Verifiable Environments Are LEGO Bricks: Recursive Composition for Reasoning Generalization
Pith reviewed 2026-06-27 09:57 UTC · model grok-4.3
The pith
RACES shows that verifiable environments can be recursively fused like LEGO bricks when output types match input types, scaling LLM reasoning training efficiently.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
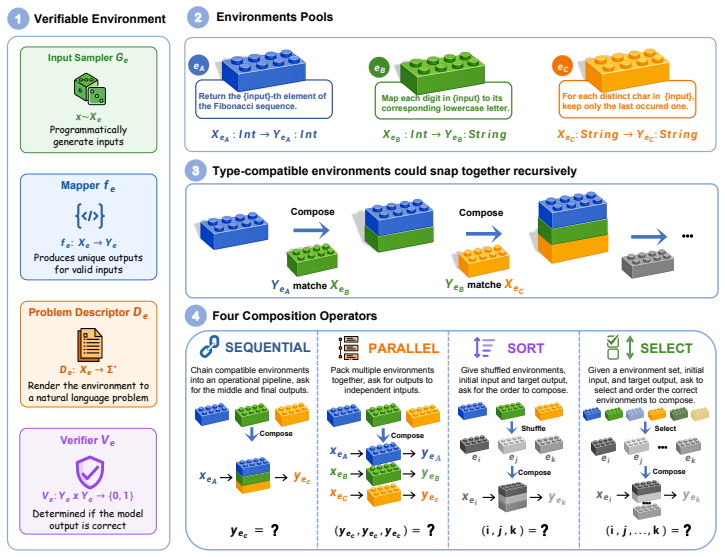
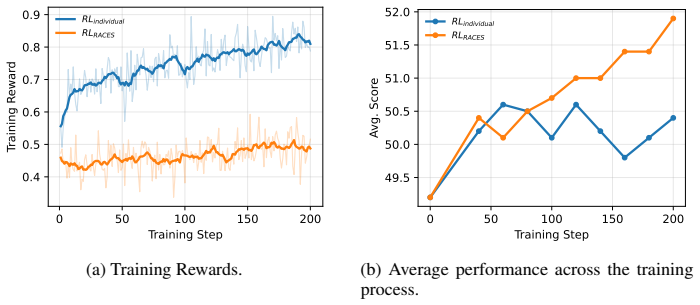
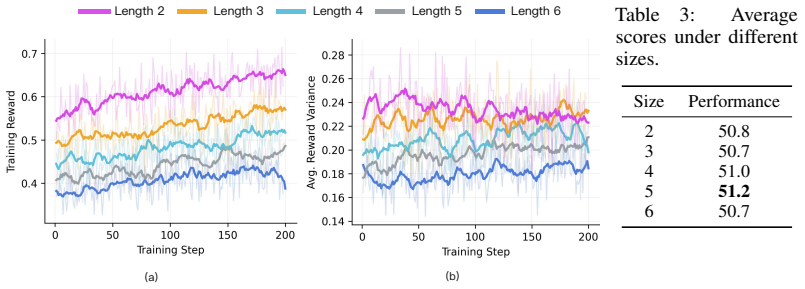
RACES treats verifiable environments as composable building blocks that fuse recursively whenever the codomain of one matches the domain of another, preserving verifiability through defined operators that generate new training instances; training large language models via reinforcement learning on the resulting composites yields consistent reasoning improvements on six unseen benchmarks and reaches performance levels comparable to training on 300 separate environments when starting from only 50 base ones.
What carries the argument
Type-matching fusion that automatically assembles new verifiable environments from existing ones via the SEQUENTIAL, PARALLEL, SORT, and SELECT operators.
If this is right
- Reinforcement learning on the composite environments improves reasoning generalization on benchmarks unseen during construction.
- DeepSeek-R1-Distill-Qwen-14B gains an average of 3.1 points across the benchmarks.
- Qwen3-14B rises from 58.8 to 61.1 on the same benchmarks.
- Comparable results to training on 300 individual environments are obtained from only 50 base environments.
Where Pith is reading between the lines
- The method could allow systematic generation of training tasks whose complexity grows with each composition layer rather than requiring new manual design.
- It may transfer to any setting that supplies verifiable outcome signals, such as theorem proving or structured data manipulation.
- Models exposed to fused patterns might internalize reasoning steps that do not appear in the original base set.
- The efficiency gain suggests that environment libraries could be maintained at modest size while still supporting large-scale training runs.
