Probabilistic Salary Prediction with Graph Attention Networks and a Mixture Density Network
Pith reviewed 2026-06-27 07:52 UTC · model grok-4.3
The pith
GAT-MDN produces full conditional salary distributions by running graph attention over hierarchical and similarity graphs on job attributes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
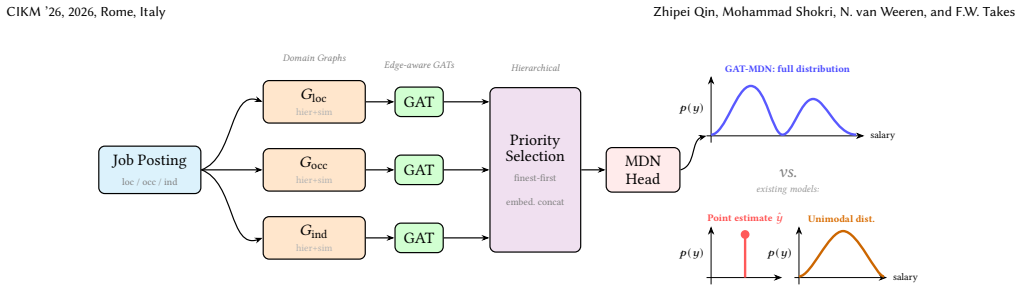
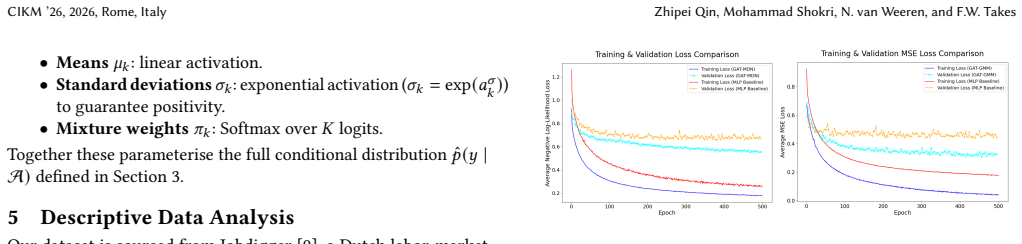
The authors claim that their GAT-MDN framework, which builds three separate multi-relational graphs (one each for location, occupation, and industry), learns node embeddings via edge-feature-aware graph attention, assembles a composite vector through priority-based hierarchical selection, and maps the result to Gaussian mixture parameters, produces strictly better negative log-likelihood and mean squared error than a non-graph MLP-MDN baseline when evaluated on over one million real Dutch job-posting records.
What carries the argument
Domain-specific graphs whose edges combine hierarchical parent-child containment with weighted Sentence-Transformer similarity links, processed by parallel edge-feature-aware Graph Attention Networks whose outputs are fed to a Mixture Density Network head.
If this is right
- The model returns a full conditional distribution over salaries instead of a point prediction, directly quantifying uncertainty and multi-modality.
- A priority-based selection module allows graceful handling of missing or coarse-grained attribute values without retraining.
- Parallel GAT processing of location, occupation, and industry graphs captures cross-domain relational effects that independent categorical encodings miss.
- The learned representations improve both likelihood of observed salaries and squared error on point forecasts simultaneously.
Where Pith is reading between the lines
- The same graph-plus-MDN pattern could be tested on other compensation or pricing tasks that involve hierarchical taxonomies and semantic similarity among categories.
- If the graph edges prove robust, the approach might extend to predicting other continuous outcomes such as house prices or project costs where relational structure among features matters.
- Randomizing or ablating the similarity edges versus the hierarchy edges on the same data would isolate which relational signal contributes most to the performance gain.
Load-bearing premise
The graphs assembled from hierarchical containment relations and sentence-transformer similarities correctly encode the semantic and structural factors that actually govern salary levels.
What would settle it
Running the same GAT-MDN and MLP-MDN models on the identical Dutch dataset but with all graph edges replaced by random connections yields no statistically significant improvement in NLL or MSE.
