Steering Multirobot Behavior via Closed-Loop Affine Activation Editing
Pith reviewed 2026-06-27 12:40 UTC · model grok-4.3
The pith
Closed-loop affine edits to selected policy activations steer frozen multirobot navigation without retraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
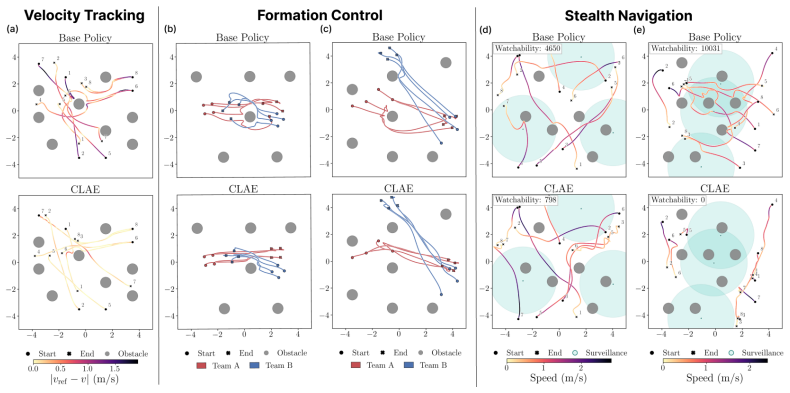
CLAE steers multirobot behavior by applying state-dependent affine edits to selected latent features of a frozen policy's activations, identified via sparse autoencoders and post-hoc probing, while the base policy and action head remain unchanged. This closed-loop editing adapts to robot state, environment, target behavior, and multi-robot context, enabling control over velocity profiles, formation preservation, and novel objectives such as reducing surveillance camera exposure.
What carries the argument
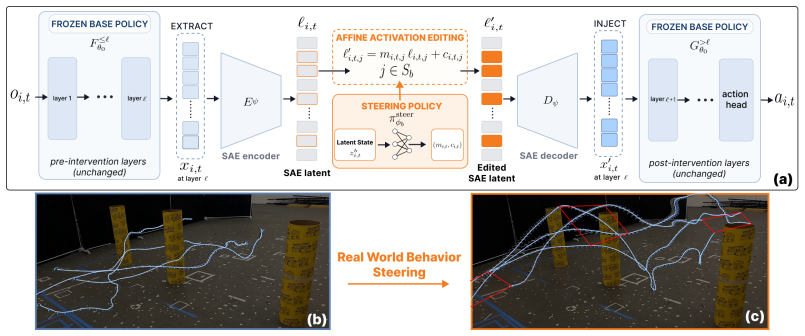
Closed-Loop Affine Activation Editing (CLAE), which trains a sparse autoencoder on frozen-policy activations, selects controllable latents via probing, and learns an RL-based steering policy to apply affine edits to those latents during inference.
If this is right
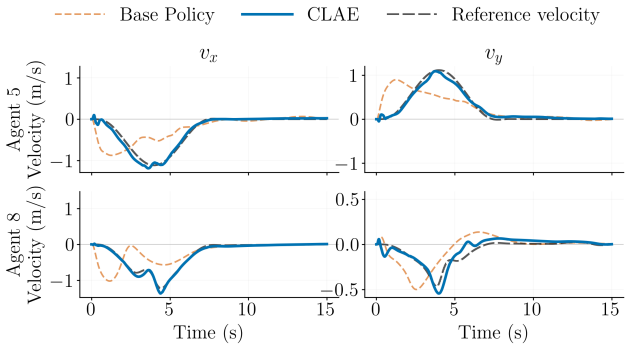
- Individual robots can have their velocity profiles adjusted independently while the group continues navigation.
- Desired multirobot formations can be preserved through coordinated activation edits.
- New behaviors such as minimizing exposure to surveillance cameras can be added on top of the original navigation task.
- The base policy performance is preserved because its weights and action head are never modified.
Where Pith is reading between the lines
- The same activation-editing approach could be applied to other frozen policies beyond navigation, such as those for manipulation or exploration.
- Because the steering policy is lightweight and closed-loop, multiple target behaviors might be combined by running several steering policies in parallel.
