NeRD: Neuro-Symbolic Rule Distillation for Efficient Ontology-Grounded Chain-of-Thought in Medical Image Diagnosis
Pith reviewed 2026-06-27 04:17 UTC · model grok-4.3
The pith
NeRD distills neuro-symbolic rules to create efficient, ontology-grounded diagnostic reasoning chains without manual crafting.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
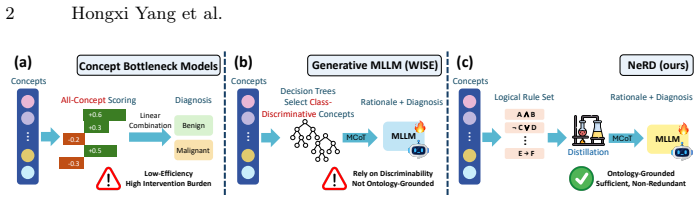
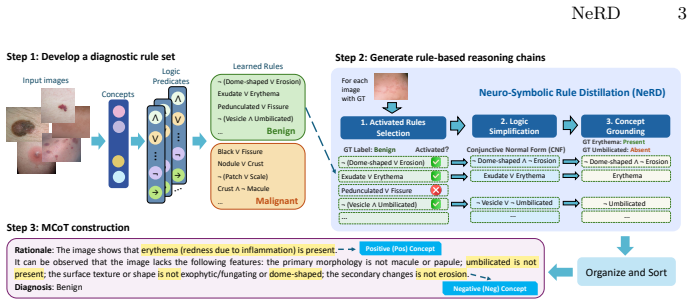
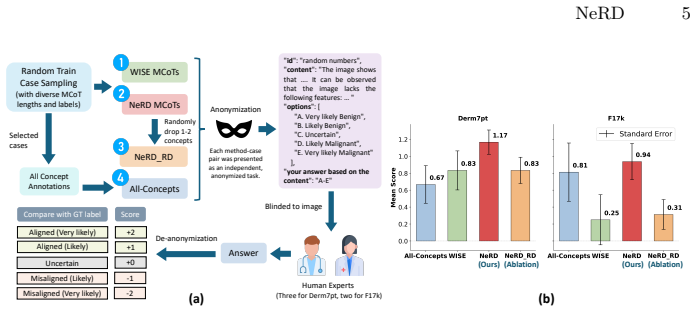
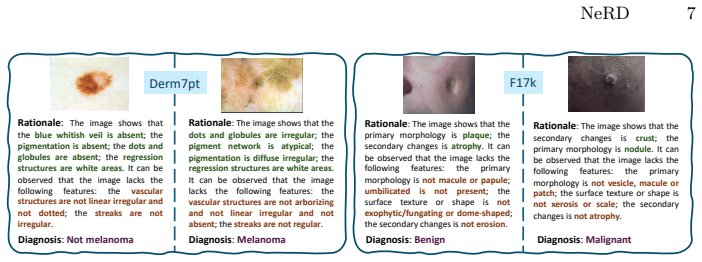
NeRD is a neuro-symbolic rule distillation framework that automatically extracts rules aligned with diagnostic ontologies to produce efficient, sufficient, and non-redundant chain-of-thought reasoning for medical image diagnosis, achieving strong performance, interpretability, and clinical plausibility on skin datasets without manual rule design.
What carries the argument
Neuro-Symbolic Rule Distillation, which extracts and compresses rules from neural predictions into ontology-grounded chains of thought.
If this is right
- Diagnostic performance remains strong on skin image datasets while using fewer concepts than full concept bottleneck models.
- Reasoning chains are interpretable and traceable to ontology elements.
- Blinded experts judge the rationales as clinically plausible.
- The system supports efficient multimodal chain-of-thought diagnosis with concept-level expert intervention.
Where Pith is reading between the lines
- The approach could lower clinician workload at inference by avoiding exhaustive concept scoring.
- If the distillation generalizes, similar pipelines might apply to other imaging modalities where ontologies exist.
- Traceable rules could support regulatory review of diagnostic AI by linking outputs directly to established medical knowledge.
Load-bearing premise
The distillation process can automatically produce rules that stay aligned with diagnostic ontologies and remain clinically plausible without manual intervention or post-hoc fixes.
