HyperTool: Beyond Step-Wise Tool Calls for Tool-Augmented Agents
Pith reviewed 2026-06-27 06:33 UTC · model grok-4.3
The pith
HyperTool changes tool execution from step-wise calls to single code-block invocations, lifting accuracy on multi-tool tasks from 10-16 percent to 33-35 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that folding locally deterministic tool workflows into a single model-visible HyperTool call, rather than unfolding them into repeated step-wise decisions, allows models to use tools more effectively. By training on synthesized HyperTool-format trajectories, both larger and smaller models achieve roughly doubled accuracy on the MCP-Universe benchmark and surpass certain stronger baselines.
What carries the argument
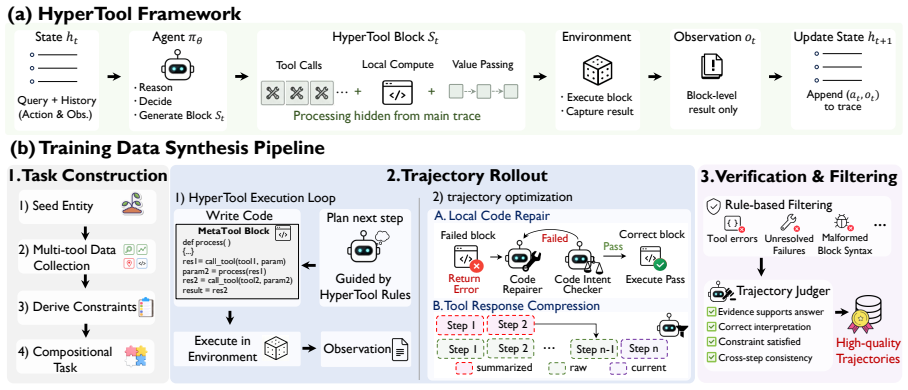
HyperTool, a unified executable MCP-style tool interface that accepts a code block capable of calling original tool schemas, manipulating returned values, and passing intermediate results locally.
If this is right
- Average accuracy on MCP-Universe increases substantially for Qwen3 models of different sizes.
- The HyperTool approach outperforms GPT-OSS and Kimi-k2.5 on average accuracy.
- Synthesized trajectories from cross-tool tasks transfer to real MCP environments.
- Changing execution granularity improves multi-step tool use.
Where Pith is reading between the lines
- The same granularity reduction could apply to other domains with deterministic subroutines, such as code generation or planning.
- Models might handle longer task horizons because fewer steps appear in the context.
- Automatic synthesis of HyperTools from observed trajectories could further scale the method.
Load-bearing premise
The performance gains result from the altered execution granularity and not from incidental differences in training data volume or fine-tuning procedure.
What would settle it
Train a control model on the same number of trajectories but kept in standard step-wise format, then compare its MCP-Universe accuracy directly to the HyperTool-trained model; if the gap disappears, the granularity change is not the cause.
Figures








read the original abstract
Tool-augmented LLM agents commonly rely on step-wise atomic tool calls, where each invocation, observation, and value transfer is exposed in the main reasoning trace. This creates an \emph{execution-granularity mismatch}: locally deterministic tool workflows are unfolded into repeated model-visible decisions, consuming context and forcing the model to manage low-level dataflow in the trace. We introduce \textbf{HyperTool}, a unified executable MCP-style tool interface that changes the model-visible unit of tool execution. A model invokes HyperTool with a code block that can call existing tools through their original schemas, manipulate returned values, and pass intermediate results locally, folding deterministic tool subroutines into a single outer call. To train models to use this interface, we synthesize HyperTool-format trajectories from cross-tool compositional tasks and verify them in real MCP environments. On MCP-Universe, HyperTool improves average accuracy from 15.69\% to 35.29\% on Qwen3-32B and from 9.93\% to 33.33\% on Qwen3-8B, and surpass GPT-OSS and Kimi-k2.5 on average accuracy, showing that our HyperTool can substantially improve multi-step tool use.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces HyperTool, a unified executable MCP-style tool interface allowing LLM agents to invoke a single code block that calls existing tools via their schemas, manipulates returned values, and handles local dataflow. This folds deterministic subroutines into one outer call to address execution-granularity mismatch in step-wise tool calling. Trajectories are synthesized from cross-tool compositional tasks and verified in real MCP environments. On the MCP-Universe benchmark, the approach reports accuracy gains from 15.69% to 35.29% on Qwen3-32B and from 9.93% to 33.33% on Qwen3-8B, surpassing GPT-OSS and Kimi-k2.5 on average accuracy.
