FreqKD: Frequency-Decoupled Cross-Modal Knowledge Distillation for Infrared Object Detection
Pith reviewed 2026-06-27 10:51 UTC · model grok-4.3
The pith
Frequency-decoupled distillation improves RGB-to-IR object detection by aligning shared structure while tolerating texture differences.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
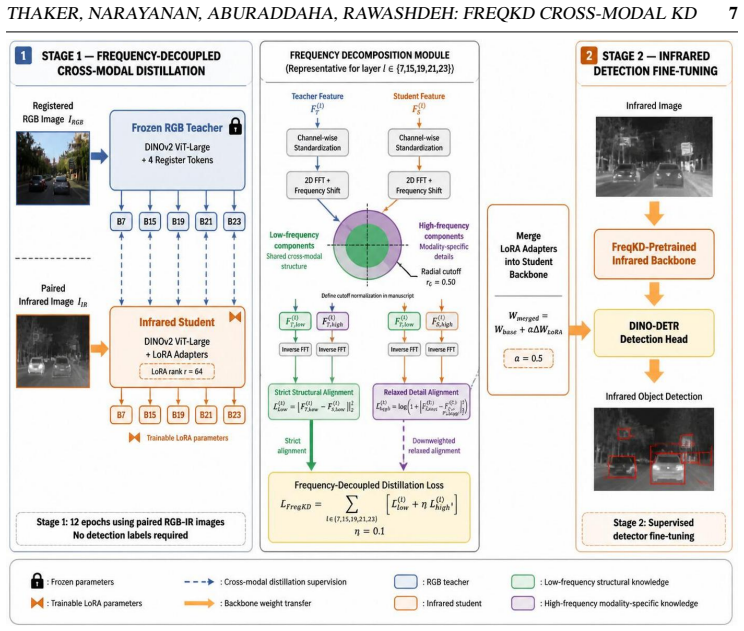
Spectral analysis of 500 paired RGB-IR samples reveals that high-frequency feature divergence exceeds low-frequency divergence by a factor of 2.4 on average across transformer layers. FreqKD exploits this by enforcing strict mean-squared error alignment on low-frequency components to preserve shared structural information and applying a 0.1-weighted log-MSE loss on high-frequency components to supply edge guidance without forcing alignment of modality-specific texture.
What carries the argument
Frequency-decoupled distillation that splits features into low- and high-frequency bands and applies asymmetric losses (strict MSE on low, relaxed weighted log-MSE on high) according to measured cross-modal consistency.
If this is right
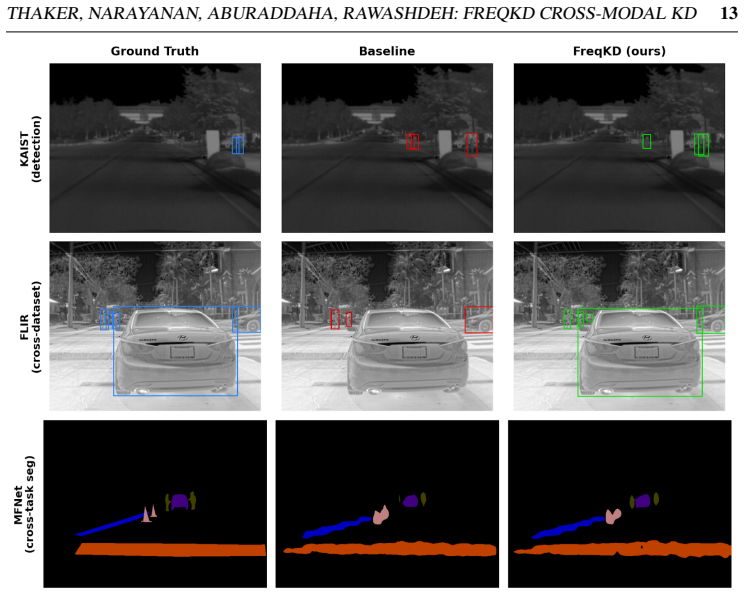
- Raises KAIST mAP50 from the DINOv2 baseline to 64.1, a 2.4-point absolute gain.
