bAdag: an adaptive block coordinate gradient method for smooth nonconvex functions
Pith reviewed 2026-06-27 08:58 UTC · model grok-4.3
The pith
bAdag adapts step sizes from cumulative block gradients to prove sublinear ergodic convergence for smooth nonconvex minimization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
bAdag computes an adaptive step size from the cumulative sum of squared block gradients at each iteration and establishes that the ergodic average of the squared gradient norms converges to zero at a sublinear rate when the objective is smooth and possibly nonconvex, provided the gradient satisfies block Lipschitz continuity; the result holds for cyclic, uniform random, and Gauss-Southwell selection and carries over to box-constrained problems.
What carries the argument
Adaptive step size computed from the cumulative sum of squared norms of the selected block gradients, replacing the full-gradient accumulation of standard AdaGrad.
If this is right
- Ergodic sublinear rates hold uniformly for cyclic, uniform random, and Gauss-Southwell block selection.
- The same rates and analysis extend to box-constrained smooth problems.
- The algorithm never evaluates the objective function value.
- Numerical experiments on synthetic and real-world instances confirm the predicted behavior.
Where Pith is reading between the lines
- The uniform rate across selection rules suggests that practical speed differences among the three rules arise mainly from implementation cost rather than asymptotic guarantees.
- The OFFO property opens the door to applying the same cumulative-block mechanism inside other first-order frameworks that avoid function evaluations.
- If the block Lipschitz assumption can be replaced by a weaker local condition, the method could apply to a broader class of nonconvex problems without changing the algorithm.
Load-bearing premise
The gradient satisfies block Lipschitz continuity.
What would settle it
A smooth nonconvex function whose gradient meets the block Lipschitz condition, yet the ergodic average of squared gradient norms fails to approach zero when bAdag is run with any of the three selection rules.
