Loss-Shift Transfer via Bayes Quotients
Pith reviewed 2026-06-27 07:13 UTC · model grok-4.3
The pith
A representation minimal for one loss cannot achieve the Bayes risk for any strictly finer loss under the same data distribution.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
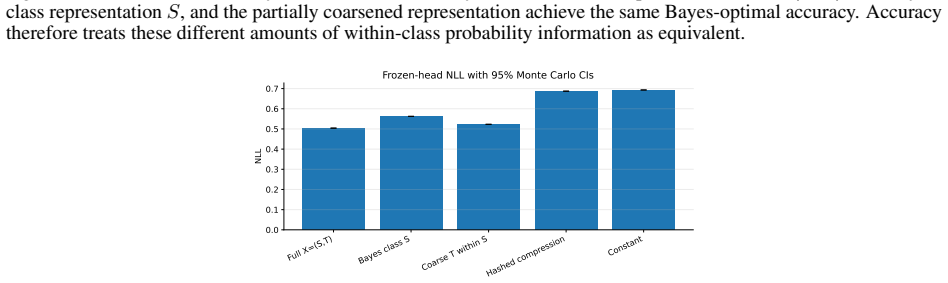
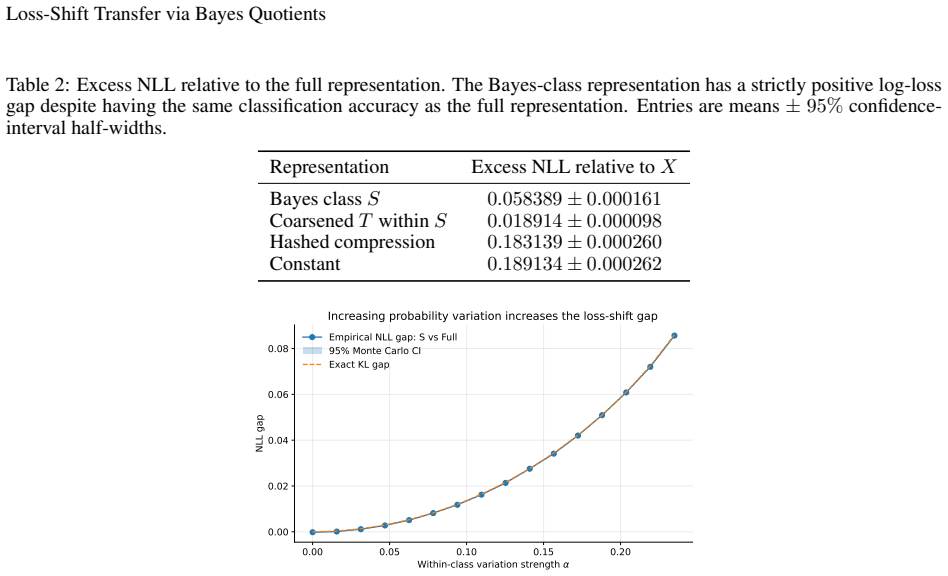
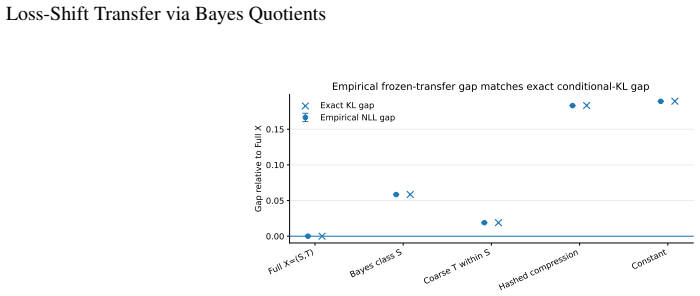
A source-minimal representation for a coarser loss is insufficient for a strictly finer target loss. For finite-output log loss the excess risk equals the conditional information about Y discarded by the representation.
What carries the argument
Bayes quotients, which order losses by refinement and thereby identify when one loss requires strictly more information from X than another.
If this is right
- Classification-optimal representations can still incur positive excess log-loss risk on the same data.
