, and Jeroen Luyten. Estimated research and development investment needed to bring a new medicine to market, 2009-2018. JAMA, 323:844–853, 2020. https://doi.org/10.1001/jama.2022.14317
-
[3]
Analyzing Learned Molecular Representations for Property Prediction
Kevin Yang, Kyle Swanson, Wengong Jin, Connor Coley, Philipp Eiden, Hua Gao, Angel Guzman-Perez, Timothy Hopper, Brian Kelley, Miriam Mathea, Andrew Palmer, Volker Settels, Tommi Jaakkola, Klav Jensen, and Regina Barzilay. Ana- lyzing learned molecular representations for property prediction.J Chem Inf Model., 59:3370–3388, 2019. https://doi.org/10.1021/a...
-
[4]
Shah, Michaela Spitzer, and Shanrong Zhao
Jessica Vamathevan, Dominic Clark, Paul Czodrowski, Ian Dunham, Edgardo Ferran, George Lee, Bin Li, Anant Madabhushi, Parantu K. Shah, Michaela Spitzer, and Shanrong Zhao. Applications of machine learning in drug discovery and development.Nat Rev Drug Discov., 18:463–477, 2019. https://doi.org/10.1038/ s41573-019-0024-5
2019
-
[5]
Kyle Swanson, Parker Walther, Jeremy Leitz, Souhrid Mukherjee, Joseph C. Wu, Rabindra V. Shivnaraine, and James Zou. Admet-AI: a machine learning admet platform for evaluation of large-scale chemical libraries.Bioinformatics, 40, 2024. https://doi.org/10.1093/bioinformatics/btae416
-
[6]
Stokes, Kevin Yang, Kyle Swanson, Wengong Jin, Andres Cubillos- Ruiz, Nina M
Jonathan M. Stokes, Kevin Yang, Kyle Swanson, Wengong Jin, Andres Cubillos- Ruiz, Nina M. Donghia, Craig R. MacNair, Shawn French, Lindsey A. Carfrae, Zohar Bloom-Ackermann, Victoria M. Tran, Anush Chiappino-Pepe, Ahmed H. Badran, Ian W. Andrews, Emma J. Chory, George M. Church, Eric D. Brown, Tommi S. Jaakkola, Regina Barzilay, and James J. Collins. A de...
2020
-
[7]
Anahtar, Jackie A
Aarti Krishnan, Melis N. Anahtar, Jackie A. Valeri, Wengong Jin, Nina M. Donghia, Leif Sieben, Andreas Luttens, Yu Zhang, Seyed M. Modaresi, Andrew Hennes, Jenna Fromer, Parijat Bandyopadhyay, Jonathan C. Chen, Danyal Rehman, Ronak Desai, Paige Edwards, Ryan S. Lach, Marie-Stéphanie Aschtgen, Margaux Ga- borieau, Massimiliano Gaetani, Samantha G. Palace, ...
-
[8]
https://doi.org/10.1016/j.cell.2025.07.033
-
[9]
Rapid traversal of vast chemical space using machine learning-guided docking screens.Nat Comput Sci., 5:301–312, 03
Andreas Luttens, Israel Cabeza de Vaca, Leonard Sparring, José Brea, Antón Lean- dro Martínez, Nour Aldin Kahlous, Dmytro Radchenko, Yurii Moroz, María Isabel Loza, Ulf Norinder, and Jens Carlsson. Rapid traversal of vast chemical space using machine learning-guided docking screens.Nat Comput Sci., 5:301–312, 03
-
[10]
https://doi.org/10.1038/s43588-025-00777-x
-
[11]
Communications Chemistry , year =
Cai Feiyang, Katelin Zacour, Zhu Tianyu, Tzeng Tzuen-Rong, Duan Yongping, Liu Ling, Pilla Srikanth, Li Gang, and Luo Feng. Chemfm as a scaling law guided foundation model pre-trained on informative chemicals.Commun Chem., 9, 2025. https://doi.org/10.1038/s42004-025-01793-8
-
[12]