Figures
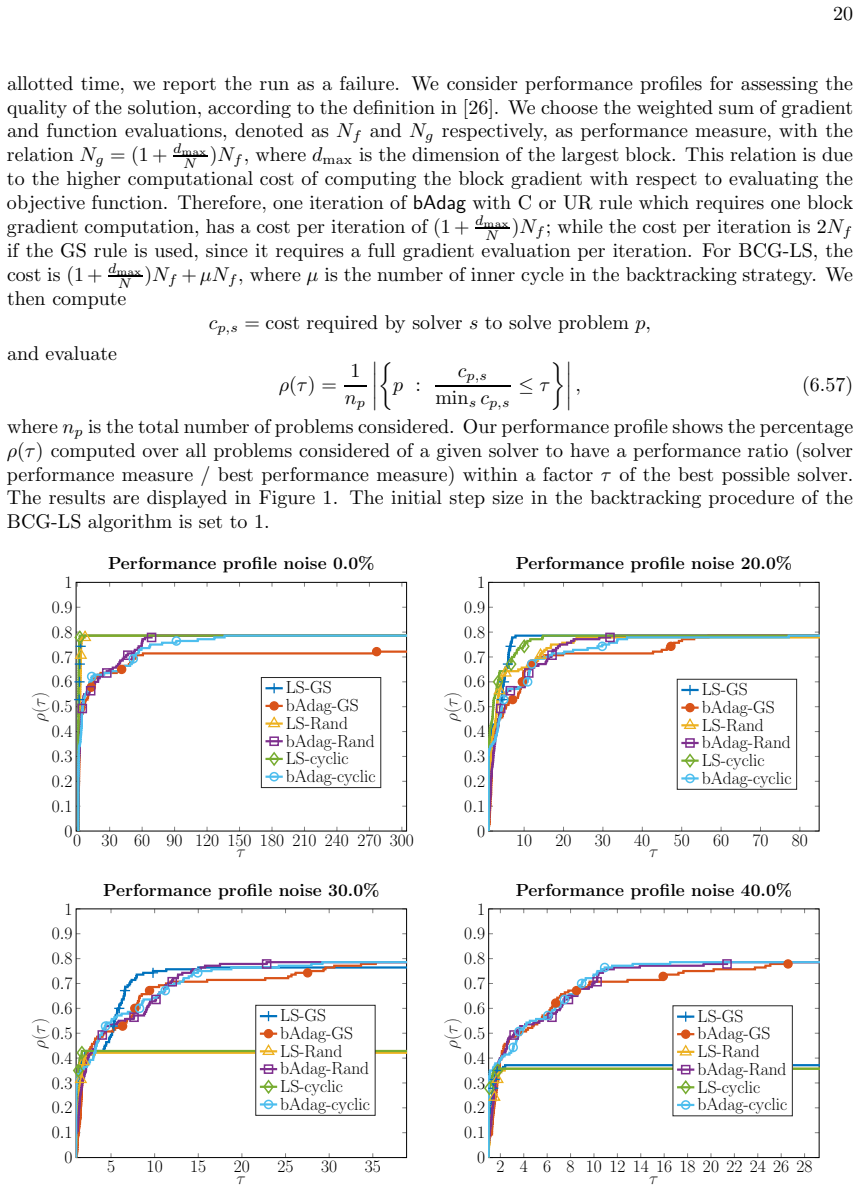
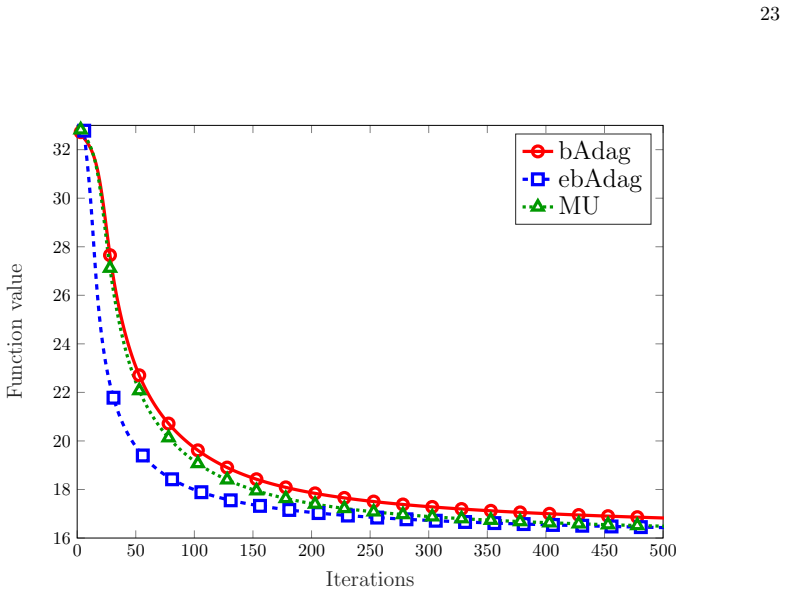

read the original abstract
A new Block Coordinate Gradient (BCG) method, dubbed bAdag, for smooth, nonconvex minimization problem is proposed; it falls in the class of Objective Function Free Optimization (OFFO) methods, and it is based on the AdaGrad algorithm. At each iteration, our method computes an adaptive step size based on the cumulative sum of block gradients, instead of full gradients as in AdaGrad-type methods. We prove ergodic, sublinear convergence rates for the bAdag algorithm when minimizing a smooth, possibly nonconvex objective under the (block) Lipschitz continuity assumption on the gradient. Our theory covers three widely popular block selection strategies: the Cyclic (C) rule, Uniform Random selection (UR), and the greedy Gauss-Southwell (GS) rule. We also extend our algorithm and its convergence theory to box-constrained smooth functions. We validate the proposed algorithms through synthetic and real-world experiments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes bAdag, an adaptive block coordinate gradient method based on AdaGrad for minimizing smooth nonconvex functions. It proves ergodic sublinear convergence rates under the standard block Lipschitz continuity assumption on the gradient, covering the cyclic, uniform random, and Gauss-Southwell block selection rules. The theory and algorithm are extended to box-constrained problems, with validation on synthetic and real-world experiments.
Significance. If the stated rates hold, the work supplies convergence guarantees for an adaptive BCG method in the nonconvex regime under the block-Lipschitz assumption, extending to three common selection strategies and box constraints. This is a useful addition to the OFFO literature, where adaptive step-size constructions with block-coordinate analysis remain relatively sparse.
minor comments (3)
- [§2] §2, definition of the cumulative block-gradient accumulator: the notation G_k^{(i)} is introduced without an explicit recursive formula; adding the update equation would improve readability.
