HyPE: Category-Aware Hypergraph Encoding with Persistent Edge Embeddings for Persona-Grounded Dialogue
Pith reviewed 2026-06-27 06:55 UTC · model grok-4.3
The pith
Grouping persona sentences into category-induced hyperedges produces more consistent dialogue responses than flat sentence pooling, with gains that hold from GPT-2 to 3B-scale models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
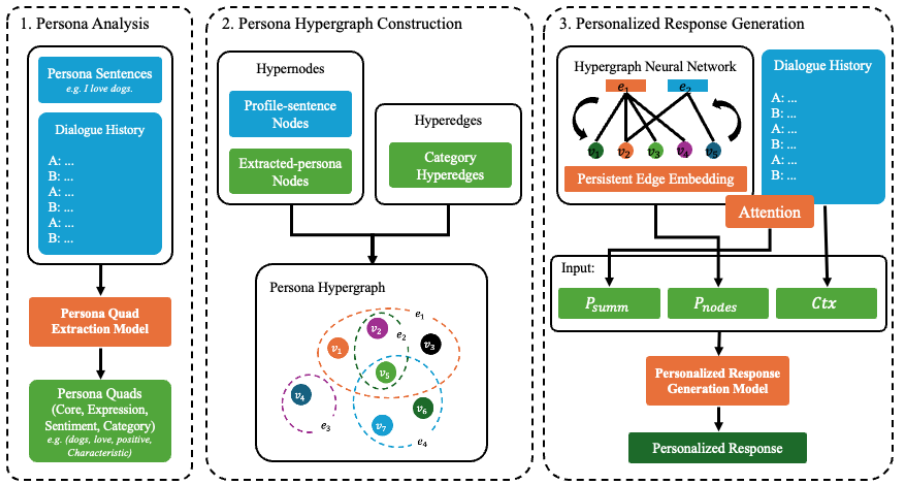
HyPE builds a hypergraph whose hyperedges are induced by shared category labels across persona quadruples, then applies HyperGCN message passing augmented by learnable per-category Persistent Edge Embeddings to produce a persona summary vector and soft-memory bank that condition the dialogue generator, resulting in responses that better respect the input persona than sentence-level pooling baselines across multiple model scales.
What carries the argument
Hypergraph whose hyperedges are induced by sentences sharing the same category label within (Core, Expression, Sentiment, Category) quadruples, processed by HyperGCN with Persistent Edge Embeddings as per-category learnable priors fused into message passing.
If this is right
- Response generators receive a persona representation that explicitly encodes relations among attributes belonging to the same category.
- The same hypergraph encoder can be attached to different backbone language models without retraining the entire system.
- The soft-memory bank produced by the HyperGCN supplies category-structured persona facts during token generation.
- Persistent Edge Embeddings act as lightweight, reusable priors that are learned once per category and reused across conversations.
Where Pith is reading between the lines
- If the category labels assigned to persona sentences are incomplete or inconsistent, the induced hyperedges may connect unrelated attributes and reduce rather than improve consistency.
- The same category-induced hyperedge construction could be applied to other dialogue tasks that involve grouped knowledge, such as topic-aware or entity-linked conversation.
- Persistent Edge Embeddings offer a general mechanism for injecting domain-specific priors into any hypergraph network without increasing the number of message-passing layers.
Load-bearing premise
Shared category labels on persona sentences induce hyperedges that capture high-order relations more usefully than treating the sentences as an unordered set.
What would settle it
An ablation that replaces category-induced hyperedges with either fully connected edges or random groupings by category, then measures whether consistency on PersonaChat drops back to the level of sentence-level pooling baselines.