What would settle it
A blinded expert panel rating a majority of NeRD rationales as clinically implausible or ontology-misaligned on the skin datasets would falsify the central claim.
Figures
read the original abstract
Interpretability is essential for trustworthy medical image diagnosis. However, existing concept-driven interpretable methods have key limitations: Concept Bottleneck Models (CBMs) require scoring all predefined concepts at inference time and for manual intervention, imposing a substantial burden on clinicians, while rationale-based generative approaches often select concepts by class discriminability, which can drift from diagnostic ontologies. To address these issues, we propose Neuro-Symbolic Rule Distillation (NeRD), a framework that produces efficient, ontology-grounded reasoning chains that are sufficient yet non-redundant, without manually crafting diagnostic rules. Experiments on two skin datasets demonstrate strong diagnostic performance and interpretability, and blinded expert evaluation confirms the clinical plausibility of NeRD rationales. Our method further enables a first expert-in-the-loop study for Multimodal Chain-of-Thought-based diagnosis, achieving efficient and effective concept-level intervention.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces NeRD, a neuro-symbolic rule distillation framework that generates efficient, ontology-grounded chain-of-thought reasoning chains for medical image diagnosis. It claims to overcome limitations of concept bottleneck models (which require scoring all concepts) and rationale-based generative methods (which may drift from ontologies) by automatically distilling sufficient yet non-redundant rules from data without manual crafting. Experiments on two skin datasets are said to demonstrate strong diagnostic performance and interpretability, with blinded expert evaluation confirming clinical plausibility; the method also enables a first expert-in-the-loop study for multimodal CoT diagnosis.
Significance. If validated, the approach could meaningfully advance interpretable medical AI by automating ontology-aligned rule extraction, reducing clinician burden compared to CBMs, and improving plausibility over discriminability-driven rationales. The expert-in-the-loop component adds practical value. However, with no quantitative results, method details, or validation procedures provided, the significance cannot be assessed.
major comments (2)
- [Abstract] Abstract: The central claims of 'strong diagnostic performance' and 'clinical plausibility' are unsupported by any quantitative results, accuracy metrics, baseline comparisons, dataset details, or validation procedures. This absence is load-bearing, as it prevents any evaluation of whether the data supports the claims.
- [Abstract] Abstract: No technical details are given on the distillation algorithm, ontology alignment mechanism, rule extraction process, efficiency metrics, or how non-redundancy is enforced. These elements are load-bearing for the novelty and correctness of the neuro-symbolic method.
minor comments (1)
- [Abstract] The phrase 'Multimodal Chain-of-Thought-based diagnosis' is used without prior definition or context.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that the abstract would be strengthened by including key quantitative results and technical details to support the claims and facilitate evaluation. We address the points below and will revise the abstract in the resubmission.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claims of 'strong diagnostic performance' and 'clinical plausibility' are unsupported by any quantitative results, accuracy metrics, baseline comparisons, dataset details, or validation procedures. This absence is load-bearing, as it prevents any evaluation of whether the data supports the claims.
Authors: We acknowledge that the abstract summarizes outcomes at a high level without specific metrics or procedural details. The full manuscript reports experiments on two skin datasets with accuracy metrics, baseline comparisons, and blinded expert validation for clinical plausibility. We will revise the abstract to include concise quantitative highlights (e.g., diagnostic performance gains and expert agreement rates), dataset references, and validation procedures. revision: yes
-
Referee: [Abstract] Abstract: No technical details are given on the distillation algorithm, ontology alignment mechanism, rule extraction process, efficiency metrics, or how non-redundancy is enforced. These elements are load-bearing for the novelty and correctness of the neuro-symbolic method.
