VL-DINO: Leveraging CLIP Vision-Language Knowledge for Open-Vocabulary Object Detectio
Pith reviewed 2026-06-27 10:59 UTC · model grok-4.3
The pith
VL-DINO adds three modules to DINO to exploit CLIP knowledge and reach 38.1 AP zero-shot on LVIS.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
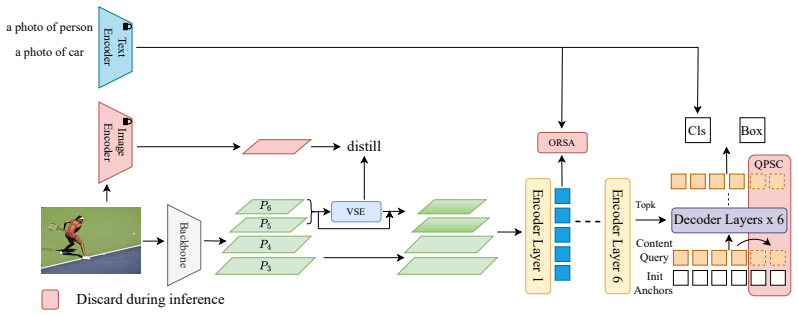
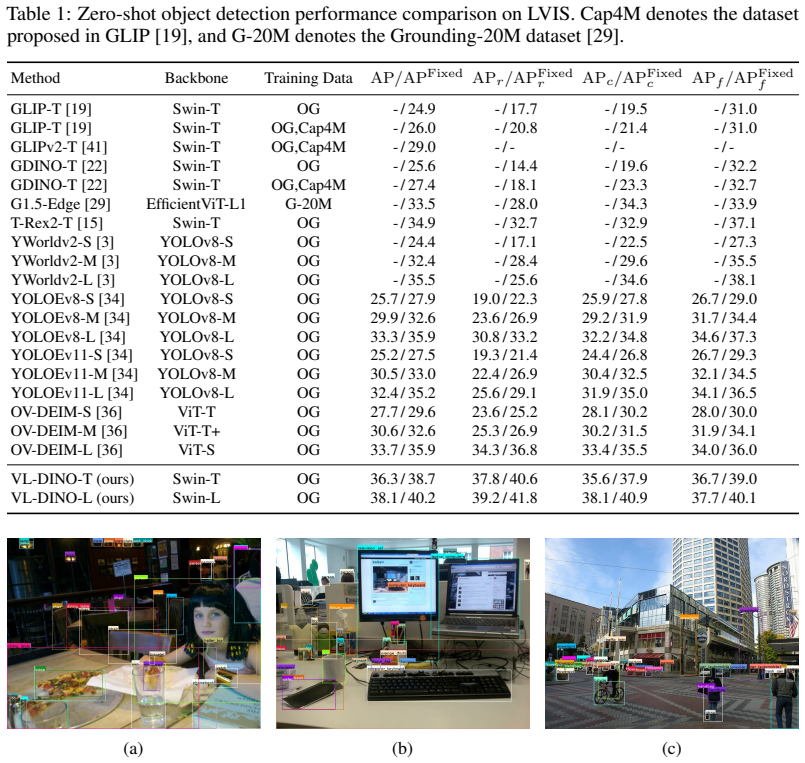
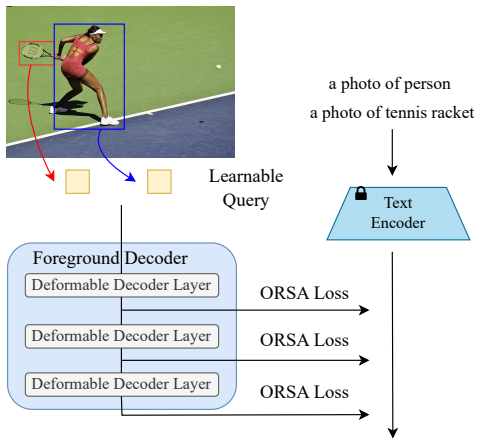
The central claim is that by constructing additional positive samples with QPSC, distilling visual knowledge via VSE, and performing object-region semantic alignment with ORSA, VL-DINO incorporates richer textual and visual cues from CLIP into DINO, enabling it to outperform previous open-vocabulary detectors in the zero-shot setting on LVIS with AP scores of 36.3 and 38.1 for the two model sizes.
