ReSum: Synergizing LLM Reasoning and Summarization with Reinforcement Learning
Pith reviewed 2026-06-27 06:38 UTC · model grok-4.3
The pith
ReSum trains LLMs to insert self-summaries that shorten reasoning rollouts while improving accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
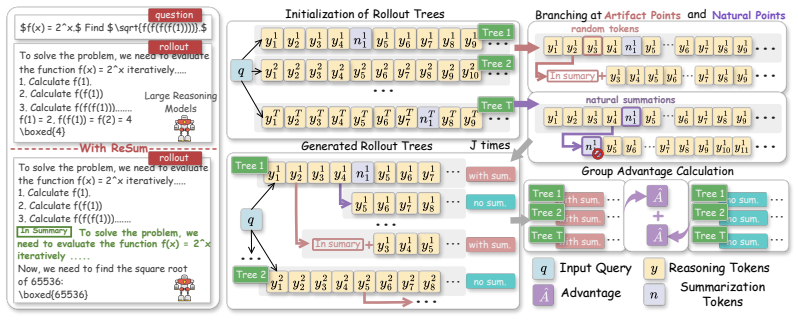
ReSum is an RLVR framework in which the model learns to trigger self-summarization during generation. When the phrase appears, the method masks it to form a contrastive branch and compares the outcome against the original trajectory; at other positions it randomly inserts the phrase to form matched branches. A summarization-aware advantage then scores the pairs at finer granularity, so the policy learns both to reason correctly and to organize its own trajectory by compression when useful.
What carries the argument
The summarization-aware adaptive rollout mechanism, which creates contrastive masked and injected branches around self-summarization points and scores them with a dedicated advantage function.
If this is right
- Models gain an internal way to manage context length instead of depending on external truncation rules.
- Early mistakes become less likely to derail the entire trajectory once a corrective summary can be inserted.
- Training simultaneously optimizes for answer correctness and for brevity in the reasoning path.
- The same contrastive idea can be applied on top of existing RLVR pipelines without changing the reward model.
Where Pith is reading between the lines
- The contrastive branch construction might be reusable for other meta-actions such as explicit backtracking or verification steps.
- If the learned policy generalizes, downstream applications could operate with smaller context windows while retaining reasoning quality.
- The method could be tested on tasks where the benefit of summarization is less obvious, such as short arithmetic chains.
Load-bearing premise
The entropy reduction and error-mitigation effects seen in pilot studies still appear when the same contrastive mechanism runs inside the complete RLVR loop on the main benchmarks.
What would settle it
Train an otherwise identical RLVR agent without the contrastive summarization branches and measure whether average rollout length and task accuracy remain unchanged on the evaluation suites.
Figures
read the original abstract