Load-bearing premise
Matching the output type of one environment to the input type of another allows automatic fusion that keeps the new environment verifiable and creates useful reasoning variety.
What would settle it
A direct check would be whether a fused environment still admits automatic verification of correct answers and whether reinforcement learning on the composites fails to produce the reported score gains on the six held-out benchmarks.
Figures
read the original abstract
Reinforcement Learning (RL) with verifiable environments has emerged as a powerful approach for enhancing the reasoning capabilities of Large Language Models (LLMs). While prior research demonstrates that scaling environment quantity improves RL performance, existing manual or individual construction methods suffer from linear scaling limits, thereby hindering scalable reasoning generalization. This paper introduces RACES (\textbf{R}ecursive \textbf{A}utomated \textbf{C}omposition for \textbf{E}nvironment \textbf{S}caling), a framework that conceptualizes verifiable environments as composable building blocks that can be recursively assembled. The key insight is that when the codomain (output type) of one environment matches the domain (input type) of another, they can be automatically fused into a new verifiable environment, enabling recursive composition. RACES is implemented with 300 individual environments and defines a set of composition operators (\textsc{SEQUENTIAL}, \textsc{PARALLEL}, \textsc{SORT}, and \textsc{SELECT}) that induce diverse reasoning patterns. Extensive experiments show that RL training on these composite environments consistently enhances reasoning generalization. Specifically, RACES improves DeepSeek-R1-Distill-Qwen-14B by an average of 3.1 points (from 48.2 to 51.3) and boosts Qwen3-14B performance from 58.8 to 61.1 on six benchmarks, which are unseen during the construction of training environments. Moreover, RACES achieves performance comparable to training on 300 individual environments using only 50 base environments, demonstrating significant efficiency in environment utilization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RACES, a framework that treats verifiable environments as composable LEGO-like blocks for RL-based LLM reasoning training. It defines four operators (SEQUENTIAL, PARALLEL, SORT, SELECT) that automatically fuse environments when the codomain of one matches the domain of another, claiming this preserves verifiability and enables recursive scaling. Experiments reportedly show that training on composites derived from 50 base environments matches performance from 300 individual environments, yielding average gains of 3.1 points on DeepSeek-R1-Distill-Qwen-14B (48.2 to 51.3) and 2.3 points on Qwen3-14B (58.8 to 61.1) across six held-out benchmarks.
Significance. If the composition operators provably preserve verifiability and the reported efficiency and generalization gains hold under controlled conditions, the work would address a key bottleneck in scaling verifiable RL environments, potentially allowing broader application of environment-based reasoning training without linear growth in manual construction effort.
major comments (1)
- [Abstract, key insight paragraph] Abstract, key insight paragraph: the central claim states that type-matching 'automatically' fuses environments into a new verifiable environment. However, no inductive definition is supplied for the composite verification predicate (e.g., whether verify(SEQUENTIAL(E1,E2)) is defined as verify_E2(E1(output)) or an equivalent rule). Without this, it is unclear whether verifiability composes for arbitrary recursion depth, which directly underpins the scaling claim that 50 base environments suffice in place of 300.
minor comments (1)
- [Abstract] Abstract: performance numbers are given without reference to baselines, number of runs, error bars, or statistical tests; the six benchmarks are described as 'unseen' but no verification protocol is stated.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for a formal inductive definition of the composite verification predicate. This is a substantive point that strengthens the paper's central claim about recursive composition preserving verifiability. We will add the requested definition and a brief preservation argument in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract, key insight paragraph] Abstract, key insight paragraph: the central claim states that type-matching 'automatically' fuses environments into a new verifiable environment. However, no inductive definition is supplied for the composite verification predicate (e.g., whether verify(SEQUENTIAL(E1,E2)) is defined as verify_E2(E1(output)) or an equivalent rule). Without this, it is unclear whether verifiability composes for arbitrary recursion depth, which directly underpins the scaling claim that 50 base environments suffice in place of 300.