- [Theorem 3.1] Theorem 3.1 (ergodic rate): the dependence of the constant on the block-Lipschitz parameter L_i is stated but the explicit scaling with the number of blocks is not highlighted; a remark clarifying this would help.
- [§5] Numerical section: the comparison baselines do not include a non-adaptive BCG method with the same block selection rules; adding one would strengthen the empirical claims.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our manuscript on bAdag and the recommendation for minor revision. The referee's summary correctly reflects the paper's contributions regarding the adaptive block coordinate method, convergence theory under block Lipschitz assumptions, coverage of multiple selection rules, extension to box constraints, and experimental validation.
Circularity Check
No significant circularity; rates derived from external Lipschitz assumption
full rationale
The paper states an explicit external assumption (block Lipschitz continuity of the gradient) and derives ergodic sublinear rates for bAdag under that assumption for standard selection rules (C/UR/GS) and a box-constraint extension. No step reduces a claimed result to a quantity defined from the algorithm outputs themselves, no fitted parameter is relabeled as a prediction, and no load-bearing self-citation chain is present in the abstract or description. The derivation chain is therefore self-contained against the stated assumption.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The gradient of the objective is (block) Lipschitz continuous
Reference graph
Works this paper leans on
-
[1]
Mushroom. UCI Machine Learning Repository, 1981. DOI: h ttps://doi.org/10.24432/C5959T. [2] . UCI machine learning repository, 2013
-
[2]
An accelerated coordinate g radient descent algorithm for non-separable composite optimization
Aviad Aberdam and Amir Beck. An accelerated coordinate g radient descent algorithm for non-separable composite optimization. Journal of Optimization Theory and Applications , 193(1):219–246, 2022
2022
-
[3]
Even faster accelerated coordinate descent using non-uniform sampling
Zeyuan Allen-Zhu, Zheng Qu, Peter Richt´ arik, and Yang Y uan. Even faster accelerated coordinate descent using non-uniform sampling. In International Conference on Machine Learning , pages 1110–1119. PMLR, 2016
2016
-
[4]
Accelerating n onnegative matrix factorization algorithms using extrapolation
Andersen Man Shun Ang and Nicolas Gillis. Accelerating n onnegative matrix factorization algorithms using extrapolation. Neural Computation , 31(2):417–439, 2019
2019
-
[5]
Proximal alternating minimization and projection methods for nonconvex problems: An approach based on the Kurdyka-/suppress lojasiewicz inequality
H´ edy Attouch, J´ erˆ ome Bolte, Patrick Redont, and Antoine Soubeyran. Proximal alternating minimization and projection methods for nonconvex problems: An approach based on the Kurdyka-/suppress lojasiewicz inequality. Mathematics of Operations Research , 35(2):438–457, 2010
2010
-
[6]
Con vergence of descent methods for semi-algebraic and tame problems: proximal algorithms, forward-backward splitting, and regularized Gauss-Seidel methods
Hedy Attouch, J´ erˆ ome Bolte, and Benar Fux Svaiter. Con vergence of descent methods for semi-algebraic and tame problems: proximal algorithms, forward-backward splitting, and regularized Gauss-Seidel methods. Mathematical programming, 137(1):91–129, 2013
2013
-
[7]
Optimisation
Alfred Auslender. Optimisation. M´ ethodes num´ eriques, 1976
1976
-
[8]
Instance-wise distributionally robust nonnegative matrix factorization
W afa Barkhoda, Amjad Seyedi, Nicolas Gillis, and Fardin Akhlaghian Tab. Instance-wise distributionally robust nonnegative matrix factorization. Pattern Recognition, 169:111732, 2026
2026
-
[9]
On the convergence of alternating minimizat ion for convex programming with applications to iteratively reweighted least squares and decomposition sc hemes
