Enhancing LLM-Based Code Translation with Verified Multi-Semantic Representations
Pith reviewed 2026-06-27 09:18 UTC · model grok-4.3
The pith
A three-module framework extracts, augments, and verifies multiple semantics from source code to guide more accurate LLM translations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
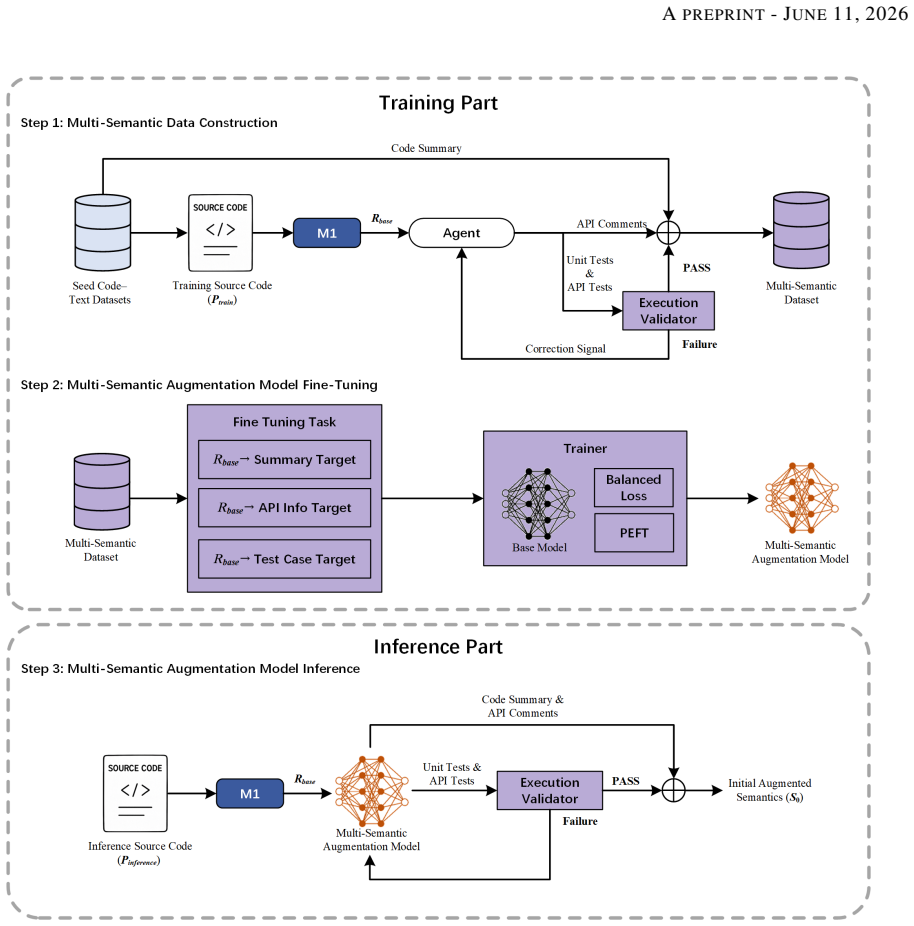
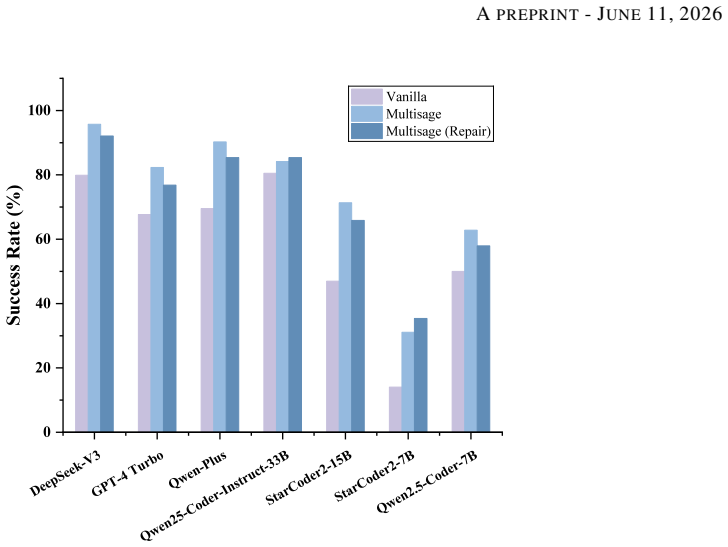
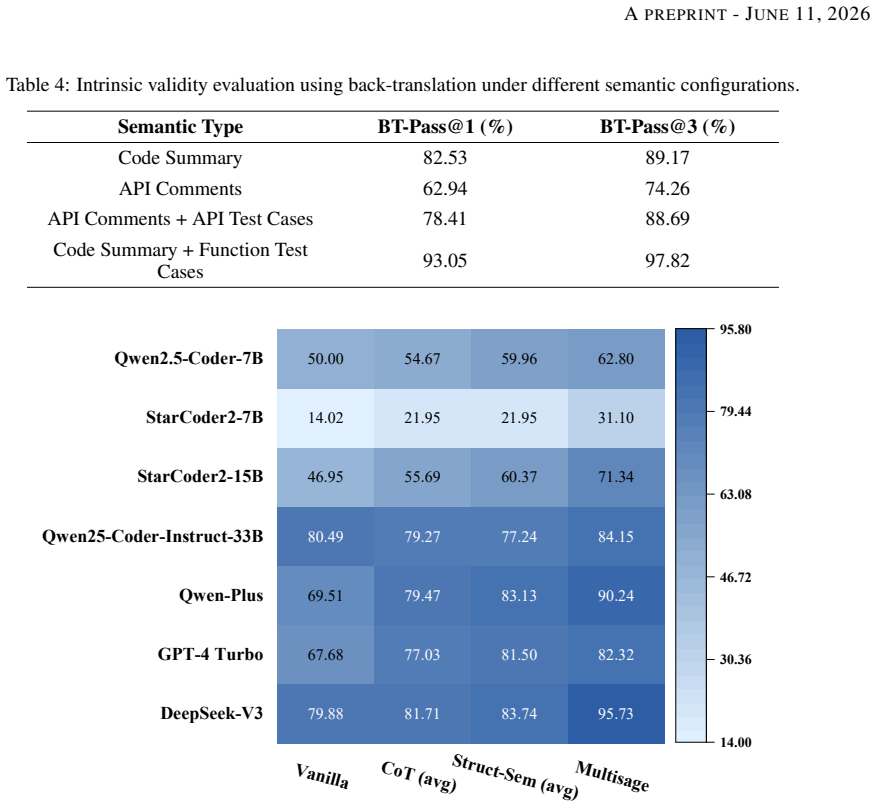
Multisage is a multi-semantic augmentation and self-calibration framework that parses structured base semantics from source code, builds augmented semantics such as code summaries and function-level tests, and refines them via semantics-preserving mutations plus cross-semantic consistency verification, yielding up to 2.22 times higher translation success rates on HumanEval-X across backbone models while outperforming vanilla prompting, instruction-tuned LLMs, and chain-of-thought reasoning.
What carries the argument
The Multisage framework with its semantic representation parsing module, multi-semantic augmentation module, and semantic consistency calibration module that uses mutations and verification.
Load-bearing premise
That semantics-preserving mutations and cross-semantic consistency verification can filter and refine the generated semantics into versions accurate enough to guide correct translations.
What would settle it
If translations guided by the calibrated semantics show no higher success rate than those guided by the uncalibrated augmented semantics on the same HumanEval-X programs, the value of the calibration module would be falsified.