What carries the argument
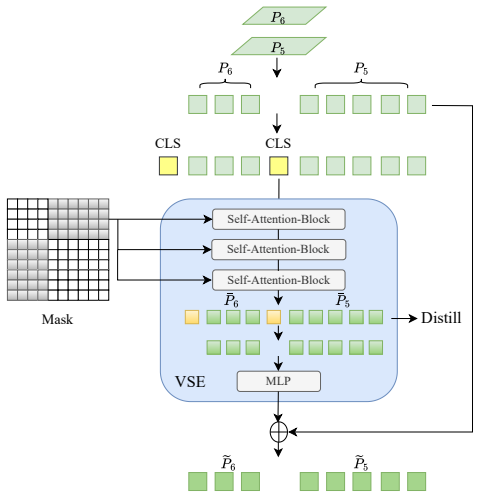
The QPSC, VSE, and ORSA modules that facilitate integration of CLIP knowledge by improving sample construction, feature fusion, and region-text alignment.
If this is right
- Training on mixed heterogeneous data sources becomes feasible with more high-quality positives and alignment signals.
- Backbone features are enriched with CLIP visual semantics for better refinement.
- Object-centric features align directly with textual embeddings to capture semantic cues.
- Zero-shot detection performance on benchmarks like LVIS improves consistently over prior approaches.
Where Pith is reading between the lines
- Similar module additions might improve other transformer-based detectors if they share DINO's structure.
- Applications in dynamic environments could see gains in recognizing novel objects via language prompts.
- Further experiments could test whether the gains hold when using different CLIP variants or larger backbones.
Load-bearing premise
The proposed modules integrate smoothly with DINO training and do not create biases when combining data from different sources.
What would settle it
Running an ablation that removes the VSE module and finds the zero-shot LVIS AP falls to or below levels of previous methods would indicate the visual distillation is not the key driver.
Figures
read the original abstract
Vision-language models like CLIP can provide rich semantic priors for open-vocabulary object detection. However, jointly integrating both textual and visual knowledge into detection architectures remains challenging. In this paper, we propose VL-DINO, an open-vocabulary detector that enhances DINO through more effective exploitation of CLIP's vision-language knowledge. Specifically, a Query-guided Positive Sample Construction (QPSC) module is first developed to construct additional high-quality positive samples, enabling the vanilla DINO framework to better accommodate mixed training across heterogeneous data sources while providing more vision-language alignment signals, thereby incorporating richer textual knowledge during training. A Visual Semantic Encoder (VSE) module is then introduced to distill CLIP visual knowledge into backbone-extracted features, producing fused features for subsequent encoder refinement. Based on the fused features, an Object-Region Semantic Alignment (ORSA) module extracts object-centric region features and aligns them with the corresponding textual embeddings, further incorporating textual cues. In the zero-shot setting, VL-DINO-T and VL-DINO-L achieve 36.3 and 38.1 AP on the LVIS benchmark, respectively, consistently outperforming prior advanced approaches. Extensive experiments demonstrate the effectiveness and competitive performance of the proposed design.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes VL-DINO, an extension of the DINO detector for open-vocabulary object detection that incorporates CLIP vision-language knowledge via three modules: Query-guided Positive Sample Construction (QPSC) to generate additional positives for mixed heterogeneous training and alignment signals, Visual Semantic Encoder (VSE) to distill CLIP visual features into the backbone, and Object-Region Semantic Alignment (ORSA) to align object-centric regions with text embeddings. In zero-shot evaluation, VL-DINO-T and VL-DINO-L report 36.3 AP and 38.1 AP respectively on LVIS, outperforming prior methods; extensive experiments are claimed to validate the design.
