Is Spurious Correlation Removal Always Learnable?
Pith reviewed 2026-06-27 07:10 UTC · model grok-4.3
The pith
Even when the invariant subspace is statistically identifiable, removing spurious correlations can remain computationally intractable.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
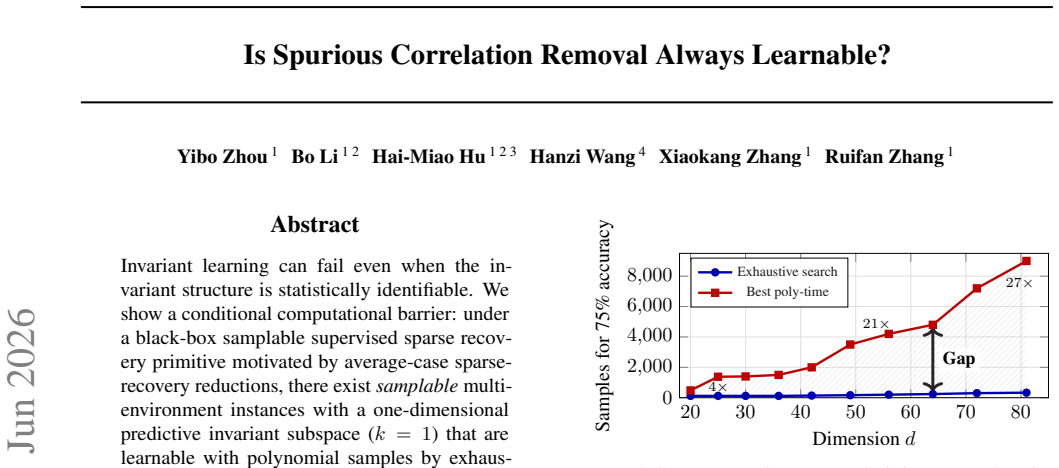
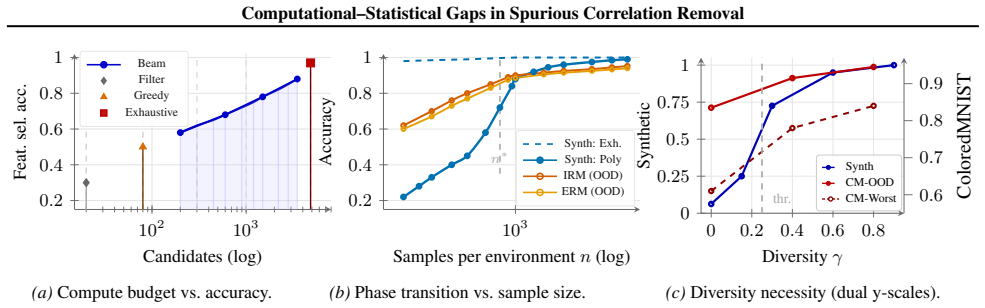
Under a black-box samplable supervised sparse recovery primitive motivated by average-case sparse-recovery reductions, there exist samplable multi-environment instances with a one-dimensional predictive invariant subspace (k=1) that are learnable with polynomial samples by exhaustive search, while any polynomial-time constant-accuracy recovery algorithm would contradict the primitive. Under sufficient diversity and local Gaussian regularity the minimax risk is E[dist(Vhat, Vinv)^2] = Theta(k(d-k)/(n|E|)), and under label-induced shifts a phase transition occurs at n* proportional to k(d-k)/(|E| gamma^2) with refined estimation error scaling proportional to 1/gamma^2.
What carries the argument
The black-box samplable supervised sparse recovery primitive that encodes computational hardness for recovering the invariant subspace from multi-environment data.
If this is right
- Samplable multi-environment instances exist where exhaustive search succeeds polynomially but efficient recovery fails.
- The separation parameter gamma controls both identifiability and the curvature of invariance objectives.
- The minimax risk for estimating the invariant subspace is Theta(k(d-k)/(n|E|)) under Gaussian regularity.
- Under label-induced shifts a phase transition in sample complexity occurs at n* proportional to k(d-k)/(|E| gamma^2) with error scaling as 1/gamma^2.