Figures
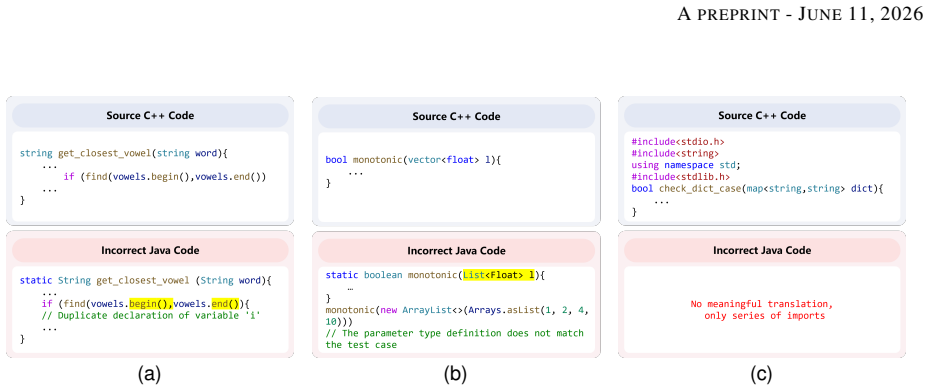
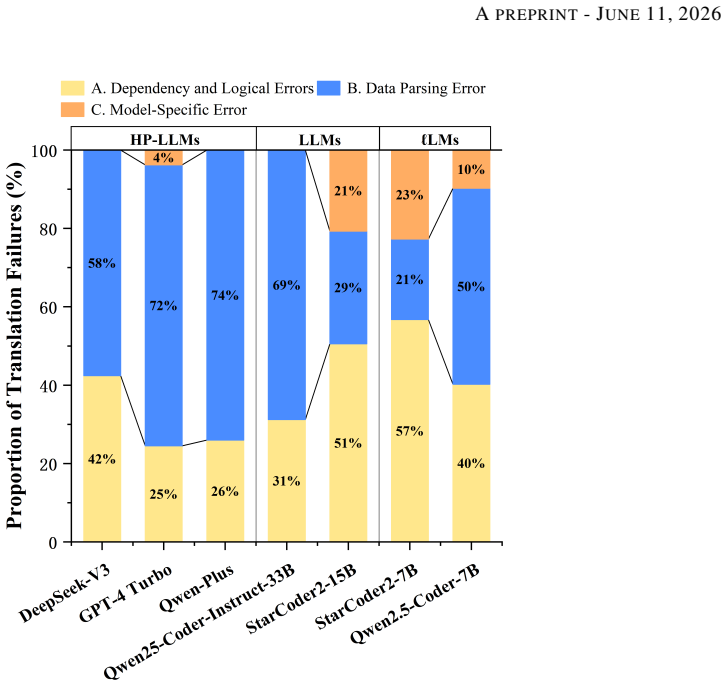
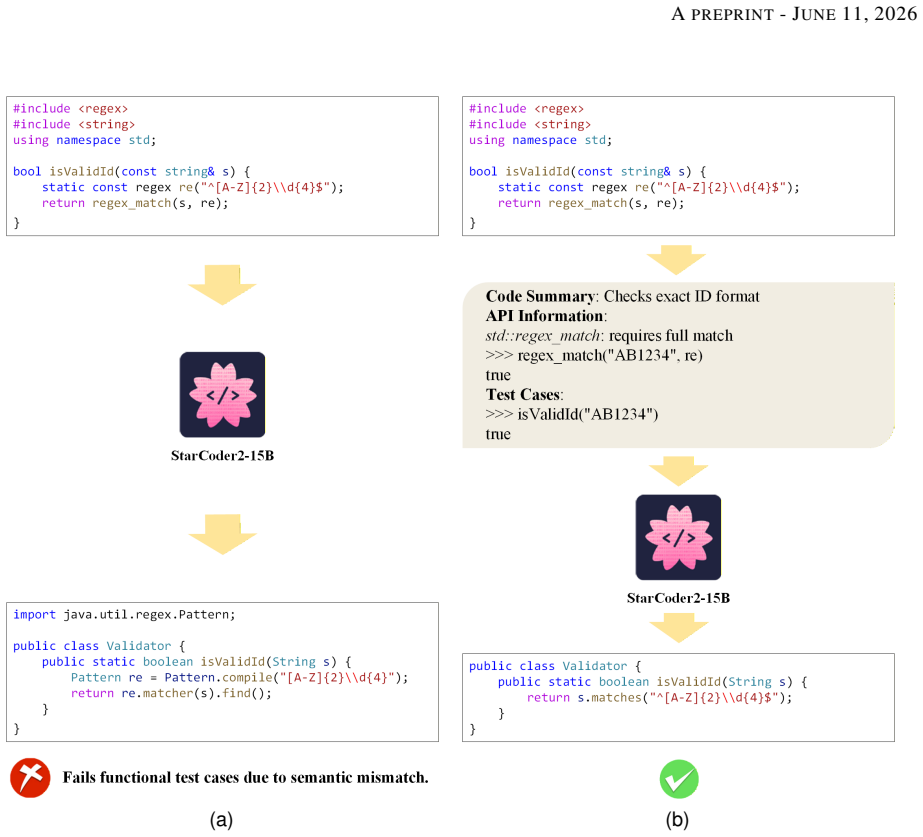
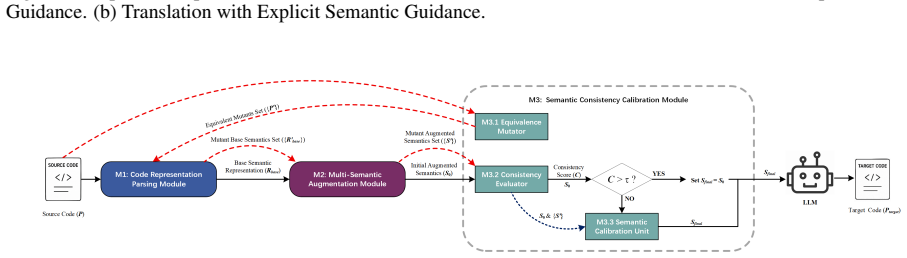
read the original abstract
Large language models (LLMs) have shown great promise for automated code translation, yet existing approaches often rely on token-level statistical patterns rather than sufficient understanding of program semantics. As a result, translated programs may still contain logical and semantic errors. Although high-quality semantic guidance, such as functional descriptions and test cases, can help mitigate these errors, such resources are often unavailable in real-world scenarios. This raises two key challenges: how to construct rich semantic information directly from source code, and how to ensure that such semantics are accurate and reliable enough to guide translation.To address these challenges, we propose Multisage, a multi-semantic augmentation and self-calibration framework for LLM-based code translation. Multisage consists of three modules. First, a semantic representation parsing module extracts structured base semantics from source code, including data-flow graphs, type constraints, and external API information. Second, a multi-semantic augmentation module builds on these representations to generate diverse augmented semantics, including code summaries, function-level test cases, and API-oriented descriptions and tests. Third, a semantic consistency calibration module uses semantics-preserving mutations and cross-semantic consistency verification to filter, calibrate, and refine the generated semantics.Experiments on the HumanEval-X code translation benchmark show that Multisage improves translation success rates by up to 2.22 times across diverse backbone models. It consistently outperforms vanilla prompting, instruction-tuned LLMs, and Chain-of-Thought reasoning, with the largest gains observed on smaller models. These results demonstrate that explicit semantic augmentation can substantially improve the reliability of LLM-based code translation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Multisage, a three-module framework for LLM-based code translation consisting of (1) semantic representation parsing to extract structured base semantics such as data-flow graphs, type constraints, and API information from source code, (2) multi-semantic augmentation to generate diverse semantics including summaries, function-level test cases, and API-oriented descriptions/tests, and (3) semantic consistency calibration that applies semantics-preserving mutations and cross-semantic consistency verification to filter and refine the generated semantics. Experiments on the HumanEval-X benchmark are reported to show translation success-rate improvements of up to 2.22 imes over vanilla prompting, instruction-tuned LLMs, and Chain-of-Thought reasoning, with larger gains on smaller backbone models.
