TimeRouter: Efficient and Adaptive Routing of Time-Series Foundation Models
Pith reviewed 2026-06-27 10:17 UTC · model grok-4.3
The pith
TimeRouter routes among time-series foundation models with a learned head, selective gate, and ensemble fallback to reach 0.6765 LB MASE on GIFT-EVAL without LLM calls at inference.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
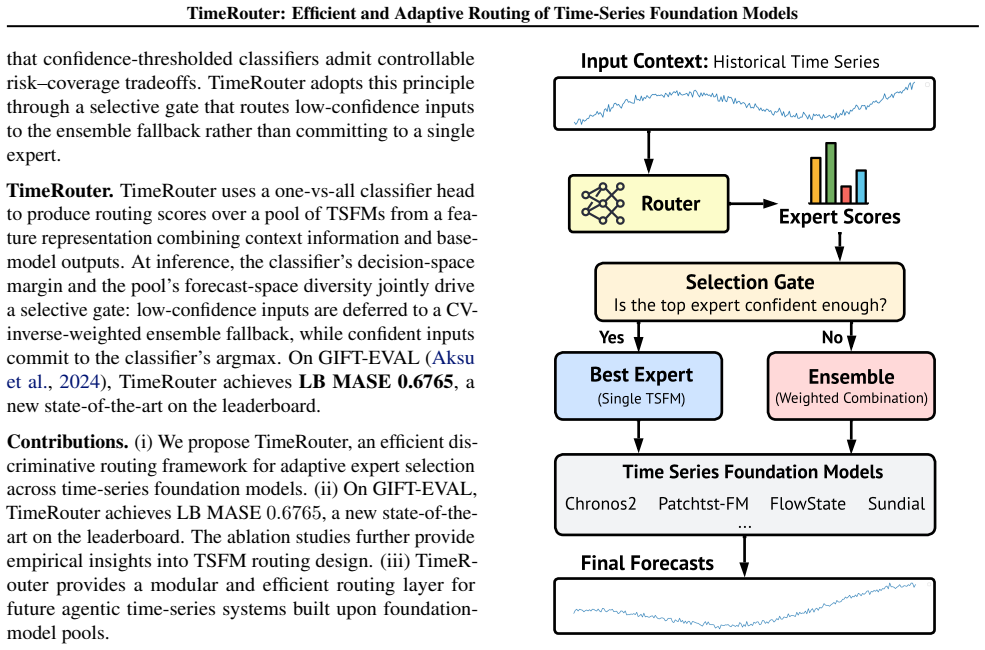
TimeRouter combines a learned routing head, a selective gate, and an ensemble fallback to adaptively select among a pool of pretrained time-series foundation models. The routing head is trained discriminatively on input features to predict which expert will perform best; the gate then either routes to the top expert or triggers the ensemble when no expert is sufficiently confident. This design captures empirical complementarity across the pool at far lower cost than LLM-based selection and produces an LB MASE of 0.6765 on GIFT-EVAL.
What carries the argument
The learned routing head that maps input features to expert scores, together with the selective gate that thresholds those scores to choose single-model routing versus ensemble fallback.
If this is right
- Pool composition directly affects how much the router can improve over any single model or static ensemble.
- Selective gating outperforms both always-route-to-one and always-ensemble strategies on the evaluated tasks.
- A modular routing layer can be inserted into future agentic time-series systems without changing the underlying foundation models.
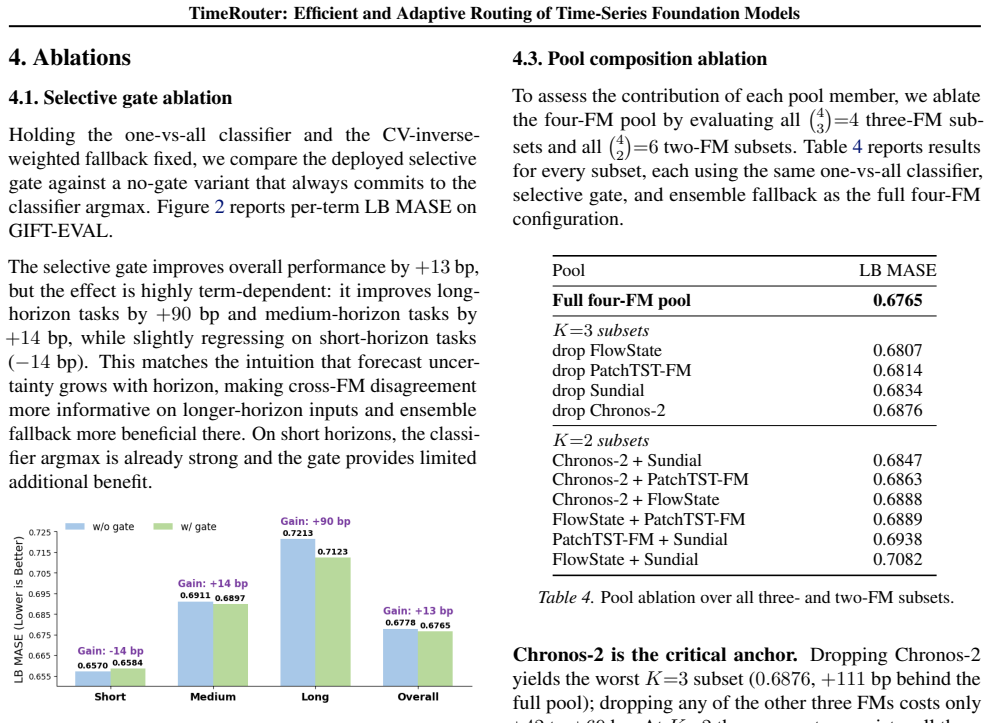
- Ablation results show that both the routing head and the gate are necessary for the reported gains.
