Gumbel-BEARD: Automatic Layer Selection for Self-Supervised Adaptation of Whisper in Low-Resource Domains
Pith reviewed 2026-06-27 11:19 UTC · model grok-4.3
The pith
A trainable Gumbel-Softmax selector lets Whisper adapt its layers to child speech and match full supervision using only 10 hours of labeled data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Gumbel-BEARD automates Whisper encoder layer selection with an end-to-end trainable hard Gumbel-Softmax selector and applies a BEST-RQ self-supervised objective to adapt the chosen layers to target acoustics without manual intervention. On the MyST child-speech corpus this procedure lets a model fine-tuned on 10 hours of labeled data match the performance of a fully supervised model trained on the full 133-hour set. The method records new state-of-the-art word error rates of 8.21 percent with Whisper-medium on MyST and 11.06 percent with Whisper-small on the OGI Spontaneous dataset, and it produces up to 6 percent relative error reduction on the CORAAL dialectal corpus.
What carries the argument
End-to-end trainable hard Gumbel-Softmax selector that automatically chooses Whisper encoder layers for adaptation, combined with the BEST-RQ self-supervised objective.
If this is right
- 10 hours of labeled fine-tuning data suffices to match a 133-hour fully supervised baseline on MyST child speech.
- New state-of-the-art word error rate of 8.21 percent is reached with Whisper-medium on MyST.
- New state-of-the-art word error rate of 11.06 percent is reached with Whisper-small on the OGI Spontaneous dataset.
- Up to 6 percent relative word error rate reduction occurs on the CORAAL adult dialectal corpus.
Where Pith is reading between the lines
- The same selector mechanism could be applied to other speech foundation models facing domain mismatch.
- Performance with substantially less than 10 hours of labeled data after adaptation remains an open test of the method's data efficiency.
- The approach suggests that automatic layer selection may replace full-model fine-tuning in many low-resource speech tasks.
Load-bearing premise
The hard Gumbel-Softmax selector can discover effective layer choices from the self-supervised BEST-RQ objective without any extra labeled data for the selection step.
What would settle it
If replacing the trainable selector with a fixed or random layer choice still produces the same word-error-rate match to the 133-hour baseline on MyST after 10-hour fine-tuning, the claim that the selector is required would be refuted.
Figures
read the original abstract
Speech foundation models often struggle in low-resource domains due to domain mismatch and data scarcity. We propose Gumbel-BEARD, a domain adaptation framework that automates Whisper encoder layer selection via an end-to-end trainable hard Gumbel-Softmax selector. It enables self-supervised adaptation with a BEST-RQ objective that dynamically adapts to target acoustic characteristics without manual tuning. Experiments on the MyST child speech corpus demonstrate efficiency and scalability: with 10 h of labeled data for fine-tuning, our method matches a fully supervised baseline trained on the complete 133 h labeled set. We establish new state-of-the-art word error rates (WERs) of 8.21% using Whisper-medium on MyST and 11.06% using Whisper-small on the OGI Spontaneous dataset. Evaluation on CORAAL further confirms robustness to adult dialectal domain shifts, with up to 6% relative WER reduction, highlighting the generalizability of our approach to diverse low-resource conditions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Gumbel-BEARD, a domain adaptation framework for Whisper that automates encoder layer selection via an end-to-end trainable hard Gumbel-Softmax selector combined with the BEST-RQ self-supervised objective. It claims that on the MyST child speech corpus, fine-tuning with only 10 h of labeled data matches the performance of a fully supervised baseline trained on the full 133 h set, while also reporting new SOTA WERs of 8.21% (Whisper-medium on MyST) and 11.06% (Whisper-small on OGI Spontaneous), plus up to 6% relative WER reduction on CORAAL for dialectal shifts.
Significance. If the reported empirical results hold under replication with proper controls, the work would be significant for low-resource speech recognition by demonstrating an automated, low-labeled-data approach to adapting large foundation models to domain shifts such as child speech without manual layer tuning.
major comments (2)
- Abstract: the central claims of matching the 133 h supervised baseline with 10 h labeled data and establishing new SOTA WERs are presented with no experimental details, baselines, error bars, number of runs, or statistical tests. This is load-bearing for the empirical contribution and prevents verification of the reported numbers.