Amir Beck. On the convergence of alternating minimizat ion for convex programming with applications to iteratively reweighted least squares and decomposition sc hemes. SIAM Journal on Optimization , 25(1):185– 209, 2015. 25
2015
-
[10]
On the convergence of b lock coordinate descent type methods
Amir Beck and Luba Tetruashvili. On the convergence of b lock coordinate descent type methods. SIAM journal on Optimization , 23(4):2037–2060, 2013
2037
-
[11]
Fast stochastic second-order adagrad for nonconvex bound-constrained optimization
Stefania Bellavia, Serge Gratton, Benedetta Morini, a nd Ph L Toint. Fast stochastic second-order adagrad for nonconvex bound-constrained optimization. arXiv preprint arXiv:2505.06374 , 2025
Pith/arXiv arXiv 2025
-
[12]
Nonlinear programming
Dimitri P Bertsekas. Nonlinear programming. Journal of the Operational Research Society , 48(3):334–334, 1997
1997
-
[13]
Hyperspectral unmixing overview: Geometri cal, statistical, and sparse regression-based ap- proaches
Jos´ e M Bioucas-Dias, Antonio Plaza, Nicolas Dobigeon , Mario Parente, Qian Du, Paul Gader, and Joce- lyn Chanussot. Hyperspectral unmixing overview: Geometri cal, statistical, and sparse regression-based ap- proaches. IEEE Journal of Selected Topics in Applied Earth Observatio ns and Remote Sensing , 5(2):354–379, 2012
2012
-
[14]
Proximal alternating linearized minimization for nonconvex and nonsmooth problems
J´ erˆ ome Bolte, Shoham Sabach, and Marc Teboulle. Proximal alternating linearized minimization for nonconvex and nonsmooth problems. Mathematical Programming, 146(1):459–494, 2014
2014
-
[15]
A cyclic block coordinate descent method with gener- alized gradient projections
Silvia Bonettini, Marco Prato, and Simone Rebegoldi. A cyclic block coordinate descent method with gener- alized gradient projections. Applied Mathematics and Computation , 286:288–300, 2016
2016
-
[16]
Cyclic block coordinate descent with variance reduction for composite nonconvex optimization
Xufeng Cai, Chaobing Song, Stephen W right, and Jelena D iakonikolas. Cyclic block coordinate descent with variance reduction for composite nonconvex optimization. In International Conference on Machine Learning , pages 3469–3494. PMLR, 2023
2023
-
[17]
E nhancing sparsity by reweighted ℓ1 minimiza- tion
Emmanuel J Candes, Michael B W akin, and Stephen P Boyd. E nhancing sparsity by reweighted ℓ1 minimiza- tion. Journal of Fourier Analysis and Applications , 14(5):877–905, 2008
2008
-
[18]
LIBSVM: A library fo r support vector machines
Chih-Chung Chang and Chih-Jen Lin. LIBSVM: A library fo r support vector machines. ACM Transactions on Intelligent Systems and Technology (TIST) , 2(3):1–27, 2011
2011
-
[19]
Trust region methods
Andrew R Conn, Nicholas IM Gould, and Philippe L Toint. Trust region methods . SIAM, 2000
2000
-
[20]
Dominik Csiba and Peter Richt´ arik. Global convergenc e of arbitrary-block gradient methods for generalized Polyak- Lojasiewicz functions. arXiv preprint arXiv:1709.03014 , 2017
Pith/arXiv arXiv 2017
-
[21]
A simple convergence proof of Adam and Adagrad
Alexandre D´ efossez, Leon Bottou, Francis Bach, and Ni colas Usunier. A simple convergence proof of Adam and Adagrad. Transactions on Machine Learning Research , 2022
2022
-
[22]
Nearest neighbor based greedy coordinate descent
Inderjit Dhillon, Pradeep Ravikumar, and Ambuj Tewari . Nearest neighbor based greedy coordinate descent. Advances in Neural Information Processing Systems , 24, 2011
2011
-
[23]
Alternatin g randomized block coordinate descent
Jelena Diakonikolas and Lorenzo Orecchia. Alternatin g randomized block coordinate descent. In International Conference on Machine Learning , pages 1224–1232. PMLR, 2018
2018
-
[24]
On the equivalence betw een non-negative matrix factorization and proba- bilistic latent semantic indexing