Authors: We agree that the manuscript lacks an explicit inductive definition of the composite verification predicate. In the revision we will insert a new subsection (likely 3.2) that supplies the missing inductive definition: verify(SEQUENTIAL(E1,E2))(x) ≜ verify_E2(E1(x)) when the codomain of E1 matches the domain of E2 (and analogously for PARALLEL, SORT, and SELECT, with appropriate conjunction or selection over the component predicates). We will also include a short inductive argument showing that if each base environment is verifiable then every finite-depth composite is verifiable. This directly addresses the concern about arbitrary recursion depth and thereby supports the efficiency claim that 50 base environments suffice. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper defines RACES via four explicit composition operators (SEQUENTIAL, PARALLEL, SORT, SELECT) and reports measured performance gains on six benchmarks held out from environment construction. The claim that type-matching enables automatic fusion into a new verifiable environment is presented as a definitional property of the operators rather than a derived result that reduces to fitted inputs or prior self-citations. No equations or sections show a prediction that is statistically forced by a subset fit, a self-citation load-bearing uniqueness theorem, or an ansatz smuggled via citation. The efficiency result (50 base environments matching 300 individual) is an empirical comparison, not a tautology. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
invented entities (1)
-
RACES composition operators (SEQUENTIAL, PARALLEL, SORT, SELECT)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Second Conference on Language Modeling , year=
Understanding R1-Zero-Like Training: A Critical Perspective , author=. Second Conference on Language Modeling , year=
-
[2]
Guo, Daya and Yang, Dejian and Zhang, Haowei and Song, Junxiao and Wang, Peiyi and Zhu, Qihao and Xu, Runxin and Zhang, Ruoyu and Ma, Shirong and Bi, Xiao and Zhang, Xiaokang and Yu, Xingkai and Wu, Yu and Wu, Z. F. and Gou, Zhibin and Shao, Zhihong and Li, Zhuoshu and Gao, Ziyi and Liu, Aixin and Xue, Bing and Wang, Bingxuan and Wu, Bochao and Feng, Bei ...
-
[3]
2024 , eprint=
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models , author=. 2024 , eprint=
2024
-
[4]
2025 , eprint=
Absolute Zero: Reinforced Self-play Reasoning with Zero Data , author=. 2025 , eprint=
2025
-
[5]
Does Reinforcement Learning Really Incentivize Reasoning Capacity in
Yang Yue and Zhiqi Chen and Rui Lu and Andrew Zhao and Zhaokai Wang and Yang Yue and Shiji Song and Gao Huang , booktitle=. Does Reinforcement Learning Really Incentivize Reasoning Capacity in. 2025 , url=
2025
-
[6]
arXiv preprint arXiv:2504.20571 , year=
Reinforcement Learning for Reasoning in Large Language Models with One Training Example , author=. arXiv preprint arXiv:2504.20571 , year=
-
[7]
The Fourteenth International Conference on Learning Representations , year=
DeepMath-103K: A Large-Scale, Challenging, Decontaminated, and Verifiable Mathematical Dataset for Advancing Reasoning , author=. The Fourteenth International Conference on Learning Representations , year=
-
[8]
2025 , eprint=
The Art of Scaling Reinforcement Learning Compute for LLMs , author=. 2025 , eprint=
2025
-
[9]
2025 , eprint=
Kimi k1.5: Scaling Reinforcement Learning with LLMs , author=. 2025 , eprint=
2025
-
[10]
2025 , eprint=
RLVE: Scaling Up Reinforcement Learning for Language Models with Adaptive Verifiable Environments , author=. 2025 , eprint=
2025
-
[11]
Position: Will we run out of data? Limits of
Pablo Villalobos and Anson Ho and Jaime Sevilla and Tamay Besiroglu and Lennart Heim and Marius Hobbhahn , booktitle=. Position: Will we run out of data? Limits of. 2024 , url=
2024
-
[12]
The Surprising Effectiveness of Negative Reinforcement in
Xinyu Zhu and Mengzhou Xia and Zhepei Wei and Wei-Lin Chen and Danqi Chen and Yu Meng , booktitle=. The Surprising Effectiveness of Negative Reinforcement in. 2025 , url=
2025
-
[13]
2025 , eprint=
VAPO: Efficient and Reliable Reinforcement Learning for Advanced Reasoning Tasks , author=. 2025 , eprint=
2025
-
[14]
R-Zero: Self-Evolving Reasoning
Chengsong Huang and Wenhao Yu and Xiaoyang Wang and Hongming Zhang and Zongxia Li and Ruosen Li and Jiaxin Huang and Haitao Mi and Dong Yu , booktitle=. R-Zero: Self-Evolving Reasoning. 2026 , url=
2026
-
[15]
Beyond Pass@ 1: Self-Play with Variational Problem Synthesis Sustains
Xiao Liang and Zhong-Zhi Li and Yeyun Gong and yelong shen and Ying Nian Wu and Zhijiang Guo and Weizhu Chen , booktitle=. Beyond Pass@ 1: Self-Play with Variational Problem Synthesis Sustains. 2026 , url=
2026
-
[16]
2026 , eprint=
SCALER:Synthetic Scalable Adaptive Learning Environment for Reasoning , author=. 2026 , eprint=
2026
-
[17]
2026 , url=
ReSyn: Autonomously Scaling Synthetic Environments for Reasoning Models , author=. 2026 , url=
2026
-
[18]
2025 , eprint=
h1: Bootstrapping LLMs to Reason over Longer Horizons via Reinforcement Learning , author=. 2025 , eprint=
2025
-
[19]
2017 , publisher=
A survey of modern algebra , author=. 2017 , publisher=
2017
-
[20]
2026 , eprint=
Composition-RL: Compose Your Verifiable Prompts for Reinforcement Learning of Large Language Models , author=. 2026 , eprint=
2026
-
[21]
L ogic P ro: Improving Complex Logical Reasoning via Program-Guided Learning
Jiang, Jin and Yan, Yuchen and Liu, Yang and Wang, Jianing and Peng, Shuai and Cai, Xunliang and Cao, Yixin and Zhang, Mengdi and Gao, Liangcai. L ogic P ro: Improving Complex Logical Reasoning via Program-Guided Learning. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1...