- Abstract: the method is described at a high level with no equations, pseudocode, or derivation for the hard Gumbel-Softmax selector or its integration with BEST-RQ; without these, it is impossible to assess whether the selector is truly parameter-free or reduces to a fitted quantity by construction.
Simulated Author's Rebuttal
We thank the referee for the feedback. We address the two major comments on the abstract below, noting that abstracts are intentionally concise summaries while full details appear in the manuscript body.
read point-by-point responses
-
Referee: Abstract: the central claims of matching the 133 h supervised baseline with 10 h labeled data and establishing new SOTA WERs are presented with no experimental details, baselines, error bars, number of runs, or statistical tests. This is load-bearing for the empirical contribution and prevents verification of the reported numbers.
Authors: We agree the abstract presents results at a summary level without these specifics. The full experimental details—including the 10 h vs. 133 h comparison on MyST, baselines, error bars from multiple runs, and statistical tests—are reported in Sections 4.1–4.3. We will revise the abstract to include a brief reference to the evaluation protocol and number of runs for improved clarity. revision: yes
-
Referee: Abstract: the method is described at a high level with no equations, pseudocode, or derivation for the hard Gumbel-Softmax selector or its integration with BEST-RQ; without these, it is impossible to assess whether the selector is truly parameter-free or reduces to a fitted quantity by construction.
Authors: Abstracts conventionally omit equations and derivations. The complete formulation of the hard Gumbel-Softmax selector, its end-to-end integration with BEST-RQ, equations, and pseudocode appear in Section 3. The selector is jointly trained rather than post-hoc fitted, as confirmed by ablations in Section 4.4 demonstrating gains from learned selection over fixed or manual alternatives; it requires no manual layer tuning by design. revision: no
Circularity Check
No significant circularity
full rationale
The paper presents an empirical domain-adaptation procedure (hard Gumbel-Softmax layer selector + BEST-RQ objective) whose central claims are experimental WER numbers obtained after fine-tuning on stated data quantities. No equations, uniqueness theorems, or first-principles derivations are offered that could reduce to fitted inputs or self-citations by construction; the reported results are falsifiable replication targets rather than algebraic identities.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
However, these models suffer significant per- formance degradation in low-resource domains, where domain mismatch and data scarcity remain critical challenges [5]
Introduction Recent advancements in automatic speech recognition (ASR) have been driven by deep neural networks trained on large- scale datasets, yielding strong end-to-end models such as Ope- nAI Whisper [1], Meta SeamlessM4T [2], NVIDIA Canary [3], and OWSM [4]. However, these models suffer significant per- formance degradation in low-resource domains, ...
-
[2]
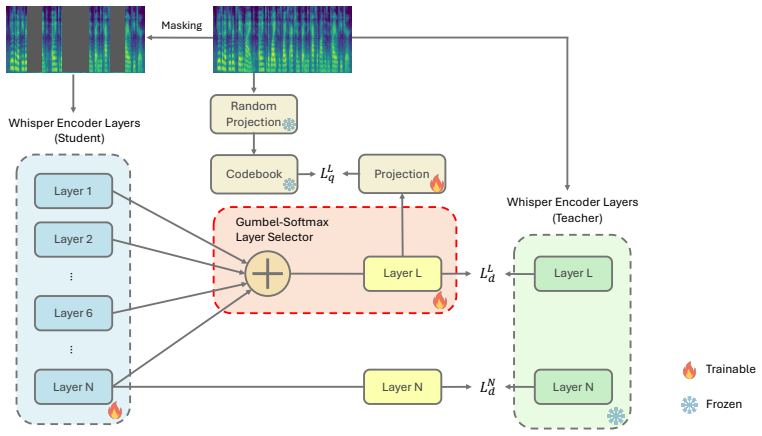
𝐿!# Layer L Layer N Whisper Encoder Layers (Teacher) Projection TrainableFrozen 𝐿$
Methods 2.1. Background: The BEARD Framework BEARD [30] adapts Whisper through a two-stage procedure. In the first stage, the Whisper encoder is adapted on unlabeled data using a combination of self-supervised learning and distil- lation, while the decoder is excluded from training. For the self- supervised objective, BEARD adopts BEST-RQ [38], where a fr...