Chris Ding, Tao Li, and W ei Peng. On the equivalence betw een non-negative matrix factorization and proba- bilistic latent semantic indexing. Computational Statistics & Data Analysis , 52(8):3913–3927, 2008
2008
-
[25]
Benchmarking optim ization software with performance profiles
Elizabeth D Dolan and Jorge J Mor´ e. Benchmarking optim ization software with performance profiles. Math- ematical Programming, 91(2):201–213, 2002
2002
-
[26]
Robust nonnegative matrix factorization via half-quadratic minimiza- tion
Liang Du, Xuan Li, and Yi-Dong Shen. Robust nonnegative matrix factorization via half-quadratic minimiza- tion. In 2012 IEEE 12th International Conference on Data Mining , pages 201–210. IEEE, 2012
2012
-
[27]
Adaptive subg radient methods for online learning and stochastic optimization
John Duchi, Elad Hazan, and Yoram Singer. Adaptive subg radient methods for online learning and stochastic optimization. Journal of Machine Learning Research , 12(7), 2011
2011
-
[28]
Tianxiang Gao, Songtao Lu, Jia Liu, and Chris Chu. Lever aging two reference functions in block Bregman proximal gradient descent for non-convex and non-lipschit z problems. arXiv preprint arXiv:1912.07527 , 2019
arXiv 1912
-
[29]
On the convergence of Randomized Bregman Coordinate Descent for Non-Lipschitz Composite Problems
Tianxiang Gao, Songtao Lu, Jia Liu, and Chris Chu. On the convergence of Randomized Bregman Coordinate Descent for Non-Lipschitz Composite Problems. In 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages 5549–5553, 2021
2021
-
[30]
Nonnegative Matrix Factorization
Nicolas Gillis. Nonnegative Matrix Factorization . SIAM, Philadelphia, 2020
2020
-
[31]
Complexity o f a class of first-order objective-function-free optimization algorithms
Serge Gratton, Sadok Jerad, and Ph L Toint. Complexity o f a class of first-order objective-function-free optimization algorithms. Optimization Methods and Software , pages 1–31, 2024
2024
-
[32]
Complexity a nd performance for two classes of noise-tolerant first-order algorithms
Serge Gratton, Sadok Jerad, and Ph L Toint. Complexity a nd performance for two classes of noise-tolerant first-order algorithms. Optimization Methods and Software , pages 1–27, 2025
2025
-
[33]
Param etric complexity analysis for a class of first-order adagrad-like algorithms
Serge Gratton, Sadok Jerad, and Philippe L Toint. Param etric complexity analysis for a class of first-order adagrad-like algorithms. arXiv preprint arXiv:2203.01647 , 2022
arXiv 2022
-
[34]
Serge Gratton, Sadok Jerad, and Philippe L Toint. Compl exity of adagrad and other first-order methods for nonconvex optimization problems with bounds constraints. arXiv preprint arXiv:2406.15793 , 2024
arXiv 2024
-
[35]
S2MPJ and CUTEst optimizat ion problems for Matlab, Python and Julia
Serge Gratton and Ph L Toint. S2MPJ and CUTEst optimizat ion problems for Matlab, Python and Julia. Optimization Methods and Software , 40(4):871–903, 2025
2025
-
[36]
Serge Gratton and Ph L Toint. A unified convergence theor y for adaptive first-order methods in the nonconvex case, including AdaNorm, full and diagonal AdaGrad, Shampo o and muon. arXiv preprint arXiv:2604.17423 , 2026. 26
Pith/arXiv arXiv 2026
-
[37]
Stochastic converg ence of parallel asynchronous adaptive first-order methods
Serge Gratton and Philippe L Toint. Stochastic converg ence of parallel asynchronous adaptive first-order methods. arXiv preprint arXiv:2606.01787 , 2026
Pith/arXiv arXiv 2026
-
[38]
On the convergence o f the block nonlinear Gauss-Seidel method under convex constraints
Luigi Grippo and Marco Sciandrone. On the convergence o f the block nonlinear Gauss-Seidel method under convex constraints. Operations Research Letters, 26(3):127–136, 2000
2000
-
[39]
MahNMF: Manhattan non-negative matrix factorization