Significance. If the empirical gains hold under controlled ablations and fair comparisons, the work would provide a concrete, modular recipe for fusing CLIP priors into query-based detectors, addressing the challenge of joint textual-visual integration. The reported LVIS numbers would indicate a measurable advance in zero-shot open-vocabulary detection, with potential for adoption in other architectures that mix detection and vision-language data.
major comments (2)
- [§3.2] §3.2 (QPSC module): the description of query-guided positive sample construction is high-level and does not specify the exact similarity threshold, sampling ratio, or modified matching loss; without these, it is impossible to verify whether the module indeed stabilizes mixed-data training or merely increases positive count by construction.
- [§4] §4 (experiments): no ablation table isolates the contribution of VSE versus ORSA to the final AP, nor reports training stability metrics (e.g., loss curves or gradient norms) when the three modules are added; this is load-bearing for the central claim that the modules can be jointly integrated without introducing systematic biases.
minor comments (1)
- [Abstract] The abstract and method overview use module acronyms (QPSC, VSE, ORSA) before they are defined; a brief parenthetical expansion on first use would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and detailed comments. We address each major comment below and will revise the manuscript to improve clarity and completeness.
read point-by-point responses
-
Referee: [§3.2] §3.2 (QPSC module): the description of query-guided positive sample construction is high-level and does not specify the exact similarity threshold, sampling ratio, or modified matching loss; without these, it is impossible to verify whether the module indeed stabilizes mixed-data training or merely increases positive count by construction.
Authors: We agree that the current description in §3.2 remains at a high level and lacks the precise hyperparameters and loss formulation needed for full reproducibility. In the revised manuscript we will expand this section to explicitly state the similarity threshold, sampling ratio, and the exact form of the modified matching loss (including any added alignment term), allowing readers to verify the module's contribution to training stability versus positive count. revision: yes
-
Referee: [§4] §4 (experiments): no ablation table isolates the contribution of VSE versus ORSA to the final AP, nor reports training stability metrics (e.g., loss curves or gradient norms) when the three modules are added; this is load-bearing for the central claim that the modules can be jointly integrated without introducing systematic biases.
Authors: We acknowledge that the experiments section does not contain an ablation isolating VSE from ORSA nor any training stability metrics. We will add a dedicated ablation table showing the incremental effect of each module on LVIS AP and include loss curves together with gradient-norm statistics in the supplementary material to substantiate that the three modules integrate without introducing systematic biases. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper proposes three architectural modules (QPSC, VSE, ORSA) added to DINO for incorporating CLIP knowledge and validates them via empirical zero-shot AP scores on the public LVIS benchmark. No equations, fitted parameters, or derivations are described that reduce by construction to the inputs themselves, nor are load-bearing claims supported solely by self-citations. The central results follow from standard training and evaluation on external data rather than internal self-definition or renaming of known quantities.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
End-to-end object detection with transformers
Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to-end object detection with transformers. InEuropean conference on computer vision, pages 213–229. Springer, 2020
2020
-
[2]
Group detr: Fast detr training with group-wise one-to-many assignment