Significance. If the empirical results are shown to be robust, the work would be significant for automated program translation by providing evidence that explicit, verified multi-semantic augmentation can substantially improve LLM reliability on this task, particularly benefiting smaller models. The self-calibration approach via mutations and consistency checks represents a potentially valuable direction if independently validated.
major comments (2)
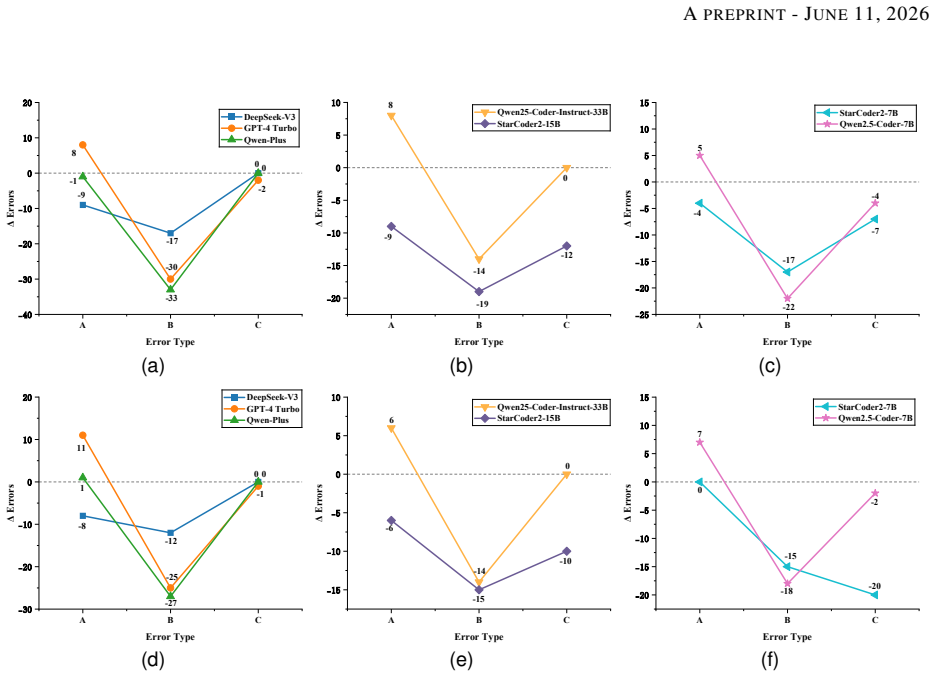
- [Description of the semantic consistency calibration module (and associated experimental results)] The central empirical claim (up to 2.22 imes gains on HumanEval-X) attributes improvement to the three-module pipeline, with the semantic consistency calibration module as the load-bearing final filter. However, the description provides no independent check such as mutation validity rate, agreement with ground-truth tests, or ablation removing only the verification step, leaving the attribution conditional on an untested property of the LLM-driven verification loop.
- [Abstract and experimental evaluation section] The abstract reports quantitative improvements on HumanEval-X but supplies no details on experimental setup, statistical significance testing, exact baseline implementations, error analysis, or how post-hoc choices were made; these omissions are load-bearing for assessing whether the data support the stated claim.
minor comments (2)
- Notation for the three modules and the mutation/verification steps could be made more precise and consistent to aid reproducibility.
- Consider including a table or figure summarizing the exact success rates per backbone model and per language pair to make the 2.22 imes claim easier to verify.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on Multisage. We address each major comment below and indicate the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Description of the semantic consistency calibration module (and associated experimental results)] The central empirical claim (up to 2.22 times gains on HumanEval-X) attributes improvement to the three-module pipeline, with the semantic consistency calibration module as the load-bearing final filter. However, the description provides no independent check such as mutation validity rate, agreement with ground-truth tests, or ablation removing only the verification step, leaving the attribution conditional on an untested property of the LLM-driven verification loop.
Authors: We agree that the current manuscript lacks an isolated ablation of the verification step and does not report mutation validity rates or agreement with ground-truth tests. This limits the strength of attribution to the calibration module. We will add to the experimental section: (1) an ablation that removes only the semantic consistency calibration module while retaining the first two modules, and (2) quantitative results on mutation validity (percentage of mutations that preserve semantics according to available ground-truth tests) and cross-semantic agreement rates. These additions will directly address the concern. revision: yes
-
Referee: [Abstract and experimental evaluation section] The abstract reports quantitative improvements on HumanEval-X but supplies no details on experimental setup, statistical significance testing, exact baseline implementations, error analysis, or how post-hoc choices were made; these omissions are load-bearing for assessing whether the data support the stated claim.
Authors: We acknowledge that the abstract is concise by design and omits these details, while the experimental section provides the core setup and baselines. However, the absence of statistical significance testing, detailed error analysis, and explicit post-hoc choices is a valid concern. We will expand the experimental evaluation section to include: statistical significance (e.g., p-values or confidence intervals for the reported gains), a breakdown of error types across baselines, precise descriptions of baseline implementations (including prompt templates and model versions), and clarification of any post-hoc decisions. We will also update the abstract with a brief reference to the evaluation protocol if space allows. revision: yes
Circularity Check
No significant circularity; empirical results on external benchmark
full rationale
The paper presents a procedural framework (Multisage) consisting of semantic parsing, augmentation, and consistency calibration modules, with performance claims resting entirely on measured success rates on the HumanEval-X benchmark. No equations, fitted parameters, or derivations are offered; the central results are not obtained by construction from the method's own outputs or self-citations. The calibration module is described as an engineering step whose effectiveness is asserted via ablation-style experiments rather than proven by internal consistency or self-reference. This is a standard empirical contribution with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLMs can generate accurate code summaries, test cases, and API descriptions from source code when guided by base semantics.