Naiyang Guan, Dacheng Tao, Zhigang Luo, and John Shawe- Taylor. MahNMF: Manhattan non-negative matrix factorization. arXiv preprint arXiv:1207.3438 , 2012
Pith/arXiv arXiv 2012
-
[40]
Non-negative matrix factorization for face recognition
David Guillamet and Jordi Vitria. Non-negative matrix factorization for face recognition. In Catalonian Conference on Artificial Intelligence , pages 336–344. Springer, 2002
2002
-
[41]
A modified Huber nonnegative matrix factorization algorithm for hyperspectral unmixing
Ziyang Guo, Anyou Min, Bing Yang, Junhong Chen, and Hong Li. A modified Huber nonnegative matrix factorization algorithm for hyperspectral unmixing. IEEE Journal of Selected Topics in Applied Earth Obser- vations and Remote Sensing , 14:5559–5571, 2021
2021
-
[42]
Shampoo: P reconditioned stochastic tensor optimization
Vineet Gupta, Tomer Koren, and Yoram Singer. Shampoo: P reconditioned stochastic tensor optimization. In International Conference on Machine Learning , pages 1842–1850. PMLR, 2018
2018
-
[43]
Fastest rates for s tochastic mirror descent methods
Filip Hanzely and Peter Richt´ arik. Fastest rates for s tochastic mirror descent methods. Computational Opti- mization and Applications , 79(3):717–766, 2021
2021
-
[44]
Accelera ted Bregman proximal gradient methods for relatively smooth convex optimization
Filip Hanzely, Peter Richtarik, and Lin Xiao. Accelera ted Bregman proximal gradient methods for relatively smooth convex optimization. Computational Optimization and Applications , 79(2):405–440, 2021
2021
-
[45]
Block majorization minimization with extrapolation and application to NMF
Le Thi Khanh Hien, Valentin Leplat, and Nicolas Gillis. Block majorization minimization with extrapolation and application to NMF. SIAM Journal on Mathematics of Data Science , 7(3):1292–1314, 2025
2025
-
[46]
Iteration complexity analysis of block coordinate descent methods
Mingyi Hong, Xiangfeng W ang, Meisam Razaviyayn, and Zh i-Quan Luo. Iteration complexity analysis of block coordinate descent methods. Mathematical Programming, 163(1):85–114, 2017
2017
-
[47]
Muon: An optimizer for hidden layers in neural networks, 202 4
Keller Jordan, Yuchen Jin, Vlado Boza, Jiacheng You, Fr anz Cesista, Laker Newhouse, and Jeremy Bernstein. Muon: An optimizer for hidden layers in neural networks, 202 4
-
[48]
Robust ℓ1-norm factorization in the presence of outliers and missing data by alternative convex programming
Qifa Ke and Takeo Kanade. Robust ℓ1-norm factorization in the presence of outliers and missing data by alternative convex programming. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 739–746, 2005
2005
-
[49]
Adam: a method for stochastic optimi zation
Diederik P Kingma. Adam: a method for stochastic optimi zation. arXiv preprint arXiv:1412.6980 , 2014
Pith/arXiv arXiv 2014
-
[50]
Robust nonneg ative matrix factorization using l21-norm
Deguang Kong, Chris Ding, and Heng Huang. Robust nonneg ative matrix factorization using l21-norm. In Proceedings of the 20th ACM International Conference on Inf ormation and Knowledge Management , pages 673–682, 2011
2011
-
[51]
Block-coordinate and incremental aggregated proximal gradient methods for nonsmooth nonconvex problem s
Puya Latafat, Andreas Themelis, and Panagiotis Patrin os. Block-coordinate and incremental aggregated proximal gradient methods for nonsmooth nonconvex problem s. Mathematical Programming, 193(1):195–224, 2022
2022
-
[52]
Gradient-based learning applied to document recognition
Yann LeCun, L´ eon Bottou, Yoshua Bengio, and Patrick Ha ffner. Gradient-based learning applied to document recognition. Proceedings of the IEEE , 86(11):2278–2324, 1998
1998
-
[53]
Random permutation s fix a worst case for cyclic coordinate descent
Ching-Pei Lee and Stephen J W right. Random permutation s fix a worst case for cyclic coordinate descent. IMA Journal of Numerical Analysis , 39(3):1246–1275, 2019
2019
-
[54]