Qiang Chen, Xiaokang Chen, Jian Wang, Shan Zhang, Kun Yao, Haocheng Feng, Junyu Han, Errui Ding, Gang Zeng, and Jingdong Wang. Group detr: Fast detr training with group-wise one-to-many assignment. InProceedings of the IEEE/CVF international conference on computer vision, pages 6633–6642, 2023
2023
-
[3]
Yolo-world: Real- time open-vocabulary object detection
Tianheng Cheng, Lin Song, Yixiao Ge, Wenyu Liu, Xinggang Wang, and Ying Shan. Yolo-world: Real- time open-vocabulary object detection. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16901–16911, 2024
2024
-
[4]
Achal Dave, Piotr Dollár, Deva Ramanan, Alexander Kirillov, and Ross Girshick. Evaluating large- vocabulary object detectors: The devil is in the details.arXiv preprint arXiv:2102.01066, 2021
-
[5]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[6]
Learning to prompt for open- vocabulary object detection with vision-language model
Yu Du, Fangyun Wei, Zihe Zhang, Miaojing Shi, Yue Gao, and Guoqi Li. Learning to prompt for open- vocabulary object detection with vision-language model. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 14084–14093, 2022
2022
-
[7]
Fast r-cnn
Ross Girshick. Fast r-cnn. InProceedings of the IEEE international conference on computer vision, pages 1440–1448, 2015
2015
-
[8]
Open-vocabulary Object Detection via Vision and Language Knowledge Distillation
Xiuye Gu, Tsung-Yi Lin, Weicheng Kuo, and Yin Cui. Open-vocabulary object detection via vision and language knowledge distillation.arXiv preprint arXiv:2104.13921, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[9]
Lvis: A dataset for large vocabulary instance segmentation
Agrim Gupta, Piotr Dollar, and Ross Girshick. Lvis: A dataset for large vocabulary instance segmentation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5356–5364, 2019
2019
-
[10]
Pay attention to your neighbours: Training-free open- vocabulary semantic segmentation
Sina Hajimiri, Ismail Ben Ayed, and Jose Dolz. Pay attention to your neighbours: Training-free open- vocabulary semantic segmentation. InProceedings of the Winter Conference on Applications of Computer Vision, pages 5061–5071, 2025
2025
-
[11]
Deim: Detr with improved matching for fast convergence
Shihua Huang, Zhichao Lu, Xiaodong Cun, Yongjun Yu, Xiao Zhou, and Xi Shen. Deim: Detr with improved matching for fast convergence. InProceedings of the computer vision and pattern recognition conference, pages 15162–15171, 2025
2025
-
[12]
Gqa: A new dataset for real-world visual reasoning and compositional question answering
Drew A Hudson and Christopher D Manning. Gqa: A new dataset for real-world visual reasoning and compositional question answering. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6700–6709, 2019
2019
-
[13]
Scaling up visual and vision-language representation learning with noisy text supervision
Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc Le, Yun-Hsuan Sung, Zhen Li, and Tom Duerig. Scaling up visual and vision-language representation learning with noisy text supervision. InInternational conference on machine learning, pages 4904–4916. PMLR, 2021
2021
-
[14]
Detrs with hybrid matching
Ding Jia, Yuhui Yuan, Haodi He, Xiaopei Wu, Haojun Yu, Weihong Lin, Lei Sun, Chao Zhang, and Han Hu. Detrs with hybrid matching. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 19702–19712, 2023. 10
2023
-
[15]
T-rex2: Towards generic object detection via text-visual prompt synergy
Qing Jiang, Feng Li, Zhaoyang Zeng, Tianhe Ren, Shilong Liu, and Lei Zhang. T-rex2: Towards generic object detection via text-visual prompt synergy. InEuropean Conference on Computer Vision, pages 38–57. Springer, 2024
2024
-
[16]
Mdetr-modulated detection for end-to-end multi-modal understanding
Aishwarya Kamath, Mannat Singh, Yann LeCun, Gabriel Synnaeve, Ishan Misra, and Nicolas Carion. Mdetr-modulated detection for end-to-end multi-modal understanding. InProceedings of the IEEE/CVF international conference on computer vision, pages 1780–1790, 2021
2021
-
[17]
Clearclip: Decomposing clip representations for dense vision-language inference