- Transfers the learned representation to FLIR ADAS with a 2.1 mAP50 improvement.
- Improves mean intersection-over-union by 1.85 on MFNet segmentation.
- Delivers a 1.0 mAP50 gain when the student uses a ResNet-50 backbone instead of the original transformer.
Where Pith is reading between the lines
- The same frequency split could be tested on other cross-modal pairs such as RGB-to-depth or RGB-to-event data where texture statistics also differ.
- The fixed 0.1 weighting might be replaced by a small validation sweep or learned scalar without changing the core decoupling idea.
- Because the method operates on intermediate features, it could be combined with existing KD techniques that already separate content and style.
Load-bearing premise
The extra divergence measured in high-frequency bands arises mainly from modality-specific characteristics that should be tolerated rather than aligned.
What would settle it
A controlled experiment in which uniform MSE applied across all frequencies on the same backbone and data produces equal or higher mAP50 than the frequency-decoupled version.
Figures
read the original abstract
Transfer learning from large-scale RGB foundation models to infrared (IR) imagery through knowledge distillation (KD) remains challenging due to fundamental differences in image formation physics. We investigate the spectral structure of the RGB--IR modality gap and observe that feature divergence is not uniform across spatial frequencies: low-frequency components (shape, layout) show greater cross-modal alignment than high-frequency components (texture, fine edges), which reflect modality-specific characteristics. Based on this analysis, we propose FreqKD, a frequency-decoupled distillation framework that applies asymmetric supervision adapted to each band's cross-modal consistency. The method employs strict mean squared error (MSE) on the low-frequency band to preserve shared structural information and a relaxed log-MSE loss (weighted at 0.1) on the high-frequency band to provide edge guidance while tolerating texture differences. Spectral divergence analysis on 500 paired samples shows that high-frequency divergence exceeds low-frequency divergence by a factor of 2.4x on average across all analysed transformer layers. On KAIST multispectral pedestrian detection, FreqKD achieves 64.1 mAP50, improving 2.4 points over the DINOv2 baseline. The learned representation transfers across datasets (FLIR ADAS, +2.1 mAP50), tasks (MFNet segmentation, +1.85 mean intersection-over-union), and architectures (ResNet-50, +1.0 mAP50). Code is available at: https://anonymous.4open.science/r/freq_decoupled_kd-5E5A
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes FreqKD, a frequency-decoupled knowledge distillation method for transferring RGB foundation models (DINOv2) to infrared object detection. Based on spectral analysis of 500 paired RGB-IR samples showing 2.4x higher feature divergence in high-frequency bands than low-frequency bands across transformer layers, it applies strict MSE to low-frequency components and a relaxed 0.1-weighted log-MSE to high-frequency components. This yields 64.1 mAP50 on KAIST multispectral pedestrian detection (+2.4 over baseline), with reported transfers to FLIR ADAS (+2.1 mAP50), MFNet segmentation (+1.85 mIoU), and ResNet-50 backbone (+1.0 mAP50).
Significance. If the frequency-specific asymmetry is shown to be robust and causally responsible for the gains, the method could offer a practical way to handle modality gaps in cross-modal KD without forcing alignment on texture differences. The cross-dataset, cross-task, and cross-architecture transfer results suggest potential generality beyond the KAIST benchmark.
major comments (4)
- [Abstract / §3] Abstract and §3 (spectral analysis): the 2.4x high-frequency divergence claim is based on 500 paired samples but provides no description of the frequency decomposition procedure, no per-layer or per-sample variance, and no error bars; this measurement directly motivates the asymmetric loss design and must be reproducible.
- [§4] §4 (loss formulation): the 0.1 weighting factor on the high-frequency log-MSE term is presented as fixed without ablation against uniform weighting, alternative factors, or learned weights; because the central claim attributes the 2.4 mAP50 gain to this specific relaxation, the lack of sensitivity analysis makes the result under-determined.
- [§5] §5 (experiments): no control experiments test whether enforcing high-frequency alignment (e.g., equal MSE on both bands) actually harms downstream detection, nor whether the observed divergence gap persists in same-modality (RGB-RGB or IR-IR) pairs after controlling for general high-frequency noise.