- domain assumption Semantics-preserving mutations can be used to verify consistency across different semantic representations.
invented entities (1)
-
Multisage framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Automated cobol to java recycling
Maxim Mossienko. Automated cobol to java recycling. In7th European Conference on Software Maintenance and Reengineering (CSMR 2003), 26-28 March 2003, Benevento, Italy, Proceedings, page 40. IEEE Computer Society, 2003
2003
-
[2]
Müller, and John Mylopoulos
Kostas Kontogiannis, Johannes Martin, Kenny Wong, Richard Gregory, Hausi A. Müller, and John Mylopoulos. Code migration through transformations: an experience report. InProceedings of the 1998 conference of the Centre for Advanced Studies on Collaborative Research, November 30 - December 3, 1998, Toronto, Ontario, Canada, page 13. IBM, 1998. 23 APREPRINT-...
1998
-
[3]
A V ATAR: A parallel corpus for java-python program translation
Wasi Uddin Ahmad, Md Golam Rahman Tushar, Saikat Chakraborty, and Kai-Wei Chang. A V ATAR: A parallel corpus for java-python program translation. In Anna Rogers, Jordan L. Boyd-Graber, and Naoaki Okazaki, editors, Findings of the Association for Computational Linguistics: ACL 2023, Toronto, Canada, July 9-14, 2023, pages 2268–2281. Association for Computa...
2023
-
[4]
Unsupervised translation of programming languages
Baptiste Rozière, Marie-Anne Lachaux, Lowik Chanussot, and Guillaume Lample. Unsupervised translation of programming languages. InAdvances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual, 2020
2020
-
[5]
Ming Zhu, Karthik Suresh, and Chandan K. Reddy. Multilingual code snippets training for program translation. InThirty-Sixth AAAI Conference on Artificial Intelligence, AAAI 2022, Thirty-Fourth Conference on Innovative Applications of Artificial Intelligence, IAAI 2022, The Twelveth Symposium on Educational Advances in Artificial Intelligence, EAAI 2022 Vi...
2022
-
[7]
An interpretable error correction method for enhancing code- to-code translation
Min Xue, Artur Andrzejak, and Marla Leuther. An interpretable error correction method for enhancing code- to-code translation. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024
2024
-
[8]
A joint learning model with variational interaction for multilingual program translation
Yali Du, Hui Sun, and Ming Li. A joint learning model with variational interaction for multilingual program translation. In Vladimir Filkov, Baishakhi Ray, and Minghui Zhou, editors,Proceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering, ASE 2024, Sacramento, CA, USA, October 27 - November 1, 2024, pages 1907–1918. ACM, 2024
2024
-
[9]
Finding compiler bugs through cross-language code generator and differential testing.Proc
Qiong Feng, Xiaotian Ma, Ziyuan Feng, Marat Akhin, Wei Song, and Peng Liang. Finding compiler bugs through cross-language code generator and differential testing.Proc. ACM Program. Lang., 9(OOPSLA2), October 2025
2025
-
[10]
Evolving paradigms in automated program repair: Taxonomy, challenges, and opportunities.ACM Comput
Kai Huang, Zhengzi Xu, Su Yang, Hongyu Sun, Xuejun Li, Zheng Yan, and Yuqing Zhang. Evolving paradigms in automated program repair: Taxonomy, challenges, and opportunities.ACM Comput. Surv., 57(2), October 2024
2024
-
[11]
Knowledge transfer from high-resource to low-resource programming languages for code llms.Proc
Federico Cassano, John Gouwar, Francesca Lucchetti, Claire Schlesinger, Anders Freeman, Carolyn Jane An- derson, Molly Q Feldman, Michael Greenberg, Abhinav Jangda, and Arjun Guha. Knowledge transfer from high-resource to low-resource programming languages for code llms.Proc. ACM Program. Lang., 8(OOPSLA2), October 2024
2024
-
[12]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdvances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, December 4-9, 2017, Long Beach, CA, USA, pages 5998–6008, 2017
2017
-
[13]
Codebert: A pre-trained model for programming and natural languages
Zhangyin Feng, Daya Guo, Duyu Tang, Nan Duan, Xiaocheng Feng, Ming Gong, Linjun Shou, Bing Qin, Ting Liu, Daxin Jiang, and Ming Zhou. Codebert: A pre-trained model for programming and natural languages. In Findings of the Association for Computational Linguistics: EMNLP 2020, Online Event, 16-20 November 2020, volume EMNLP 2020 ofFindings of ACL, pages 15...