- The size of the loss-shift gap is exactly the conditional information about Y discarded by the representation.
- The obstruction is independent of the particular joint law P(X,Y) and arises solely from the refinement relation between the losses.
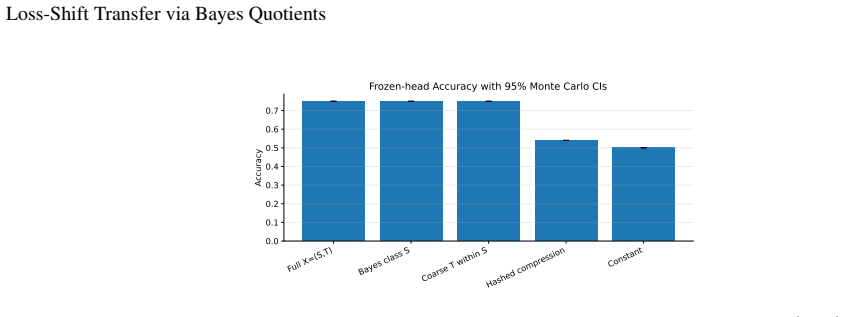
- Empirical checks in synthetic and real-image settings reproduce the predicted excess risk.
Where Pith is reading between the lines
- Representations intended for downstream use may need to preserve information for an entire family of possible losses rather than a single one.
- The same mechanism could explain why pre-training objectives sometimes transfer incompletely even when the target data distribution matches the source.
- One could design controlled experiments that vary only the refinement depth between source and target losses while holding all other factors fixed.
Load-bearing premise
Losses admit a refinement ordering via Bayes quotients such that any strict refinement creates a qualitative obstruction that holds for every data distribution.
What would settle it
Construct two log losses where one strictly refines the other, obtain a representation that is minimal for the coarser loss, then check whether its excess risk on the finer loss equals the conditional mutual information between the representation and Y that is lost.
Figures
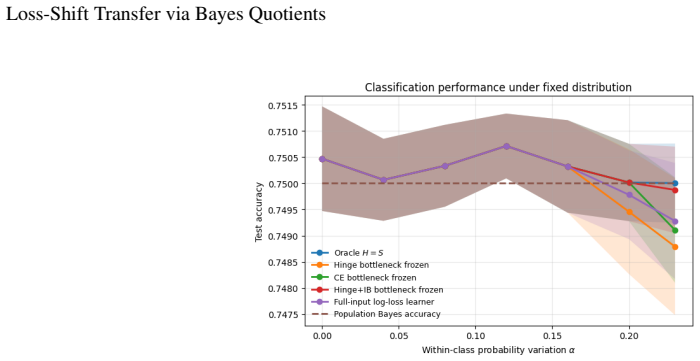
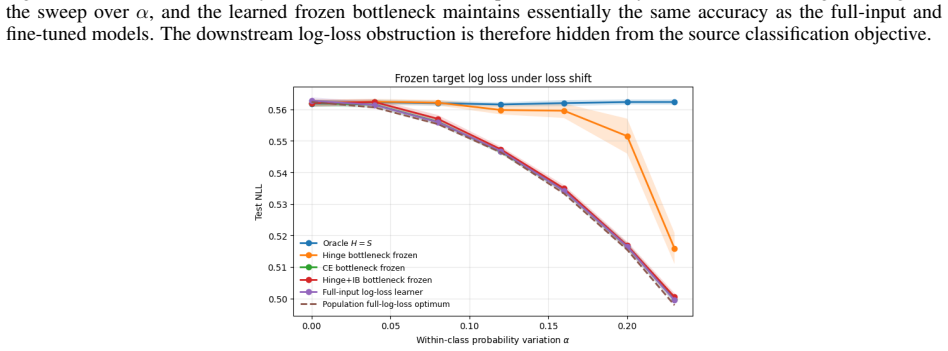
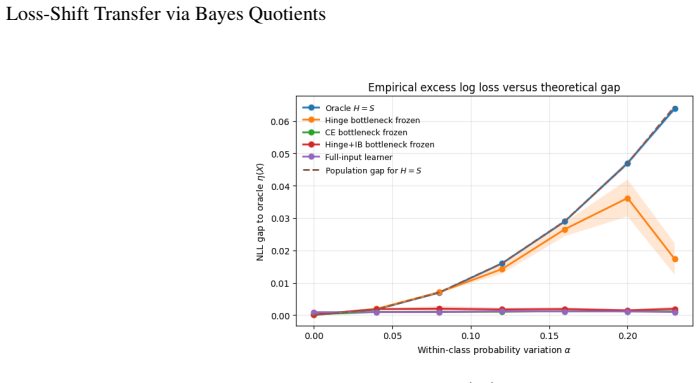
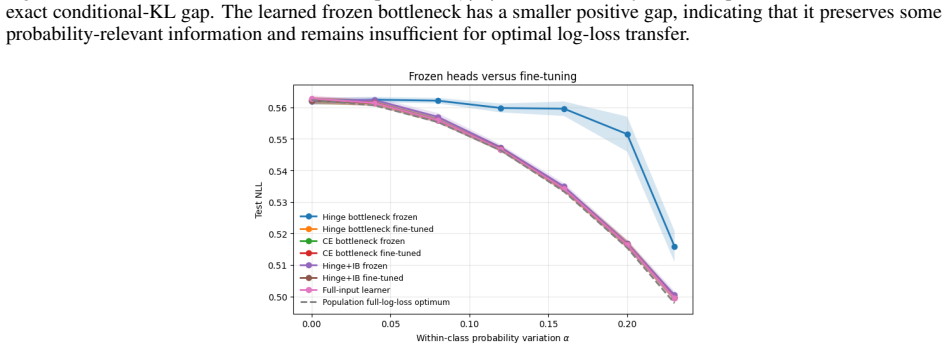
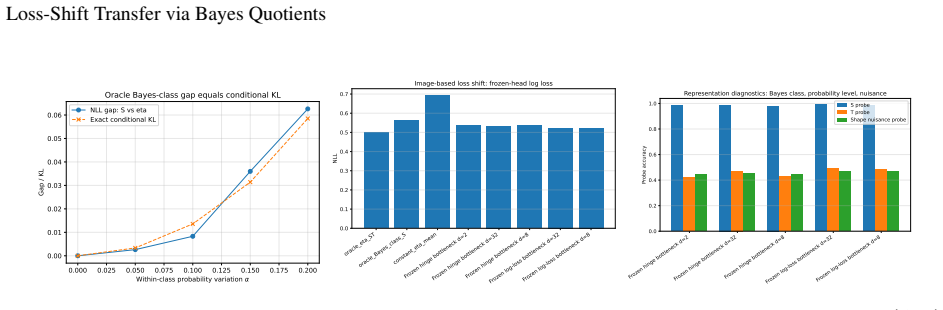
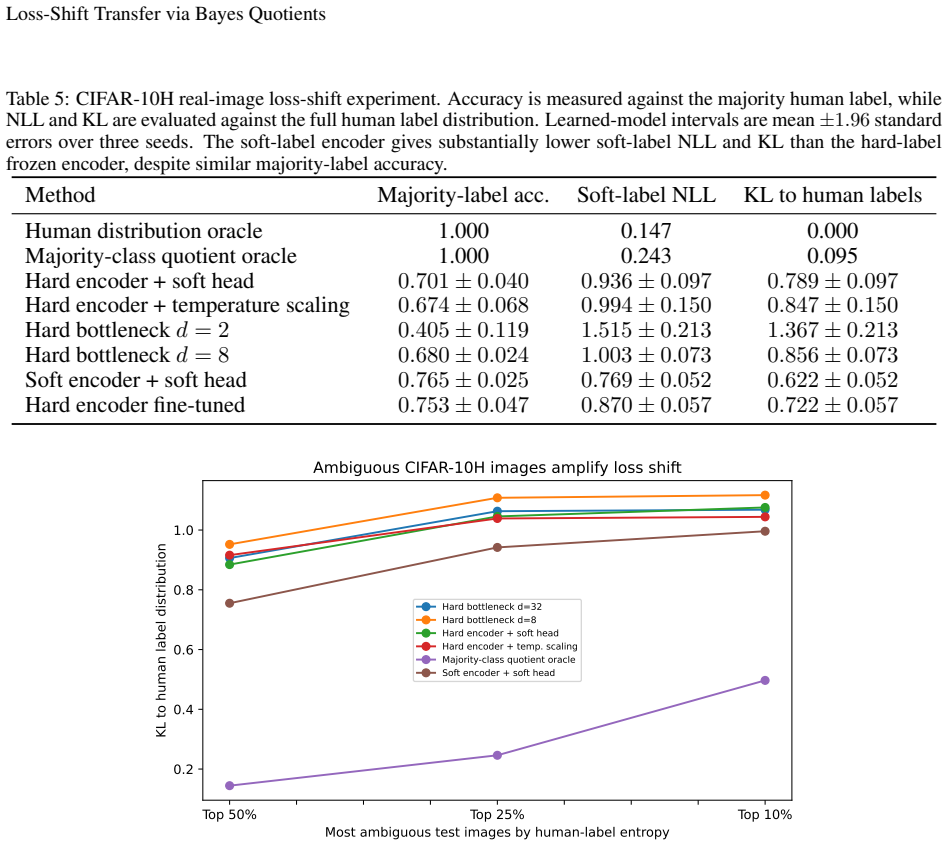
read the original abstract