- [§5] §5 (KAIST results): the 64.1 mAP50 figure and +2.4 improvement are reported without standard deviations across runs or statistical significance tests, weakening the claim that the frequency-decoupled losses are responsible for the observed gain.
minor comments (1)
- [Abstract] The code link is given as anonymous; a permanent repository with the exact spectral-analysis script would strengthen reproducibility.
Simulated Author's Rebuttal
We thank the referee for the thoughtful comments on our manuscript. We address each of the major comments below and will incorporate revisions to improve clarity, reproducibility, and experimental rigor.
read point-by-point responses
-
Referee: [Abstract / §3] the 2.4x high-frequency divergence claim is based on 500 paired samples but provides no description of the frequency decomposition procedure, no per-layer or per-sample variance, and no error bars; this measurement directly motivates the asymmetric loss design and must be reproducible.
Authors: We agree that additional details are necessary for reproducibility. In the revised manuscript, we will provide a full description of the frequency decomposition procedure in §3, including the use of 2D Fourier transforms with specific low-pass and high-pass filters. We will also report per-layer and per-sample variance along with error bars on the 2.4x factor to quantify the consistency of the observation across the 500 samples. revision: yes
-
Referee: [§4] the 0.1 weighting factor on the high-frequency log-MSE term is presented as fixed without ablation against uniform weighting, alternative factors, or learned weights; because the central claim attributes the 2.4 mAP50 gain to this specific relaxation, the lack of sensitivity analysis makes the result under-determined.
Authors: We acknowledge this point and will add a comprehensive ablation study in the revised §5. This will include results for different weighting factors (0.01, 0.05, 0.1, 0.5, 1.0) on the high-frequency term, as well as uniform weighting across both bands. We will also explore a learned weight variant if feasible. These experiments will help substantiate the choice of 0.1 and its contribution to the performance gains. revision: yes
-
Referee: [§5] no control experiments test whether enforcing high-frequency alignment (e.g., equal MSE on both bands) actually harms downstream detection, nor whether the observed divergence gap persists in same-modality (RGB-RGB or IR-IR) pairs after controlling for general high-frequency noise.
Authors: We agree that such controls would provide stronger evidence for the frequency-specific approach. We commit to adding these experiments in the revision: (1) a variant with equal MSE on high-frequency components to measure any degradation in detection performance, and (2) divergence analysis on same-modality pairs to demonstrate that the observed gap is modality-specific. These will be presented in §5. revision: yes
-
Referee: [§5] the 64.1 mAP50 figure and +2.4 improvement are reported without standard deviations across runs or statistical significance tests, weakening the claim that the frequency-decoupled losses are responsible for the observed gain.
Authors: We will address this by conducting multiple runs (at least 5 seeds) and reporting mean performance with standard deviations for the KAIST results. We will also perform and report a statistical significance test (e.g., t-test) to support the significance of the +2.4 mAP50 improvement. revision: yes
Circularity Check
No significant circularity; method defined independently of results
full rationale
The paper measures spectral divergence empirically on 500 paired samples (2.4x factor) to motivate an asymmetric loss design (strict MSE on low-frequency, log-MSE weighted at 0.1 on high-frequency), then reports downstream mAP gains on public benchmarks. No equation shows the 0.1 weight or performance numbers reducing to the divergence measurement by construction, nor any self-citation chain, uniqueness theorem, or ansatz smuggling that would make the central claim tautological. The derivation chain remains self-contained against external data.
Axiom & Free-Parameter Ledger
free parameters (1)
- high-frequency loss weight =
0.1
axioms (1)
- domain assumption Low-frequency components exhibit greater cross-modal alignment than high-frequency components.