Pith/arXiv arXiv 2026
-
[3]
Datasets To evaluate the efficacy of our proposed method on domain shifts, we conduct experiments on three distinct corpora rep- resenting child speech and dialectal variations
Experiments 3.1. Datasets To evaluate the efficacy of our proposed method on domain shifts, we conduct experiments on three distinct corpora rep- resenting child speech and dialectal variations. •MyST [35]:A large corpus of conversational child speech from students (grades 3–5) interacting with a virtual science tutor. Of the total 448 h, only 240 h are t...
2048
-
[4]
Comparison with Baselines on MyST Table 1 reports WER on the MyST test set with the Whisper- small backbone
Results 4.1. Comparison with Baselines on MyST Table 1 reports WER on the MyST test set with the Whisper- small backbone. Gumbel-BEARD (hard selection) consistently outperforms all baselines across labeled data budgets, with sta- tistically significant gains (p <0.05) over SFT. With only 10 h of labeled data, it attains 9.35% WER, nearly matching the SFT ...
-
[5]
Our experiments establish state-of-the-art WERs of 8.21% on MyST and 11.06% on the OGI Spontaneous test set, with general- ization to adult dialectal speech (CORAAL)
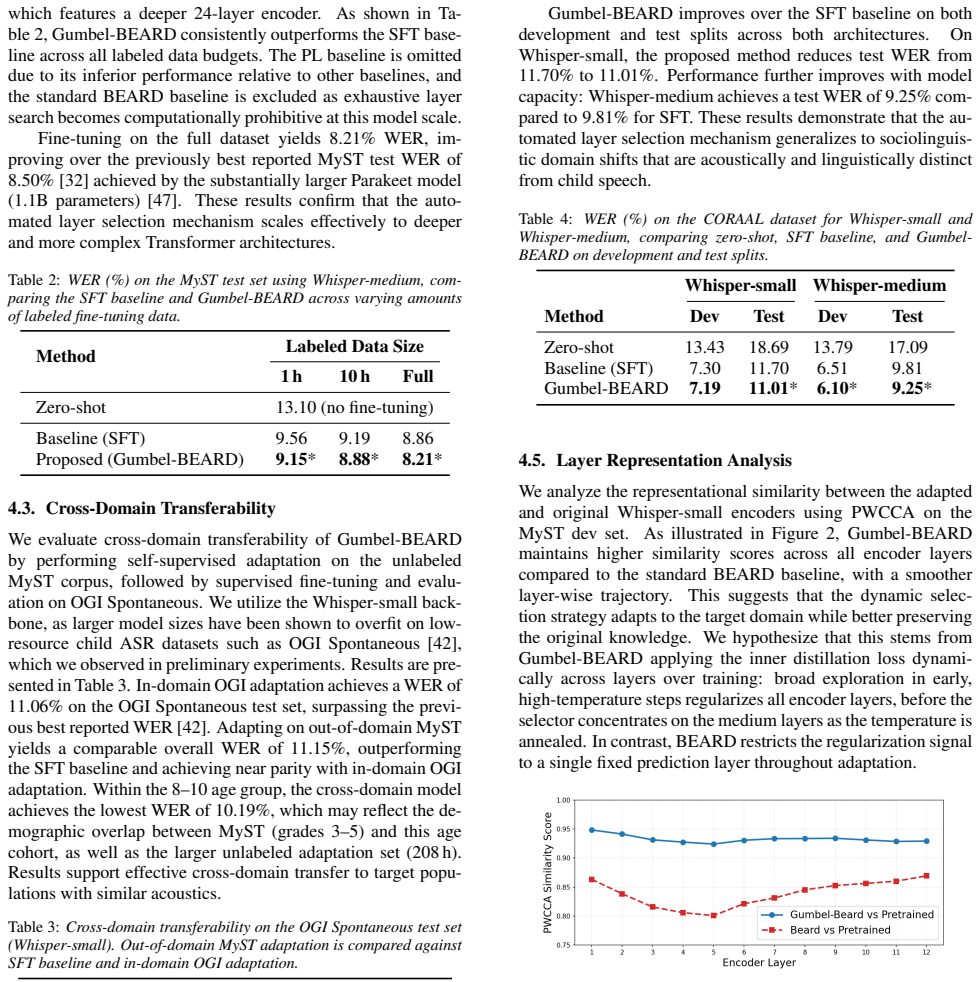
Conclusion We introduce Gumbel-BEARD, a domain adaptation frame- work that automates Whisper encoder layer selection via an end-to-end trainable hard Gumbel-Softmax layer selector. Our experiments establish state-of-the-art WERs of 8.21% on MyST and 11.06% on the OGI Spontaneous test set, with general- ization to adult dialectal speech (CORAAL). PWCCA ana...