Significance. If the accuracy improvements can be isolated to the change in model-visible execution granularity (rather than differences in training data volume or fine-tuning), the work would provide a practical mechanism for reducing context consumption and model involvement in low-level deterministic workflows in tool-augmented agents. The synthesis of trajectories and verification in actual MCP environments constitutes a concrete, reproducible training pipeline that could be extended to other agent settings.
major comments (3)
- [Abstract / experimental results] Abstract and experimental results: The reported accuracy lifts (15.69%→35.29% on Qwen3-32B; 9.93%→33.33% on Qwen3-8B) are presented without any information on baseline construction, including whether the step-wise models were trained on identical data volume, identical number of trajectories, identical fine-tuning steps, or the same verification pipeline. This directly undermines attribution of the delta to the HyperTool granularity change.
- [Abstract / experimental results] Abstract and results: No statistical significance, standard deviations, number of runs, or data exclusion rules are reported for the benchmark numbers, preventing evaluation of whether the observed improvements exceed noise.
- [Method (trajectory synthesis)] Trajectory synthesis description: The claim that synthesized HyperTool-format trajectories from cross-tool compositional tasks are representative of real MCP environments lacks supporting experiments (e.g., comparison of synthesized vs. naturally occurring trajectories or ablation on synthesis quality), which is load-bearing for the training methodology.
minor comments (2)
- [Abstract] Abstract: 'surpass GPT-OSS and Kimi-k2.5' should read 'surpasses' for subject-verb agreement.
- [Abstract] Abstract: The acronym 'MCP' is introduced without expansion on first use.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on experimental clarity and methodology. We address each major comment below with clarifications and proposed revisions.
read point-by-point responses
-
Referee: [Abstract / experimental results] Abstract and experimental results: The reported accuracy lifts (15.69%→35.29% on Qwen3-32B; 9.93%→33.33% on Qwen3-8B) are presented without any information on baseline construction, including whether the step-wise models were trained on identical data volume, identical number of trajectories, identical fine-tuning steps, or the same verification pipeline. This directly undermines attribution of the delta to the HyperTool granularity change.
Authors: We agree that the manuscript should explicitly document baseline equivalence. The step-wise baselines were trained on the identical set of trajectories synthesized from the same cross-tool compositional tasks, using the same number of fine-tuning steps and the same verification pipeline in real MCP environments; the sole controlled difference is the tool-call format. We will revise the experimental setup section and abstract to state these details explicitly. revision: yes
-
Referee: [Abstract / experimental results] Abstract and results: No statistical significance, standard deviations, number of runs, or data exclusion rules are reported for the benchmark numbers, preventing evaluation of whether the observed improvements exceed noise.
Authors: We acknowledge that statistical details are missing. Evaluations were performed as single runs owing to the substantial compute required for fine-tuning Qwen3-32B. No trajectories were excluded. We will add a note in the results section stating that figures reflect single-run evaluations and list this as a limitation. revision: yes
-
Referee: [Method (trajectory synthesis)] Trajectory synthesis description: The claim that synthesized HyperTool-format trajectories from cross-tool compositional tasks are representative of real MCP environments lacks supporting experiments (e.g., comparison of synthesized vs. naturally occurring trajectories or ablation on synthesis quality), which is load-bearing for the training methodology.