Figures
read the original abstract
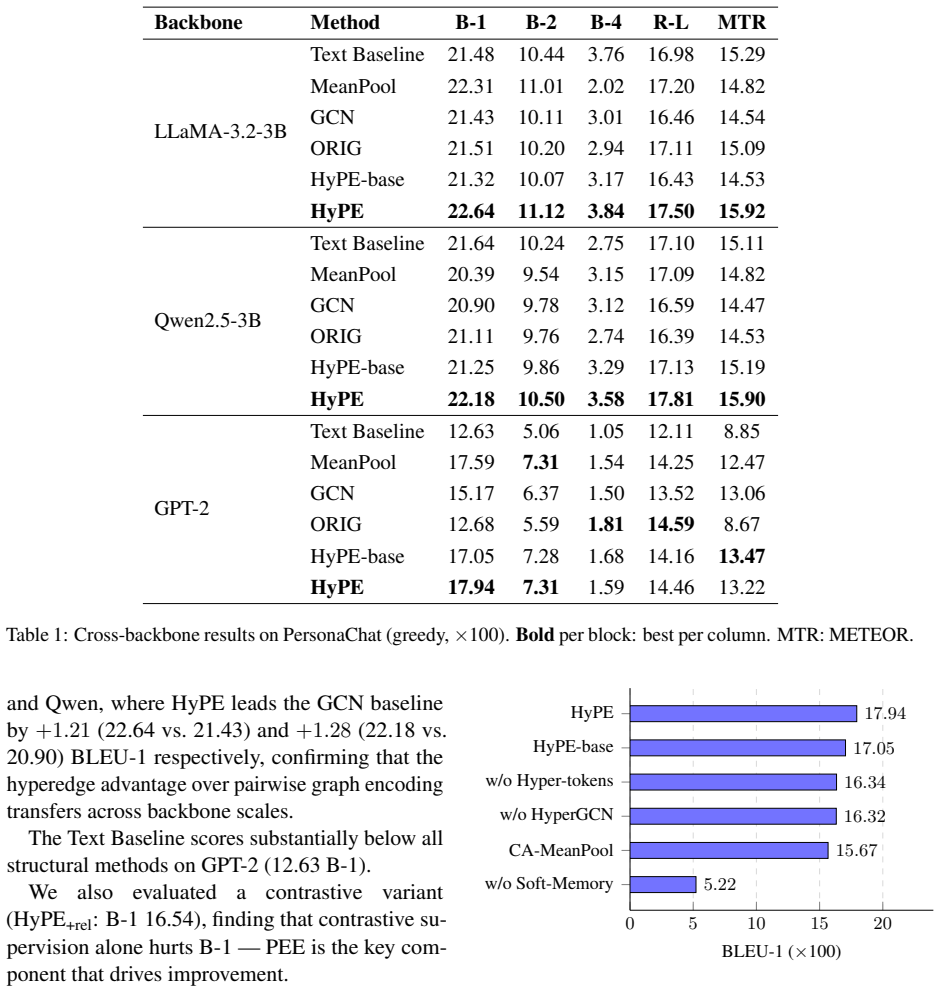
Persona-grounded dialogue systems aim to produce responses consistent with a speaker's persona, yet existing methods treat personas as a flat set of sentences and fail to model the high-order relations among persona attributes-e.g., that several persona sentences share a topical category. We propose HyPE (Hypergraph Persona Encoder), a framework that (i) analyzes each persona-bearing text as a (Core, Expression, Sentiment, Category) quadruple, and (ii) organizes persona elements into a hypergraph whose hyperedges are induced by shared category labels. An HyperGCN hypergraph neural network propagates this structure into a persona summary vector and a soft-memory bank that condition the response generator. We further propose Persistent Edge Embeddings (PEE), lightweight per-category learnable priors fused into the HyperGCN message-passing step. On PersonaChat under greedy decoding, HyPE consistently outperforms sentence-level pooling baselines across GPT-2, LLaMA-3.2-3B, and Qwen2.5-3B backbones by demonstrating that structured hyperedge-level persona encoding provides a transferable advantage across model scales.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that HyPE, by decomposing each persona sentence into a (Core, Expression, Sentiment, Category) quadruple and inducing hyperedges from shared Category labels, uses HyperGCN with Persistent Edge Embeddings (PEE) to produce a persona summary vector and soft-memory bank that condition response generation, yielding consistent outperformance over sentence-level pooling baselines across GPT-2, LLaMA-3.2-3B and Qwen2.5-3B on PersonaChat under greedy decoding, with the advantage attributed to structured hyperedge-level persona encoding.
Significance. If the reported gains survive controls that isolate the contribution of hyperedge connectivity, the framework could supply a practical method for injecting high-order relational structure into persona representations, with the observed transferability across model scales constituting a useful empirical finding. The lightweight PEE priors are a cleanly motivated design element.
major comments (1)
- [Experimental evaluation] Experimental evaluation (and abstract): the central claim that 'structured hyperedge-level persona encoding provides a transferable advantage' rests on the premise that category-induced hyperedges capture useful high-order relations beyond what category labels and PEE alone supply. The described baselines receive neither the quadruple decomposition nor the category signal, so an ablation that retains both the quadruple representation and PEE but substitutes ordinary set pooling for HyperGCN message passing is required; without it the load-bearing premise remains untested.
minor comments (1)
- [Abstract] Abstract: the statement of 'consistent outperformance' would be strengthened by inclusion of concrete metrics, standard deviations, or at least the number of runs.
Simulated Author's Rebuttal
We are grateful to the referee for the constructive comment on strengthening the experimental evaluation. Our point-by-point response follows, and we will revise the manuscript to include the requested ablation.
read point-by-point responses
-
Referee: [Experimental evaluation] Experimental evaluation (and abstract): the central claim that 'structured hyperedge-level persona encoding provides a transferable advantage' rests on the premise that category-induced hyperedges capture useful high-order relations beyond what category labels and PEE alone supply. The described baselines receive neither the quadruple decomposition nor the category signal, so an ablation that retains both the quadruple representation and PEE but substitutes ordinary set pooling for HyperGCN message passing is required; without it the load-bearing premise remains untested.