Authors: We agree the abstract is high-level and omits algorithmic specifics. The manuscript details the data-driven rule distillation, ontology alignment, extraction process, efficiency considerations, and non-redundancy enforcement via minimal sufficient rule sets. We will add brief descriptions of these components to the revised abstract. revision: yes
Circularity Check
No significant circularity identified
full rationale
The provided abstract and summary describe NeRD as distilling ontology-grounded rules from data without manual crafting or post-hoc adjustments, with experiments on skin datasets. No equations, derivation steps, self-citations, fitted parameters renamed as predictions, or uniqueness theorems are present in the text. The central claim relies on external ontologies and data-driven distillation rather than reducing to its own inputs by construction, making the method self-contained against the described benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., et al.: Qwen3-vl technical report. arXiv preprint arXiv:2511.21631 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Advances in health sciences education14(Suppl 1), 27–35 (2009)
Croskerry, P.: Clinical cognition and diagnostic error: applications of a dual process model of reasoning. Advances in health sciences education14(Suppl 1), 27–35 (2009)
2009
-
[3]
Taylor and Walton (1847)
De Morgan, A.: Formal logic: or, the calculus of inference, necessary and probable. Taylor and Walton (1847)
-
[4]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Groh, M., Harris, C., Soenksen, L., Lau, F., Han, R., Kim, A., Koochek, A., Badri, O.: Evaluating deep neural networks trained on clinical images in dermatology with the fitzpatrick 17k dataset. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 1820–1828 (2021)
2021
-
[5]
Iclr1(2), 3 (2022)
Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W., et al.: Lora: Low-rank adaptation of large language models. Iclr1(2), 3 (2022)
2022
-
[6]
In: Proceedings of the63rdAnnualMeetingoftheAssociationforComputationalLinguistics(Volume 1: Long Papers)
Jiang,Y.,Mehta,D.,Feng,W.,Ge,Z.:Enhancinginterpretableimageclassification through LLM agents and conditional concept bottleneck models. In: Proceedings of the63rdAnnualMeetingoftheAssociationforComputationalLinguistics(Volume 1: Long Papers). pp. 12285–12297 (Jul 2025)
2025
-
[7]
In: Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing
Jiang, Y., Mehta, D., Yan, S., Shen, Y., Wang, Z., Ge, Z.: Wise: Weak-supervision- guided step-by-step explanations for multimodal llms in image classification. In: Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. pp. 14685–14696 (2025)
2025
-
[8]
IEEE journal of biomedical and health informatics23(2), 538–546 (2018)
Kawahara, J., Daneshvar, S., Argenziano, G., Hamarneh, G.: Seven-point checklist and skin lesion classification using multitask multimodal neural nets. IEEE journal of biomedical and health informatics23(2), 538–546 (2018)
2018
-
[9]
In: International conference on machine learning
Koh, P.W., Nguyen, T., Tang, Y.S., Mussmann, S., Pierson, E., Kim, B., Liang, P.: Concept bottleneck models. In: International conference on machine learning. pp. 5338–5348. PMLR (2020)
2020
-
[10]
Entropy23(1), 18 (2020)
Linardatos, P., Papastefanopoulos, V., Kotsiantis, S.: Explainable ai: A review of machine learning interpretability methods. Entropy23(1), 18 (2020)
2020
-
[11]
In: Information Processing in Medical Imaging
Mehta, D., Jiang, Y., Jan, C., He, M., Jadhav, K., Ge, Z.: Interpretable few-shot retinal disease diagnosis with concept-guided prompting of vision-language mod- els. In: Information Processing in Medical Imaging. pp. 263–277. Springer Nature Switzerland (2026)
2026
-
[12]
In: International Conference on Medical Image Computing and Computer-Assisted Intervention
Pang, W., Ke, X., Tsutsui, S., Wen, B.: Integrating clinical knowledge into concept bottleneck models. In: International Conference on Medical Image Computing and Computer-Assisted Intervention. pp. 243–253. Springer (2024) 10 Hongxi Yang et al
2024
-
[13]
In: Proceedings of the 2017 ACM on Asia conference on computer and communications security