Where Pith is reading between the lines
- Practical invariant learning may need heuristics or extra structure to avoid this computational gap.
- Dataset construction should prioritize high environment diversity to cross the identifiability threshold.
- The reduction technique could apply to other settings where statistical identifiability does not guarantee efficient algorithms.
Load-bearing premise
The black-box supervised sparse recovery primitive is computationally hard for any polynomial-time algorithm achieving constant accuracy.
What would settle it
A polynomial-time algorithm achieving constant accuracy on recovering the invariant subspace from the constructed multi-environment instances without solving the sparse recovery primitive.
Figures
read the original abstract
Invariant learning can fail even when the invariant structure is statistically identifiable. We show a conditional computational barrier: under a black-box samplable supervised sparse recovery primitive motivated by average-case sparse-recovery reductions, there exist \emph{samplable} multi-environment instances with a one-dimensional predictive invariant subspace ($k=1$) that are learnable with polynomial samples by exhaustive search, while any polynomial-time constant-accuracy recovery algorithm would contradict the primitive. We further quantify environment diversity by a separation parameter $\gamma$, which controls identifiability and the curvature of invariance objectives. Under sufficient diversity and local Gaussian regularity, the minimax risk is $\mathbb{E}[\dist(\hat{V},V_{\mathrm{inv}})^2]=\Theta(k(d-k)/(n|\mathcal{E}|))$, and under label-induced shifts a phase transition occurs at $n^*\propto k(d-k)/(|\mathcal{E}|\gamma^2)$ with refined estimation error scaling proportional to $1/\gamma^2$. Synthetic and real datasets illustrate the predicted gaps and transitions and motivate simple diversity diagnostics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
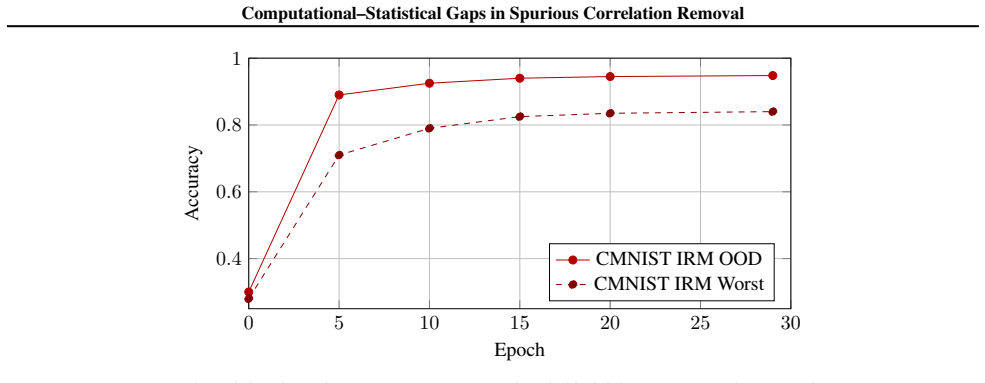
Summary. The paper claims a conditional computational barrier for invariant learning: under a black-box samplable supervised sparse recovery primitive (motivated by average-case sparse recovery), there exist samplable multi-environment distributions possessing a one-dimensional predictive invariant subspace (k=1) that exhaustive search can learn with polynomial samples, yet any polynomial-time constant-accuracy recovery algorithm would contradict the primitive. A separation parameter γ quantifies environment diversity and controls identifiability; under sufficient diversity and local Gaussian regularity the statistical minimax risk is Θ(k(d-k)/(n|E|)), while label-induced shifts induce a phase transition at n* ∝ k(d-k)/(|E|γ²) with refined error scaling as 1/γ². Synthetic and real-data experiments illustrate the predicted statistical-computational gaps and transitions.