Where Pith is reading between the lines
- The same lightweight routing pattern could be tested on pools of non-time-series foundation models where inference cost is also a concern.
- If the router generalizes across datasets outside GIFT-EVAL, it would reduce the need for per-task model selection in deployed forecasting pipelines.
- Curating pools that deliberately maximize complementarity may become a design goal once routing overhead is shown to be low.
Load-bearing premise
The empirical complementarity across the pool of pretrained TSFMs can be captured reliably by a lightweight discriminative router without requiring LLM-based selection at inference time.
What would settle it
An ablation that removes the learned routing head and replaces it with uniform random expert selection while keeping the same pool and gate; if the resulting MASE on GIFT-EVAL equals or beats the reported 0.6765, the claim that the router learns useful complementarity would be falsified.
Figures
read the original abstract
Time-series foundation models (TSFMs) are increasingly explored as predictive experts within emerging agentic time-series systems. However, TSFMs exhibit heterogeneous inductive biases, and no single model consistently dominates across forecasting regimes, making expert selection a critical challenge. Existing systems often delegate this decision to LLM-based controllers, incurring substantial inference overhead. We present TimeRouter, an efficient routing framework that leverages empirical complementarity across a pool of pretrained TSFMs through lightweight discriminative routing, selective gating, and ensemble fallback. Concretely, TimeRouter combines a learned routing head, a selective gate, and an ensemble fallback, enabling adaptive expert selection without invoking an LLM at inference time. TimeRouter achieves state-of-the-art performance on the GIFT-EVAL leaderboard, with an LB MASE of 0.6765. Beyond benchmark performance, our ablation studies provide empirical insights into TSFM routing design, highlighting the importance of pool composition and selective gating. Taken together, these results position TimeRouter as a modular and lightweight routing layer for future agentic time-series systems built upon foundation-model pools. Our code is available at https://github.com/UConn-DSIS/TimeRouter.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces TimeRouter, a routing framework for pools of pretrained time-series foundation models (TSFMs). It combines a learned routing head, a selective gate, and an ensemble fallback to enable adaptive expert selection at inference time without invoking an LLM. The central empirical claim is state-of-the-art performance on the GIFT-EVAL leaderboard (LB MASE of 0.6765), with ablation studies highlighting the roles of pool composition and selective gating; code is released.
Significance. If the reported result is reproducible and properly controlled, the work supplies a lightweight, modular routing layer that exploits empirical complementarity among TSFMs while avoiding LLM inference overhead. The explicit release of code and the ablation-based insights into design choices constitute concrete strengths for an empirical contribution in this area.
major comments (1)
- [Abstract] Abstract: the headline claim of SOTA performance (LB MASE = 0.6765) is presented without any information on the set of baselines, the statistical significance of the improvement, the train/validation/test splits, or confirmation that the reported MASE is computed on held-out data. These details are load-bearing for any empirical SOTA assertion and cannot be assessed from the supplied description.
minor comments (1)
- The abstract states that ablations highlight the importance of pool composition and selective gating but does not enumerate the exact ablation configurations or report quantitative deltas for each component.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. The concern is valid, and we will revise the abstract in the next version to provide the requested context on baselines, evaluation protocol, and held-out data while preserving brevity.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claim of SOTA performance (LB MASE = 0.6765) is presented without any information on the set of baselines, the statistical significance of the improvement, the train/validation/test splits, or confirmation that the reported MASE is computed on held-out data. These details are load-bearing for any empirical SOTA assertion and cannot be assessed from the supplied description.
Authors: We agree that the abstract, as currently written, does not supply these supporting details. The full manuscript (Section 4) describes the GIFT-EVAL leaderboard comparison against the full set of submitted TSFMs and routing baselines, confirms that MASE is computed on the official held-out test splits, and reports the exact train/validation/test partitioning used for any learned components. Statistical significance is not currently quantified in the paper. We will revise the abstract to explicitly note the leaderboard setting, held-out evaluation, and pool of baselines. We will also add a brief statement on statistical significance if space allows or move the claim to a more qualified phrasing. revision: yes
Circularity Check
No significant circularity
full rationale
The paper describes an empirical routing system (learned head + selective gate + ensemble) evaluated on the external GIFT-EVAL leaderboard. No derivation chain, equations, fitted predictions, or first-principles results are present that could reduce to inputs by construction. Ablations are described as empirical, code is released, and the SOTA claim (MASE 0.6765) is benchmark performance rather than a self-referential quantity. No load-bearing self-citations or ansatzes are invoked in the supplied text.