- Physical robot tests indicate that the method can handle real sensor noise and dynamics without requiring policy retraining.
Load-bearing premise
Post-hoc probing identifies latent features that stay stable and controllable across the closed-loop steering policy without destabilizing the frozen base policy or creating unintended side effects.
What would settle it
A direct comparison showing that robots using CLAE edits fail to reach goals or avoid obstacles at rates comparable to the original frozen policy in the same physical or simulated environments.
Figures
read the original abstract
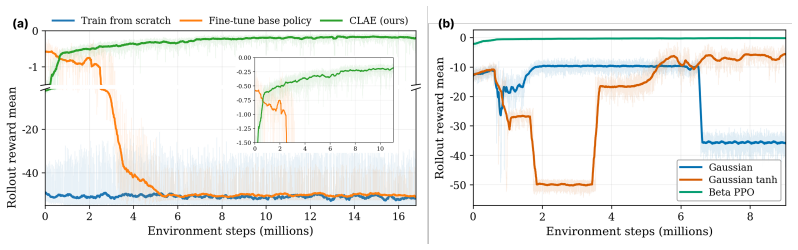
Real-world robots need to adapt their behavior beyond the envelope of their pre-trained policy. Policy finetuning or retraining are options, but they risk catastrophic forgetting, degrading the pretrained policy's base performance. To combat this, we introduce CLAE: Closed-Loop Affine Activation Editing, an inference-time framework for steering the behavior of a frozen policy by editing intermediate activations while keeping the base policy weights and downstream action head untouched. CLAE approaches behavior steering as a closed-loop problem whose outputs edit policy activations that adapt online to the robot state, environment, target behavior, and multi-robot context. It trains a sparse autoencoder over frozen-policy activations, selects behavior-relevant latent features via post-hoc probing, and learns a lightweight RL-based steering policy that applies state-dependent affine edits to selected latents during inference. We validate CLAE on a frozen multi-quadrotor navigation policy trained to perform a single task: navigating robots to a set of goal locations while avoiding obstacles. Through extensive simulations and physical tests, we show that while navigating to their goal positions, CLAE can 1. steer individual robot behavior by controlling each robot's velocity profile; 2. coordinate multirobot behavior by preserving a desired formation; and 3. produce entirely new behavior wherein robots are required to reduce their exposure to surveillance cameras in the environment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CLAE, a closed-loop inference-time framework for steering behaviors of a frozen multi-quadrotor navigation policy. It trains a sparse autoencoder on frozen activations, uses post-hoc probing to select behavior-relevant latents, and learns an RL steering policy that applies state-dependent affine edits to those latents. The central claims are that this enables (1) controlling individual robot velocity profiles, (2) preserving multirobot formations, and (3) producing new behaviors such as reducing camera exposure, all while the base policy continues navigating to goals and avoiding obstacles, as shown in simulations and physical tests.
Significance. If the controllability and isolation claims hold with quantitative support, CLAE would provide a practical route to behavior adaptation that avoids catastrophic forgetting of pretrained policies, which is valuable in robotics. The combination of SAE + probing + closed-loop RL steering, applied to multirobot settings, is a clear technical contribution over open-loop activation editing methods.
major comments (2)
- [Abstract and §4 (validation)] The central claim that post-hoc probing yields latents that remain independently controllable under the RL steering policy's state-dependent affine edits (without coupling through the frozen policy or multirobot dynamics) is load-bearing for all three behaviors. No section provides evidence such as orthogonality metrics on the probed directions, intervention tests showing isolated effects on velocity vs. formation vs. exposure, or ablation of the probing step; without these, the closed-loop edits could induce unintended collisions or formation drift that the base policy cannot correct.
- [§5] §5 (physical experiments): the claim of successful new behavior (camera exposure reduction) while preserving navigation requires reporting of quantitative metrics (e.g., exposure reduction percentage, collision rate, formation error) with and without CLAE, plus comparison to baselines; the abstract's reference to 'extensive simulations and physical tests' does not substitute for these numbers.
minor comments (2)
- [§3] Notation for the affine edit (e.g., the precise form of the state-dependent transform applied to SAE latents) should be defined with an equation in the methods section for reproducibility.