Seyone Chithrananda, Gabriel Grand, and Bharath Ramsundar. Chemberta: Large-scale self-supervised pretraining for molecular property prediction.arXiv, 2010.09885, 2020. https://doi.org/10.48550/arXiv.2010.09885
-
[13]
Belgodere, Vijil Chenthamarakshan, Inkit Padhi, Youssef Mroueh, and Payel Das
Jerret Ross, Brian M. Belgodere, Vijil Chenthamarakshan, Inkit Padhi, Youssef Mroueh, and Payel Das. Large-scale chemical language representations capture molecular structure and properties.Nat Mach Intell, 4:1256–1264, 2021. https: //doi.org/10.1038/s42256-022-00580-7
-
[14]
and Gomes, Joseph and Geniesse, Caleb and Pappu, Aneesh S
Zhenqin Wu, Bharath Ramsundar, Evan N. Feinberg, Joseph Gomes, Caleb Geniesse, Aneesh S. Pappu, Karl Leswing, and Vijay S. Pande. Moleculenet: a benchmark for molecular machine learning.Chem Sci., 9:513–530, 2017. https://doi.org/10.1039/c7sc02664a
-
[15]
Coley, Cao Xiao, Jimeng Sun, and Marinka Zitnik
Kexin Huang, Tianfan Fu, Wenhao Gao, Yue Zhao, Yusuf Roohani, Jure Leskovec, Connor W. Coley, Cao Xiao, Jimeng Sun, and Marinka Zitnik. Therapeutics data commons: Machine learning datasets and tasks for drug discovery and develop- ment.Proceedings of Neural Information Processing Systems, NeurIPS Datasets and Benchmarks, 2021. URL https://openreview.net/f...
2021
-
[16]
Self-supervised graph transformer on large-scale molecular data
Yu Rong, Yatao Bian, Tingyang Xu, Weiyang Xie, Ying Wei, Wenbing Huang, and Junzhou Huang. Self-supervised graph transformer on large-scale molecular data. InAdvances in Neural Information Processing Systems, volume 33, pages 12559–12571, 2020
2020
-
[17]
Uni-mol: A universal 3d molecular represen- tation learning framework
Gengmo Zhou, Zhifeng Gao, Qiankun Ding, Hang Zheng, Hongteng Xu, Zhewei Wei, Linfeng Zhang, and Guolin Ke. Uni-mol: A universal 3d molecular represen- tation learning framework. InThe Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=6K2RM6wVqKu
2023
-
[18]
Zheni Zeng, Yuan Yao, Zhiyuan Liu, and Maosong Sun. A deep-learning system bridging molecule structure and biomedical text with comprehension comparable to human professionals.Nat Commun, 13, 2022. https://doi.org/10.1038/s41467- 022-28494-3
-
[19]
Kerstin Kläser, Bla.zej Banaszewski, Samuel Maddrell-Mander, Callum McLean, Luis Müller, Alipanah Parviz, Shenyang Huang, and Andrew W. Fitzgibbon. Minimol: A parameter-efficient foundation model for molecular learning.arXiv, 2404.14986, 2024. https://doi.org/10.48550/arXiv.2404.14986
-
[20]
Sur les espaces de finsler
Elie Cartan. Sur les espaces de finsler. InComptes rendus de l’Académie des Sciences, volume 196, pages 582–586, 1933
1933
-
[21]
Thomas Dagès, Simon Nikolaus Weber, Ya-Wei Eileen Lin, Ronen Talmon, Daniel Cremers, Michael Lindenbaum, Alfred Marcel Bruckstein, and Ron Kimmel. Finsler multi-Dimensional Scaling: Manifold Learning for Asymmetric Dimen- sionality Reduction and Embedding.Conference on Computer Vision and Pattern Recognition (CVPR), pages 25842–25853, 2025. https://doi.or...