Transfer learning is usually studied as a consequence of distribution shift. This paper identifies an orthogonal failure mode in which the data distribution is fixed and the loss changes. This setting is called \emph{loss shift}. A loss determines which information in \(X\) is Bayes-relevant, and two losses may therefore require different representations even under the same joint law \(P(X,Y)\). The idea is formalized using Bayes quotients, which allow losses to be ordered by refinement. In the Bayes-quotient formulation, strict refinement gives an immediate qualitative obstruction. A source-minimal representation for a coarser loss is insufficient for a strictly finer target loss. For finite-output log loss, this obstruction becomes an exact quantitative identity. The excess risk is the conditional information about \(Y\) discarded by the representation. Experiments in controlled, learned, synthetic-image, and real-image settings show the predicted effect, i.e., classification-equivalent representations can have different optimal log-loss performance under a fixed data distribution.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces 'loss-shift' as a transfer-learning failure mode orthogonal to distribution shift: with fixed P(X,Y), a change in loss can render a representation that is minimal for one loss insufficient for another. Losses are ordered via Bayes quotients; strict refinement is claimed to produce an immediate, distribution-independent qualitative obstruction (a source-minimal representation for the coarser loss cannot suffice for the strictly finer loss). For finite-output log loss the obstruction is quantified exactly as the conditional mutual information between Y and the information discarded by the representation. Experiments in controlled, learned, synthetic-image and real-image regimes are reported to confirm the predicted effect.