Learning the parts of objects by non-negative matrix factorization
Daniel D Lee and H Sebastian Seung. Learning the parts of objects by non-negative matrix factorization. nature, 401(6755):788–791, 1999
1999
-
[55]
Efficient accelerated coor dinate descent methods and faster algorithms for solving linear systems
Yin Tat Lee and Aaron Sidford. Efficient accelerated coor dinate descent methods and faster algorithms for solving linear systems. In 2013 IEEE 54th Annual Symposium on Foundations of Computer S cience, pages 147–156. IEEE, 2013
2013
-
[56]
Coordinate-w ise power method
Qi Lei, Kai Zhong, and Inderjit S Dhillon. Coordinate-w ise power method. Advances in neural information processing systems, 29, 2016
2016
-
[57]
On faster convergence of cyclic block coordinate descent-type methods for strongly convex minim ization
Xingguo Li, Tuo Zhao, Raman Arora, Han Liu, and Mingyi Ho ng. On faster convergence of cyclic block coordinate descent-type methods for strongly convex minim ization. Journal of Machine Learning Research , 18(184):1–24, 2018
2018
-
[58]
An improved Adam optimization algorithm combining adaptive coefficients and composite gra dients based on randomized block coordinate descent
Miaomiao Liu, Dan Yao, Zhigang Liu, Jingfeng Guo, and Ji ng Chen. An improved Adam optimization algorithm combining adaptive coefficients and composite gra dients based on randomized block coordinate descent. Computational Intelligence and Neuroscience , 2023(1):4765891, 2023
2023
-
[59]
Randomized block coordinate n on-monotone gradient method for a class of nonlinear programming
Zhaosong Lu and Lin Xiao. Randomized block coordinate n on-monotone gradient method for a class of nonlinear programming. arXiv preprint arXiv:1306.5918 , 1273, 2013
Pith/arXiv arXiv 2013
-
[60]
On the complexity analysis of r andomized block-coordinate descent methods
Zhaosong Lu and Lin Xiao. On the complexity analysis of r andomized block-coordinate descent methods. Mathematical Programming, 152(1):615–642, 2015
2015
-
[61]
On the convergence of the co ordinate descent method for convex differentiable minimization
Zhi-Quan Luo and Paul Tseng. On the convergence of the co ordinate descent method for convex differentiable minimization. Journal of Optimization Theory and Applications , 72(1):7–35, 1992
1992
-
[62]
A signal processi ng perspective on hyperspectral unmixing: Insights from remote sensing
Wing-Kin Ma, Jos´ e M Bioucas-Dias, Tsung-Han Chan, Nic olas Gillis, Paul Gader, Antonio J Plaza, Arul- Murugan Ambikapathi, and Chong-Yung Chi. A signal processi ng perspective on hyperspectral unmixing: Insights from remote sensing. IEEE Signal Processing Magazine , 31(1):67–81, 2013. 27
2013
-
[63]
Adaptive bound optimization for online convex optimization
H Brendan McMahan and Matthew Streeter. Adaptive bound optimization for online convex optimization. arXiv preprint arXiv:1002.4908 , 2010
Pith/arXiv arXiv 2010
-
[64]
Efficiency of stochast ic coordinate proximal gradient methods on nonsep- arable composite optimization
Ion Necoara and Flavia Chorobura. Efficiency of stochast ic coordinate proximal gradient methods on nonsep- arable composite optimization. Mathematics of Operations Research , 50(2):993–1018, 2025
2025
-
[65]
Parallel random coordi nate descent method for composite minimization: Convergence analysis and error bounds
Ion Necoara and Dragos Clipici. Parallel random coordi nate descent method for composite minimization: Convergence analysis and error bounds. SIAM Journal on Optimization , 26(1):197–226, 2016
2016
-
[66]
Efficiency of coordinate descent methods on huge-scale optimization problems
Yu Nesterov. Efficiency of coordinate descent methods on huge-scale optimization problems. SIAM Journal on Optimization , 22(2):341–362, 2012
2012
-
[67]
Efficiency of the ac celerated coordinate descent method on structured optimization problems
