Tac-DINO: Learning Vision-Tactile Features with Patch Alignment
Pith reviewed 2026-06-27 10:17 UTC · model grok-4.3
The pith
Tac-DINO learns vision-tactile features by aligning local patches rather than whole images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
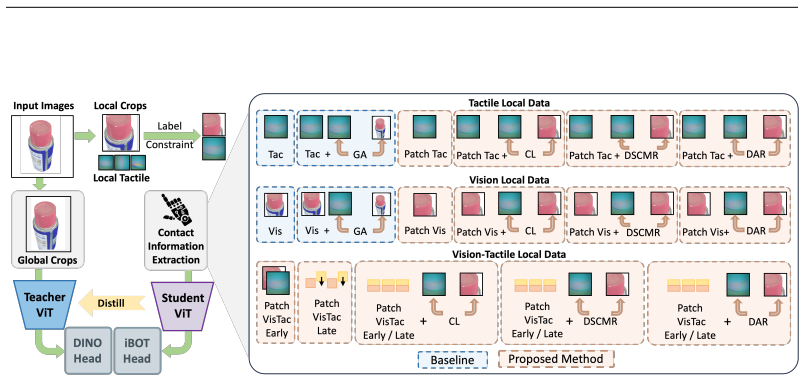
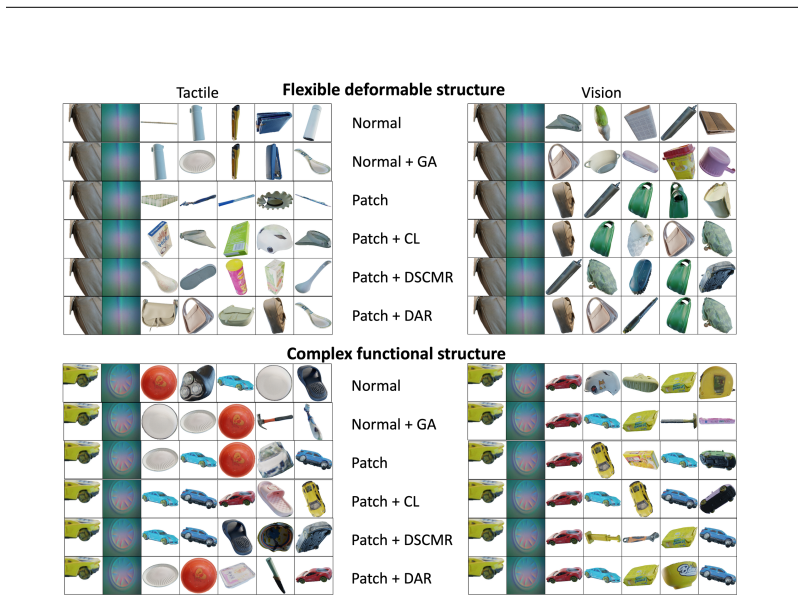
By building a large-scale tactile dataset and the Vis-Tac Holographic Matching Benchmark, the work proposes Vision-Tactile Patch Alignment (VTPA) methods in Tac-DINO for vision-tactile representation learning; experiments on the benchmark show these methods exceed the performance of approaches without alignment and produce features that align with whole-object images.