Reference graph
Works this paper leans on
-
[1]
Multimodal object detection via probabilistic ensembling
Yi-Ting Chen, Jinghao Shi, Zelin Ye, Christoph Mertz, Deva Ramanan, and Shu Kong. Multimodal object detection via probabilistic ensembling. InECCV, 2022
2022
-
[2]
Cross-modality fusion transformer for multispectral object detection.arXiv:2111.00273, 2021
Qingyun Fang, Dapeng Han, and Zhaokui Wang. Cross-modality fusion transformer for multispectral object detection.arXiv:2111.00273, 2021
arXiv 2021
-
[3]
Dantas, Luigi Di Caro, and Dino Ienco
Roger Ferrod, Cássio F. Dantas, Luigi Di Caro, and Dino Ienco. Revisiting cross-modal knowledge distillation: A disentanglement approach for RGBD semantic segmentation. InECML-PKDD, 2025
2025
-
[4]
Domain-adversarial train- ing of neural networks
Yaroslav Ganin, Evgeniya Ustinova, Hana Ajakan, Pascal Germain, Hugo Larochelle, François Laviolette, Mario Marchand, and Victor Lempitsky. Domain-adversarial train- ing of neural networks. InJMLR, volume 17, pages 1–35, 2016
2016
-
[5]
Dual-stream spectral decoupling distillation for remote sensing object detection.IEEE Trans
Xiangyi Gao, Danpei Zhao, Bo Yuan, and Wentao Li. Dual-stream spectral decoupling distillation for remote sensing object detection.IEEE Trans. Geosci. Remote Sens., 2025
2025
-
[6]
ImageBind: One embedding space to bind them all
Rohit Girdhar, Alaaeldin El-Nouby, Zhuang Liu, Mannat Singh, Kalyan Vasudev Al- wala, Armand Joulin, and Ishan Misra. ImageBind: One embedding space to bind them all. InCVPR, 2023
2023
-
[7]
A kernel two-sample test.JMLR, 13:723–773, 2012
Arthur Gretton, Karsten M Borgwardt, Malte J Rasch, Bernhard Schölkopf, and Alexander Smola. A kernel two-sample test.JMLR, 13:723–773, 2012
2012
-
[8]
MFNet: Towards real-time semantic segmentation for autonomous vehicles with multi-spectral scenes
Qishen Ha, Kohei Watanabe, Takumi Karasawa, Yoshitaka Ushiku, and Tatsuya Harada. MFNet: Towards real-time semantic segmentation for autonomous vehicles with multi-spectral scenes. InIROS, 2017
2017
-
[9]
Distilling the knowledge in a neural network.arXiv:1503.02531, 2015
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network.arXiv:1503.02531, 2015
Pith/arXiv arXiv 2015
-
[10]
LoRA: Low-rank adaptation of large language models
Edward J Hu, Shen Yelong, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. InICLR, 2022
2022
-
[11]
C2KD: Bridg- ing the modality gap for cross-modal knowledge distillation
Fushuo Huo, Wenchao Xu, Jingcai Guo, Haozhao Wang, and Song Guo. C2KD: Bridg- ing the modality gap for cross-modal knowledge distillation. InCVPR, 2024
2024
-
[12]
KAIST multispectral pedestrian dataset.IEEE Trans
Soonmin Hwang, Jaesik Park, Namil Kim, Yukyung Choi, and In So Kweon. KAIST multispectral pedestrian dataset.IEEE Trans. Intell. Transp. Syst., 19(3), 2018
2018
-
[13]
LLVIP: A visible- infrared paired dataset for low-light vision
Xinyu Jia, Chuang Zhu, Minzhen Li, Wenqi Tang, and Wenli Zhou. LLVIP: A visible- infrared paired dataset for low-light vision. InICCV Workshops, 2021
2021
-
[14]
Contrast-guided cross-modal distillation for thermal object detection.arXiv:2511.01435, 2025
SiWoo Kim and JhongHyun An. Contrast-guided cross-modal distillation for thermal object detection.arXiv:2511.01435, 2025. 16THAKER, NARA Y ANAN, ABURADDAHA, RAW ASHDEH: FREQKD CROSS-MODAL KD
arXiv 2025
-
[15]
Seg- ment anything
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C Berg, Wan-Yen Lo, et al. Seg- ment anything. InICCV, 2023
2023
-
[16]
Similarity of neural network representations revisited