2020
-
[14]
Lost in translation: A study of bugs introduced by large language models while translating code
Rangeet Pan, Ali Reza Ibrahimzada, Rahul Krishna, Divya Sankar, Lambert Pouguem Wassi, Michele Merler, Boris Sobolev, Raju Pavuluri, Saurabh Sinha, and Reyhaneh Jabbarvand. Lost in translation: A study of bugs introduced by large language models while translating code. InProceedings of the 46th IEEE/ACM International Conference on Software Engineering, IC...
2024
-
[15]
Lever- aging automated unit tests for unsupervised code translation
Baptiste Rozière, Jie Zhang, François Charton, Mark Harman, Gabriel Synnaeve, and Guillaume Lample. Lever- aging automated unit tests for unsupervised code translation. InThe Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022. OpenReview.net, 2022
2022
-
[16]
Tree-to-tree neural networks for program translation
Xinyun Chen, Chang Liu, and Dawn Song. Tree-to-tree neural networks for program translation. InAdvances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems 2018, NeurIPS 2018, December 3-8, 2018, Montréal, Canada, pages 2552–2562, 2018
2018
-
[17]
Exploring and unleashing the power of large language models in automated code translation.Proc
Zhen Yang, Fang Liu, Zhongxing Yu, Jacky Wai Keung, Jia Li, Shuo Liu, Yifan Hong, Xiaoxue Ma, Zhi Jin, and Ge Li. Exploring and unleashing the power of large language models in automated code translation.Proc. ACM Softw. Eng., 1(FSE):1585–1608, 2024
2024
-
[18]
Alphatrans: A neuro-symbolic compositional approach for repository-level code translation and validation.Proc
Ali Reza Ibrahimzada, Kaiyao Ke, Mrigank Pawagi, Muhammad Salman Abid, Rangeet Pan, Saurabh Sinha, and Reyhaneh Jabbarvand. Alphatrans: A neuro-symbolic compositional approach for repository-level code translation and validation.Proc. ACM Softw. Eng., 2(FSE):2454–2476, 2025. 24 APREPRINT- JUNE11, 2026
2025
-
[19]
On codex prompt engineering for ocl generation: An empirical study
Seif Abukhalaf, Mohammad Hamdaqa, and Foutse Khomh. On codex prompt engineering for ocl generation: An empirical study. In2023 IEEE/ACM 20th International Conference on Mining Software Repositories (MSR), pages 148–157, 2023
2023
-
[20]
Gunter.Semantics of programming languages - structures and techniques
Carl A. Gunter.Semantics of programming languages - structures and techniques. Foundations of computing. MIT Press, 1993
1993
-
[21]
Min, Gail E
Yangruibo Ding, Jinjun Peng, Marcus J. Min, Gail E. Kaiser, Junfeng Yang, and Baishakhi Ray. Semcoder: Training code language models with comprehensive semantics reasoning. In Amir Globersons, Lester Mackey, Danielle Belgrave, Angela Fan, Ulrich Paquet, Jakub M. Tomczak, and Cheng Zhang, editors,Advances in Neural Information Processing Systems 38: Annual...
2024
-
[22]
Domain adaptation for code model-based unit test case generation
Jiho Shin, Sepehr Hashtroudi, Hadi Hemmati, and Song Wang. Domain adaptation for code model-based unit test case generation. In Maria Christakis and Michael Pradel, editors,Proceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis, ISSTA 2024, Vienna, Austria, September 16-20, 2024, pages 1211–1222. ACM, 2024
2024
-
[23]
Code semantic enrichment for deep code search.J
Zhongyang Deng, Ling Xu, Chao Liu, Luwen Huangfu, and Meng Yan. Code semantic enrichment for deep code search.J. Syst. Softw., 207:111856, 2024
2024
-
[24]
Method-level test-to-code traceability link construction by semantic correlation learning.IEEE Trans
Weifeng Sun, Zhenting Guo, Meng Yan, Zhongxin Liu, Yan Lei, and Hongyu Zhang. Method-level test-to-code traceability link construction by semantic correlation learning.IEEE Trans. Software Eng., 50(10):2656–2676, 2024
2024
-
[25]
TIT: A tree- structured instruction tuning approach for llm-based code translation, 2025
He Jiang, Yufu Wang, Hao Lin, Peiyu Zou, Zhide Zhou, Ang Jia, Xiaochen Li, and Zhilei Ren. TIT: A tree- structured instruction tuning approach for llm-based code translation, 2025
2025
-
[26]
Ming Zhu, Aneesh Jain, Karthik Suresh, Roshan Ravindran, Sindhu Tipirneni, and Chandan K. Reddy. Xlcost: A benchmark dataset for cross-lingual code intelligence.CoRR, abs/2206.08474, 2022
arXiv 2022
-
[27]
Few-shot code translation via task-adapted prompt learning.J
Xuan Li, Shuai Yuan, Xiaodong Gu, Yuting Chen, and Beijun Shen. Few-shot code translation via task-adapted prompt learning.J. Syst. Softw., 212:112002, 2024
2024
-
[28]
Saiful Bari, Xuan Do Long, Weishi Wang, Md
Mohammad Abdullah Matin Khan, M. Saiful Bari, Xuan Do Long, Weishi Wang, Md. Rizwan Parvez, and Shafiq Joty. Xcodeeval: An execution-based large scale multilingual multitask benchmark for code understanding, generation, translation and retrieval. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors,Proceedings of the 62nd Annual Meeting of the Associ...