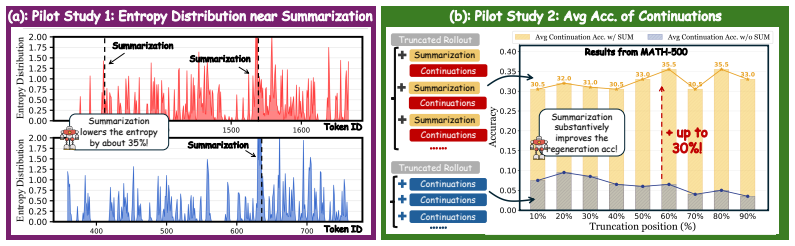
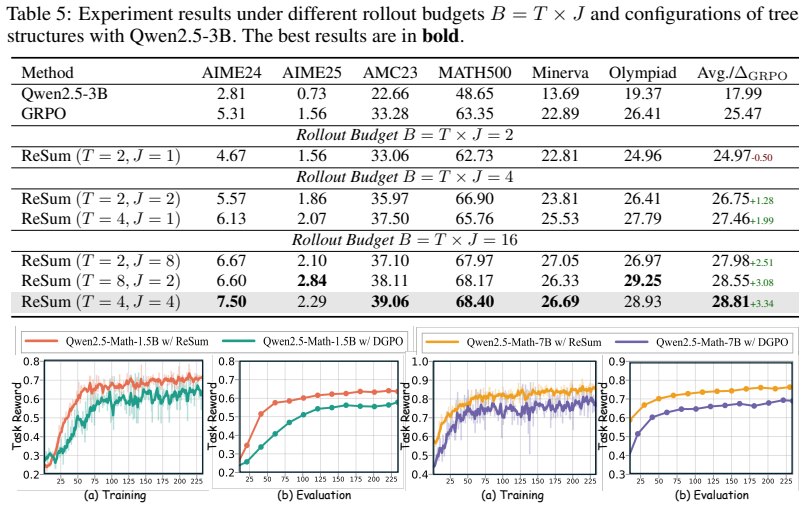
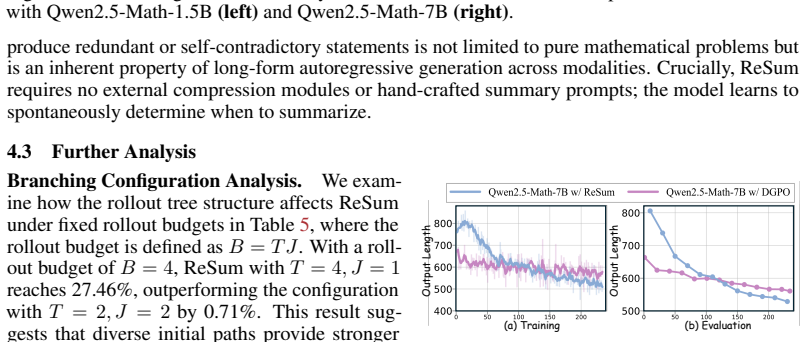
Reinforcement Learning with Verifiable Rewards (RLVR) is a central technique for improving long-horizon reasoning in Large Language Models (LLMs). However, existing RLVR methods often encourage unnecessarily long reasoning rollouts, which can degrade reasoning coherence and exhaust the available context budget. Existing approaches to long-context organization often depend on external mechanisms to organize rollouts, rather than enabling the model to manage its own reasoning trajectory. To address this limitation, we propose ReSum, a novel RLVR framework that enables LLMs to compress and organize their reasoning trajectories through self-summarization. Our pilot studies show that self-summarization stabilizes generation by lowering token-level entropy, and that introducing a ``summarization'' phrase can substantially mitigate errors propagated from an incorrect rollout prefix. Motivated by these findings, ReSum adopts a summarization-aware adaptive rollout mechanism that contrastively evaluates whether self-summarization benefits the ongoing reasoning process. Specifically, when the model spontaneously triggers self-summarization, ReSum masks the summarization phrase to create a contrastive branch; for non-summarization positions, it instead randomly injects the phrase to create a matched branch. We further design a summarization-aware advantage to enable finer-grained comparison between contrastive rollout trajectories. Extensive experiments show that ReSum improves performance at an average of 4\% while reducing rollout length by 18.6\%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ReSum, an RLVR framework that enables LLMs to perform self-summarization to compress and organize reasoning trajectories. Motivated by pilot studies showing that self-summarization lowers token-level entropy and that a summarization phrase mitigates error propagation from incorrect prefixes, it proposes a summarization-aware adaptive rollout mechanism that creates contrastive branches (masking the phrase on spontaneous triggers, randomly injecting it otherwise) plus a summarization-aware advantage. The central empirical claim is an average 4% performance improvement and 18.6% rollout length reduction.