Simon Kornblith, Mohammad Norouzi, Honglak Lee, and Geoffrey Hinton. Similarity of neural network representations revisited. InICML, 2019
2019
-
[17]
Multispectral pedestrian detection via simultaneous detection and segmentation
Chengyang Li, Dan Song, Ruofeng Tong, and Min Tang. Multispectral pedestrian detection via simultaneous detection and segmentation. InBMVC, 2018
2018
-
[18]
Multi-teacher knowledge distillation with triplet loss for cross-modal object tracking
Yi Li, Lei Liu, Mengya Zhang, and Chenglong Li. Multi-teacher knowledge distillation with triplet loss for cross-modal object tracking. InInt. Conf. Brain Inspired Cognitive Systems (BICS), 2024
2024
-
[19]
Distilling cross- modal knowledge via feature disentanglement
Junhong Liu, Yuan Zhang, Tao Huang, Wenchao Xu, and Renyu Yang. Distilling cross- modal knowledge via feature disentanglement. InAAAI, 2026
2026
-
[20]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InICLR, 2019
2019
-
[21]
Guerrero Pena, Masih Aminbeidokhti, Thomas Dubail, Eric Granger, and Marco Pedersoli
Heitor Rapela Medeiros, Fidel A. Guerrero Pena, Masih Aminbeidokhti, Thomas Dubail, Eric Granger, and Marco Pedersoli. HalluciDet: Hallucinating RGB modal- ity for person detection through privileged information. InWACV, 2024
2024
-
[22]
DINOv2: Learning robust visual features without supervision.Transactions on Machine Learning Research, 2024
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. DINOv2: Learning robust visual features without supervision.Transactions on Machine Learning Research, 2024
2024
-
[23]
How do vision transformers work? InICLR, 2022
Namuk Park and Songkuk Kim. How do vision transformers work? InICLR, 2022
2022
-
[24]
Frequency attention for knowledge distillation
Cuong Pham, Van-Anh Nguyen, Trung Le, Dinh Phung, Gustavo Carneiro, and Thanh- Toan Do. Frequency attention for knowledge distillation. InWACV, 2024
2024
-
[25]
FcaNet: Frequency channel attention networks
Zequn Qin, Pengyi Zhang, Fei Wu, and Xi Li. FcaNet: Frequency channel attention networks. InICCV, 2021
2021
-
[26]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InICML, 2021
2021
-
[27]
PHI-S: Distribution balancing for label-free multi-teacher distillation
Mike Ranzinger, Jon Barker, Greg Heinrich, Pavlo Molchanov, Bryan Catanzaro, and Andrew Tao. PHI-S: Distribution balancing for label-free multi-teacher distillation. arXiv:2410.01680, 2024
arXiv 2024
-
[28]
AM-RADIO: Ag- glomerative vision foundation model reduce all domains into one
Mike Ranzinger, Greg Heinrich, Jan Kautz, and Pavlo Molchanov. AM-RADIO: Ag- glomerative vision foundation model reduce all domains into one. InCVPR, pages 12490–12500, 2024
2024
-
[29]
Global filter networks for image classification
Yongming Rao, Wenliang Zhao, Zheng Zhu, Jiwen Lu, and Jie Zhou. Global filter networks for image classification. InNeurIPS, 2021. THAKER, NARA Y ANAN, ABURADDAHA, RAW ASHDEH: FREQKD CROSS-MODAL KD17
2021
-
[30]
SAM 2: Segment anything in images and videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman Rädle, Chloe Rolland, Laura Gustafson, et al. SAM 2: Segment anything in images and videos. InICLR, 2025
2025
-
[31]
Faster R-CNN: Towards real-time object detection with region proposal networks
Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster R-CNN: Towards real-time object detection with region proposal networks. InNeurIPS, 2015
2015
-
[32]
FitNets: Hints for thin deep nets
Adriana Romero, Nicolas Ballas, Samira Ebrahimi Kahou, Antoine Chassang, Carlo Gatta, and Yoshua Bengio. FitNets: Hints for thin deep nets. InICLR, 2015
2015
-
[33]
Return of frustratingly easy domain adaptation