Significance. If the central claims hold, the work supplies a novel, distribution-independent obstruction in representation transfer together with an exact, falsifiable excess-risk identity for log loss. The Bayes-quotient ordering and the quantitative identity constitute clear strengths; the experimental controls across synthetic and real settings add credibility. The result would affect both theoretical accounts of sufficient representations and practical loss design in transfer settings.
major comments (2)
- [§3] §3 (Bayes-quotient refinement ordering): the argument that strict refinement forces insufficiency for every joint law P(X,Y) is load-bearing. The derivation must explicitly rule out the possibility that, for some P, the additional Bayes-relevant information required by the finer loss is already recoverable from (or irrelevant to) any source-minimal representation of the coarser loss; without this step the claimed distribution independence does not follow directly from the partial order.
- [§4.1] §4.1 (excess-risk identity for finite-output log loss): the identity equating excess risk to I(Y; discarded part | representation) is presented as following from the refinement relation. The proof should state the precise measurability and finiteness conditions under which the discarded part is well-defined and the mutual-information term is exactly the excess risk; any hidden dependence on the particular form of the representation map would weaken the claim.
minor comments (2)
- [Abstract / Introduction] Notation: the term 'source-minimal representation' is used in the abstract and introduction before its formal definition; a one-sentence gloss at first use would improve readability.