Significance. If the results hold and the gains can be attributed to the claimed mechanism, the work would be significant for RLVR research: it offers an internal, model-driven approach to managing long reasoning rollouts instead of external organizers, with potential benefits for coherence and context efficiency in long-horizon tasks.
major comments (1)
- [Abstract / pilot studies] Abstract / pilot studies description: the 4% gain and 18.6% length reduction are attributed to the contrastive rollout mechanism, which is justified by the pilot observations on entropy reduction and error mitigation. No analysis or ablation is described showing that these effects persist once the policy is updated inside the RLVR loop (different distribution, different optimization pressure), so the contrastive branches may not isolate the intended benefit and the reported improvements cannot be confidently attributed to the adaptive mechanism.
minor comments (1)
- [Abstract] Abstract: no information is given on baselines, number of runs, statistical tests, datasets, or tasks, which weakens the ability to evaluate the central empirical claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the single major comment below and will revise the manuscript to strengthen the attribution of results to the proposed mechanism.
read point-by-point responses
-
Referee: [Abstract / pilot studies] Abstract / pilot studies description: the 4% gain and 18.6% length reduction are attributed to the contrastive rollout mechanism, which is justified by the pilot observations on entropy reduction and error mitigation. No analysis or ablation is described showing that these effects persist once the policy is updated inside the RLVR loop (different distribution, different optimization pressure), so the contrastive branches may not isolate the intended benefit and the reported improvements cannot be confidently attributed to the adaptive mechanism.
Authors: We agree that the pilot studies alone do not demonstrate persistence of the entropy and error-mitigation effects under the shifted distribution induced by RLVR updates. The pilots were intended only to motivate the design of the summarization-aware adaptive rollout and the contrastive branching procedure. The main experimental results reflect performance of the complete ReSum framework, in which the contrastive branches and summarization-aware advantage are active at every training step. To directly address the concern about isolation of the mechanism inside the training loop, we will add a new subsection containing (i) token-level entropy measurements on on-policy rollouts collected at multiple training checkpoints and (ii) an ablation that disables the contrastive masking/injection while keeping all other components fixed. These additions will be included in the revised manuscript. revision: yes
Circularity Check
No circularity: empirical outcomes independent of inputs
full rationale
The paper motivates its adaptive rollout mechanism from separate pilot observations on entropy and error propagation, then reports measured performance gains (4% average improvement, 18.6% length reduction) from full RLVR experiments on the resulting system. No equations, fitted parameters, or self-citations reduce the reported results to quantities defined by construction from the same inputs. The derivation chain consists of an empirical training procedure whose outputs are not tautological with its design choices.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Existing RLVR methods often encourage unnecessarily long reasoning rollouts that degrade coherence
