GRIP: Feedback-Guided Prompt Retrieval for Large Multimodal Models
Pith reviewed 2026-06-27 09:32 UTC · model grok-4.3
The pith
Feedback from multimodal models trains a retriever that selects more useful in-context examples than visual similarity does.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
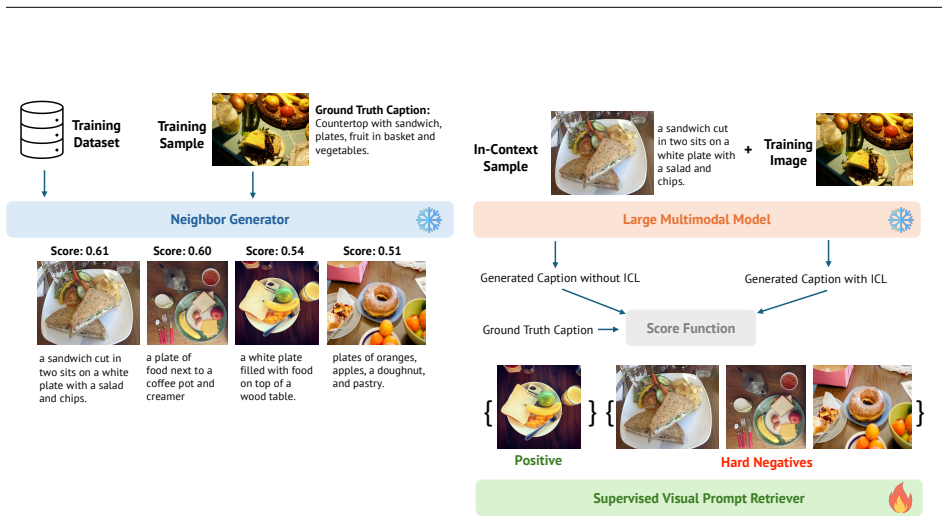
GRIP is a learnable vision-only retrieval framework that leverages feedback from LMMs to identify examples that truly improve model predictions. It learns to distinguish beneficial from detrimental in-context examples through contrastive training, refining retrieval beyond pure similarity. This yields consistent gains over similarity-based retrieval across three multimodal tasks and enables transfer of the trained retriever to different models without retraining.
What carries the argument
Contrastive training that uses LMM prediction feedback to separate helpful from unhelpful in-context examples.
If this is right
- Performance improves over similarity-based retrieval on classification, captioning, and VQA tasks.
- Retrievers trained with feedback from one model transfer to other models without retraining.
- The approach supports scalable deployment of multimodal in-context learning across open and closed models.
- Example selection can move beyond the assumption that semantic similarity alone determines usefulness.
Where Pith is reading between the lines
- Feedback may capture how an example interacts with a specific query in ways that generic similarity metrics overlook.
- The same feedback-driven contrastive approach could be tested on text-only in-context learning for language models.
- One trained retriever serving multiple models could lower the cost of adapting large multimodal systems to new tasks.
Load-bearing premise
Feedback signals from LMM predictions on held-out examples provide a reliable training signal that generalizes beyond the models and tasks used to collect it.
What would settle it
A retriever trained on feedback from one LMM that fails to outperform similarity retrieval or shows negative transfer when applied to a different LMM on the same tasks would falsify the central claims.
Figures


read the original abstract
In-Context Learning (ICL) has become a powerful mechanism for adapting Large Language Models (LLMs) to new tasks without fine-tuning. Extending this concept to Large Multimodal Models (LMMs), Multimodal In-Context Learning (M-ICL) relies on retrieving relevant examples, such as images, captions, or question-answer pairs, to guide predictions across tasks like classification, captioning, and visual question answering (VQA). Most existing approaches select in-context examples based on feature-space similarity, assuming that semantically similar samples provide the most useful context. However, our systematic analysis reveals that this assumption does not always hold: visually similar examples are not necessarily those that most effectively enhance in-context learning performance. To address this, we propose the Guided Retrieval of In-context Prompts (GRIP), a learnable vision-only retrieval framework that leverages feedback from LMMs to identify examples that truly improve model predictions. GRIP learns to distinguish beneficial from detrimental in-context examples through contrastive training, refining retrieval beyond pure similarity. Across three multimodal tasks, namely classification, captioning, and VQA, GRIP improves consistently over similarity-based retrieval on Qwen2.5-VL-7B, with its strongest gains in classification on Idefics2-8B. Moreover, we demonstrate that retrievers trained with feedback from one open LMM can be transferred to other models without retraining, including closed-source GPT-4o and Gemini, enabling scalable and cost-efficient deployment of M-ICL. Code will be published upon acceptance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces GRIP (Guided Retrieval of In-context Prompts), a vision-only learnable retriever for multimodal in-context learning (M-ICL) in LMMs. It argues that similarity-based example selection does not always yield the most beneficial in-context examples and instead proposes contrastive training that uses feedback signals derived from LMM predictions on held-out data to distinguish beneficial from detrimental examples. The paper claims consistent gains over similarity baselines across classification, captioning, and VQA on models including Qwen2.5-VL-7B and Idefics2-8B, plus zero-shot transfer of the trained retriever to other open and closed-source LMMs such as GPT-4o and Gemini.