- [Experiments] Experiments: the controlled synthetic settings should report the exact pair of losses, the induced Bayes quotient, and the numerical value of the predicted conditional mutual information so that the quantitative identity can be directly checked.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of the work and for the detailed, constructive comments. Both major comments identify places where the proofs would benefit from additional explicit steps and stated conditions. We address each below and will revise the manuscript to incorporate the requested clarifications.
read point-by-point responses
-
Referee: [§3] §3 (Bayes-quotient refinement ordering): the argument that strict refinement forces insufficiency for every joint law P(X,Y) is load-bearing. The derivation must explicitly rule out the possibility that, for some P, the additional Bayes-relevant information required by the finer loss is already recoverable from (or irrelevant to) any source-minimal representation of the coarser loss; without this step the claimed distribution independence does not follow directly from the partial order.
Authors: We agree that an explicit treatment of these cases strengthens the argument. The Bayes-quotient partial order is defined solely from the loss functions and is therefore independent of P(X,Y). Strict refinement means there exist outcomes whose relative probabilities affect the finer loss but not the coarser loss. Any representation that is minimal for the coarser loss is permitted to discard information irrelevant to that loss; the refinement relation guarantees that this discarded information is precisely the additional Bayes-relevant information for the finer loss. To rule out the referee's concern, we will add a short paragraph in §3 that (i) considers an arbitrary P, (ii) notes that if the extra information happens to be recoverable from a particular minimal representation then that representation is no longer minimal for the coarser loss (by definition of minimality), and (iii) shows that when the information is irrelevant under P the excess risk is zero, which is consistent with but does not contradict the qualitative obstruction. This makes the distribution-independent claim fully rigorous. revision: yes
-
Referee: [§4.1] §4.1 (excess-risk identity for finite-output log loss): the identity equating excess risk to I(Y; discarded part | representation) is presented as following from the refinement relation. The proof should state the precise measurability and finiteness conditions under which the discarded part is well-defined and the mutual-information term is exactly the excess risk; any hidden dependence on the particular form of the representation map would weaken the claim.
Authors: The identity is stated for finite output spaces Y (as indicated by the section title and the abstract). Under the standing assumptions that the representation map is measurable and that the coarser representation is a sufficient statistic for the coarser loss, the sigma-algebra generated by the discarded information is well-defined and the conditional mutual information equals the excess log-loss risk exactly. There is no additional dependence on the concrete form of the map beyond the sufficiency property already used in the refinement relation. We will insert a short “Assumptions and notation” paragraph at the start of §4.1 that lists the conditions (finite Y, measurable maps, sufficiency for the coarser loss) and briefly recalls why they suffice for the information-theoretic identity to hold. revision: yes
Circularity Check
No circularity: derivation follows from independent definition of Bayes-quotient refinement.