Reference graph
Works this paper leans on
-
[1]
S. Bai, K. Chen, X. Liu, J. Wang, W. Ge, S. Song, K. Dang, P. Wang, S. Wang, J. Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923, 4(5), 1
- [2]
- [3]
-
[4]
J. Chen, J. Tang, J. Qin, X. Liang, L. Liu, E. Xing, and L. Lin. Geoqa: A geometric question answering benchmark towards multimodal numerical reasoning. InFindings of the Association for Computational Linguistics: ACL-IJCNLP 2021, pages 513–523, 2021
2021
-
[5]
L. Chen, L. Li, H. Zhao, and Y . Song. Vinci. r1-v: Reinforcing super generalization ability in vision- language models with less than $3, 2025
2025
-
[6]
L. Chen, Z. Liu, W. He, Y . Zheng, H. Sun, Y . Li, R. Luo, and M. Yang. Long context is not long at all: A prospector of long-dependency data for large language models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8222–8234, 2024
2024
-
[7]
X. Chen, J. Xu, T. Liang, Z. He, J. Pang, D. Yu, L. Song, Q. Liu, M. Zhou, Z. Zhang, et al. Do not think that much for 2+ 3=? on the overthinking of o1-like llms.arXiv preprint arXiv:2412.21187, 2024
Pith/arXiv arXiv 2024
-
[8]
X. Chu, H. Huang, X. Zhang, F. Wei, and Y . Wang. GPG: A simple and strong reinforcement learning baseline for model reasoning. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[9]
Y . Dai, Y . Ji, X. Zhang, Y . Wang, X. Chu, and Z. Lu. Harder is better: Boosting mathematical reasoning via difficulty-aware GRPO and multi-aspect question reformulation. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[10]
Y . Dai, J. Lian, Y . Huang, W. Zhang, M. Zhou, M. Wu, X. Xie, and H. Liao. Pretraining context compressor for large language models with embedding-based memory. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 28715–28732, 2025
2025
-
[11]
G. Dong, L. Bao, Z. Wang, K. Zhao, X. Li, J. Jin, J. Yang, H. Mao, F. Zhang, K. Gai, et al. Agentic entropy-balanced policy optimization.arXiv preprint arXiv:2510.14545, 2025
arXiv 2025
-
[12]
G. Dong, H. Mao, K. Ma, L. Bao, Y . Chen, Z. Wang, Z. Chen, J. Du, H. Wang, F. Zhang, et al. Agentic reinforced policy optimization.arXiv preprint arXiv:2507.19849, 2025
Pith/arXiv arXiv 2025
-
[13]
Z. Dong, J. Li, J. Jiang, M. Xu, W. X. Zhao, B. Wang, and W. Chen. Longred: Mitigating short-text degradation of long-context large language models via restoration distillation. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 10687–10707, 2025
2025
-
[14]
H. Face. Open r1: A fully open reproduction of deepseek-r1, january 2025.URL https://github. com/huggingface/open-r1, 7, 2025
2025
-
[15]
L. Feng, Z. Xue, T. Liu, and B. An. Group-in-group policy optimization for llm agent training.arXiv preprint arXiv:2505.10978, 2025
Pith/arXiv arXiv 2025
-
[16]
J. Gao, W. Fu, M. Xie, S. Xu, C. He, Z. Mei, B. Zhu, and Y . Wu. Beyond ten turns: Unlocking long-horizon agentic search with large-scale asynchronous rl.arXiv preprint arXiv:2508.07976, 2025
arXiv 2025
-
[17]
T. Ge, J. Hu, L. Wang, X. Wang, S.-Q. Chen, and F. Wei. In-context autoencoder for context compression in a large language model.arXiv preprint arXiv:2307.06945, 2023
arXiv 2023
-
[18]