-
[6]
Department of Education (DoE), through Grant R305C240046 to the U
Acknowledgements This research is supported in part by the National Science Foun- dation (NSF) and the Institute of Education Sciences (IES), U.S. Department of Education (DoE), through Grant R305C240046 to the U. at Buffalo. The opinions expressed are those of the authors and do not represent views of the IES, DoE, or the NSF
-
[7]
All technical con- tent, experimental design, results, and conclusions were inde- pendently developed and verified by the authors
Generative AI Use Disclosure During the preparation of this manuscript, the authors utilized ChatGPT (GPT-5.2) exclusively for language editing, includ- ing proofreading and enhancing readability. All technical con- tent, experimental design, results, and conclusions were inde- pendently developed and verified by the authors. Following the use of this too...
-
[8]
Robust speech recognition via large-scale weak supervision,
A. Radfordet al., “Robust speech recognition via large-scale weak supervision,” inProc. ICML, 2023
2023
-
[9]
Seamless: Multilingual expressive and streaming speech translation,
L. Barraultet al., “Seamless: Multilingual expressive and streaming speech translation,”CoRR, vol. abs/2312.05187, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2312.05187
-
[10]
Less is more: Accurate speech recognition & translation without web-scale data,
K. C. Puvvadaet al., “Less is more: Accurate speech recognition & translation without web-scale data,” inINTERSPEECH, 2024
2024
-
[11]
OWSM v3.1: Better and faster open whisper-style speech models based on e-branchformer,
Y . Penget al., “OWSM v3.1: Better and faster open whisper-style speech models based on e-branchformer,” inINTERSPEECH, 2024
2024
-
[12]
ML-SUPERB 2.0: Benchmarking multilingual speech models across modeling constraints, languages, and datasets,
J. Shiet al., “ML-SUPERB 2.0: Benchmarking multilingual speech models across modeling constraints, languages, and datasets,” inINTERSPEECH, 2024
2024
-
[13]
V ocal tract length perturbation (vtlp) improves speech recognition,
N. Jaitly and G. E. Hinton, “V ocal tract length perturbation (vtlp) improves speech recognition,”Proc. ICML Workshop on Deep Learning for Audio, Speech and Language, 2013
2013
-
[14]
Specaugment: A simple data augmentation method for automatic speech recognition,
D. S. Parket al., “Specaugment: A simple data augmentation method for automatic speech recognition,” inINTERSPEECH, 2019
2019
-
[15]
Audio augmentation for speech recognition,
T. Koet al., “Audio augmentation for speech recognition,” inIN- TERSPEECH, 2015
2015
-
[16]
V oice conversion can improve ASR in very low-resource settings,
M. Baas and H. Kamper, “V oice conversion can improve ASR in very low-resource settings,” inINTERSPEECH, 2022
2022
-
[17]
Parameter-efficient transfer learning for NLP,
N. Houlsbyet al., “Parameter-efficient transfer learning for NLP,” inICML, 2019
2019
-
[18]
Prefix-tuning: Optimizing continuous prompts for generation,
X. L. Li and P. Liang, “Prefix-tuning: Optimizing continuous prompts for generation,” inACL/IJCNLP (1), 2021
2021
-
[19]
Lora: Low-rank adaptation of large language mod- els,
E. J. Huet al., “Lora: Low-rank adaptation of large language mod- els,” inICLR, 2022
2022
-
[20]
P-tuning: Prompt tuning can be comparable to fine- tuning across scales and tasks,
X. Liuet al., “P-tuning: Prompt tuning can be comparable to fine- tuning across scales and tasks,” inACL (2), 2022
2022
-
[21]
Transfer learning from adult to children for speech recognition: Evaluation, analysis and recommendations,
P. G. Shivakumar and P. G. Georgiou, “Transfer learning from adult to children for speech recognition: Evaluation, analysis and recommendations,”Comput. Speech Lang., vol. 63, p. 101077, 2020