-
[22]
Smiles, a chemical language and information system
David Weininger. Smiles, a chemical language and information system. 1. intro- duction to methodology and encoding rules.J. Chem. Inf. Comput. Sci., 28(1): 31–36, 1988. https://doi.org/10.1021/ci00057a005
-
[23]
Laurianne David, Amol Thakkar, Rocío Mercado, and Ola Engkvist. Molecular representations in ai-driven drug discovery: a review and practical guide.J Cheminform., 12, 2020. https://doi.org/10.1186/s13321-020-00460-5
-
[24]
Mateusz Praski, Jakub Adamczyk, and Wojciech Czech. Benchmarking pretrained molecular embedding models for molecular representation learning.arXiv, 2508.06199, 2025. https://doi.org/10.48550/arXiv.2508.06199
-
[25]
Pre-training molecular graph representation with 3d geometry.arXiv, 2110.07728, 2021
Shengchao Liu, Hanchen Wang, Weiyang Liu, Joan Lasenby, Hongyu Guo, and Jian Tang. Pre-training molecular graph representation with 3d geometry.arXiv, 2110.07728, 2021. https://doi.org/10.48550/arXiv.2110.07728
-
[26]
Fragment-based pretraining and finetuning on molecular graphs.Advances in Neural Information Processing Systems, 36: 17584–17601, 2023
Kha-Dinh Luong and Ambuj K Singh. Fragment-based pretraining and finetuning on molecular graphs.Advances in Neural Information Processing Systems, 36: 17584–17601, 2023
2023
-
[27]
Descriptor-based foundation models for molecular property prediction.arXiv, 2506.15792, 2025
Jackson Burns, Akshat Shirish Zalte, and William Green. Descriptor-based foundation models for molecular property prediction.arXiv, 2506.15792, 2025. https://doi.org/10.48550/arXiv.2506.15792
-
[28]
Riya Singh, Aryan Amit Barsainyan, Rida Irfan, Connor Joseph Amorin, Stewart He, Tony Davis, Arun Pa Thiagarajan, Shiva Sankaran, Seyone Chithrananda, Wal¯ıd Ah. mad, Derek Jones, Kevin S. McLoughlin, Hyojin Kim, Anoushka Bhutani, Shreyas Vinaya Sathyanarayana, Venkat Viswanathan, Jonathan E. Allen, and Bharath Ramsundar. Chemberta-3: An open source train...
-
[29]
Frey, Ryan Soklaski, Simon Axelrod, Siddharth Samsi, Rafael G´omez- Bombarelli, Connor W
Nathan C. Frey, Ryan Soklaski, Simon Axelrod, Siddharth Samsi, Rafael G´omez- Bombarelli, Connor W. Coley, and Vijay Gadepally. Neural scaling of deep chemical models.Nat Mach Intell, 5:1297–1305, 2023. https://doi.org/10.1038/ s42256-023-00740-3
2023
-
[30]
Juncai Li and Xiaofei Jiang. Mol-bert: An effective molecular representation with bert for molecular property prediction.Wireless Communications and Mobile Computing, 2021(1):7181815, 2021. https://doi.org/10.1155/2021/7181815. 9 GLACIER: A Multimodal Student-Teacher Foundation Model for Molecular Property Prediction Nguyen et al
-
[31]
Chae Eun Lee, Jin Sob Kim, Jin Hong Min, and Sung Won Han. Simson: simple contrastive learning of smiles for molecular property prediction.Bioinformatics, 41(5):btaf275, 2025. https://doi.org/10.1093/bioinformatics/btaf275
-
[32]
Gomez, Łukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdvances in Neural Information Processing Systems, volume 30, 2017
2017
-
[33]
Exploring molecular pretraining model at scale
Xiaohong Ji, Zhen Wang, Zhifeng Gao, Hang Zheng, Linfeng Zhang, Guolin Ke, and Weinan E. Exploring molecular pretraining model at scale. InAdvances in Neural Information Processing Systems, volume 37, pages 46956–46978, 2024. URL https://openreview.net/forum?id=64V40K2fDv
2024
-
[34]
Relative molecule self- attention transformer.J Cheminform., 16, 2021
Łukasz Maziarka, Dawid Majchrowski, Tomasz Danel, Piotr Gaiński, Jacek Tabor, Igor Podolak, Paweł Morkisz, and Stanisław Jastrzębski. Relative molecule self- attention transformer.J Cheminform., 16, 2021. https://doi.org/10.1186/s13321- 023-00789-7
-
[35]
On the computational complexity of self-attention
Feyza Duman Keles, Pruthuvi Maheshakya Wijewardena, and Chinmay Hegde. On the computational complexity of self-attention. InProceedings of The 34th In- ternational Conference on Algorithmic Learning Theory, volume 201 ofProceedings of Machine Learning Research, pages 597–619. PMLR, 2023
2023
-
[36]
Accelerating molecular graph neural networks via knowledge distillation
Filip Ekström Kelvinius, Dimitar Georgiev, Artur Toshev, and Johannes Gasteiger. Accelerating molecular graph neural networks via knowledge distillation. In Advances in Neural Information Processing Systems, volume 36, pages 25761– 25792, 2023. URL https://openreview.net/forum?id=A18PgVSUgf
2023
-
[37]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InProceedings of the 38th International Conference on Machine Learning, volume 139 ofProceedings of ...