- [Figures 4-7] Figure captions for simulation and hardware results should include error bars or statistical significance when comparing steered vs. base-policy trajectories.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address the major comments point-by-point below and will make the requested revisions to provide stronger quantitative support for the claims.
read point-by-point responses
-
Referee: [Abstract and §4 (validation)] The central claim that post-hoc probing yields latents that remain independently controllable under the RL steering policy's state-dependent affine edits (without coupling through the frozen policy or multirobot dynamics) is load-bearing for all three behaviors. No section provides evidence such as orthogonality metrics on the probed directions, intervention tests showing isolated effects on velocity vs. formation vs. exposure, or ablation of the probing step; without these, the closed-loop edits could induce unintended collisions or formation drift that the base policy cannot correct.
Authors: We agree that explicit evidence of latent independence under closed-loop editing is important. While §4 shows that the RL steering policy achieves the three target behaviors concurrently with preserved navigation and obstacle avoidance (with no observed formation drift or excess collisions in the reported trials), we acknowledge the absence of orthogonality metrics, isolated intervention tests, and probing ablations. In revision we will add these: pairwise cosine similarities among probed directions, single-latent intervention results, and an ablation removing the probing step. revision: yes
-
Referee: [§5] §5 (physical experiments): the claim of successful new behavior (camera exposure reduction) while preserving navigation requires reporting of quantitative metrics (e.g., exposure reduction percentage, collision rate, formation error) with and without CLAE, plus comparison to baselines; the abstract's reference to 'extensive simulations and physical tests' does not substitute for these numbers.
Authors: We agree that the physical-experiments section requires quantitative metrics. The current text reports qualitative success; we will expand §5 with tables containing exposure-reduction percentages, collision rates, formation errors (with/without CLAE), and comparisons against the base policy and at least one additional baseline. revision: yes
Circularity Check
No circularity: method components trained independently on frozen policy.
full rationale
The paper presents CLAE as a composite framework with distinct stages (SAE training on frozen activations, post-hoc probing for latents, separate RL steering policy for affine edits) whose outputs are validated empirically on navigation tasks. No equations, fitted parameters, or self-citations are described that reduce a claimed prediction or uniqueness result to the inputs by construction. The abstract and method outline treat each module as separately trained and externally testable, satisfying the criteria for a self-contained non-circular presentation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
S. Liu, I. S. Singh, Y . Xu, J. Duan, and R. Krishna. Vls: Steering pretrained robot policies via vision–language models, 2026
2026
-
[2]
Nakamoto, O
M. Nakamoto, O. Mees, A. Kumar, and S. Levine. Steering your generalists: Improving robotic foundation models via value guidance, 2024
2024
-
[3]
Y . Wang, L. Wang, Y . Du, B. Sundaralingam, X. Yang, Y .-W. Chao, C. Perez-D’Arpino, D. Fox, and J. Shah. Inference-time policy steering through human interactions, 2024
2024
-
[4]
Wagenmaker, Y
A. Wagenmaker, Y . Zhang, M. Nakamoto, S. Park, W. Yagoub, A. Nagabandi, A. Gupta, and S. Levine. Steering your diffusion policy with latent space reinforcement learning, 2025
2025
-
[5]
Y . Wu, R. Tian, G. Swamy, and A. Bajcsy. From foresight to forethought: Vlm-in-the-loop policy steering via latent alignment, 2025
2025
-
[6]