Significance. If the empirical results hold, GRIP would provide a practical advance in M-ICL by replacing heuristic similarity retrieval with a learned objective that directly optimizes for downstream performance gains. The reported transferability of a single retriever across open and closed models is a concrete strength that could reduce the cost of deploying M-ICL with proprietary LMMs. The vision-only design of the retriever is also noted as an efficiency advantage.
major comments (1)
- The central claim that feedback-derived contrastive training isolates beneficial examples rests on the unverified assumption that LMM predictions on held-out data supply a reliable, low-noise training signal; without the data-construction procedure, loss formulation, or any quantitative results, ablation studies, or error analysis, it is impossible to assess whether the reported improvements are robust or whether the contrastive objective actually isolates the claimed beneficial examples.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The major comment raises a valid point about the need for greater transparency and validation of the feedback signal used in training. We address this below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: The central claim that feedback-derived contrastive training isolates beneficial examples rests on the unverified assumption that LMM predictions on held-out data supply a reliable, low-noise training signal; without the data-construction procedure, loss formulation, or any quantitative results, ablation studies, or error analysis, it is impossible to assess whether the reported improvements are robust or whether the contrastive objective actually isolates the claimed beneficial examples.
Authors: We acknowledge that the current version of the manuscript provides only a high-level description of the feedback mechanism and does not include dedicated quantitative validation, ablations on signal noise, or error analysis of the contrastive labels. Section 3 outlines the overall contrastive training setup and how LMM predictions on held-out data are used to assign beneficial/detrimental labels, but we agree this is insufficient for full assessment. In the revised manuscript we will: (1) expand the data-construction procedure with pseudocode and concrete examples of how predictions are thresholded to create training pairs; (2) include the exact contrastive loss formulation with hyperparameters; (3) add ablation results comparing feedback-based labels against random or similarity-based labels; and (4) provide error analysis measuring agreement between the derived labels and actual downstream performance gains on a held-out test set. These additions will directly address the robustness concern. revision: yes
Circularity Check
No significant circularity
full rationale
The paper describes an empirical method (GRIP) that collects feedback signals from external LMM predictions on held-out data and uses them to train a contrastive retriever. No equations, derivations, or first-principles claims appear in the abstract or description. The central claim is an empirical performance improvement over similarity baselines plus cross-model transfer; this does not reduce to any fitted parameter or self-citation by construction. The feedback signal is generated outside the paper's own definitions, satisfying the criterion for independent content. No self-citation load-bearing steps, uniqueness theorems, or ansatzes are referenced.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
URLhttps://arxiv.org/abs/ 2502.13923. Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901,
Pith/arXiv arXiv 1901
-
[2]
Can multimodal large language models truly perform multimodal in-context learning? In 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pp
Shuo Chen, Zhen Han, Bailan He, Jianzhe Liu, Mark Buckley, Yao Qin, Philip Torr, Volker Tresp, and Jindong Gu. Can multimodal large language models truly perform multimodal in-context learning? In 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pp. 6000–6010. IEEE,
2025
-
[3]
Microsoft coco captions: Data collection and evaluation server.arXiv preprint arXiv:1504.00325,
Xinlei Chen, Hao Fang, Tsung-Yi Lin, Ramakrishna Vedantam, Saurabh Gupta, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco captions: Data collection and evaluation server.arXiv preprint arXiv:1504.00325,
-
[4]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al- Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783,
-
[5]
URLhttps://doi.org/10.5281/zenodo.5143773. If you use this software, please cite it as below. Prannay Khosla, Piotr Teterwak, Chen Wang, Aaron Sarna, Yonglong Tian, Phillip Isola, Aaron Maschinot, Ce Liu, and Dilip Krishnan. Supervised contrastive learning.Advances in neural information processing systems, 33:18661–18673,
-
[6]
Syntriever: How to train your retriever with synthetic data from llms
Minsang Kim and Seungjun Baek. Syntriever: How to train your retriever with synthetic data from llms. arXiv preprint arXiv:2502.03824,
-
[7]
Bohao Li, Rui Wang, Guangzhi Wang, Yuying Ge, Yixiao Ge, and Ying Shan. Seed-bench: Benchmarking multimodal llms with generative comprehension.arXiv preprint arXiv:2307.16125,
-
[8]
Man Luo, Xin Xu, Zhuyun Dai, Panupong Pasupat, Mehran Kazemi, Chitta Baral, Vaiva Imbrasaite, and Vincent Y Zhao. Dr. icl: Demonstration-retrieved in-context learning.arXiv preprint arXiv:2305.14128,
-
[9]
Yang Luo, Zangwei Zheng, Zirui Zhu, and Yang You. How does the textual information affect the retrieval of multimodal in-context learning? InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pp. 5321–5335,
2024
-
[10]
Learning to retrieve prompts for in-context learning
Ohad Rubin, Jonathan Herzig, and Jonathan Berant. Learning to retrieve prompts for in-context learning. In Marine Carpuat, Marie-Catherine de Marneffe, and Ivan Vladimir Meza Ruiz (eds.),Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 2655–2671, Seattle, Un...
2022
-
[11]
Learning To Retrieve Prompts for In-Context Learning , url =
Association for Com- putational Linguistics. doi: 10.18653/v1/2022.naacl-main.191. URLhttps://aclanthology.org/2022. naacl-main.191/. Christoph Schuhmann, Romain Beaumont, Richard Vencu, Cade Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Wortsman, et al. Laion-5b: An open large-scale datasetfortrainingnextgenera...
-
[12]
Learning to retrieve in-context examples for large language models
Liang Wang, Nan Yang, and Furu Wei. Learning to retrieve in-context examples for large language models. arXiv preprint arXiv:2307.07164,
-
[13]
Xubin Wang, Jianfei Wu, Yichen Yuan, Deyu Cai, Mingzhe Li, and Weijia Jia. Demonstration selection for in-context learning via reinforcement learning.arXiv preprint arXiv:2412.03966,
-
[14]
Haozhe Zhao, Zefan Cai, Shuzheng Si, Xiaojian Ma, Kaikai An, Liang Chen, Zixuan Liu, Sheng Wang, Wenjuan Han, and Baobao Chang. Mmicl: Empowering vision-language model with multi-modal in- context learning.arXiv preprint arXiv:2309.07915,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.