full rationale
The paper introduces Bayes quotients as a new ordering on losses and states that strict refinement produces an immediate obstruction by the definition of the partial order itself. No equations reduce a prediction to a fitted input, no self-citation chain is load-bearing, and the quantitative identity for log loss is presented as a direct consequence of the ordering rather than a renaming or tautology. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
1950 , publisher =
Statistical Decision Functions , author =. 1950 , publisher =
1950
-
[2]
1985 , edition =
Statistical Decision Theory and Bayesian Analysis , author =. 1985 , edition =
1985
-
[3]
1996 , publisher =
A Probabilistic Theory of Pattern Recognition , author =. 1996 , publisher =
1996
-
[4]
2002 , edition =
Foundations of Modern Probability , author =. 2002 , edition =
2002
-
[5]
2007 , publisher =
Measure Theory , author =. 2007 , publisher =
2007
-
[6]
1998 , edition =
Theory of Point Estimation , author =. 1998 , edition =
1998
-
[7]
1954 , publisher =
Sufficiency and Statistical Decision Functions , author =. 1954 , publisher =
1954
-
[8]
The Annals of Mathematical Statistics , volume =
Equivalent Comparisons of Experiments , author =. The Annals of Mathematical Statistics , volume =. 1953 , doi =
1953
-
[9]
1991 , publisher =
Comparison of Statistical Experiments , author =. 1991 , publisher =
1991
-
[10]
Journal of the American Statistical Association , volume =
Elicitation of Personal Probabilities and Expectations , author =. Journal of the American Statistical Association , volume =. 1971 , doi =
1971
-
[11]
Journal of the American Statistical Association , volume =
Strictly Proper Scoring Rules, Prediction, and Estimation , author =. Journal of the American Statistical Association , volume =. 2007 , doi =
2007
-
[12]
Journal of the American Statistical Association , volume =
Making and Evaluating Point Forecasts , author =. Journal of the American Statistical Association , volume =. 2011 , doi =
2011
-
[13]
Annals of the Institute of Statistical Mathematics , volume =
The Geometry of Proper Scoring Rules , author =. Annals of the Institute of Statistical Mathematics , volume =. 2007 , doi =
2007
-
[14]
Metron , volume =
Theory and Applications of Proper Scoring Rules , author =. Metron , volume =. 2014 , doi =
2014
-
[15]
Proceedings of the 9th ACM Conference on Electronic Commerce , pages =
Eliciting Properties of Probability Distributions , author =. Proceedings of the 9th ACM Conference on Electronic Commerce , pages =. 2008 , doi =
2008
-
[16]
Proceedings of The 28th Conference on Learning Theory , series =
Vector-Valued Property Elicitation , author =. Proceedings of The 28th Conference on Learning Theory , series =. 2015 , publisher =
2015
-
[17]
Journal of the American Statistical Association , volume =
Sliced Inverse Regression for Dimension Reduction , author =. Journal of the American Statistical Association , volume =. 1991 , doi =
1991
-
[18]
1998 , publisher =
Regression Graphics: Ideas for Studying Regressions Through Graphics , author =. 1998 , publisher =
1998
-
[19]
Philosophical Transactions of the Royal Society A , volume =
Sufficient Dimension Reduction and Prediction in Regression , author =. Philosophical Transactions of the Royal Society A , volume =. 2009 , doi =
2009
-
[20]
2006 , edition =
Elements of Information Theory , author =. 2006 , edition =
2006
-
[21]
IEEE Transactions on Information Theory , volume =
Minimum Excess Risk in Bayesian Learning , author =. IEEE Transactions on Information Theory , volume =. 2022 , doi =
2022
-
[22]
Working Paper , year =
Loss Functions for Binary Class Probability Estimation and Classification: Structure and Applications , author =. Working Paper , year =
-
[23]
Journal of Machine Learning Research , volume =
Composite Binary Losses , author =. Journal of Machine Learning Research , volume =
-
[24]
Journal of the American Statistical Association , volume =
Convexity, Classification, and Risk Bounds , author =. Journal of the American Statistical Association , volume =. 2006 , doi =
2006
-
[25]
Proceedings of the 22nd International Conference on Machine Learning , pages =
Predicting Good Probabilities with Supervised Learning , author =. Proceedings of the 22nd International Conference on Machine Learning , pages =. 2005 , doi =
2005
-
[26]
Proceedings of the 34th International Conference on Machine Learning , series =