D. Guo, D. Yang, H. Zhang, J. Song, P. Wang, Q. Zhu, R. Xu, R. Zhang, S. Ma, X. Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
Pith/arXiv arXiv 2025
-
[19]
R. Guo, Y . Liu, G. Ma, Y . Wang, Y . Zhang, L. Xia, K. Chen, Z. Sun, and D. Shi. When less is more: The llm scaling paradox in context compression.arXiv preprint arXiv:2602.09789, 2026. 10
Pith/arXiv arXiv 2026
-
[20]
C. He, R. Luo, Y . Bai, S. Hu, Z. Thai, J. Shen, J. Hu, X. Han, Y . Huang, Y . Zhang, et al. Olympiadbench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 3828–3850, 2024
2024
-
[21]
D. Hendrycks, C. Burns, S. Kadavath, A. Arora, S. Basart, E. Tang, D. Song, and J. Steinhardt. Measuring mathematical problem solving with the math dataset.arXiv preprint arXiv:2103.03874, 2021
Pith/arXiv arXiv 2021
-
[22]
C. R. C. Hooper, S. Kim, H. Mohammadzadeh, M. Maheswaran, S. Zhao, J. Paik, M. W. Mahoney, K. Keutzer, and A. Gholami. Squeezed attention: Accelerating long context length llm inference. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 32631–32652, 2025
2025
-
[23]
Z. Hou, Z. Hu, Y . Li, R. Lu, J. Tang, and Y . Dong. Treerl: Llm reinforcement learning with on-policy tree search. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 12355–12369, 2025
2025
-
[24]
Y . Ji, Z. Ma, Y . Wang, G. Chen, X. Chu, and L. Wu. Tree search for llm agent reinforcement learning. arXiv preprint arXiv:2509.21240, 2025
arXiv 2025
-
[25]
B. Jin, H. Zeng, Z. Yue, J. Yoon, S. Arik, D. Wang, H. Zamani, and J. Han. Search-r1: Training llms to reason and leverage search engines with reinforcement learning.arXiv preprint arXiv:2503.09516, 2025
Pith/arXiv arXiv 2025
-
[26]
H. Y . Koh, J. Ju, M. Liu, and S. Pan. An empirical survey on long document summarization: Datasets, models, and metrics.ACM computing surveys, 55(8):1–35, 2022
2022
-
[27]
X. Lai, Z. Tian, Y . Chen, S. Yang, X. Peng, and J. Jia. Step-dpo: Step-wise preference optimization for long-chain reasoning of llms.arXiv preprint arXiv:2406.18629, 2024
Pith/arXiv arXiv 2024
-
[28]
Lewkowycz, A
A. Lewkowycz, A. Andreassen, D. Dohan, E. Dyer, H. Michalewski, V . Ramasesh, A. Slone, C. Anil, I. Schlag, T. Gutman-Solo, et al. Solving quantitative reasoning problems with language models.Advances in neural information processing systems, 35:3843–3857, 2022
2022
-
[29]
C. Li, X. Liu, Z. Zhang, S. Zhang, S. Liu, G. Ma, Y . Lan, and C. Shen. Upfront chain-of-thought: A cooperative framework for chain-of-thought compression.arXiv preprint arXiv:2510.08647, 2025
Pith/arXiv arXiv 2025
-
[30]
J. Li, X. Dong, Y . Liu, Z. Yang, Q. Wang, X. Wang, S.-C. Zhu, Z. Jia, and Z. Zheng. Reflectevo: Improving meta introspection of small llms by learning self-reflection. InFindings of the Association for Computational Linguistics: ACL 2025, pages 16948–16966, 2025
2025
-
[31]
R. Li, H. Huang, F. Wei, F. Xiong, Y . Wang, and X. Chu. Adacurl: Adaptive curriculum reinforcement learning with invalid sample mitigation and historical revisiting. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 23123–23131, 2026
2026
-
[32]
X. Li, G. Dong, J. Jin, Y . Zhang, Y . Zhou, Y . Zhu, P. Zhang, and Z. Dou. Search-o1: Agentic search- enhanced large reasoning models. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 5420–5438, 2025
2025
-
[33]
Z. Li, Y . Hu, and W. Wang. Encouraging good processes without the need for good answers: Reinforcement learning for llm agent planning. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: Industry Track, pages 1654–1666, 2025