Axiom & Free-Parameter Ledger
free parameters (1)
- parameters of the learned routing head
axioms (2)
- domain assumption TSFMs exhibit heterogeneous inductive biases with no single model dominating across regimes
- domain assumption Empirical complementarity across the chosen pool of pretrained TSFMs can be leveraged by lightweight discriminative routing
Reference graph
Works this paper leans on
-
[1]
Aksu, T., Woo, G., Liu, J., Liu, X., Liu, C., Savarese, S., Xiong, C., and Sahoo, D. Gift-eval: A benchmark for general time series forecasting model evaluation.arXiv preprint arXiv:2410.10393,
-
[2]
F., Stella, L., Turkmen, C., Zhang, X., Mer- cado, P., Shen, H., Shchur, O., Rangapuram, S
Ansari, A. F., Stella, L., Turkmen, C., Zhang, X., Mer- cado, P., Shen, H., Shchur, O., Rangapuram, S. S., Pineda Arango, S., Kapoor, S., et al. Chronos: Learning the language of time series.arXiv preprint arXiv:2403.07815,
-
[3]
Ansari, A. F. et al. Chronos-2: From univariate to universal forecasting.arXiv preprint arXiv:2510.15821,
-
[4]
Tirex: Zero-shot forecasting across long and short horizons with enhanced in-context learning
Auer, A., Podest, P., Klotz, D., B¨ock, S., Klambauer, G., and Hochreiter, S. Tirex: Zero-shot forecasting across long and short horizons with enhanced in-context learning. arXiv preprint arXiv:2505.23719,
-
[5]
Conversational time series foundation models: Towards explainable and effective forecasting
Cao, D., Gee, M., Liu, J., Wang, H., Yang, W., Wang, R., and Liu, Y . Conversational time series foundation models: Towards explainable and effective forecasting. arXiv preprint arXiv:2512.16022,
-
[6]
Das, S. S. S., Goyal, P., Parmar, M., Song, Y ., Le, L. T., Mi- culicich, L., Yoon, J., Zhang, R., Palangi, H., and Pfister, T. Synapse: Adaptive arbitration of complementary ex- pertise in time series foundational models.arXiv preprint arXiv:2511.05460,
-
[7]
Ekambaram, V ., Jati, A., Nguyen, N., Sinthong, P., and Kalagnanam, J. Tiny time mixers (ttms): Fast pre-trained models for enhanced zero/few-shot forecasting of mul- tivariate time series.arXiv preprint arXiv:2401.03955,
- [8]
-
[9]
Graf, L. et al. Flowstate: A sampling-rate-invariant ssm- based time-series foundation model.arXiv preprint arXiv:2508.05287,
-
[10]
Liu, C. et al. Moirai 2.0: When less is more for time series forecasting.arXiv preprint arXiv:2511.11698, 2025a. Liu, X. et al. Moirai-moe: Empowering time series founda- tion models with sparse mixture of experts. InInterna- tional Conference on Machine Learning (ICML),
-
[11]
arXiv:2410.10469. Liu, Y . et al. Sundial: A native flexible decoder transformer for time series. InInternational Conference on Machine Learning (ICML, Oral), 2025b. arXiv:2502.00816. Mozannar, H. and Sontag, D. Consistent estimators for learning to defer to an expert. InInternational Conference on Machine Learning (ICML),
-
[12]
URLhttps://arxiv.org/abs/2310.08278. Salesforce AI Research. Moiraiagent: An agentic framework for context-aware time-series forecasting. Salesforce AI Research blog post, https://www. salesforce.com/blog/moiraiagent/,
-
[13]
Shi, H.-N., Huang, T.-J., Han, L., Zhan, D.-C., and Ye, H.-J. One-embedding-fits-all: Efficient zero-shot time series forecasting by a model zoo.arXiv preprint arXiv:2509.04208,
-
[14]
Wen, Y ., Gifford, W. M., Reddy, C., Nguyen, L. M., Kalagnanam, J., and Julius, A. A. Revisiting the generic transformer: Deconstructing a strong baseline for time se- ries foundation models.arXiv preprint arXiv:2602.06909,
-
[15]
Yu, A., Maddix, D. C., Ansari, A. F., Mahoney, M. W., et al. Understanding the implicit biases of design choices for time series foundation models.arXiv preprint arXiv:2510.19236,
-
[16]
Feature map ϕ.The feature vector for each (series,cutoff) row concatenates four blocks; total dimension d= 165 + 35K (d=305 for the four-FM pool)
The per-FM CV scores are computed from context-tail validation windows for both training and test inputs and used as routing features as well as ensemble weights. Feature map ϕ.The feature vector for each (series,cutoff) row concatenates four blocks; total dimension d= 165 + 35K (d=305 for the four-FM pool). (i)Context-window statistics( 31 dims): 18 time...
1992
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.