What carries the argument
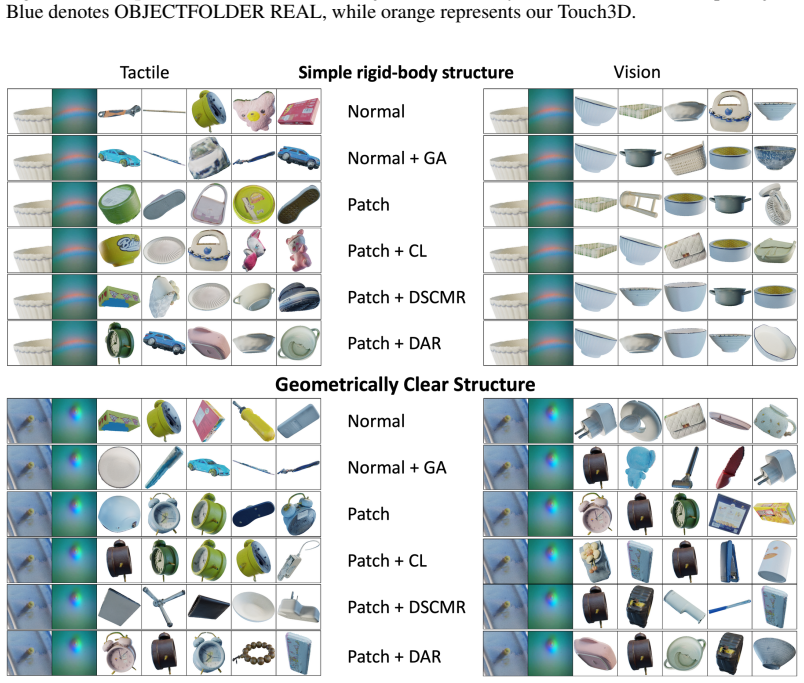
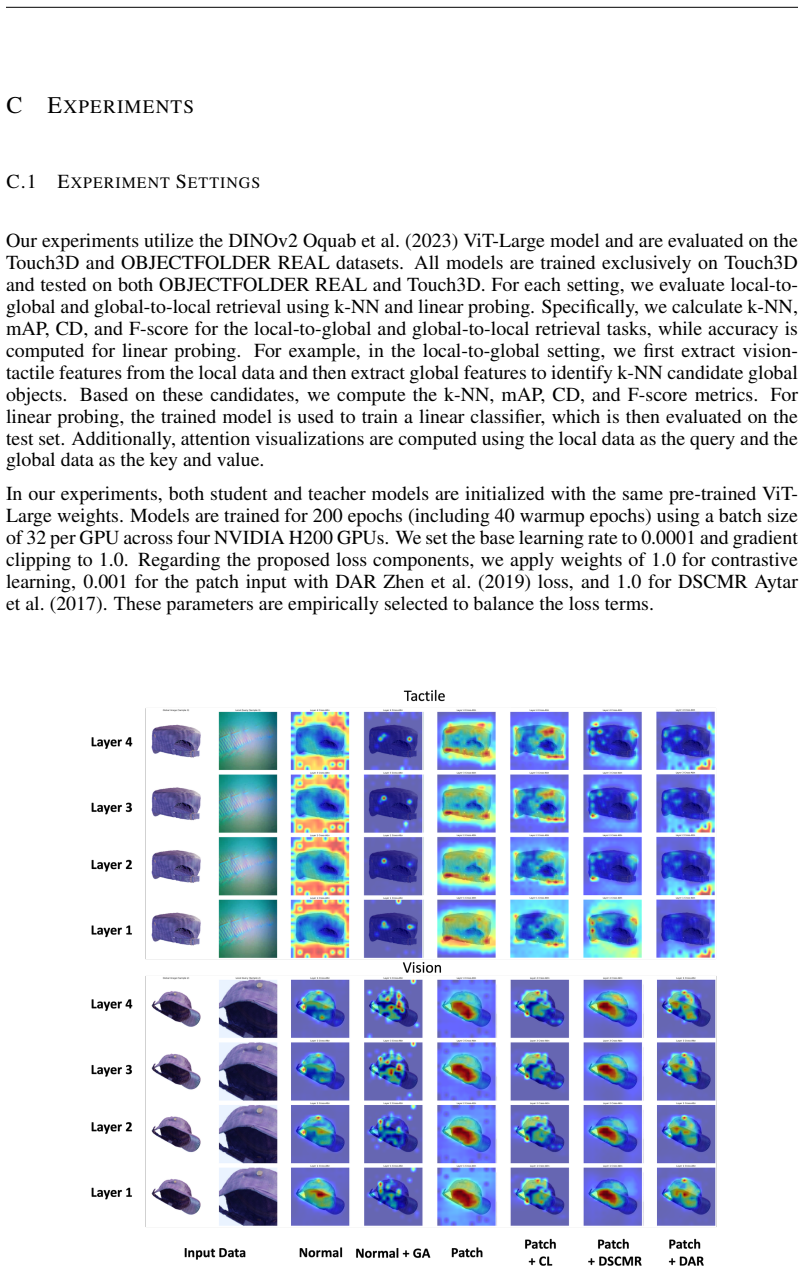
Vision-Tactile Patch Alignment (VTPA), the process of matching local tactile contact patches to corresponding visual patches to learn cross-modal features.
If this is right
- Tac-DINO exceeds the performance of methods without alignment on the Vis-Tac Holographic Matching Benchmark.
- The learned features align with whole-object images.
- Patch-level alignment enables local-to-global correspondence learning for vision-tactile data.