Figures
read the original abstract
Accurate salary prediction is critical for bridging the information gap between employers and job seekers in modern labor markets. Existing approaches predominantly yield a single point estimate and treat job attributes such as location, occupation, and industry as independent categorical features, ignoring both the inherent uncertainty and multi-modality of real-world compensation data and the rich hierarchical and semantic-similarity relationships that govern pay norms. In this paper we propose GAT-MDN, a unified framework that addresses both limitations simultaneously. For each of the three attribute domains we construct a domain-specific graph whose edges encode (i) hierarchical parent-child containment and (ii) weighted similarity links derived from a pre-trained Sentence-Transformer. Parallel Graph Attention Networks (GATs) with edge-feature-aware attention learn rich, context-sensitive node representations from these multi-relational graphs. A priority-based hierarchical selection module then assembles a composite feature vector that gracefully handles missing or coarse attributes, and a Mixture Density Network (MDN) head maps this vector to the parameters of a Gaussian Mixture Model (GMM), yielding a full conditional salary distribution. Extensive experiments on a real-world Dutch job-posting dataset of over 1 million records demonstrate that GAT-MDN significantly outperforms a non-graph MLP-MDN baseline in both Negative Log-Likelihood (NLL) and Mean Squared Error (MSE).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes GAT-MDN, a framework that builds three domain-specific graphs (for location, occupation, industry) with hierarchical containment edges and weighted Sentence-Transformer similarity edges, processes them with parallel edge-aware GATs, applies a priority-based hierarchical selection module to handle missing attributes, and feeds the resulting representation to an MDN head that outputs parameters of a Gaussian mixture model for conditional salary distributions. On a Dutch job-posting dataset exceeding 1 million records, the model is reported to achieve lower NLL and MSE than a non-graph MLP-MDN baseline.
Significance. If the reported gains are robust and attributable to the graph structure rather than capacity or selection effects, the work would demonstrate a practical way to inject relational inductive bias into probabilistic regression for labor-market data. The scale of the real-world dataset and the explicit handling of multi-modality and missing attributes are positive features; however, the absence of experimental controls leaves the magnitude and source of improvement difficult to assess.
major comments (3)
- [Abstract, §4] Abstract and experimental section: the central claim of statistically significant outperformance in NLL and MSE rests on a comparison to an MLP-MDN baseline, yet no information is supplied on train/test splits, hyper-parameter search protocol, number of random seeds, or any statistical test for the reported differences; without these details the empirical result cannot be evaluated as load-bearing evidence for the GAT component.
- [Graph construction paragraph] Section describing graph construction: the edges derived from a pre-trained Sentence-Transformer are justified only by generic semantic similarity of attribute text; no analysis, ablation, or external validation is provided showing that these edges correlate with similarity of conditional salary distributions rather than unrelated textual similarity, which directly undermines the interpretation that the GATs are learning “pay norms.”
- [Priority-based hierarchical selection module] Methodology section on the priority-based selection module: because the module is present only in the GAT-MDN pipeline and absent from the MLP-MDN baseline, any performance difference could be driven by the selection logic or by the additional parameters it introduces rather than by the graph attention layers; an ablation isolating the GAT contribution is required to support the central attribution.
minor comments (2)
- [GAT description] Notation for the edge-feature-aware attention mechanism should be defined explicitly before its first use to avoid ambiguity with standard GAT formulations.
- [MDN head] The number of Gaussian components in the MDN is listed among the free parameters but no sensitivity analysis or selection criterion is reported.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments raise important points about the robustness of our empirical evaluation and the attribution of performance gains to the graph components. We provide point-by-point responses below and commit to revisions where appropriate to address these concerns.
read point-by-point responses
-
Referee: [Abstract, §4] Abstract and experimental section: the central claim of statistically significant outperformance in NLL and MSE rests on a comparison to an MLP-MDN baseline, yet no information is supplied on train/test splits, hyper-parameter search protocol, number of random seeds, or any statistical test for the reported differences; without these details the empirical result cannot be evaluated as load-bearing evidence for the GAT component.
Authors: We agree that these experimental details are essential for reproducibility and to support the significance claims. In the revised manuscript, we will expand the experimental section to specify the train/test split (80/20 random split stratified by salary range), the hyper-parameter search protocol (Bayesian optimization over learning rate, number of GAT layers, etc.), the use of 5 random seeds with reported means and standard deviations, and the application of a paired t-test to confirm statistical significance (p < 0.05). This addresses the concern directly. revision: yes
-
Referee: [Graph construction paragraph] Section describing graph construction: the edges derived from a pre-trained Sentence-Transformer are justified only by generic semantic similarity of attribute text; no analysis, ablation, or external validation is provided showing that these edges correlate with similarity of conditional salary distributions rather than unrelated textual similarity, which directly undermines the interpretation that the GATs are learning “pay norms.”