Mengcheng Lan, Chaofeng Chen, Yiping Ke, Xinjiang Wang, Litong Feng, and Wayne Zhang. Clearclip: Decomposing clip representations for dense vision-language inference. InEuropean Conference on Computer Vision, pages 143–160. Springer, 2024
2024
-
[18]
Dn-detr: Accelerate detr training by introducing query denoising
Feng Li, Hao Zhang, Shilong Liu, Jian Guo, Lionel M Ni, and Lei Zhang. Dn-detr: Accelerate detr training by introducing query denoising. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 13619–13627, 2022
2022
-
[19]
Grounded language-image pre-training
Liunian Harold Li, Pengchuan Zhang, Haotian Zhang, Jianwei Yang, Chunyuan Li, Yiwu Zhong, Lijuan Wang, Lu Yuan, Lei Zhang, Jenq-Neng Hwang, et al. Grounded language-image pre-training. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10965–10975, 2022
2022
-
[20]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. InEuropean conference on computer vision, pages 740–755. Springer, 2014
2014
-
[21]
Focal loss for dense object detection
Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Dollár. Focal loss for dense object detection. InProceedings of the IEEE international conference on computer vision, pages 2980–2988, 2017
2017
-
[22]
Grounding dino: Marrying dino with grounded pre-training for open-set object detection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. InEuropean conference on computer vision, pages 38–55. Springer, 2024
2024
-
[23]
Swin transformer: Hierarchical vision transformer using shifted windows
Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. InProceedings of the IEEE/CVF international conference on computer vision, pages 10012–10022, 2021
2021
-
[24]
Representation Learning with Contrastive Predictive Coding
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predictive coding.arXiv preprint arXiv:1807.03748, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[25]
Flickr30k entities: Collecting region-to-phrase correspondences for richer image-to-sentence models
Bryan A Plummer, Liwei Wang, Chris M Cervantes, Juan C Caicedo, Julia Hockenmaier, and Svetlana Lazebnik. Flickr30k entities: Collecting region-to-phrase correspondences for richer image-to-sentence models. InProceedings of the IEEE international conference on computer vision, pages 2641–2649, 2015
2015
-
[26]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
2021
-
[27]
You only look once: Unified, real-time object detection
Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali Farhadi. You only look once: Unified, real-time object detection. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 779–788, 2016
2016
-
[28]
Tianhe Ren, Yihao Chen, Qing Jiang, Zhaoyang Zeng, Yuda Xiong, Wenlong Liu, Zhengyu Ma, Junyi Shen, Yuan Gao, Xiaoke Jiang, et al. Dino-x: A unified vision model for open-world object detection and understanding.arXiv preprint arXiv:2411.14347, 2024
-
[29]
Grounding dino 1.5: Advance the
Tianhe Ren, Qing Jiang, Shilong Liu, Zhaoyang Zeng, Wenlong Liu, Han Gao, Hongjie Huang, Zhengyu Ma, Xiaoke Jiang, Yihao Chen, et al. Grounding dino 1.5: Advance the" edge" of open-set object detection. arXiv preprint arXiv:2405.10300, 2024
-
[30]
Objects365: A large-scale, high-quality dataset for object detection
Shuai Shao, Zeming Li, Tianyuan Zhang, Chao Peng, Gang Yu, Xiangyu Zhang, Jing Li, and Jian Sun. Objects365: A large-scale, high-quality dataset for object detection. InProceedings of the IEEE/CVF international conference on computer vision, pages 8430–8439, 2019
2019
-
[31]
Oriane Siméoni, Huy V V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Michaël Ramamonjisoa, et al. Dinov3.arXiv preprint arXiv:2508.10104, 2025. 11
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Fcos: Fully convolutional one-stage object detection
Zhi Tian, Chunhua Shen, Hao Chen, and Tong He. Fcos: Fully convolutional one-stage object detection. InProceedings of the IEEE/CVF international conference on computer vision, pages 9627–9636, 2019
2019
-
[33]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
2017
-
[34]
Yoloe: Real-time seeing anything