Authors: The synthesis draws directly from cross-tool compositional tasks whose outputs are subsequently verified for successful execution inside real MCP environments. While we do not include an explicit ablation against naturally occurring trajectories, the verification step constitutes direct evidence of environmental fidelity. We will expand the method section with additional description of the synthesis procedure and its grounding in verified MCP execution. revision: partial
Circularity Check
No circularity: empirical benchmark results with no derivation chain or self-referential fitting
full rationale
The paper reports experimental accuracy gains on the MCP-Universe benchmark after synthesizing HyperTool-format trajectories and fine-tuning models. No equations, first-principles derivations, fitted parameters, or predictions appear that reduce to their own inputs by construction. The central claims rest on reported benchmark deltas rather than any mathematical reduction or self-citation load-bearing step. Potential confounding factors such as training data volume are questions of experimental isolation, not circularity in a claimed derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
J Gateway Condo, Singapore
maps_geocode(address="J Gateway Condo, Singapore") -> lat=1.3357764, lng=103.7424381
-
[2]
Park Place Residences at PLQ, Singapore
maps_geocode(address="Park Place Residences at PLQ, Singapore") -> lat=1.3163901, lng=103.8927333
-
[3]
cafe", location={
maps_search_places(query="cafe", location={"latitude": 1.32608325, "longitude": 103.8175857}, radius=5000) -> initial cafe candidates
-
[4]
J Gateway Condo, Singapore
maps_distance_matrix(origins=["J Gateway Condo, Singapore"], destinations=[initial cafe candidates], mode="driving")
-
[5]
Park Place Residences at PLQ, Singapore
maps_distance_matrix(origins=["Park Place Residences at PLQ, Singapore"], destinations=[initial cafe candidates], mode="walking")
-
[6]
Compare |driving_time - walking_time| for all initial candidates -> best initial candidate: Ms Durian | Speciality Bakery & Cafe, diff=1953
1953
-
[7]
cafe", location={
maps_search_places(query="cafe", location={"latitude": 1.3163901, "longitude": 103.8927333}, radius=5000) -> expanded candidate set near Park Place Residences at PLQ
-
[8]
J Gateway Condo, Singapore
maps_distance_matrix(origins=["J Gateway Condo, Singapore"], destinations=[expanded cafe candidates], mode="driving")
-
[9]
Park Place Residences at PLQ, Singapore
maps_distance_matrix(origins=["Park Place Residences at PLQ, Singapore"], destinations=[expanded cafe candidates], mode="walking")
-
[10]
Compare |driving_time - walking_time| for all expanded candidates -> best candidate: Knots Cafe & Living (Paya Lebar), driving_time=1812, walking_time=1654, diff=158
-
[11]
Knots Cafe & Living (Paya Lebar)
maps_search_places(query="Knots Cafe & Living (Paya Lebar)") -> types=["cafe", "restaurant", "point_of_interest", "store", "food", "establishment"] Final answer: {"stops": [{"name": "Knots Cafe & Living (Paya Lebar)", "place id": "ChIJKXkHO4sX2jERhWTgW68Gs44"}]} Figure 9: Trajectory trace for Case 1: Standard Step-wise MCP execution. 14 Case 2: One-call H...
-
[12]
param":
The only tool you can call directly isHyperTool. Other tools can only be called through HyperTool by usingcall_tool(server_name, tool_name, {"param": "value"})—note double braces in format string
-
[13]
You must carefully read the tool descriptions and the tool output format, and use the exact argument names as specified without deviation
-
[14]
If a tool returns empty,None, or unexpected output, you MUST diagnose and retry with a corrected approach
Do not introduce unsupported facts; use reasoning to interpret tool results, but ensure conclusions are evidence-grounded. If a tool returns empty,None, or unexpected output, you MUST diagnose and retry with a corrected approach
-
[15]
The variables in different HyperTool code blocks are not reusable
-
[16]
Only use fields explicitly provided in the tool output, and eliminate any irrelevant or noisy data
Carefully follow the tool output format and implement simple data processing logic within the HyperTool code block to extract the required information. Only use fields explicitly provided in the tool output, and eliminate any irrelevant or noisy data
-
[17]
result"as the variable name to store the final result
Remember each HyperTool code block must use"result"as the variable name to store the final result."result"must contain the actual data returned by tool calls (or processed/extracted values derived from it), never a hand-written status string like"done"or "completed". Do not use print statements to print the result. E.2 Prompt of Trajectory Judge Task $QUE...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.