W. Chen, J. S. Bhatia, C. Glossop, N. Mathihalli, R. Doshi, A. Tang, D. Driess, K. Pertsch, and S. Levine. Steerable vision-language-action policies for embodied reasoning and hierarchical control, 2026
2026
-
[7]
A. M. Turner, L. Thiergart, G. Leech, D. Udell, J. J. Vazquez, U. Mini, and M. MacDiarmid. Steering language models with activation engineering, 2023
2023
-
[8]
A. Zou, L. Phan, S. Chen, J. Campbell, P. Guo, R. Ren, A. Pan, X. Yin, M. Mazeika, et al. Representation engineering: A top-down approach to ai transparency, 2023
2023
-
[9]
Cunningham, A
H. Cunningham, A. Ewart, L. Riggs, R. Huben, and L. Sharkey. Sparse autoencoders find highly interpretable features in language models, 2023
2023
-
[10]
Templeton.Scaling monosemanticity: Extracting interpretable features from claude 3 son- net
A. Templeton.Scaling monosemanticity: Extracting interpretable features from claude 3 son- net. Anthropic, 2024
2024
-
[11]
H ¨aon, K
B. H ¨aon, K. Stocking, I. Chuang, and C. Tomlin. Mechanistic interpretability for steering vision-language-action models, 2025
2025
-
[12]
Swann, L
A. Swann, L. McGranahan, H. Buurmeijer, M. Kennedy, and M. Schwager. Sparse autoen- coders reveal interpretable and steerable features in vla models, 2026
2026
-
[13]
S. Das, D. Chiu, Z. Huang, L. Lindemann, and G. S. Sukhatme. Latent activation editing: Inference-time refinement of learned policies for safer multirobot navigation, 2025
2025
-
[14]
Singh, S
S. Singh, S. Ravfogel, J. Herzig, R. Aharoni, R. Cotterell, and P. Kumaraguru. Representation surgery: Theory and practice of affine steering, 2024
2024
-
[15]
H. Buurmeijer, C. A. Alonso, A. Swann, and M. Pavone. Observing and controlling features in vision-language-action models.arXiv preprint arXiv:2603.05487, 2026
arXiv 2026
-
[16]
Bricken, A
T. Bricken, A. Templeton, J. Batson, B. Chen, A. Jermyn, T. Conerly, N. Turner, C. Anil, C. Denison, A. Askell, R. Lasenby, Y . Wu, S. Kravec, N. Schiefer, T. Maxwell, N. Joseph, Z. Hatfield-Dodds, A. Tamkin, K. Nguyen, B. McLean, J. E. Burke, T. Hume, S. Carter, C. Olah, and T. Henighan. Towards monosemanticity: Decomposing language mod- els with diction...
2023
-
[17]
Alain and Y
G. Alain and Y . Bengio. Understanding intermediate layers using linear classifier probes, 2016
2016
-
[18]
B. Kim, M. Wattenberg, J. Gilmer, C. Cai, J. Wexler, F. Vi´egas, and R. Sayres. Interpretability beyond feature attribution: Quantitative testing with concept activation vectors (TCA V). In Proceedings of the 35th International Conference on Machine Learning, volume 80 ofPro- ceedings of Machine Learning Research, pages 2668–2677. PMLR, 2018
2018
-
[19]
Computational Linguistics48(4), 1125–1135 (2022) https://doi.org/10.1162/coli a 00448
Y . Belinkov. Probing classifiers: Promises, shortcomings, and advances.Computational Lin- guistics, 48(1):207–219, 2022. doi:10.1162/coli a 00422
-
[20]
I. G. Petrazzini and E. A. Antonelo. Proximal policy optimization with continuous bounded action space via the beta distribution. In2021 IEEE symposium series on computational intel- ligence (SSCI), pages 1–8. IEEE, 2021
2021
- [21]
-
[22]
Huang, Z
Z. Huang, Z. Yang, R. Krupani, B. S ¸enbas ¸lar, S. Batra, and G. S. Sukhatme. Collision avoid- ance and navigation for a quadrotor swarm using end-to-end deep reinforcement learning. In IEEE Int. Conf. Robot. Autom. (ICRA), 2024
2024
-
[23]
Mellinger and V
D. Mellinger and V . Kumar. Minimum snap trajectory generation and control for quadrotors. In2011 IEEE international conference on robotics and automation, pages 2520–2525. Ieee, 2011
2011
-
[24]
L. Wang, A. Ames, and M. Egerstedt. Safety barrier certificates for heterogeneous multi-robot systems. InAmer. cont. conf. (ACC), 2016. 10 A Steering Policy Details This appendix summarizes the steering-policy observations, edit constraints, and task rewards used in our experiments. Across all tasks, the base policyπθ0, the SAE encoderE ψ, and the SAE dec...
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.