Ao Wang, Lihao Liu, Hui Chen, Zijia Lin, Jungong Han, and Guiguang Ding. Yoloe: Real-time seeing anything. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 24591– 24602, 2025
2025
-
[35]
Sclip: Rethinking self-attention for dense vision-language inference
Feng Wang, Jieru Mei, and Alan Yuille. Sclip: Rethinking self-attention for dense vision-language inference. InEuropean conference on computer vision, pages 315–332. Springer, 2024
2024
-
[36]
Leilei Wang, Longfei Liu, Xi Shen, Xuanlong Yu, Ying Tiffany He, Fei Richard Yu, and Yingyi Chen. Ov-deim: Real-time detr-style open-vocabulary object detection with gridsynthetic augmentation.arXiv preprint arXiv:2603.07022, 2026
-
[37]
Object-aware distillation pyramid for open-vocabulary object detection
Luting Wang, Yi Liu, Penghui Du, Zihan Ding, Yue Liao, Qiaosong Qi, Biaolong Chen, and Si Liu. Object-aware distillation pyramid for open-vocabulary object detection. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11186–11196, 2023
2023
-
[38]
Aligning bag of regions for open-vocabulary object detection
Size Wu, Wenwei Zhang, Sheng Jin, Wentao Liu, and Chen Change Loy. Aligning bag of regions for open-vocabulary object detection. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 15254–15264, 2023
2023
-
[39]
Detclip: Dictionary-enriched visual-concept paralleled pre-training for open-world detection.Advances in Neural Information Processing Systems, 35:9125–9138, 2022
Lewei Yao, Jianhua Han, Youpeng Wen, Xiaodan Liang, Dan Xu, Wei Zhang, Zhenguo Li, Chunjing Xu, and Hang Xu. Detclip: Dictionary-enriched visual-concept paralleled pre-training for open-world detection.Advances in Neural Information Processing Systems, 35:9125–9138, 2022
2022
-
[40]
DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection
Hao Zhang, Feng Li, Shilong Liu, Lei Zhang, Hang Su, Jun Zhu, Lionel M Ni, and Heung-Yeung Shum. Dino: Detr with improved denoising anchor boxes for end-to-end object detection.arXiv preprint arXiv:2203.03605, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[41]
Glipv2: Unifying localization and vision-language understanding.Advances in Neural Information Processing Systems, 35:36067–36080, 2022
Haotian Zhang, Pengchuan Zhang, Xiaowei Hu, Yen-Chun Chen, Liunian Li, Xiyang Dai, Lijuan Wang, Lu Yuan, Jenq-Neng Hwang, and Jianfeng Gao. Glipv2: Unifying localization and vision-language understanding.Advances in Neural Information Processing Systems, 35:36067–36080, 2022
2022
-
[42]
Regionclip: Region-based language-image pretraining
Yiwu Zhong, Jianwei Yang, Pengchuan Zhang, Chunyuan Li, Noel Codella, Liunian Harold Li, Luowei Zhou, Xiyang Dai, Lu Yuan, Yin Li, et al. Regionclip: Region-based language-image pretraining. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16793–16803, 2022
2022
-
[43]
Extract free dense labels from clip
Chong Zhou, Chen Change Loy, and Bo Dai. Extract free dense labels from clip. InEuropean conference on computer vision, pages 696–712. Springer, 2022
2022
-
[44]
Detecting twenty- thousand classes using image-level supervision
Xingyi Zhou, Rohit Girdhar, Armand Joulin, Philipp Krähenbühl, and Ishan Misra. Detecting twenty- thousand classes using image-level supervision. InEuropean conference on computer vision, pages 350–368. Springer, 2022
2022
-
[45]
Deformable DETR: Deformable Transformers for End-to-End Object Detection
Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, and Jifeng Dai. Deformable detr: Deformable transformers for end-to-end object detection.arXiv preprint arXiv:2010.04159, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[46]
Limitations
Zhuofan Zong, Guanglu Song, and Yu Liu. Detrs with collaborative hybrid assignments training. In Proceedings of the IEEE/CVF international conference on computer vision, pages 6748–6758, 2023. 12 A Technical appendices and supplementary material A.1 Mode implementation details VL-DINO is trained on eight NVIDIA L40 GPUs. The total batch sizes for VL-DINO-...
2023
-
[47]
Guidelines: • The answer [N/A] means that the paper does not involve crowdsourcing nor research with human subjects
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.