Authors: The manuscript motivates the use of Sentence-Transformer embeddings for edge weights by noting that semantic similarity in job attributes is expected to reflect shared pay norms in the labor market. While we did not include a dedicated correlation analysis in the original submission, we agree this would bolster the claim. We will add such an analysis in the revision, for example by measuring the relationship between edge weights and salary variance or mean differences across connected nodes, to validate that the edges capture relevant structure for salary prediction. revision: yes
-
Referee: [Priority-based hierarchical selection module] Methodology section on the priority-based selection module: because the module is present only in the GAT-MDN pipeline and absent from the MLP-MDN baseline, any performance difference could be driven by the selection logic or by the additional parameters it introduces rather than by the graph attention layers; an ablation isolating the GAT contribution is required to support the central attribution.
Authors: We recognize that the priority-based hierarchical selection module is unique to the GAT-MDN architecture in the current experiments. To better isolate the contribution of the graph attention networks, we will perform an ablation study in the revised manuscript by equipping the MLP-MDN baseline with an equivalent selection mechanism. This will allow us to attribute performance differences more confidently to the relational inductive bias provided by the GATs. revision: yes
Circularity Check
No circularity; empirical claim is externally evaluated
full rationale
The paper's central result is an empirical demonstration that GAT-MDN yields lower NLL and MSE than an MLP-MDN baseline on a held-out real-world Dutch job-posting dataset of >1M records. Graph construction uses fixed hierarchical containment plus edges from a pre-trained external Sentence-Transformer; the MDN head produces a GMM whose parameters are learned from data. No equation reduces the reported performance metrics to quantities defined by the model's own fitted parameters, no self-citation supplies a uniqueness theorem or ansatz that the present work depends upon, and the evaluation protocol (explicit non-graph baseline, external data) is independent of the model's internal definitions. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- number of Gaussian components in the MDN
- graph edge weighting parameters from Sentence-Transformer
axioms (2)
- domain assumption Job attributes form meaningful hierarchical containment and semantic-similarity relations that influence salary norms
- domain assumption A Gaussian mixture is an adequate parametric family for conditional salary distributions
Reference graph
Works this paper leans on
-
[1]
Takuya Akiba, Shotaro Sano, Toshihiko Yanase, Takeru Ohta, and Masanori Koyama. 2019. Optuna: A Next-generation Hyperparameter Optimization Frame- work.arXiv preprint arXiv:1907.10902(2019). arXiv:1907.10902
Pith/arXiv arXiv 2019
-
[2]
2025.Community Structure Analysis from Social Networks
Sajid Yousuf Bhat, Fouzia Jan, and Muhammad Abulaish. 2025.Community Structure Analysis from Social Networks. CRC Press. https://doi.org/10.1201/ 9781003508724
2025
-
[3]
Christopher M. Bishop. 1994.Mixture Density Networks. Technical Report NCRG/94/004. Aston University
1994
-
[4]
Long Chen, Yeran Sun, and Piyushimita Thakuriah. 2020.Modelling and Predicting Individual Salaries in the United Kingdom with Graph Convolutional Network. Springer, 61–74. https://doi.org/10.1007/978-3-030-14347-3_7
-
[5]
Zhikai Chen, Haitao Mao, Hang Li, Wei Jin, Hongzhi Wen, Xiaochi Wei, Shuaiqiang Wang, Dawei Yin, Wenqi Fan, Hui Liu, and Jiliang Tang. 2024. Ex- ploring the Potential of Large Language Models (LLMs) in Learning on Graphs. arXiv:2307.03393 [cs.LG] https://arxiv.org/abs/2307.03393