Significance. If the reduction holds, the result establishes that statistical identifiability of an invariant subspace does not imply efficient learnability, separating statistical and computational aspects of spurious-correlation removal in a manner analogous to other average-case hardness reductions. The explicit γ-controlled rates, phase transition, and samplable construction provide concrete, falsifiable predictions. Credit is due for the black-box primitive formulation, the minimax derivation, and the inclusion of both synthetic and real-dataset validation that directly tests the predicted gaps.
major comments (2)
- [Reduction construction (§4)] Reduction (likely §4–5): the central claim requires that the explicit construction simultaneously (i) produces a joint distribution samplable in poly time, (ii) keeps V_inv statistically identifiable so that exhaustive search succeeds with poly samples, and (iii) ensures no poly-time constant-accuracy algorithm can recover an approximation without solving the primitive. The presentation does not contain an explicit argument ruling out the possibility that environment sampling or label-induced shifts leak information that an efficient algorithm could exploit to bypass the hardness.
- [Minimax analysis (§3)] Minimax risk derivation (Eq. for Θ(k(d-k)/(n|E|))): the statistical lower bound appears to treat environments as fixed and independent; it is unclear whether the same rate continues to hold once the construction is required to embed the sparse-recovery primitive while preserving samplability, or whether the embedding introduces additional statistical cost that would alter the Θ(·) expression.
minor comments (2)
- [Notation] Notation: the symbol |E| is used both for the number of environments and (implicitly) for the cardinality of the environment set; a single consistent definition would avoid ambiguity when the phase-transition threshold is stated.
- [Experiments] Figure captions for the synthetic experiments should explicitly state the value of γ and the dimension d used in each panel so that the observed gaps can be directly compared to the predicted n* scaling.
Simulated Author's Rebuttal
We thank the referee for the careful reading and insightful comments on our manuscript. We address each major comment below, providing clarifications on the reduction and minimax analysis while committing to revisions that strengthen the presentation.
read point-by-point responses
-
Referee: [Reduction construction (§4)] Reduction (likely §4–5): the central claim requires that the explicit construction simultaneously (i) produces a joint distribution samplable in poly time, (ii) keeps V_inv statistically identifiable so that exhaustive search succeeds with poly samples, and (iii) ensures no poly-time constant-accuracy algorithm can recover an approximation without solving the primitive. The presentation does not contain an explicit argument ruling out the possibility that environment sampling or label-induced shifts leak information that an efficient algorithm could exploit to bypass the hardness.
Authors: The construction in Section 4 embeds the sparse-recovery primitive into the invariant subspace such that the joint distribution remains samplable in polynomial time via the black-box primitive and independent Gaussian noise. Identifiability for exhaustive search is ensured by the γ-separation condition, which guarantees a unique population minimizer at V_inv. Environment sampling and label-induced shifts are generated independently of the sparse vector and orthogonal to it in the sense that they do not reveal its support; any algorithm attempting to exploit them for constant-accuracy recovery must still solve an instance of the primitive. We will add an explicit paragraph in the revised manuscript (new Remark 4.3) that formally rules out leakage by showing that any bypass would imply an efficient solver for the primitive, contradicting the assumption. revision: yes
-
Referee: [Minimax analysis (§3)] Minimax risk derivation (Eq. for Θ(k(d-k)/(n|E|))): the statistical lower bound appears to treat environments as fixed and independent; it is unclear whether the same rate continues to hold once the construction is required to embed the sparse-recovery primitive while preserving samplability, or whether the embedding introduces additional statistical cost that would alter the Θ(·) expression.
Authors: The minimax lower bound of Section 3 is established for the broad class of distributions satisfying the local Gaussian regularity and diversity assumptions (Assumptions 1–3), without reference to computational primitives. The Section 4 construction is explicitly verified to satisfy these assumptions: the embedding of the sparse instance into the means preserves the local curvature, environment independence, and γ-controlled separation, introducing no extra statistical cost. Consequently the Θ(k(d-k)/(n|E|)) rate and the n* phase transition remain unchanged. We will insert a short verification paragraph after the construction to confirm that the embedded distributions lie within the minimax class. revision: yes
Circularity Check
No circularity: conditional hardness via external black-box primitive
full rationale
The paper's central result is a conditional computational barrier obtained by explicit reduction to a stated external black-box samplable supervised sparse recovery primitive (motivated by average-case sparse-recovery reductions but not derived internally). The construction is presented as preserving samplability while ensuring statistical identifiability for exhaustive search, with no equations or steps that reduce a claimed prediction or uniqueness result to a self-definition, fitted input, or self-citation chain. The separation parameter γ and minimax rate are derived from standard statistical arguments under the stated assumptions, without circular renaming or ansatz smuggling. This is the normal case of an externally grounded hardness claim.