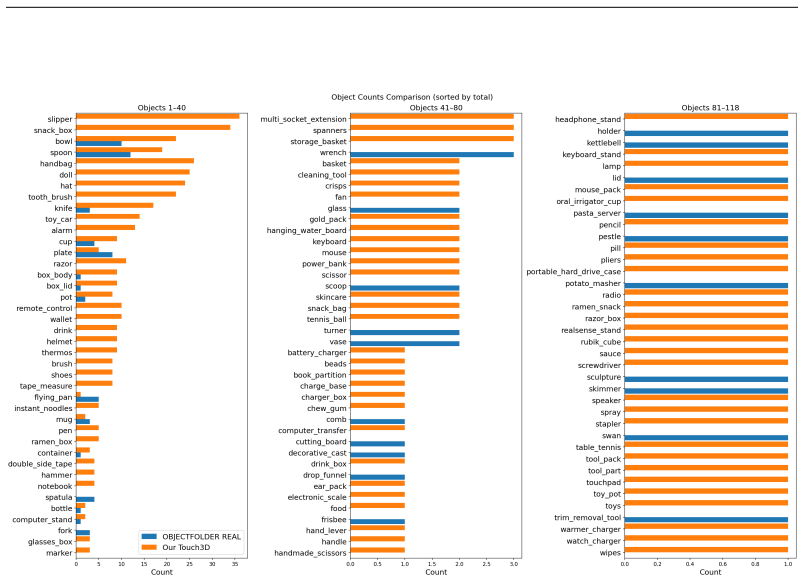
- The new dataset of over 20K contacts supports training of such alignment methods.
Where Pith is reading between the lines
- Robots could combine these features with partial touch observations to identify objects more reliably than with vision alone.
- The benchmark offers a standardized test for other cross-modal alignment techniques beyond the ones proposed here.
- Extensions to multi-contact or dynamic scenes might reveal whether patch alignment generalizes to real-time manipulation.
Load-bearing premise
The collected tactile dataset and holographic matching benchmark accurately capture the local-to-global correspondence problem real robotic systems face without biases from contact geometry or sensor calibration.
What would settle it
An evaluation on a held-out set of objects or a different tactile sensor where Tac-DINO shows no improvement over non-alignment methods.
Figures




read the original abstract
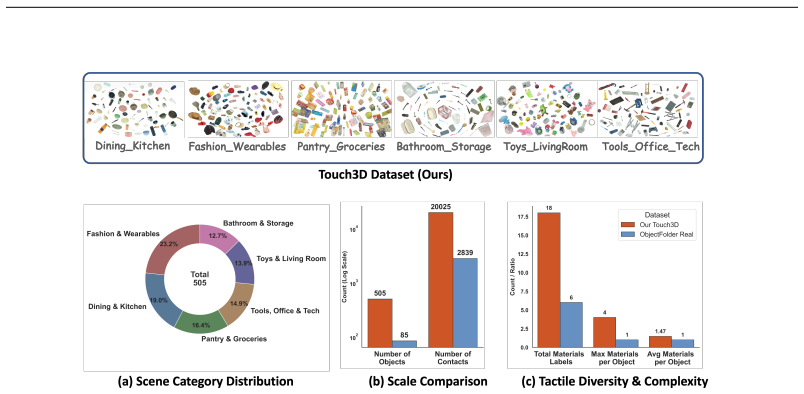
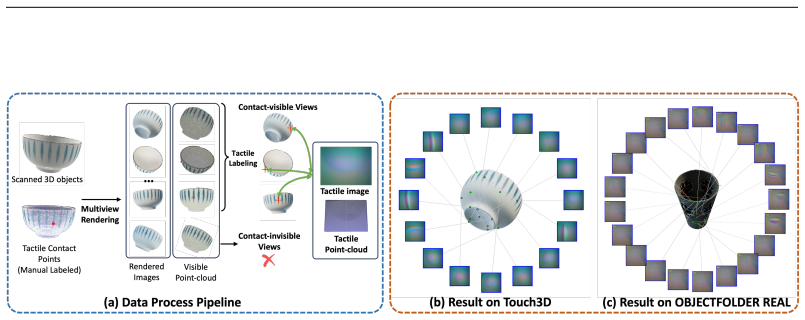
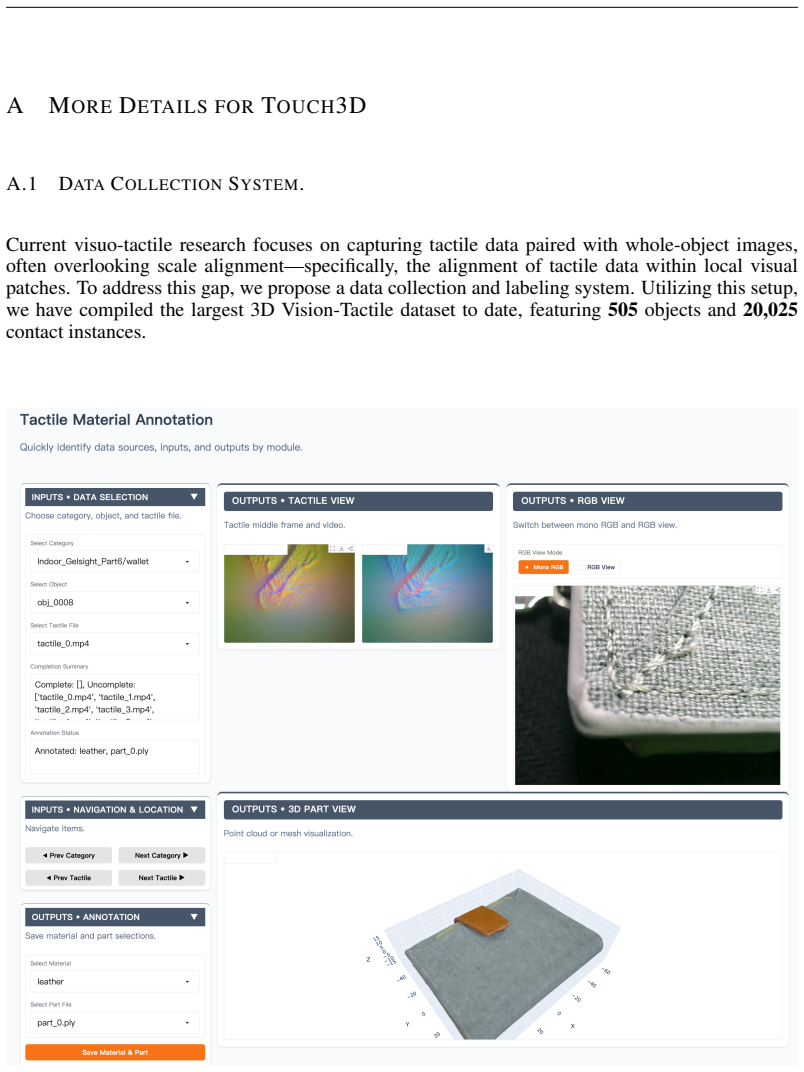
Touch is the primary medium through which humans interact with the environment. Currently, tactile learning mainly focuses on image-level pretraining or alignment. However, tactile signals correspond to local object contact, while research into scale alignment and holographic matching remains limited and proper datasets and benchmarks also lack. To bridge this gap, we first construct a data collection system to acquire a large-scale tactile dataset, with over 20 K tactile contacts from 505 real-world objects. Building on this dataset, we design a Vis-Tac Holographic Matching Benchmark to evaluate vision-tactile local-to-global alignment ability. Then we propose Vision-Tactile Patch Alignment (VTPA) methods for vision-tactile representation learning. Experiments demonstrate that these exceed the performance of methods without alignment and align with whole-object images.