2021
-
[38]
CL-MFAP: A contrastive learning-based multimodal foundation model for molecular property prediction and antibiotic screening
Gen Zhou, Sugitha Janarthanan, Yutong Lu, and Pingzhao Hu. CL-MFAP: A contrastive learning-based multimodal foundation model for molecular property prediction and antibiotic screening. InThe Thirteenth International Confer- ence on Learning Representations, 2025. URL https://openreview.net/forum?id= fv9XU7CyN2
2025
-
[39]
Williams, Carl Underkoffler, Ryan Pederson, Narbe Mardirossian, Ian Watson, and John Parkhill
Benjamin Kaufman, Edward C. Williams, Carl Underkoffler, Ryan Pederson, Narbe Mardirossian, Ian Watson, and John Parkhill. Coati: Multimodal con- trastive pretraining for representing and traversing chemical space.J Chem Inf Model., 64(4):1145–1157, 2024. https://doi.org/10.1021/acs.jcim.3c01753
-
[40]
Pengfei Liu, Yiming Ren, Jun Tao, and Zhixiang Ren. Git-mol: A multi-modal large language model for molecular science with graph, image, and text.Comput Biol Med., page 108073, 2024. https://doi.org/10.1016/j.compbiomed.2024.108073
-
[41]
Advancing molecular graph-text pre-training via fine-grained alignment
Yibo Li, Yuan Fang, Mengmei Zhang, and Chuan Shi. Advancing molecular graph-text pre-training via fine-grained alignment. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V.2, pages 1589–1599. Association for Computing Machinery, 2025. https://doi.org/10.1145/ 3711896.3736834
arXiv 2025
-
[42]
Schoenholz, Patrick F
Justin Gilmer, Samuel S. Schoenholz, Patrick F. Riley, Oriol Vinyals, and George E. Dahl. Neural message passing for quantum chemistry. InInternational conference on machine learning, pages 1263–1272. PMLR, 2017
2017
-
[43]
Enamine real space, 2024
Enamine. Enamine real space, 2024. URL https://enamine.net/compound- collections/real-compounds/real-space-navigator
2024
-
[44]
RDKit Open-Source Cheminformatics Software, 2025
RDKit. RDKit Open-Source Cheminformatics Software, 2025. URL https://www. rdkit.org/docs/
2025
-
[45]
On an asymmetrical metric in the four-space of general rela- tivity.Phys
Gunnar Randers. On an asymmetrical metric in the four-space of general rela- tivity.Phys. Rev., 59:195–199, Jan 1941. https://doi.org/10.1103/PhysRev.59.195. URL https://link.aps.org/doi/10.1103/PhysRev.59.195
-
[46]
Gated Attention for Large Language Models: Non-linearity, Sparsity, and Attention-Sink-Free
Zihan Qiu, Zekun Wang, Bo Zheng, Zeyu Huang, Kaiyue Wen, Songlin Yang, Rui Men, Le Yu, Fei Huang, Suozhi Huang, Dayiheng Liu, Jingren Zhou, and Junyang Lin. Gated attention for large language models: Non-linearity, sparsity, and attention-sink-free.arXiv, 2025. https://doi.org/10.48550/arXiv.2505.06708
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.06708 2025
-
[47]
Representation learning with contrastive predictive coding.arXiv, 1807.03748, 2018
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predictive coding.arXiv, 1807.03748, 2018. https://doi.org/10.48550/ arXiv.1807.03748
Pith/arXiv arXiv 2018
-
[48]
Oleksandr O. Grygorenko, Dmytro S. Radchenko, Igor Dziuba, Alexander Chup- rina, Kateryna E. Gubina, and Yurii S. Moroz. Generating multibillion chemical space of readily accessible screening compounds.iScience, 23(11):101681, 2020. ISSN 2589-0042. https://doi.org/10.1016/j.isci.2020.101681