Axiom & Free-Parameter Ledger
free parameters (1)
- gamma
axioms (1)
- domain assumption Existence of a black-box samplable supervised sparse recovery primitive that is hard for polynomial-time constant-accuracy algorithms, motivated by average-case sparse-recovery reductions.
Reference graph
Works this paper leans on
-
[1]
International Conference on Learning Representations , year =
Distributionally Robust Neural Networks for Group Shifts: On the Importance of Regularization for Worst-Case Generalization , author =. International Conference on Learning Representations , year =
-
[3]
, journal =
Gao, Chao and Ma, Zongming and Zhou, Harrison H. , journal =. Sparse. 2017 , month =
2017
-
[4]
Proceedings of the 38th International Conference on Machine Learning , series =
Out-of-Distribution Generalization via Risk Extrapolation (REx) , author =. Proceedings of the 38th International Conference on Machine Learning , series =. 2021 , publisher =
2021
-
[7]
Proceedings of the 38th International Conference on Machine Learning , series =
WILDS: A Benchmark of in-the-Wild Distribution Shifts , author =. Proceedings of the 38th International Conference on Machine Learning , series =. 2021 , publisher =
2021
-
[8]
Proceedings of The 24th International Conference on Artificial Intelligence and Statistics , series =
Does Invariant Risk Minimization Capture Invariance? , author =. Proceedings of The 24th International Conference on Artificial Intelligence and Statistics , series =. 2021 , publisher =
2021
-
[9]
Proceedings of the 30th Conference on Learning Theory , series =
A General Characterization of the Statistical Query Complexity , author =. Proceedings of the 30th Conference on Learning Theory , series =. 2017 , publisher =
2017
-
[10]
Banach Center Publications , volume =
Metric Entropy of Homogeneous Spaces , author =. Banach Center Publications , volume =. 1998 , publisher =. doi:10.4064/-43-1-395-410 , url =
-
[11]
Random Structures & Algorithms , volume =
Jerrum, Mark , title =. Random Structures & Algorithms , volume =. 1992 , doi =
1992
-
[12]
Random Structures & Algorithms , volume =
Alon, Noga and Krivelevich, Michael and Sudakov, Benny , title =. Random Structures & Algorithms , volume =. 1998 , doi =
1998
-
[13]
Random Structures & Algorithms , volume =
Feige, Uriel and Krauthgamer, Robert , title =. Random Structures & Algorithms , volume =. 2000 , doi =
2000
-
[14]
Proceedings of the 26th Annual Conference on Learning Theory , pages =
Berthet, Quentin and Rigollet, Philippe , title =. Proceedings of the 26th Annual Conference on Learning Theory , pages =. 2013 , editor =
2013
-
[15]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages =
Zhou, Yibo , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages =
-
[16]
Proceedings of the 41st International Conference on Machine Learning , pages =
Pedestrian Attribute Recognition as Label-balanced Multi-label Learning , author =. Proceedings of the 41st International Conference on Machine Learning , pages =. 2024 , editor =
2024
-
[18]
International Journal of Computer Vision , volume =
Zhou, Yibo and Hu, Hai-Miao and Yu, Jinzuo and Wu, Haotian and Pu, Shiliang and Wang, Hanzi , title =. International Journal of Computer Vision , volume =. 2025 , doi =
2025
-
[19]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume =
Zhou, Yibo and Li, Bo and Hu, Hai-Miao and Zhang, Xiaokang and Zhang, Dongping and Wang, Hanzi , title =. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume =. 2025 , doi =