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a data collection system yielding a tactile dataset of over 20K contacts from 505 real-world objects, defines the Vis-Tac Holographic Matching Benchmark to assess local-to-global vision-tactile alignment, and proposes Vision-Tactile Patch Alignment (VTPA) methods for representation learning. It claims that VTPA outperforms non-alignment baselines and achieves performance comparable to whole-object image alignment.
Significance. If the experimental claims hold after standard controls, the dataset and benchmark would constitute useful resources for multimodal tactile-vision research, and the patch-alignment approach could clarify how local contact signals relate to global object structure in robotic perception.
major comments (2)
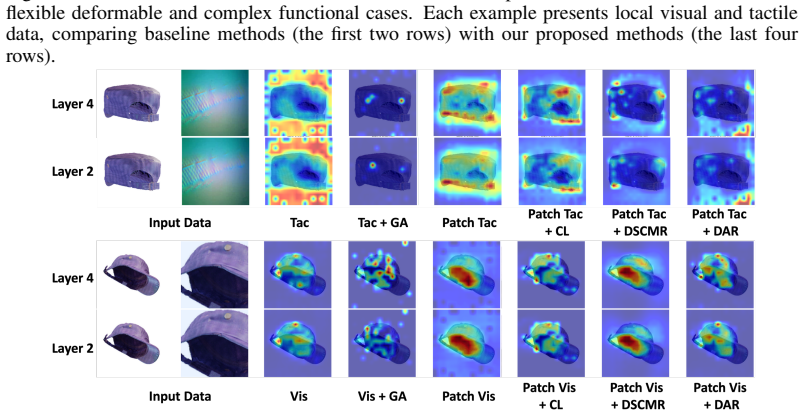
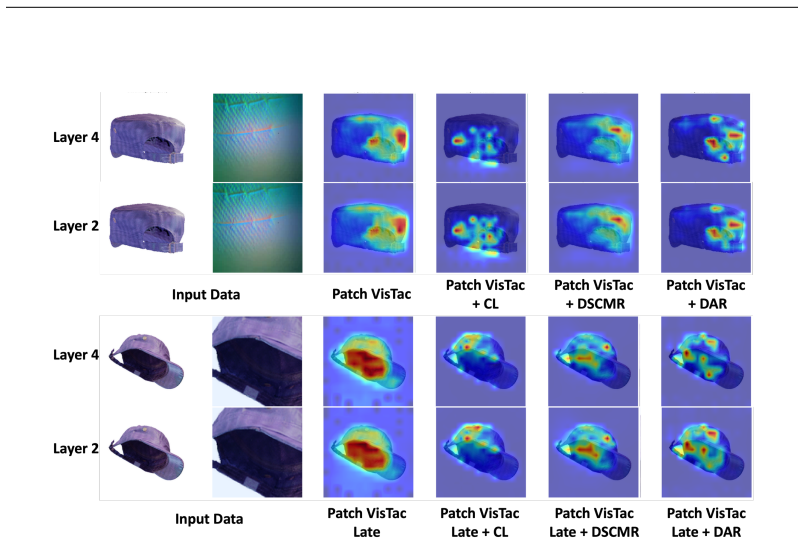
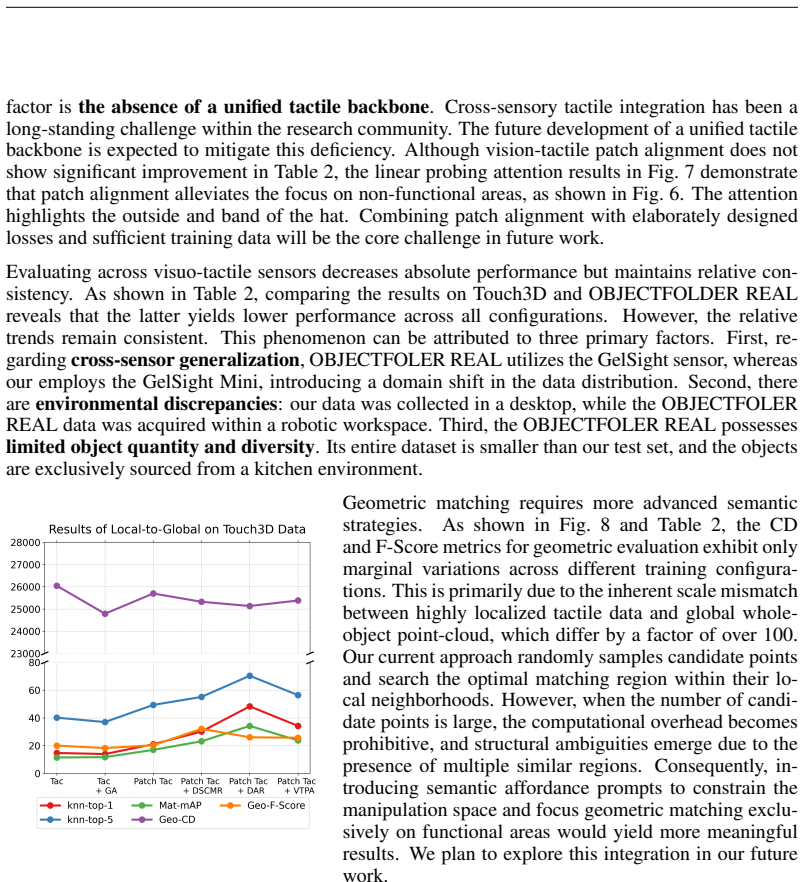
- [Abstract / Experiments] Abstract and Experiments section: the central claim that VTPA methods 'exceed the performance of methods without alignment' is stated without any quantitative metrics, ablation tables, error bars, or statistical tests, preventing verification that the reported gains survive standard controls for dataset bias or hyperparameter tuning.
- [Dataset and Benchmark] Dataset construction and Vis-Tac Holographic Matching Benchmark: the claim that superior benchmark numbers imply transferable local-to-global alignment capability rests on the untested assumption that the >20K-contact collection rig introduces no systematic distortions in contact geometry, force distribution, or sensor calibration; no cross-validation against external tactile corpora or sensitivity analysis to pose/pressure variations is described.
minor comments (1)
- [Abstract] Abstract: the phrase 'align with whole-object images' is ambiguous; clarify whether this refers to feature similarity, downstream task performance, or a specific metric.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to strengthen the presentation of results and dataset validation.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments section: the central claim that VTPA methods 'exceed the performance of methods without alignment' is stated without any quantitative metrics, ablation tables, error bars, or statistical tests, preventing verification that the reported gains survive standard controls for dataset bias or hyperparameter tuning.
Authors: We agree the abstract is high-level. The experiments section reports comparative results, but we will expand it in revision to include full ablation tables, quantitative metrics, error bars across runs, and statistical significance tests. This will allow direct verification that gains hold under controls for bias and hyperparameter choices. revision: yes
-
Referee: [Dataset and Benchmark] Dataset construction and Vis-Tac Holographic Matching Benchmark: the claim that superior benchmark numbers imply transferable local-to-global alignment capability rests on the untested assumption that the >20K-contact collection rig introduces no systematic distortions in contact geometry, force distribution, or sensor calibration; no cross-validation against external tactile corpora or sensitivity analysis to pose/pressure variations is described.