2025
-
[34]
Lightman, V
H. Lightman, V . Kosaraju, Y . Burda, H. Edwards, B. Baker, T. Lee, J. Leike, J. Schulman, I. Sutskever, and K. Cobbe. Let’s verify step by step. InThe twelfth international conference on learning representations, 2023
2023
-
[35]
Z. Ling, K. Liu, K. Yan, Y . Yang, W. Lin, T.-H. Fan, L. Shen, Z. Du, and J. Chen. Longreason: A synthetic long-context reasoning benchmark via context expansion.arXiv preprint arXiv:2501.15089, 2025
arXiv 2025
-
[36]
S. Liu, R. Li, L. Yu, L. Zhang, Z. Liu, and G. Jin. Badthink: Triggered overthinking attacks on chain- of-thought reasoning in large language models. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 32141–32149, 2026
2026
-
[37]
S. Liu, H. Yuan, M. Hu, Y . Li, Y . Chen, S. Liu, Z. Lu, and J. Jia. Rl-gpt: Integrating reinforcement learning and code-as-policy.Advances in Neural Information Processing Systems, 37:28430–28459, 2024
2024
-
[38]
X. Liu, R. Zhao, P. Huang, C. Xiao, B. Li, J. Wang, T. Xiao, and J. Zhu. Forgetting curve: A reliable method for evaluating memorization capability for long-context models. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 4667–4682, 2024. 11
2024
-
[39]
Z. Liu, C. Chen, W. Li, P. Qi, T. Pang, C. Du, W. S. Lee, and M. Lin. Understanding r1-zero-like training: A critical perspective.arXiv preprint arXiv:2503.20783, 2025
Pith/arXiv arXiv 2025
-
[40]
Y . Long, X. Wu, Y . Zhang, X. Wen, Y . Zhou, and S. Hong. Copy-paste to mitigate large language model hallucinations.arXiv preprint arXiv:2510.00508, 2025
arXiv 2025
-
[41]
Longpre, K
S. Longpre, K. Perisetla, A. Chen, N. Ramesh, C. DuBois, and S. Singh. Entity-based knowledge conflicts in question answering. InProceedings of the 2021 conference on empirical methods in natural language processing, pages 7052–7063, 2021
2021
-
[42]
Z. Lu, Y . Chai, Y . Guo, X. Yin, L. Liu, H. Wang, H. Xiao, S. Ren, P. Zhao, G. Liu, et al. Ui-r1: Enhancing efficient action prediction of gui agents by reinforcement learning. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 17608–17616, 2026
2026
-
[43]
R. Luo, L. Wang, W. He, L. Chen, J. Li, and X. Xia. Gui-r1: A generalist r1-style vision-language action model for gui agents.arXiv preprint arXiv:2504.10458, 2025
Pith/arXiv arXiv 2025
-
[44]
C. Ma, S. Yang, K. Huang, J. Lu, H. Meng, S. Wang, B. Ding, S. V osoughi, G. Wang, and J. Zhou. Fipo: Eliciting deep reasoning with future-kl influenced policy optimization.arXiv preprint arXiv:2603.19835, 2026
arXiv 2026
-
[45]
D. Ma, L. Chen, S. Zhang, Y . Miao, S. Zhu, Z. Chen, H. Xu, H. Li, S. Fan, L. Pan, et al. Compressing kv cache for long-context llm inference with inter-layer attention similarity. InICASSP 2026-2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 16407–16411. IEEE, 2026
2026
-
[46]
Z. Ma, S. Yang, Y . Ji, X. Wang, Y . Wang, Y . Hu, T. Huang, and X. Chu. Skillclaw: Let skills evolve collectively with agentic evolver.arXiv preprint arXiv:2604.08377, 2026
Pith/arXiv arXiv 2026
-
[47]
X. Mai, H. Xu, Z.-Z. Li, W. Wang, J. Hu, Y . Zhang, W. Zhang, et al. Agent rl scaling law: Agent rl with spontaneous code execution for mathematical problem solving.arXiv preprint arXiv:2505.07773, 2025
arXiv 2025
-
[48]
the moon is made of marshmallows