arXiv 2024
-
[6]
Eurostat. 2008. NACE Rev. 2: Statistical Classification of Economic Activities in the European Community. https://ec.europa.eu/eurostat/web/nace-rev2. Based on Regulation (EC) No 1893/2006 of the European Parliament and of the Council
2008
-
[7]
Alex Graves. 2013. Generating Sequences with Recurrent Neural Networks.arXiv preprint arXiv:1308.0850(2013). arXiv:1308.0850 [cs.NE]
Pith/arXiv arXiv 2013
-
[8]
Zhuxi Jiang, Yin Zheng, Huachun Tan, Bangsheng Tang, and Hanning Zhou
-
[9]
Variational Deep Embedding: A Generative Approach to Clustering.arXiv preprint arXiv:1611.05148(2016). arXiv:1611.05148
Pith/arXiv arXiv 2016
-
[10]
Jobdigger. 2025. Real-time Labour Market Data and Analysis. https://www. jobdigger.nl/. Data provided for research purposes
2025
-
[11]
Keisuke Kinoshita, Marc Delcroix, Atsunori Ogawa, Takuya Higuchi, and To- mohiro Nakatani. 2017. Deep mixture density network for statistical model- based feature enhancement. InProceedings of the 2017 IEEE International Con- ference on Acoustics, Speech and Signal Processing (ICASSP). 251–255. https: //doi.org/10.1109/ICASSP.2017.7952156
-
[12]
A. Lazar. 2004. Income Prediction via Support Vector Machine. InICMLA. 143– 149
2004
-
[13]
Ying Li, Hengshu Zhu, Keli Liu, Panpan Zhang, and Hui Xiong. 2022. Learning to Distinguish and Aggregate Skill Sets for Job Salary Prediction. InProceedings of the 31st ACM International Conference on Information & Knowledge Management (CIKM ’22). ACM, 1045–1055. https://doi.org/10.1145/3511808.3557379
-
[14]
McLachlan and Suren Rathnayake
Geoffrey J. McLachlan and Suren Rathnayake. 2014. On the number of compo- nents in a Gaussian mixture model.WIREs Data Mining and Knowledge Discovery 4, 5 (2014), 361–372. https://doi.org/10.1002/widm.1135
-
[15]
Qingxin Meng, Keli Xiao, Dazhong Shen, Hengshu Zhu, and Hui Xiong. 2022. Fine-Grained Job Salary Benchmarking with a Nonparametric Dirichlet Process- Based Latent Factor Model.INFORMS Journal on Computing34, 5 (2022). https: //doi.org/10.1287/ijoc.2022.1182
-
[16]
Qingxin Meng, Hengshu Zhu, Keli Xiao, and Hui Xiong. 2018. Intelligent Salary Benchmarking for Talent Recruitment: A Holistic Matrix Factorization Approach. InProceedings of the 2018 IEEE International Conference on Data Mining (ICDM). 337–346. https://doi.org/10.1109/ICDM.2018.00049
-
[17]
Nils Reimers and Iryna Gurevych. 2019. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing (EMNLP). Association for Computational Linguistics, 3982–3992. https://doi.org/10.18653/v1/D19-1410
-
[18]
Yujun Sun, Fuzhen Zhuang, Hengshu Zhu, Deqing Wang, and Hui Xiong. 2021. Market-oriented job skill valuation with cooperative composition neural network. Nature Communications12, 1 (2021), 1992. https://doi.org/10.1038/s41467-021- 22215-y
-
[19]
Petar Veličković, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Liò, and Yoshua Bengio. 2018. Graph Attention Networks. arXiv:1710.10903 [stat.ML] https://arxiv.org/abs/1710.10903
Pith/arXiv arXiv 2018
-
[20]
Zhongsheng Wang, Shinsuke Sugaya, and Dat P. T. Nguyen. 2019. Salary Predic- tion Using Bidirectional-GRU-CNN Model.Proceedings of the Annual Conference of the Association for Natural Language Processing(2019)
2019
-
[21]
Gulnarida Zhalilova, Aliyma Mamatkasymova, Elnura Zhusupova, and Kunduz Zhalzhaeva. 2024. Forecasting data science professionals’ salaries using machine learning methods based on real data.AIP Conference Proceedings3244 (2024), 030034. https://doi.org/10.1063/5.0242445
-
[22]
Chuxu Zhang, Dongjin Song, Chao Huang, Ananthram Swami, and Nitesh V. Chawla. 2019. Heterogeneous Graph Neural Network.Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (2019). https://api.semanticscholar.org/CorpusID:198952485
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.