Authors: We recognize that additional validation would strengthen claims about the rig. In revision we will add sensitivity analyses for pose and pressure variations and, where feasible, cross-checks against available external tactile datasets to test for systematic distortions in geometry, force, or calibration. revision: yes
Circularity Check
No circularity: empirical dataset construction and benchmark evaluation with no self-referential derivations
full rationale
The paper describes an empirical pipeline: building a data collection system for a >20K-contact tactile dataset from 505 objects, designing a Vis-Tac Holographic Matching Benchmark, proposing VTPA methods for representation learning, and reporting experimental comparisons. No equations, fitted parameters presented as predictions, self-definitional constructs, or load-bearing self-citations appear in the provided text. The central claims rest on external data collection and standard performance metrics rather than any reduction of outputs to inputs by construction. This matches the default expectation for non-circular empirical work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Scaling Learning Algorithms Towards
Bengio, Yoshua and LeCun, Yann , booktitle =. Scaling Learning Algorithms Towards
-
[2]
and Osindero, Simon and Teh, Yee Whye , journal =
Hinton, Geoffrey E. and Osindero, Simon and Teh, Yee Whye , journal =. A Fast Learning Algorithm for Deep Belief Nets , volume =
-
[3]
2016 , publisher=
Deep learning , author=. 2016 , publisher=
2016
-
[4]
2024 IEEE International Conference on Robotics and Automation (ICRA) , pages=
Sim2real manipulation on unknown objects with tactile-based reinforcement learning , author=. 2024 IEEE International Conference on Robotics and Automation (ICRA) , pages=. 2024 , organization=
2024
-
[5]
IEEE Robotics and Automation Letters , year=
Dextouch: Learning to seek and manipulate objects with tactile dexterity , author=. IEEE Robotics and Automation Letters , year=
-
[6]
2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , pages=
Eyesight hand: Design of a fully-actuated dexterous robot hand with integrated vision-based tactile sensors and compliant actuation , author=. 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , pages=. 2024 , organization=
2024
-
[7]
2024 IEEE International Conference on Robotics and Automation (ICRA) , pages=
Generalize by touching: Tactile ensemble skill transfer for robotic furniture assembly , author=. 2024 IEEE International Conference on Robotics and Automation (ICRA) , pages=. 2024 , organization=
2024
-
[8]
arXiv preprint arXiv:2410.11834 , year=
Contrastive touch-to-touch pretraining , author=. arXiv preprint arXiv:2410.11834 , year=
-
[10]
arXiv preprint arXiv:2310.16917 , year=
Mimictouch: Leveraging multi-modal human tactile demonstrations for contact-rich manipulation , author=. arXiv preprint arXiv:2310.16917 , year=
-
[11]
arXiv preprint arXiv:2409.17549 , year=
Canonical representation and force-based pretraining of 3d tactile for dexterous visuo-tactile policy learning , author=. arXiv preprint arXiv:2409.17549 , year=
-
[12]
2025 IEEE International Conference on Robotics and Automation (ICRA) , pages=
Contrastive touch-to-touch pretraining , author=. 2025 IEEE International Conference on Robotics and Automation (ICRA) , pages=. 2025 , organization=
2025
-
[14]
arXiv preprint arXiv:2405.02794 , year=
Octopi: Object property reasoning with large tactile-language models , author=. arXiv preprint arXiv:2405.02794 , year=
-
[15]
arXiv preprint arXiv:2507.09985 , year=
Demonstrating the Octopi-1.5 Visual-Tactile-Language Model , author=. arXiv preprint arXiv:2507.09985 , year=
-
[16]
Information Fusion , pages=
Touch100k: A large-scale touch-language-vision dataset for touch-centric multimodal representation , author=. Information Fusion , pages=. 2025 , publisher=
2025
-
[17]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
The objectfolder benchmark: Multisensory learning with neural and real objects , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[18]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Tactile-augmented radiance fields , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[19]
2022 International Conference on Robotics and Automation (ICRA) , pages=
Gelslim 3.0: High-resolution measurement of shape, force and slip in a compact tactile-sensing finger , author=. 2022 International Conference on Robotics and Automation (ICRA) , pages=. 2022 , organization=
2022
-
[20]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Objaverse: A universe of annotated 3d objects , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[21]
Advances in Neural Information Processing Systems , volume=
Objaverse-xl: A universe of 10m+ 3d objects , author=. Advances in Neural Information Processing Systems , volume=
-
[22]
IEEE Robotics and Automation Letters , year=
9dtact: A compact vision-based tactile sensor for accurate 3d shape reconstruction and generalizable 6d force estimation , author=. IEEE Robotics and Automation Letters , year=
-
[23]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
From isolated islands to pangea: Unifying semantic space for human action understanding , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[24]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Beyond object recognition: A new benchmark towards object concept learning , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[25]