2024
-
[29]
FAMO: fast adaptive multitask optimization
Bo Liu, Yihao Feng, Peter Stone, and Qiang Liu. FAMO: fast adaptive multitask optimization. In Alice Oh, Tristan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, and Sergey Levine, editors,Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 1...
2023
-
[30]
Mftcoder: Boosting code llms with multitask fine-tuning
Bingchang Liu, Chaoyu Chen, Zi Gong, Cong Liao, Huan Wang, Zhichao Lei, Ming Liang, Dajun Chen, Min Shen, Hailian Zhou, Wei Jiang, Hang Yu, and Jianguo Li. Mftcoder: Boosting code llms with multitask fine-tuning. In Ricardo Baeza-Yates and Francesco Bonchi, editors,Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, KDD 2...
2024
-
[31]
Misleading authorship attribution of source code using adversarial learning
Erwin Quiring, Alwin Maier, and Konrad Rieck. Misleading authorship attribution of source code using adversarial learning. In Nadia Heninger and Patrick Traynor, editors,28th USENIX Security Symposium, USENIX Security 2019, Santa Clara, CA, USA, August 14-16, 2019, pages 479–496. USENIX Association, 2019
2019
-
[32]
Contrastive code representation learning
Paras Jain, Ajay Jain, Tianjun Zhang, Pieter Abbeel, Joseph Gonzalez, and Ion Stoica. Contrastive code representation learning. In Marie-Francine Moens, Xuanjing Huang, Lucia Specia, and Scott Wen-tau Yih, editors,Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, EMNLP 2021, Virtual Event / Punta Cana, Dominican Repub...
2021
-
[33]
Qinkai Zheng, Xiao Xia, Xu Zou, Yuxiao Dong, Shan Wang, Yufei Xue, Zihan Wang, Lei Shen, Andi Wang, Yang Li, Teng Su, Zhilin Yang, and Jie Tang. Codegeex: A pre-trained model for code generation with multilingual evaluations on humaneval-x.CoRR, abs/2303.17568, 2023
arXiv 2023
-
[34]
DeepSeek-AI, Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, Damai Dai, Daya Guo, Dejian Yang, Deli Chen, Dongjie Ji, Erhang Li, Fangyun Lin, Fucong Dai, Fuli Luo, Guangbo Hao, Guanting Chen, Guowei Li, H. Zhang, Han Bao, Hanwei Xu, Haocheng Wang, Haowei Zhang, Honghui Ding, Huaj...
Pith/arXiv arXiv 2026
-
[35]
GPT-4 technical report.CoRR, abs/2303.08774, 2023
OpenAI. GPT-4 technical report.CoRR, abs/2303.08774, 2023
Pith/arXiv arXiv 2023
-
[36]
Qwen2.5 technical report, 2025
Qwen, :, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li,...
2025
-
[37]
Qwen2.5-coder technical report.CoRR, abs/2409.12186, 2024
Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jiajun Zhang, Bowen Yu, Kai Dang, An Yang, Rui Men, Fei Huang, Xingzhang Ren, Xuancheng Ren, Jingren Zhou, and Junyang Lin. Qwen2.5-coder technical report.CoRR, abs/2409.12186, 2024
Pith/arXiv arXiv 2024
-
[38]
Anton Lozhkov, Raymond Li, Loubna Ben Allal, Federico Cassano, Joel Lamy-Poirier, Nouamane Tazi, Ao Tang, Dmytro Pykhtar, Jiawei Liu, Yuxiang Wei, Tianyang Liu, Max Tian, Denis Kocetkov, Arthur Zucker, Younes Belkada, Zijian Wang, Qian Liu, Dmitry Abulkhanov, Indraneil Paul, Zhuang Li, Wen-Ding Li, Megan Risdal, Jia Li, Jian Zhu, Terry Yue Zhuo, Evgenii Z...
Pith/arXiv arXiv 2024
-
[39]
DOBF: A deobfuscation pre-training objective for programming languages
Marie-Anne Lachaux, Baptiste Rozière, Marc Szafraniec, and Guillaume Lample. DOBF: A deobfuscation pre-training objective for programming languages. InAdvances in Neural Information Processing Systems 34: Annual Conference on Neural Information Processing Systems 2021, NeurIPS 2021, December 6-14, 2021, virtual, pages 14967–14979, 2021
2021
-
[40]
Code translation with compiler representations
Marc Szafraniec, Baptiste Rozière, Hugh Leather, Patrick Labatut, François Charton, and Gabriel Synnaeve. Code translation with compiler representations. InThe Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net, 2023
2023
-
[41]
INTERTRANS: leveraging transitive intermediate translations to enhance llm-based code translation
Marcos Macedo, Yuan Tian, Pengyu Nie, Filipe Roseiro Côgo, and Bram Adams. INTERTRANS: leveraging transitive intermediate translations to enhance llm-based code translation. In47th IEEE/ACM International Conference on Software Engineering, ICSE 2025, Ottawa, ON, Canada, April 26 - May 6, 2025, pages 1153–1164. IEEE, 2025
2025
-
[42]
Codebleu: a method for automatic evaluation of code synthesis.CoRR, abs/2009.10297, 2020
Shuo Ren, Daya Guo, Shuai Lu, Long Zhou, Shujie Liu, Duyu Tang, Neel Sundaresan, Ming Zhou, Ambrosio Blanco, and Shuai Ma. Codebleu: a method for automatic evaluation of code synthesis.CoRR, abs/2009.10297, 2020
Pith/arXiv arXiv 2009
-
[43]
Qihao Zhu, Daya Guo, Zhihong Shao, Dejian Yang, Peiyi Wang, Runxin Xu, Y Wu, Yukun Li, Huazuo Gao, Shirong Ma, et al. Deepseek-coder-v2: Breaking the barrier of closed-source models in code intelligence.arXiv preprint arXiv:2406.11931, 2024
Pith/arXiv arXiv 2024
-
[44]
Function-to-style guidance of LLMs for code translation
Longhui Zhang, Bin Wang, Jiahao Wang, Xiaofeng Zhao, Min Zhang, Hao Yang, Meishan Zhang, Yu Li, Jing Li, Jun Yu, and Min Zhang. Function-to-style guidance of LLMs for code translation. In Aarti Singh, Maryam Fazel, Daniel Hsu, Simon Lacoste-Julien, Felix Berkenkamp, Tegan Maharaj, Kiri Wagstaff, and Jerry Zhu, editors, Proceedings of the 42nd Internationa...