Papernot, N., McDaniel, P., Goodfellow, I., Jha, S., Celik, Z.B., Swami, A.: Prac- tical black-box attacks against machine learning. In: Proceedings of the 2017 ACM on Asia conference on computer and communications security. pp. 506–519 (2017)
2017
-
[14]
Singh, A., Fry, A., Perelman, A., Tart, A., Ganesh, A., El-Kishky, A., McLaughlin, A., Low, A., Ostrow, A., Ananthram, A., et al.: Openai gpt-5 system card. arXiv preprint arXiv:2601.03267 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Szegedy, C., Vanhoucke, V., Ioffe, S., Shlens, J., Wojna, Z.: Rethinking the incep- tion architecture for computer vision. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 2818–2826 (2016)
2016
-
[16]
arXiv preprint arXiv:2512.07383 (2025)
Vemuri, D.S., Bellamkonda, G., Pola, A., Balasubramanian, V.N.: Logiccbms: Logic-enhanced concept-based learning. arXiv preprint arXiv:2512.07383 (2025)
-
[17]
In: 2025 IEEE/CVF International Conference on Computer Vision (ICCV)
Yan,S.,Hu,M.,Jiang,Y.,Li,X.,Fei,H.,Tschandl,P.,Kittler,H.,Ge,Z.:Derm1m: A million-scale vision-language dataset aligned with clinical ontology knowledge for dermatology. In: 2025 IEEE/CVF International Conference on Computer Vision (ICCV). pp. 12681–12690 (2025)
2025
-
[18]
In: International Conference on Medical Image Computing and Computer-Assisted Intervention
Yan, S., Li, X., Hu, M., Jiang, Y., Yu, Z., Ge, Z.: Make: Multi-aspect knowledge- enhanced vision-language pretraining for zero-shot dermatological assessment. In: International Conference on Medical Image Computing and Computer-Assisted Intervention. pp. 369–379. Springer (2025)
2025
-
[19]
Yan, S., Li, X., Mo, D., Tschandl, P., Jiang, Y., Wang, Z., Hu, M., Ju, L., Vico-Alonso, C., Zheng, Y., Liu, J., Zhou, J., Chello, C., Cheung, J.G., An- riot, J., Thomas, L., Primiero, C., Tan, G., Ng, A.B., See, S., Tang, X., Ip, A., Liao, X., Bowling, A., Haskett, M., Zhao, S., Janda, M., Soyer, H.P., Mar, V., Kittler, H., Ge, Z.: A vision-language foun...
-
[20]
In: Pro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition
Yan, S., Yu, Z., Zhang, X., Mahapatra, D., Chandra, S.S., Janda, M., Soyer, P., Ge, Z.: Towards trustable skin cancer diagnosis via rewriting model’s decision. In: Pro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 11568–11577 (2023)
2023
-
[21]
American Journal of Neuroradiology47(4), 920–928 (2026)
Yang, H., George, Y., Mehta, D., Lin, L., Chen, C., Yang, D., Sun, J., Lau, K.F., Bain, C., Yang, Q., et al.: Multimodal ct perfusion–based deep learning for predict- ing stroke lesion outcomes in complete and no recanalization scenarios. American Journal of Neuroradiology47(4), 920–928 (2026)
2026
-
[22]
In: 2026 IEEE 23rd International Symposium on Biomedical Imaging (ISBI)
Yang, H., Yu, Z., Mehta, D., George, Y., Ge, Z.: Semantic-guided 3d ct generation for stroke lesion segmentation. In: 2026 IEEE 23rd International Symposium on Biomedical Imaging (ISBI). pp. 1–5. IEEE (2026)
2026
-
[23]
Computational Neurosurgery pp
Yang, H., Yuwen, C., Cheng, X., Fan, H., Wang, X., Ge, Z.: Deep learning: A primer for neurosurgeons. Computational Neurosurgery pp. 39–70 (2024)
2024
-
[24]
National Science Review11(12), nwae403 (2024)
Yin, S., Fu, C., Zhao, S., Li, K., Sun, X., Xu, T., Chen, E.: A survey on multimodal large language models. National Science Review11(12), nwae403 (2024)
2024
-
[25]
Zhang, Y., Unell, A., Wang, X., Ghosh, D., Su, Y., Schmidt, L., Yeung-Levy, S.: Why are visually-grounded language models bad at image classification? Advances in Neural Information Processing Systems37, 51727–51753 (2024)
2024
-
[26]
Multimodal Chain-of-Thought Reasoning in Language Models
Zhang, Z., Zhang, A., Li, M., Zhao, H., Karypis, G., Smola, A.: Multimodal chain- of-thought reasoning in language models. arXiv preprint arXiv:2302.00923 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[27]
In: Proceedings of the 62nd annual meeting of the association for computational linguistics (volume 3: system demonstrations)
Zheng, Y., Zhang, R., Zhang, J., Ye, Y., Luo, Z.: Llamafactory: Unified efficient fine-tuning of 100+ language models. In: Proceedings of the 62nd annual meeting of the association for computational linguistics (volume 3: system demonstrations). pp. 400–410 (2024)
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.