-
[22]
2025 , url=
Yang Zhou and Hongyi Liu and Zhuoming Chen and Yuandong Tian and Beidi Chen , booktitle=. 2025 , url=
2025
-
[23]
M ath F usion: E nhancing M athematical P roblem-solving of LLM through I nstruction F usion
Pei, Qizhi and Wu, Lijun and Pan, Zhuoshi and Li, Yu and Lin, Honglin and Ming, Chenlin and Gao, Xin and He, Conghui and Yan, Rui. M ath F usion: Enhancing Mathematical Problem-solving of LLM through Instruction Fusion. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/20...
-
[24]
2026 , eprint=
RLAnything: Forge Environment, Policy, and Reward Model in Completely Dynamic RL System , author=. 2026 , eprint=
2026
-
[25]
2025 , eprint=
LongReasonArena: A Long Reasoning Benchmark for Large Language Models , author=. 2025 , eprint=
2025
-
[26]
From f(x) and g(x) to f(g(x)):
Lifan Yuan and Weize Chen and Yuchen Zhang and Ganqu Cui and Hanbin Wang and Ziming You and Ning Ding and Zhiyuan Liu and Maosong Sun and Hao Peng , booktitle=. From f(x) and g(x) to f(g(x)):. 2026 , url=
2026
-
[27]
Chen, Xinyi and Liao, Baohao and Qi, Jirui and Eustratiadis, Panagiotis and Monz, Christof and Bisazza, Arianna and de Rijke, Maarten. The SIF o Benchmark: Investigating the Sequential Instruction Following Ability of Large Language Models. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.92
-
[28]
The Thirteenth International Conference on Learning Representations , year=
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code , author=. The Thirteenth International Conference on Learning Representations , year=
-
[29]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Enigmata: Scaling Logical Reasoning in Large Language Models with Synthetic Verifiable Puzzles , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[30]
L ong B ench v2: Towards Deeper Understanding and Reasoning on Realistic Long-context Multitasks
Bai, Yushi and Tu, Shangqing and Zhang, Jiajie and Peng, Hao and Wang, Xiaozhi and Lv, Xin and Cao, Shulin and Xu, Jiazheng and Hou, Lei and Dong, Yuxiao and Tang, Jie and Li, Juanzi. L ong B ench v2: Towards Deeper Understanding and Reasoning on Realistic Long-context Multitasks. Proceedings of the 63rd Annual Meeting of the Association for Computational...
-
[31]
2024 American Invitational Mathematics Examination , year =
2024
-
[32]
2025 American Invitational Mathematics Examination , year =
2025
-
[33]
arXiv preprint arXiv:2311.07911 , year=
Instruction-Following Evaluation for Large Language Models , author=. arXiv preprint arXiv:2311.07911 , year=
-
[34]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[35]
2025 , eprint=
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning , author=. 2025 , eprint=
2025
-
[36]
2025 , eprint=
LeetCodeDataset: A Temporal Dataset for Robust Evaluation and Efficient Training of Code LLMs , author=. 2025 , eprint=
2025
-
[37]
2025 , eprint=
REST: Stress Testing Large Reasoning Models by Asking Multiple Problems at Once , author=. 2025 , eprint=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.