2025
-
[45]
Effireasontrans: Rl-optimized reasoning for code translation, 2025
Yanlin Wang, Rongyi Ou, Yanli Wang, Mingwei Liu, Jiachi Chen, Ensheng Shi, Xilin Liu, Yuchi Ma, and Zibin Zheng. Effireasontrans: Rl-optimized reasoning for code translation, 2025
2025
-
[46]
Beyond code pairs: Dialogue-based data generation for llm code translation, 2025
Le Chen, Nuo Xu, Winson Chen, Bin Lei, Pei-Hung Lin, Dunzhi Zhou, Rajeev Thakur, Caiwen Ding, Ali Jannesari, and Chunhua Liao. Beyond code pairs: Dialogue-based data generation for llm code translation, 2025. 26 APREPRINT- JUNE11, 2026
2025
-
[47]
Syncobert: Syntax-guided multi-modal contrastive pre-training for code representation, 2021
Xin Wang, Yasheng Wang, Fei Mi, Pingyi Zhou, Yao Wan, Xiao Liu, Li Li, Hao Wu, Jin Liu, and Xin Jiang. Syncobert: Syntax-guided multi-modal contrastive pre-training for code representation, 2021
2021
-
[48]
Syntax and domain aware model for unsupervised program translation
Fang Liu, Jia Li, and Li Zhang. Syntax and domain aware model for unsupervised program translation. In45th IEEE/ACM International Conference on Software Engineering, ICSE 2023, Melbourne, Australia, May 14-20, 2023, pages 755–767. IEEE, 2023
2023
-
[49]
Clement, and Neel Sundaresan
Yufan Huang, Mengnan Qi, Yongqiang Yao, Maoquan Wang, Bin Gu, Colin B. Clement, and Neel Sundaresan. Program translation via code distillation. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, EMNLP 2023, Singapore, December 6-10, 2023, pages 10903–10914. Association for Computational Linguistics, 2023
2023
-
[50]
Babelcoder: Agentic code translation with specification alignment.CoRR, abs/2512.06902, 2025
Fazle Rabbi, Soumit Kanti Saha, Tri Minh Triet Pham, Song Wang, and Jinqiu Yang. Babelcoder: Agentic code translation with specification alignment.CoRR, abs/2512.06902, 2025
arXiv 2025
-
[51]
Program skeletons for automated program translation.Proc
Bo Wang, Tianyu Li, Ruishi Li, Umang Mathur, and Prateek Saxena. Program skeletons for automated program translation.Proc. ACM Program. Lang., 9(PLDI), June 2025
2025
-
[52]
Execoder: Empowering large language models with executability representation for code translation
Minghua He, Fangkai Yang, Pu Zhao, Wenjie Yin, Yu Kang, Qingwei Lin, Saravan Rajmohan, Dongmei Zhang, and Qi Zhang. Execoder: Empowering large language models with executability representation for code translation. CoRR, abs/2501.18460, 2025
arXiv 2025
-
[53]
Chaofan Wang, Tingrui Yu, Jie Wang, Dong Chen, Wenrui Zhang, Yuling Shi, Xiaodong Gu, and Beijun Shen. EVOC2RUST: A skeleton-guided framework for project-level c-to-rust translation.CoRR, abs/2508.04295, 2025
arXiv 2025
-
[54]
Parameter-efficient transfer learning for NLP
Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin de Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly. Parameter-efficient transfer learning for NLP. In Kamalika Chaudhuri and Ruslan Salakhutdinov, editors,Proceedings of the 36th International Conference on Machine Learning, ICML 2019, 9-15 June 2019, Long Beach, C...
2019
-
[55]
Based on the validation feedback, adjust the test cases for the function or specified API to resolve the reported issues
External API Comments and Test Cases [Code] [API List] A.2 Semantic Refinement Prompt Semantic Refinement Prompt You are an expert [Lang] developer and software engineer. Based on the validation feedback, adjust the test cases for the function or specified API to resolve the reported issues. [Target Function/API] [Corrective Signal] 27 APREPRINT- JUNE11, ...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.