2025
-
[20]
Neural Networks , pages=
ASRL: Correlation-Robust Pedestrian Attribute Recognition via Fixed Orthogonal Classifier , author=. Neural Networks , pages=. 2025 , publisher=
2025
-
[21]
IEEE Transactions on Industrial Informatics , volume=
Dual-constraint autoencoder and adaptive weighted similarity spatial attention for unsupervised anomaly detection , author=. IEEE Transactions on Industrial Informatics , volume=. 2024 , publisher=
2024
-
[22]
IEEE Transactions on Image Processing , year=
A Multi-Category Anomaly Editing Network With Correlation Exploration and Voxel-Level Attention for Unsupervised Surface Anomaly Detection , author=. IEEE Transactions on Image Processing , year=
-
[23]
IEEE Transactions on Instrumentation and Measurement , volume=
JRCC-Net: A segmentation network with joint representation and contrast clustering for surface anomaly detection , author=. IEEE Transactions on Instrumentation and Measurement , volume=. 2023 , publisher=
2023
-
[24]
Journal of Intelligent & Fuzzy Systems , volume=
MFFA: Multi-level feature fusion and anomaly map compensation for anomaly detection , author=. Journal of Intelligent & Fuzzy Systems , volume=. 2023 , publisher=
2023
-
[25]
Finding a large hidden clique in a random graph
Alon, N., Krivelevich, M., and Sudakov, B. Finding a large hidden clique in a random graph. Random Structures & Algorithms, 13 0 (3--4): 0 457--466, 1998. doi:10.1002/(SICI)1098-2418(199810/12)13:3/4<457::AID-RSA14>3.0.CO;2-W
-
[26]
Arjovsky, M., Bottou, L., Gulrajani, I., and Lopez-Paz, D. Invariant risk minimization. arXiv preprint arXiv:1907.02893, 2019. URL https://arxiv.org/abs/1907.02893
Pith/arXiv arXiv 1907
-
[27]
and Rigollet, P
Berthet, Q. and Rigollet, P. Complexity theoretic lower bounds for sparse principal component detection. In Shalev-Shwartz, S. and Steinwart, I. (eds.), Proceedings of the 26th Annual Conference on Learning Theory, volume 30 of Proceedings of Machine Learning Research, pp.\ 1046--1066, Princeton, NJ, USA, 12--14 Jun 2013. PMLR. URL https://proceedings.mlr...
2013
-
[28]
Feige, U. and Krauthgamer, R. Finding and certifying a large hidden clique in a semirandom graph. Random Structures & Algorithms, 16 0 (2): 0 195--208, 2000. doi:10.1002/(SICI)1098-2418(200003)16:2<195::AID-RSA5>3.0.CO;2-A
-
[29]
Gulrajani, I. and Lopez-Paz, D. In search of lost domain generalization. arXiv preprint arXiv:2007.01434, 2020. URL https://arxiv.org/abs/2007.01434
arXiv 2007
-
[30]
Large cliques elude the Metropolis process
Jerrum, M. Large cliques elude the Metropolis process. Random Structures & Algorithms, 3 0 (4): 0 347--359, 1992. doi:10.1002/rsa.3240030402
-
[31]
W., Sagawa, S., Marklund, H., Xie, S
Koh, P. W., Sagawa, S., Marklund, H., Xie, S. M., Zhang, M., Balsubramani, A., Hu, W., Yasunaga, M., Phillips, R. L., Gao, I., Lee, T., David, E., Stavness, I., Guo, W., Earnshaw, B., Haque, I., Beery, S. M., Leskovec, J., Kundaje, A., Pierson, E., Levine, S., Finn, C., and Liang, P. Wilds: A benchmark of in-the-wild distribution shifts. In Proceedings of...
2021
-
[32]
Out-of-distribution generalization via risk extrapolation (rex)
Krueger, D., Caballero, E., Jacobsen, J.-H., Zhang, A., Binas, J., Zhang, D., Le Priol, R., and Courville, A. Out-of-distribution generalization via risk extrapolation (rex). In Proceedings of the 38th International Conference on Machine Learning, volume 139 of Proceedings of Machine Learning Research, pp.\ 5815--5826. PMLR, 2021. URL https://proceedings....