2020
-
[22]
Beyond traditional speech modifications: Utilizing self supervised features for en- hanced zero-shot children asr,
A. Sinha, H. K. Kathania, and M. Kurimo, “Beyond traditional speech modifications: Utilizing self supervised features for en- hanced zero-shot children asr,” inINTERSPEECH, 2025
2025
-
[23]
Multilingual transfer learning for children au- tomatic speech recognition,
T. Rollandet al., “Multilingual transfer learning for children au- tomatic speech recognition,” inLREC, 2022
2022
-
[24]
Selective attention merging for low resource tasks: A case study of child ASR,
N. B. Shankaret al., “Selective attention merging for low resource tasks: A case study of child ASR,” inICASSP, 2025
2025
-
[25]
Task vector arithmetic for low-resource ASR,
H. Nagasawa, S. Otake, and S. Iwata, “Task vector arithmetic for low-resource ASR,” inICASSP, 2025
2025
-
[26]
Compositional domain adaptation for auto- matic speech recognition with headwise selective attention merg- ing,
N. B. Shankaret al., “Compositional domain adaptation for auto- matic speech recognition with headwise selective attention merg- ing,”Computer Speech & Language, p. 102012, 2026
2026
-
[27]
Combining spectral and self-supervised fea- tures for low resource speech recognition and translation,
D. Berrebbiet al., “Combining spectral and self-supervised fea- tures for low resource speech recognition and translation,” inIN- TERSPEECH, 2022
2022
-
[28]
EFFUSE: efficient self-supervised feature fu- sion for E2E ASR in low resource and multilingual scenarios,
T. Srivastavaet al., “EFFUSE: efficient self-supervised feature fu- sion for E2E ASR in low resource and multilingual scenarios,” in INTERSPEECH, 2024
2024
-
[29]
Learnable layer selection and model fusion for speech self-supervised learning models,
S. Chiuet al., “Learnable layer selection and model fusion for speech self-supervised learning models,” inINTERSPEECH, 2024
2024
-
[30]
Mind the shift: Using delta ssl embeddings to enhance child asr,
Z. Wanget al., “Mind the shift: Using delta ssl embeddings to enhance child asr,” inICASSP, 2026
2026
-
[31]
Self-training for end-to-end speech recognition,
J. Kahn, A. Lee, and A. Y . Hannun, “Self-training for end-to-end speech recognition,” inICASSP, 2020
2020
-
[32]
Pseudo label is better than human label,
D. Hwanget al., “Pseudo label is better than human label,” in INTERSPEECH, 2022
2022
-
[33]
Large-scale ASR domain adaptation using self- and semi- supervised learning,
——, “Large-scale ASR domain adaptation using self- and semi- supervised learning,” inICASSP, 2022
2022
-
[34]
Self-taught recognizer: Toward unsupervised adap- tation for speech foundation models,
Y . Huet al., “Self-taught recognizer: Toward unsupervised adap- tation for speech foundation models,” inNeurIPS, 2024
2024
-
[35]
SOA: reducing domain mismatch in SSL pipeline by speech only adaptation for low re- source ASR,
N. B. Shankar, R. Fan, and A. Alwan, “SOA: reducing domain mismatch in SSL pipeline by speech only adaptation for low re- source ASR,” inICASSP Workshops, 2024
2024
-
[36]
Comparing unsupervised and supervised semantic speech tokens: A case study of child ASR,
M. Shiet al., “Comparing unsupervised and supervised semantic speech tokens: A case study of child ASR,” inIEEE ASRU Satel- lite Workshop-AI for Children’s Speech and Language, 2025
2025
-
[37]
Best-rq-based self-supervised learning for whisper domain adaptation,
R. Bagat, I. Illina, and E. Vincent, “Best-rq-based self-supervised learning for whisper domain adaptation,” inICASSP, 2026
2026
-
[38]
Interface design for self-supervised speech models,
Y . Shih and D. Harwath, “Interface design for self-supervised speech models,” inINTERSPEECH, 2024
2024
-
[39]
Benchmarking children’s asr with supervised and self-supervised speech foundation models,