Y . Ming, S. Purushwalkam, S. Pandit, Z. Ke, X.-P. Nguyen, C. Xiong, and S. Joty. Faitheval: Can your language model stay faithful to context, even if" the moon is made of marshmallows".arXiv preprint arXiv:2410.03727, 2024
arXiv 2024
-
[49]
Muennighoff, Z
N. Muennighoff, Z. Yang, W. Shi, X. L. Li, L. Fei-Fei, H. Hajishirzi, L. Zettlemoyer, P. Liang, E. Candès, and T. B. Hashimoto. s1: Simple test-time scaling. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 20286–20332, 2025
2025
-
[50]
D. Paul, M. Ismayilzada, M. Peyrard, B. Borges, A. Bosselut, R. West, and B. Faltings. Refiner: Reasoning feedback on intermediate representations. InProceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1100–1126, 2024
2024
- [51]
-
[52]
Rafailov, A
R. Rafailov, A. Sharma, E. Mitchell, C. D. Manning, S. Ermon, and C. Finn. Direct preference optimization: Your language model is secretly a reward model.Advances in neural information processing systems, 36:53728–53741, 2023
2023
-
[53]
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017
Pith/arXiv arXiv 2017
-
[54]
Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, X. Bi, H. Zhang, M. Zhang, Y . Li, Y . Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
Pith/arXiv arXiv 2024
-
[55]
Y . Shi, W. Yu, Z. Li, Y . Wang, H. Zhang, N. Liu, H. Mi, and D. Yu. Mobilegui-rl: Advancing mobile gui agent through reinforcement learning in online environment.arXiv preprint arXiv:2507.05720, 2025
arXiv 2025
-
[56]
G. Srivastava, A. Hussain, S. Srinivasan, and X. Wang. Do llms overthink basic math reasoning? bench- marking the accuracy-efficiency tradeoff in language models.arXiv preprint arXiv:2507.04023, 2025
Pith/arXiv arXiv 2025
-
[57]
Y . Tian, Z. Wang, Y . Peng, A. Yuan, Z. Wang, B. Yi, X. Liu, Y . Cui, and T. Yang. Keepkv: Achieving periodic lossless kv cache compression for efficient llm inference. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 33259–33267, 2026. 12
2026
-
[58]
L. Wang, W. Xu, Y . Lan, Z. Hu, Y . Lan, R. K.-W. Lee, and E.-P. Lim. Plan-and-solve prompting: Improving zero-shot chain-of-thought reasoning by large language models. InProceedings of the 61st annual meeting of the association for computational linguistics (volume 1: long papers), pages 2609–2634, 2023
2023
-
[59]
P. Wang, S. Xu, J. Li, Y . Luo, D. Li, J. Hao, and M. Zhang.Re2: Unlocking llm reasoning via reinforcement learning with re-solving.arXiv preprint arXiv:2603.07197, 2026
arXiv 2026
-
[60]
Z. Wang, X. Zheng, K. An, C. Ouyang, J. Cai, Y . Wang, and Y . Wu. Stepsearch: Igniting llms search ability via step-wise proximal policy optimization.arXiv preprint arXiv:2505.15107, 2025
arXiv 2025
-
[61]
X. Wu, K. Li, Y . Zhao, L. Zhang, L. Ou, H. Yin, Z. Zhang, X. Yu, D. Zhang, Y . Jiang, et al. Resum: Unlocking long-horizon search intelligence via context summarization.arXiv preprint arXiv:2509.13313, 2025
arXiv 2025
-
[62]
Y . Wu, Y . Wang, Z. Ye, T. Du, S. Jegelka, and Y . Wang. When more is less: Understanding chain-of-thought length in llms.arXiv preprint arXiv:2502.07266, 2025
arXiv 2025
-
[63]
Y . Xie, A. Goyal, W. Zheng, M.-Y . Kan, T. P. Lillicrap, K. Kawaguchi, and M. Shieh. Monte carlo tree search boosts reasoning via iterative preference learning.arXiv preprint arXiv:2405.00451, 2024
arXiv 2024
- [64]
-
[65]
A. Yang, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Li, D. Liu, F. Huang, H. Wei, et al. Qwen2. 5 technical report. Technical report, 2024
2024
-
[66]