2021
-
[33]
The risks of invariant risk minimization
Rosenfeld, E., Ravikumar, P., and Risteski, A. The risks of invariant risk minimization. arXiv preprint arXiv:2010.05761, 2020. URL https://arxiv.org/abs/2010.05761
arXiv 2010
-
[34]
W., Hashimoto, T
Sagawa, S., Koh, P. W., Hashimoto, T. B., and Liang, P. Distributionally robust neural networks for group shifts: On the importance of regularization for worst-case generalization. In International Conference on Learning Representations, 2020. URL https://openreview.net/forum?id=ryxGuJrFvS
2020
-
[35]
and Hu, H.-M
Zhang, R. and Hu, H.-M. A multi-category anomaly editing network with correlation exploration and voxel-level attention for unsupervised surface anomaly detection. IEEE Transactions on Image Processing, 2025 a
2025
-
[36]
Jrcc-net: A segmentation network with joint representation and contrast clustering for surface anomaly detection
Zhang, R., Wang, H., Feng, M., Liu, Y., and Yang, G. Jrcc-net: A segmentation network with joint representation and contrast clustering for surface anomaly detection. IEEE Transactions on Instrumentation and Measurement, 72: 0 1--14, 2023 a
2023
-
[37]
Mffa: Multi-level feature fusion and anomaly map compensation for anomaly detection
Zhang, R., Wang, H., and Yang, G. Mffa: Multi-level feature fusion and anomaly map compensation for anomaly detection. Journal of Intelligent & Fuzzy Systems, 44 0 (5): 0 7195--7210, 2023 b
2023
-
[38]
Dual-constraint autoencoder and adaptive weighted similarity spatial attention for unsupervised anomaly detection
Zhang, R., Wang, H., Feng, M., Liu, Y., and Yang, G. Dual-constraint autoencoder and adaptive weighted similarity spatial attention for unsupervised anomaly detection. IEEE Transactions on Industrial Informatics, 20 0 (7): 0 9393--9403, 2024
2024
-
[39]
and Hu, H.-M
Zhang, X. and Hu, H.-M. Asrl: Correlation-robust pedestrian attribute recognition via fixed orthogonal classifier. Neural Networks, pp.\ 108408, 2025 b
2025
-
[40]
Rethinking reconstruction autoencoder-based out-of-distribution detection
Zhou, Y. Rethinking reconstruction autoencoder-based out-of-distribution detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp.\ 7379--7387, June 2022
2022
-
[41]
Zhou, Y., Hu, H.-M., Yu, J., Xu, Z., Lu, W., and Cao, Y. A solution to co-occurence bias: Attributes disentanglement via mutual information minimization for pedestrian attribute recognition. In Elkind, E. (ed.), Proceedings of the Thirty-Second International Joint Conference on Artificial Intelligence, IJCAI-23 , pp.\ 1831--1839. International Joint Confe...
-
[42]
Pedestrian attribute recognition as label-balanced multi-label learning
Zhou, Y., Hu, H.-M., Xiang, Y., Zhang, X., and Wu, H. Pedestrian attribute recognition as label-balanced multi-label learning. In Salakhutdinov, R., Kolter, Z., Heller, K., Weller, A., Oliver, N., Scarlett, J., and Berkenkamp, F. (eds.), Proceedings of the 41st International Conference on Machine Learning, volume 235 of Proceedings of Machine Learning Res...
2024
-
[43]
Zhou, Y., Hu, H.-M., Yu, J., Wu, H., Pu, S., and Wang, H. A solution to co-occurrence bias in pedestrian attribute recognition: Theory, algorithms, and improvements. International Journal of Computer Vision, 133 0 (7): 0 4712--4726, 2025 a . doi:10.1007/s11263-025-02405-7. URL https://doi.org/10.1007/s11263-025-02405-7
-
[44]
Heterogeneous feature re-sampling for balanced pedestrian attribute recognition
Zhou, Y., Li, B., Hu, H.-M., Zhang, X., Zhang, D., and Wang, H. Heterogeneous feature re-sampling for balanced pedestrian attribute recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 47 0 (4): 0 2706--2722, 2025 b . doi:10.1109/TPAMI.2025.3526930. URL https://doi.org/10.1109/TPAMI.2025.3526930
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.