Benchmarking LLM Agents on Meta-Analysis Articles from Nature Portfolio
Pith reviewed 2026-06-30 10:19 UTC · model grok-4.3
The pith
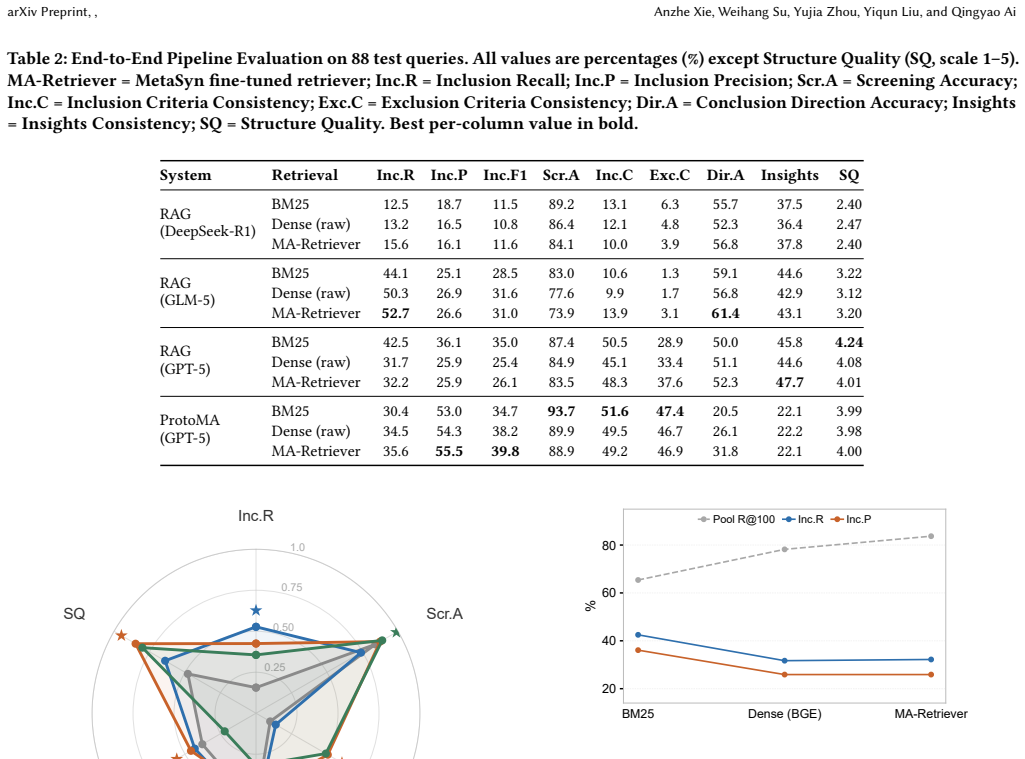
LLM agents recover at most 52.7 percent of required studies for meta-analyses because they cannot reliably apply PI/ECO inclusion rules to topically similar papers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
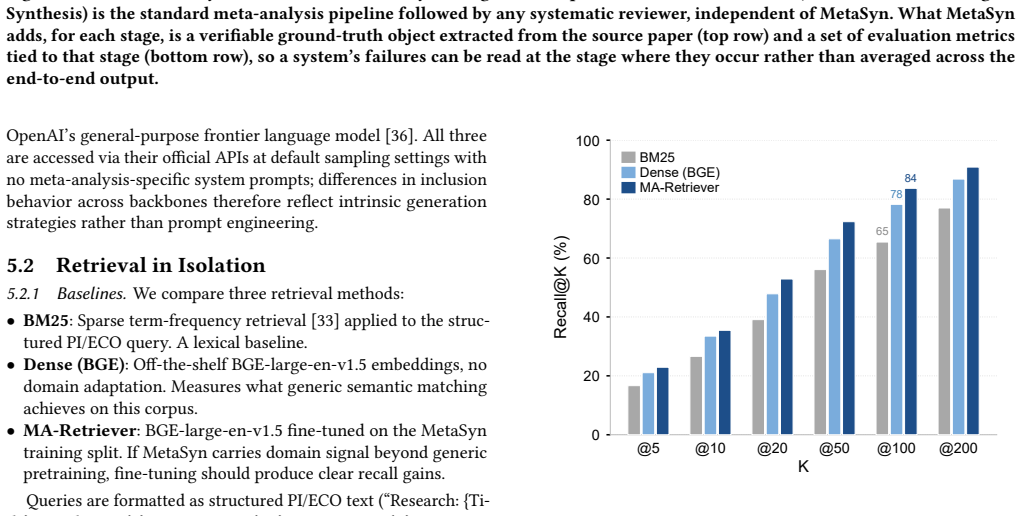
Despite retrieval ceilings of 90.9 percent recall at K=200, no tested RAG or agent system recovers more than 52.7 percent of the ground-truth included studies; the shortfall occurs because LLMs cannot consistently separate PI/ECO-eligible papers from topically similar but ineligible distractors.