Authors: We concur that an ablation isolating the HyperGCN component is necessary to substantiate the claim regarding the benefits of hyperedge-level encoding. The current baselines lack the quadruple decomposition and category signal, making it difficult to attribute gains solely to the hypergraph structure versus these additional features. In the revised version, we will introduce a new baseline that incorporates the (Core, Expression, Sentiment, Category) quadruple and Persistent Edge Embeddings but employs ordinary set pooling (such as mean or max pooling) instead of HyperGCN message passing. Results from this ablation will be reported, and the abstract will be updated to accurately reflect the findings. This addition will provide a clearer test of whether the category-induced hyperedges offer advantages beyond the category labels and PEE alone. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper defines a hypergraph construction from category-induced hyperedges plus PEE priors, then reports empirical gains on external baselines (sentence-level pooling) across multiple backbones. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text that would make the claimed advantage equivalent to its inputs by construction. The derivation remains self-contained against measured performance rather than tautological.
Axiom & Free-Parameter Ledger
free parameters (1)
- Persistent Edge Embeddings
axioms (1)
- domain assumption Shared category labels on persona sentences define meaningful hyperedges that capture high-order relations
invented entities (2)
-
Persistent Edge Embeddings (PEE)
no independent evidence
-
HyperGCN hypergraph neural network for persona summary
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Hongjie Cai, Rui Xia, and Jianfei Yu
Hyperbert: Mixing hypergraph-aware layers with language models for node classification on text- attributed hypergraphs.Preprint, arXiv:2402.07309. Hongjie Cai, Rui Xia, and Jianfei Yu
-
[2]
InProceedings of the 59th Annual Meeting of the Association for Computational Linguistics (ACL)
Aspect- category-opinion-sentiment quadruple extraction with implicit aspects and opinions. InProceedings of the 59th Annual Meeting of the Association for Computational Linguistics (ACL). Liang Chen, Hongru Wang, Yang Deng, Wai Chung Kwan, Zezhong Wang, and Kam-Fai Wong. 2023a. Towards robust personalized dialogue generation via order-insensitive represe...
2023
-
[3]
The llama 3 herd of models.Preprint, arXiv:2407.21783. Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
-
[4]
Hyperg: Hypergraph-enhanced llms for structured knowledge. Preprint, arXiv:2502.18125. Thomas N. Kipf and Max Welling
-
[5]
InFindings of the Association for Computational Linguistics: ACL 2023, pages 13449– 13467
DiaASQ: A benchmark of conversational aspect-based sentiment quadruple analysis. InFindings of the Association for Computational Linguistics: ACL 2023, pages 13449– 13467. Association for Computational Linguistics. Chin-Yew Lin
2023
-
[6]
InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 2511–2522
G-eval: NLG evaluation using GPT-4 with better human alignment. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 2511–2522. Association for Com- putational Linguistics. OpenAI, :, Aaron Hurst, Adam Lerer, Adam P. Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Haye...
2023
-
[7]
Kishore Papineni, Salim Roukos, Todd Ward, and Wei- Jing Zhu
Gpt-4o system card.Preprint, arXiv:2410.21276. Kishore Papineni, Salim Roukos, Todd Ward, and Wei- Jing Zhu
-
[8]
Alec Radford, Jeff Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever
Qwen2.5 technical report.Preprint, arXiv:2412.15115. Alec Radford, Jeff Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever
-
[9]
InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing (EMNLP)
Sentence- BERT: Sentence embeddings using Siamese BERT- networks. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing (EMNLP). Association for Computational Linguis- tics. Rui Ribeiro, Joao P. Carvalho, and Luísa Coheur
2019
-
[10]
BoB: BERT over BERT for training persona-based dialogue models from lim- ited personalized data. InProceedings of the 59th Annual Meeting of the Association for Computa- tional Linguistics and the 11th International Joint Conference on Natural Language Processing (ACL- IJCNLP), pages 167–177. Association for Computa- tional Linguistics. Chen Tang, Hongbo ...
-
[11]
Chien-Sheng Wu, Andrea Madotto, Zhaojiang Lin, Peng Xu, and Pascale Fung
Representation learning with contrastive predictive coding.arXiv preprint arXiv:1807.03748. Chien-Sheng Wu, Andrea Madotto, Zhaojiang Lin, Peng Xu, and Pascale Fung
-
[12]
InProceed- ings of the 12th Language Resources and Evaluation Conference (LREC)
Getting to know you: User attribute extraction from dialogues. InProceed- ings of the 12th Language Resources and Evaluation Conference (LREC). Naganand Yadati, Madhav Nimishakavi, Prateek Ya- dav, Vikram Nitin, Anand Louis, and Partha Talukdar. 2019.HyperGCN: a new method of training graph convolutional networks on hypergraphs. Curran As- sociates Inc., ...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.