Computer Vision--ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13 , pages=
Microsoft coco: Common objects in context , author=. Computer Vision--ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13 , pages=. 2014 , organization=
2014
-
[26]
arXiv preprint arXiv:1512.03012 , year=
Shapenet: An information-rich 3d model repository , author=. arXiv preprint arXiv:1512.03012 , year=
-
[27]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Abo: Dataset and benchmarks for real-world 3d object understanding , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[28]
2022 International Conference on Robotics and Automation (ICRA) , pages=
Google scanned objects: A high-quality dataset of 3d scanned household items , author=. 2022 International Conference on Robotics and Automation (ICRA) , pages=. 2022 , organization=
2022
-
[29]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Omniobject3d: Large-vocabulary 3d object dataset for realistic perception, reconstruction and generation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[30]
Sensors , volume=
Gelsight: High-resolution robot tactile sensors for estimating geometry and force , author=. Sensors , volume=. 2017 , publisher=
2017
-
[31]
2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , pages=
GelTip: A finger-shaped optical tactile sensor for robotic manipulation , author=. 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , pages=. 2020 , organization=
2020
-
[32]
2020 IEEE International Conference on Robotics and Automation (ICRA) , pages=
Omnitact: A multi-directional high-resolution touch sensor , author=. 2020 IEEE International Conference on Robotics and Automation (ICRA) , pages=. 2020 , organization=
2020
-
[33]
2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , pages=
Improved gelsight tactile sensor for measuring geometry and slip , author=. 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , pages=. 2017 , organization=
2017
-
[35]
2013 World Haptics Conference (WHC) , pages=
Tactile sensing over articulated joints with stretchable sensors , author=. 2013 World Haptics Conference (WHC) , pages=. 2013 , organization=
2013
-
[37]
2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , pages=
Adaptive visuo-tactile fusion with predictive force attention for dexterous manipulation , author=. 2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , pages=. 2025 , organization=
2025
-
[41]
2025 IEEE International Conference on Robotics and Automation (ICRA) , pages=
Anyskin: Plug-and-play skin sensing for robotic touch , author=. 2025 IEEE International Conference on Robotics and Automation (ICRA) , pages=. 2025 , organization=
2025
-
[42]
Science Robotics , volume=
NeuralFeels with neural fields: Visuotactile perception for in-hand manipulation , author=. Science Robotics , volume=. 2024 , publisher=
2024
-
[44]
2024 IEEE International Conference on Robotics and Automation (ICRA) , pages=
Robot synesthesia: In-hand manipulation with visuotactile sensing , author=. 2024 IEEE International Conference on Robotics and Automation (ICRA) , pages=. 2024 , organization=
2024
-
[48]
IEEE Robotics and Automation Letters , volume=
Tacipc: Intersection-and inversion-free fem-based elastomer simulation for optical tactile sensors , author=. IEEE Robotics and Automation Letters , volume=. 2024 , publisher=
2024
-
[49]
The Fourteenth International Conference on Learning Representations , year=
TaCo: A Benchmark for Lossless and Lossy Codecs of Heterogeneous Tactile Data , author=. The Fourteenth International Conference on Learning Representations , year=
-
[50]
Sensors , volume=
Flexible tactile sensing based on piezoresistive composites: A review , author=. Sensors , volume=. 2014 , publisher=
2014
-
[51]
Nature , volume=
Learning the signatures of the human grasp using a scalable tactile glove , author=. Nature , volume=. 2019 , publisher=
2019
-
[52]
Smart Materials and Structures , volume=
Stretch not flex: programmable rubber keyboard , author=. Smart Materials and Structures , volume=. 2016 , publisher=
2016
-
[53]
Proceedings of the 33rd annual acm symposium on user interface software and technology , pages=
Capacitivo: Contact-based object recognition on interactive fabrics using capacitive sensing , author=. Proceedings of the 33rd annual acm symposium on user interface software and technology , pages=
-
[54]
ACM Transactions on Graphics (TOG) , volume=
Deformation capture via soft and stretchable sensor arrays , author=. ACM Transactions on Graphics (TOG) , volume=. 2019 , publisher=
2019
-
[55]
Nature neuroscience , volume=
Extrastriate body area in human occipital cortex responds to the performance of motor actions , author=. Nature neuroscience , volume=. 2004 , publisher=
2004
-
[57]
arXiv preprint arXiv:2601.20239 , year=
TouchGuide: Inference-Time Steering of Visuomotor Policies via Touch Guidance , author=. arXiv preprint arXiv:2601.20239 , year=
-
[58]
International Conference on Intelligent Robotics and Applications , pages=
MC-TAC: Modular camera-based tactile sensor for robot gripper , author=. International Conference on Intelligent Robotics and Applications , pages=. 2023 , organization=