Baochen Sun and Kate Saenko. Return of frustratingly easy domain adaptation. In AAAI, 2016
2016
-
[34]
CRC Press, 2016
Glenn J Tattersall.Infrared Thermography: A Complete Laboratory and Field Manual. CRC Press, 2016
2016
-
[35]
FLIR thermal dataset for algorithm training.https://oem.flir
Teledyne FLIR. FLIR thermal dataset for algorithm training.https://oem.flir. com/solutions/automotive/adas-dataset-form/, 2018
2018
-
[36]
Michael Tschannen et al. SigLIP 2: Multilingual vision-language encoders with im- proved semantic understanding, localization, and dense features.arXiv:2502.14786, 2025
Pith/arXiv arXiv 2025
-
[37]
SAMamba: Adaptive state space modeling with hierarchical vision for infrared small target detection.Information Fusion, 124, 2025
Wenhao Xu, Shuchen Zheng, Changwei Wang, Zherui Zhang, Chuan Ren, Rongtao Xu, and Shibiao Xu. SAMamba: Adaptive state space modeling with hierarchical vision for infrared small target detection.Information Fusion, 124, 2025
2025
-
[38]
Meng Yang, Fan Fan, Zizhuo Li, Songchu Deng, Yong Ma, and Jiayi Ma. DistillMatch: Leveraging knowledge distillation from vision foundation model for multimodal image matching.arXiv:2509.16017, 2025
arXiv 2025
-
[39]
Focal and global knowledge distillation for detectors
Zhendong Yang, Zhe Li, Xiaohu Jiang, Yuan Gong, Zehuan Yuan, Danpei Zhao, and Chun Yuan. Focal and global knowledge distillation for detectors. InCVPR, 2022
2022
-
[40]
Masked generative distillation
Zhendong Yang, Zhe Li, Mingqi Shao, Dachuan Shi, Zehuan Yuan, and Chun Yuan. Masked generative distillation. InECCV, 2022
2022
-
[41]
Sigmoid loss for language image pre-training
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre-training. InICCV, 2023
2023
-
[42]
DINO: DETR with improved denoising anchor boxes for end-to- end object detection
Hao Zhang, Feng Li, Shilong Liu, Lei Zhang, Hang Su, Jun Zhu, Lionel M Ni, and Heung-Yeung Shum. DINO: DETR with improved denoising anchor boxes for end-to- end object detection. InICLR, 2023
2023
-
[43]
Wavelet knowledge distillation: Towards efficient image-to-image translation
Linfeng Zhang, Xin Chen, Xiaobing Tu, Pengfei Wan, Ning Xu, and Kaisheng Ma. Wavelet knowledge distillation: Towards efficient image-to-image translation. In CVPR, 2022
2022
-
[44]
Efficient RGB-T tracking via cross-modality distillation
Tianlu Zhang, Hongyuan Guo, Qiang Jiao, Qiang Zhang, and Jungong Han. Efficient RGB-T tracking via cross-modality distillation. InCVPR, pages 5404–5413, 2023
2023
-
[45]
Xiwei Zhang, Chunjin Yang, Yiming Xiao, Runtong Zhang, and Fanman Meng. SS- DC: Spatial-spectral decoupling and coupling across visible-infrared gap for domain adaptive object detection.arXiv:2507.12017, 2025. 18THAKER, NARA Y ANAN, ABURADDAHA, RAW ASHDEH: FREQKD CROSS-MODAL KD
arXiv 2025
-
[46]
FreeKD: Knowledge distillation via semantic frequency prompt
Yuan Zhang, Tao Huang, Jiaming Liu, Tao Jiang, Kuan Cheng, and Shanghang Zhang. FreeKD: Knowledge distillation via semantic frequency prompt. InCVPR, 2024
2024
-
[47]
Unveiling the potential of segment anything model 2 for RGB-thermal semantic segmentation with language guidance
Jiayi Zhao, Fei Teng, Kai Luo, Guoqiang Zhao, Zhiyong Li, Xu Zheng, and Kailun Yang. Unveiling the potential of segment anything model 2 for RGB-thermal semantic segmentation with language guidance. InIROS, 2025
2025
-
[48]
Improving multispectral pedestrian detection by addressing modality imbalance problems
Kailai Zhou, Linsen Chen, and Xun Cao. Improving multispectral pedestrian detection by addressing modality imbalance problems. InECCV, 2020
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.