Yurii Nesterov and Sebastian U Stich. Efficiency of the ac celerated coordinate descent method on structured optimization problems. SIAM Journal on Optimization , 27(1):110–123, 2017
2017
-
[68]
Let’s ma ke block coordinate descent converge faster: Faster Greedy Rules, Message-Passing, Active-Set Complexity, an d Superlinear Convergence
Julie Nutini, Issam Laradji, and Mark Schmidt. Let’s ma ke block coordinate descent converge faster: Faster Greedy Rules, Message-Passing, Active-Set Complexity, an d Superlinear Convergence. Journal of Machine Learning Research, 23(131):1–74, 2022
2022
-
[69]
Coordinate descent converges faster with the Gauss-Southwell rule than random selection
Julie Nutini, Mark Schmidt, Issam Laradji, Michael Fri edlander, and Hoyt Koepke. Coordinate descent converges faster with the Gauss-Southwell rule than random selection. In International Conference on Machine Learning, pages 1632–1641. PMLR, 2015
2015
-
[70]
Efficient random coordi nate descent algorithms for large-scale structured nonconvex optimization
Andrei Patrascu and Ion Necoara. Efficient random coordi nate descent algorithms for large-scale structured nonconvex optimization. Journal of Global Optimization , 61(1):19–46, 2015
2015
-
[71]
Coordinate friendly structures, algorithms and applications
Zhimin Peng, Tianyu W u, Yangyang Xu, Ming Yan, and W otao Yin. Coordinate friendly structures, algorithms and applications. arXiv preprint arXiv:1601.00863 , 2016
Pith/arXiv arXiv 2016
-
[72]
prunadag: an adaptive pruning-aware gradient method
Margherita Porcelli, Giovanni Seraghiti, and Philipp e L Toint. prunadag: an adaptive pruning-aware gradient method. Computational Optimization and Applications , 2026
2026
-
[73]
A uni fied convergence analysis of block successive minimization methods for nonsmooth optimization
Meisam Razaviyayn, Mingyi Hong, and Zhi-Quan Luo. A uni fied convergence analysis of block successive minimization methods for nonsmooth optimization. SIAM Journal on Optimization , 23(2):1126–1153, 2013
2013
-
[74]
Iteration complexity of randomized block-coordinate descent methods for minimizing a composite function
Peter Richt´ arik and Martin Tak´ aˇ c. Iteration complexity of randomized block-coordinate descent methods for minimizing a composite function. Mathematical Programming, 144(1):1–38, 2014
2014
-
[75]
On the finite time convergen ce of cyclic coordinate descent methods
Ankan Saha and Ambuj Tewari. On the finite time convergen ce of cyclic coordinate descent methods. arXiv preprint arXiv:1005.2146 , 2010
Pith/arXiv arXiv 2010
-
[76]
Nonnegative matrix factorization in the component-wise l1 norm for sparse data
Giovanni Seraghiti, K´ evin Dubrulle, Arnaud Vandaele , and Nicolas Gillis. Nonnegative matrix factorization in the component-wise l1 norm for sparse data. arXiv preprint arXiv:2603.29715 , 2026
arXiv 2026
-
[77]
Document clustering using non- negative matrix factorization
Farial Shahnaz, Michael W Berry, V Paul Pauca, and Rober t J Plemmons. Document clustering using non- negative matrix factorization. Information Processing & Management , 42(2):373–386, 2006
2006
-
[78]
Stochastic meth ods for ℓ1 regularized loss minimization
Shai Shalev-Shwartz and Ambuj Tewari. Stochastic meth ods for ℓ1 regularized loss minimization. In Proceed- ings of the 26th Annual International Conference on Machine Learning, pages 929–936, 2009
2009
-
[79]
A primer on coordinate descent algo- rithms
Hao-Jun Michael Shi, Shenyinying Tu, Yangyang Xu, and W otao Yin. A primer on coordinate descent algo- rithms. arXiv preprint arXiv:1610.00040 , 2016
Pith/arXiv arXiv 2016
-
[80]
Cyclic coordin ate dual averaging with extrapolation
Chaobing Song and Jelena Diakonikolas. Cyclic coordin ate dual averaging with extrapolation. SIAM Journal on Optimization , 33(4):2935–2961, 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.