A. Yang, B. Zhang, B. Hui, B. Gao, B. Yu, C. Li, D. Liu, J. Tu, J. Zhou, J. Lin, et al. Qwen2. 5-math technical report: Toward mathematical expert model via self-improvement.arXiv preprint arXiv:2409.12122, 2024
Pith/arXiv arXiv 2024
-
[67]
D. Yang, X. Han, Y . Gao, Y . Hu, S. Zhang, and H. Zhao. Pyramidinfer: Pyramid kv cache compression for high-throughput llm inference. InFindings of the Association for Computational Linguistics: ACL 2024, pages 3258–3270, 2024
2024
-
[68]
Q. Yu, Z. Zhang, R. Zhu, Y . Yuan, X. Zuo, Y . Yue, W. Dai, T. Fan, G. Liu, L. Liu, et al. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476, 2025
Pith/arXiv arXiv 2025
-
[69]
X. Yuan, J. Zhang, K. Li, Z. Cai, L. Yao, J. Chen, E. Wang, Q. Hou, J. Chen, P.-T. Jiang, et al. En- hancing visual grounding for gui agents via self-evolutionary reinforcement learning.arXiv preprint arXiv:2505.12370, 2025
arXiv 2025
-
[70]
Zhang and C
J. Zhang and C. Zuo. Grpo-lead: A difficulty-aware reinforcement learning approach for concise mathe- matical reasoning in language models. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 5642–5665, 2025
2025
-
[71]
Q. Zhang, C. Hu, S. Upasani, B. Ma, F. Hong, V . Kamanuru, J. Rainton, C. Wu, M. Ji, H. Li, et al. Agentic context engineering: Evolving contexts for self-improving language models.arXiv preprint arXiv:2510.04618, 2025
Pith/arXiv arXiv 2025
- [72]
-
[73]
X. F. Zhang, A. Mohananey, A. Chronopoulou, P. Papalampidi, S. Gupta, T. Munkhdalai, L. Wang, and S. Upadhyay. Do llms really need 10+ thoughts for" find the time 1000 days later"? towards structural understanding of llm overthinking.arXiv preprint arXiv:2510.07880, 2025
arXiv 2025
-
[74]
X. Zhao, T. Xu, X. Wang, Z. Chen, D. Jin, L. Tan, Z. Yu, Z. Zhao, Y . He, S. Wang, et al. Boosting llm reasoning via spontaneous self-correction.arXiv preprint arXiv:2506.06923, 2025
arXiv 2025
-
[75]
Y . Zhao, W. Huang, S. Wang, R. Zhao, C. Chen, Y . Shu, and C. Qin. Training multi-turn search agent via contrastive dynamic branch sampling.arXiv preprint arXiv:2602.03719, 2026
Pith/arXiv arXiv 2026
-
[76]
Y . Zhao, Y . Liu, J. Liu, J. Chen, X. Wu, Y . Hao, T. Lv, S. Huang, L. Cui, Q. Ye, et al. Geometric-mean policy optimization.arXiv preprint arXiv:2507.20673, 2025
arXiv 2025
-
[77]
C. Zheng, S. Liu, M. Li, X.-H. Chen, B. Yu, C. Gao, K. Dang, Y . Liu, R. Men, A. Yang, et al. Group sequence policy optimization.arXiv preprint arXiv:2507.18071, 2025. 13 Appendix ReSum: Synergizing LLM Reasoning and Summarization with Reinforcement Learning The Appendix of the paper is organized as: • Appendix A: We give the proof of the proposition. • A...
Pith/arXiv arXiv 2025
-
[78]
Isolate one of the square roots. 2. Square both sides to eliminate the square root. 3. Simplify and isolate the remaining square root. 4. Square both sides again to eliminate the remaining square root. 5. Solve the resulting equation for x. 6. Verify the solution by substituting back into the original equation. Let’s implement this step-by-step in Python ...
-
[79]
Lety i =x i −1
Variable substitution. Lety i =x i −1. Then0≤y i ≤3and the equation becomes y1 +y 2 +y 3 +y 4 = 6
-
[80]
By stars and bars, the total number of non-negative integer solutions is 6 + 4−1 4−1 = 9 3 = 84
Unconstrained count. By stars and bars, the total number of non-negative integer solutions is 6 + 4−1 4−1 = 9 3 = 84
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.