-
[49]
Chemaxon Extended SMILES and SMARTS-CXSMILES and CXSMARTS-Documentation, 2025
ChemAxon. Chemaxon Extended SMILES and SMARTS-CXSMILES and CXSMARTS-Documentation, 2025. URL https://docs.chemaxon.com/ latest/formats_chemaxon-extended-smiles-and-smarts-cxsmiles-and- cxsmarts.html
2025
-
[50]
Esben Jannik Bjerrum. Smiles enumeration as data augmentation for neural network modeling of molecules.arXiv, 1703.07076, 2017. https://doi.org/10. 48550/arXiv.1703.07076
Pith/arXiv arXiv 2017
-
[51]
TRIDENT: Tri-modal molecular representation learning with taxonomic annotations and local corre- spondence
Feng Jiang, Mangal Prakash, Hehuan Ma, Jianyuan Deng, Yuzhi Guo, Amina Mollaysa, Tommaso Mansi, Rui Liao, and Junzhou Huang. TRIDENT: Tri-modal molecular representation learning with taxonomic annotations and local corre- spondence. InAdvances in Neural Information Processing Systems, volume 38, pages 174391–174419, 2026. URL https://openreview.net/forum?...
2026
-
[52]
Why is tanimoto index an appropriate choice for fingerprint-based similarity calculations?J Cheminform.,
Dávid Bajusz, Anita Rácz, and Károly Héberger. Why is tanimoto index an appropriate choice for fingerprint-based similarity calculations?J Cheminform.,
-
[53]
https://doi.org/10.1186/s13321-015-0069-3
-
[54]
Visualizing data using t-SNE
Laurens Van der Maaten and Geoffrey Hinton. Visualizing data using t-SNE. Journal of Machine Learning Research, 9(86):2579–2605, 2008. URL http://jmlr. org/papers/v9/vandermaaten08a.html
2008
-
[55]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Thomas Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeff Wu, and Dario Amodei. Scaling laws for neural language models.arXiv, 2001.08361, 2020. https://doi. org/10.48550/arXiv.2001.08361
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2001.08361 2001
-
[56]
Preetum Nakkiran, Gal Kaplun, Yamini Bansal, Tristan Yang, Boaz Barak, and Ilya Sutskever. Deep double descent: Where bigger models and more data hurt. J. Stat. Mech.: Theory Exp., 2021(12):124003, 2021. https://doi.org/10.1088/1742- 5468/ac3a74
-
[57]
Tetralith, 2025
National Supercomputer Centre at Linköping University. Tetralith, 2025. URL https://www.nsc.liu.se/systems/tetralith/
2025
-
[58]
Simi- larity of neural network representations revisited
Simon Kornblith, Mohammad Norouzi, Honglak Lee, and Geoffrey Hinton. Simi- larity of neural network representations revisited. In Kamalika Chaudhuri and Ruslan Salakhutdinov, editors,Proceedings of the 36th International Conference on Machine Learning, volume 97 ofProceedings of Machine Learning Research, pages 3519–3529. PMLR, 2019
2019
-
[59]
Measur- ing statistical dependence with hilbert-schmidt norms
Arthur Gretton, Olivier Bousquet, Alex Smola, and Bernhard Schölkopf. Measur- ing statistical dependence with hilbert-schmidt norms. InAlgorithmic Learning Theory, pages 63–77. Springer Berlin Heidelberg, 2005. https://doi.org/10.1007/ 11564089_7. 10 GLACIER: A Multimodal Student-Teacher Foundation Model for Molecular Property Prediction Nguyen et al. A I...
2005
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.