2023
-
[59]
Neuron , volume=
Topographic representation of the human body in the occipitotemporal cortex , author=. Neuron , volume=. 2010 , publisher=
2010
-
[60]
Nature , volume=
Vicarious body maps bridge vision and touch in the human brain , author=. Nature , volume=
-
[61]
IEEE Robotics and Automation Letters , year=
Tactile-driven dexterous in-hand writing via extrinsic contact sensing , author=. IEEE Robotics and Automation Letters , year=
-
[62]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Binding touch to everything: Learning unified multimodal tactile representations , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[65]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Deep supervised cross-modal retrieval , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[67]
Advances in Neural Information Processing Systems , volume=
Tactile dreamfusion: Exploiting tactile sensing for 3d generation , author=. Advances in Neural Information Processing Systems , volume=
-
[68]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Structured 3d latents for scalable and versatile 3d generation , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[69]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Vggt: Visual geometry grounded transformer , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[72]
First conference on language modeling , year=
Mamba: Linear-time sequence modeling with selective state spaces , author=. First conference on language modeling , year=
-
[73]
European Conference on Computer Vision , pages=
Pace: A large-scale dataset with pose annotations in cluttered environments , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[75]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Weakly-Supervised Learning of Dense Functional Correspondences , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[76]
Sensors , volume=
Design and evaluation of a rapid monolithic manufacturing technique for a novel vision-based tactile sensor: C-Sight , author=. Sensors , volume=. 2024 , publisher=
2024
-
[78]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Objectfolder 2.0: A multisensory object dataset for sim2real transfer , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[79]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Revisiting point cloud classification: A new benchmark dataset and classification model on real-world data , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[80]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Scannet: Richly-annotated 3d reconstructions of indoor scenes , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[81]
2016 fourth international conference on 3D vision (3DV) , pages=
Scenenn: A scene meshes dataset with annotations , author=. 2016 fourth international conference on 3D vision (3DV) , pages=. 2016 , organization=
2016
-
[82]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Image-to-image translation with conditional adversarial networks , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[83]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Connecting touch and vision via cross-modal prediction , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[84]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Ulip-2: Towards scalable multimodal pre-training for 3d understanding , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[85]
arXiv preprint arXiv:2402.13232 , year=
A touch, vision, and language dataset for multimodal alignment , author=. arXiv preprint arXiv:2402.13232 , year=
-
[86]
Proceedings of the 24th annual conference on Computer graphics and interactive techniques , pages=
Surface simplification using quadric error metrics , author=. Proceedings of the 24th annual conference on Computer graphics and interactive techniques , pages=
-
[87]
Blender Foundation , title =
-
[88]
ACM SIGGRAPH 2024 Conference Papers , pages=
Part123: part-aware 3d reconstruction from a single-view image , author=. ACM SIGGRAPH 2024 Conference Papers , pages=
2024
-
[89]
arXiv preprint arXiv:2411.07184 , year=
Sampart3d: Segment any part in 3d objects , author=. arXiv preprint arXiv:2411.07184 , year=
-
[90]
Sensor fusion IV: control paradigms and data structures , volume=
Method for registration of 3-D shapes , author=. Sensor fusion IV: control paradigms and data structures , volume=. 1992 , organization=
1992
-
[93]
Langley , title =
P. Langley , title =. Proceedings of the 17th International Conference on Machine Learning (ICML 2000) , address =. 2000 , pages =
2000
-
[94]
T. M. Mitchell. The Need for Biases in Learning Generalizations. 1980
1980
-
[95]
M. J. Kearns , title =
-
[96]
Machine Learning: An Artificial Intelligence Approach, Vol. I. 1983
1983
-
[97]
R. O. Duda and P. E. Hart and D. G. Stork. Pattern Classification. 2000
2000
-
[98]
Suppressed for Anonymity , author=
-
[99]
Newell and P
A. Newell and P. S. Rosenbloom. Mechanisms of Skill Acquisition and the Law of Practice. Cognitive Skills and Their Acquisition. 1981
1981
-
[100]
A. L. Samuel. Some Studies in Machine Learning Using the Game of Checkers. IBM Journal of Research and Development. 1959
1959
-
[101]
2022 , eprint=
DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection , author=. 2022 , eprint=
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.