On Calibration of Modern Neural Networks , author =. Proceedings of the 34th International Conference on Machine Learning , series =. 2017 , publisher =
2017
-
[27]
Krizhevsky, Alex , title =
-
[28]
and Battleday, Ruairidh M
Peterson, Joshua C. and Battleday, Ruairidh M. and Griffiths, Thomas L. and Russakovsky, Olga , title =. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages =. 2019 , doi =
2019
-
[29]
Journal of Machine Learning Research , volume =
From Classification Accuracy to Proper Scoring Rules , author =. Journal of Machine Learning Research , volume =
-
[30]
International Conference on Learning Representations Workshop , year =
Understanding Intermediate Layers Using Linear Classifier Probes , author =. International Conference on Learning Representations Workshop , year =
-
[31]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
Momentum Contrast for Unsupervised Visual Representation Learning , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =. 2020 , doi =
2020
-
[32]
Proceedings of the 37th International Conference on Machine Learning , series =
A Simple Framework for Contrastive Learning of Visual Representations , author =. Proceedings of the 37th International Conference on Machine Learning , series =. 2020 , publisher =
2020
-
[33]
IEEE Transactions on Knowledge and Data Engineering , volume =
A Survey on Transfer Learning , author =. IEEE Transactions on Knowledge and Data Engineering , volume =. 2010 , doi =
2010
-
[34]
Proceedings of the IEEE , volume =
A Comprehensive Survey on Transfer Learning , author =. Proceedings of the IEEE , volume =. 2021 , doi =
2021
-
[35]
Advances in Neural Information Processing Systems , volume =
Ben-David, Shai and Blitzer, John and Crammer, Koby and Pereira, Fernando , title =. Advances in Neural Information Processing Systems , volume =
-
[36]
Machine Learning , volume =
Ben-David, Shai and Blitzer, John and Crammer, Koby and Kulesza, Alex and Pereira, Fernando and Vaughan, Jennifer Wortman , title =. Machine Learning , volume =. 2010 , doi =
2010
-
[37]
Dataset Shift in Machine Learning , publisher =
-
[38]
Domain-Adversarial Training of Neural Networks , journal =
Ganin, Yaroslav and Ustinova, Evgeniya and Ajakan, Hana and Germain, Pascal and Larochelle, Hugo and Laviolette, Fran. Domain-Adversarial Training of Neural Networks , journal =
-
[39]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume =
Bengio, Yoshua and Courville, Aaron and Vincent, Pascal , title =. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume =. 2013 , doi =
2013
-
[40]
and Bialek, William , title =
Tishby, Naftali and Pereira, Fernando C. and Bialek, William , title =. Proceedings of the 37th Annual Allerton Conference on Communication, Control, and Computing , pages =
-
[41]
Journal of Machine Learning Research , volume =
Achille, Alessandro and Soatto, Stefano , title =. Journal of Machine Learning Research , volume =
-
[42]
, title =
Zhao, Han and Des Combes, Remi Tachet and Zhang, Kun and Gordon, Geoffrey J. , title =. Proceedings of the 36th International Conference on Machine Learning , series =. 2019 , publisher =
2019
-
[43]
and Ghosh, Joydeep , title =
Banerjee, Arindam and Merugu, Srujana and Dhillon, Inderjit S. and Ghosh, Joydeep , title =. Journal of Machine Learning Research , volume =
-
[44]
2012 , isbn =
Sugiyama, Masashi and Kawanabe, Motoaki , title =. 2012 , isbn =
2012
-
[45]
Advances in Neural Information Processing Systems , volume =
Stojanov, Petar and Li, Zijian and Gong, Mingming and Cai, Ruichu and Carbonell, Jaime and Zhang, Kun , title =. Advances in Neural Information Processing Systems , volume =
-
[46]
and Gordon, Geoffrey J
Zhao, Han and Dan, Chen and Aragam, Bryon and Jaakkola, Tommi S. and Gordon, Geoffrey J. and Ravikumar, Pradeep , title =. Journal of Machine Learning Research , volume =
-
[47]
, title =
Frongillo, Rafael and Kash, Ian A. , title =. Advances in Neural Information Processing Systems , volume =
-
[48]
Dennis , title =
Chiaromonte, Francesca and Cook, R. Dennis , title =. Annals of the Institute of Statistical Mathematics , volume =. 2002 , doi =
2002
-
[49]
2026 , eprint=
Bayes-Sufficient Representations in Supervised Learning , author=. 2026 , eprint=
2026
-
[50]
2026 , eprint=
A Fiber Criterion for Representation Identifiability in Supervised Learning , author=. 2026 , eprint=
2026
-
[51]
Support Vector Machines , author =
-
[52]
Understanding Machine Learning: From Theory to Algorithms , author =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.