R. Fanet al., “Benchmarking children’s asr with supervised and self-supervised speech foundation models,” inINTERSPEECH, 2024
2024
-
[40]
Acoustics of children’s speech: Developmental changes of temporal and spectral parameters,
S. Leeet al., “Acoustics of children’s speech: Developmental changes of temporal and spectral parameters,”The Journal of the Acoustical Society of America, vol. 105, no. 3, pp. 1455–1468, 1999
1999
-
[41]
Categorical reparameterization with gumbel-softmax,
E. Jang, S. Gu, and B. Poole, “Categorical reparameterization with gumbel-softmax,” inICLR, 2017
2017
-
[42]
My science tutor: A conversational multimedia virtual tutor for elementary school science,
W. Wardet al., “My science tutor: A conversational multimedia virtual tutor for elementary school science,”ACM Transactions on Speech and Language Processing (TSLP), vol. 7, no. 4, pp. 1–29, 2011
2011
-
[43]
The OGI kids 2 speech corpus and recognizers,
K. Shobaki, J. Hosom, and R. A. Cole, “The OGI kids 2 speech corpus and recognizers,” inINTERSPEECH, 2000
2000
-
[44]
The Corpus of Regional African American Language,
T. Kendall and C. Farrington, “The Corpus of Regional African American Language,” 2023. [Online]. Available: https: //doi.org/10.7264/1ad5-6t35
-
[45]
Self-supervised learning with random- projection quantizer for speech recognition,
C.-C. Chiuet al., “Self-supervised learning with random- projection quantizer for speech recognition,” inICML, 2022
2022
-
[46]
Exploring prediction targets in masked pre- training for speech foundation models,
L. Chenet al., “Exploring prediction targets in masked pre- training for speech foundation models,” inICASSP, 2025
2025
-
[47]
Estimating or prop- agating gradients through stochastic neurons for conditional com- putation,
Y . Bengio, N. L´eonard, and A. C. Courville, “Estimating or prop- agating gradients through stochastic neurons for conditional com- putation,”CoRR, vol. abs/1308.3432, 2013
Pith/arXiv arXiv 2013
-
[48]
Kid-whisper: Towards bridging the performance gap in automatic speech recognition for children vs. adults,
A. Attiaet al., “Kid-whisper: Towards bridging the performance gap in automatic speech recognition for children vs. adults,” in Proc. AAAI/ACM Conference on AI, Ethics, and Society, 2024
2024
-
[49]
Benchmarking Training Paradigms, Dataset Com- position, and Model Scaling for Child ASR in ESPnet,
A. Yinget al., “Benchmarking Training Paradigms, Dataset Com- position, and Model Scaling for Child ASR in ESPnet,” inWork- shop on Child Computer Interaction - WOCCI, 2025
2025
-
[50]
SCTK: The NIST Scoring Toolkit,
J. Fiscus, “SCTK: The NIST Scoring Toolkit,” National Institute of Standards and Technology, 2007, [Software]
2007
-
[51]
Comparative layer-wise analysis of self- supervised speech models,
A. Pasadet al., “Comparative layer-wise analysis of self- supervised speech models,” inICASSP, 2023
2023
-
[52]
Relations between two sets of variates,
H. Hotelling, “Relations between two sets of variates,” inBreak- throughs in Statistics: Methodology and Distribution. Springer, 1992, pp. 162–190
1992
-
[53]
Insights on representational similarity in neural networks with canonical correlation,
A. Morcoset al., “Insights on representational similarity in neural networks with canonical correlation,”Advances in Neural Infor- mation Processing Systems, vol. 31, 2018
2018
-
[54]
Fast conformer with linearly scalable attention for efficient speech recognition,
D. Rekeshet al., “Fast conformer with linearly scalable attention for efficient speech recognition,” inASRU, 2023
2023
-
[55]
Canary-Qwen-2.5B,
NVIDIA, “Canary-Qwen-2.5B,” https://huggingface.co/nvidia/ canary-qwen-2.5b, 2025, hugging Face model
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.