What carries the argument
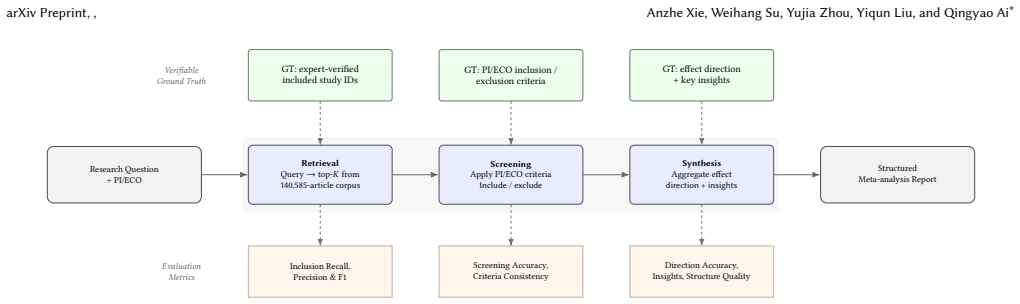
The MetaSyn dataset, which supplies each meta-analysis with its research question, PI/ECO criteria, 140k-article retrieval corpus, verified positives, and hard negatives that match on topic but fail eligibility rules.
If this is right
- Screening remains the dominant error source across all tested retrieval-augmented and agent pipelines.
- End-to-end accuracy metrics conceal stage-specific weaknesses that stage-attributed metrics expose.
- Current LLMs lack reliable mechanisms for applying structured eligibility criteria inside large pools of topically matched documents.
- Protocol-driven agents do not overcome the screening bottleneck observed in standard RAG variants.
Where Pith is reading between the lines
- The same screening limitation would likely appear in other evidence-synthesis tasks that require fine-grained eligibility judgments.
- Targeted training on PI/ECO decision examples drawn from hard-negative pairs could be tested as a direct remedy.
- Extending the benchmark to later synthesis stages would show whether retrieval-plus-screening errors compound in final statistical outputs.
Load-bearing premise
The 442 selected meta-analyses and their associated hard negatives capture the typical difficulty of real-world study screening tasks.
What would settle it
A system that, when run on the same 442 questions and 140k-article pools, assembles more than 52.7 percent of the expert-verified included studies while maintaining low false-positive rates on the hard negatives.
Figures

read the original abstract
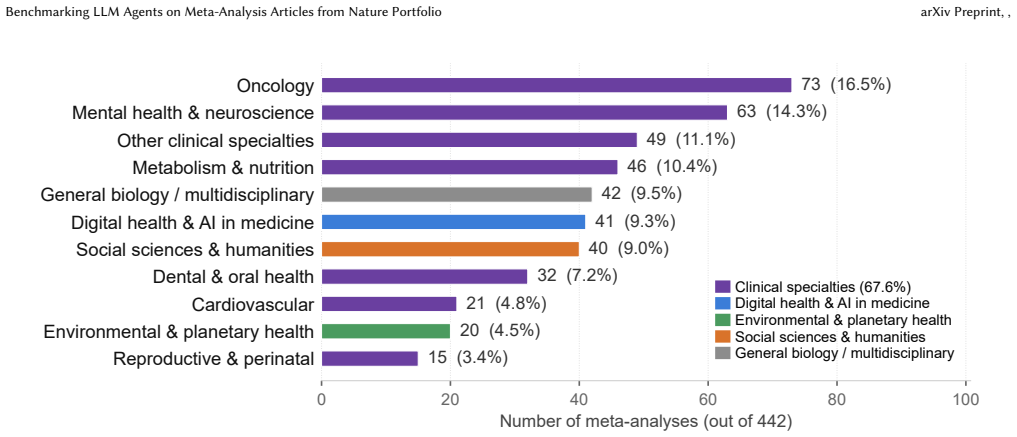
Meta-analysis is a demanding form of evidence synthesis that combines literature retrieval, PI/ECO-guided study selection, and statistical aggregation. Its structured, verifiable workflow makes it an ideal substrate for evaluating systematic scientific reasoning, yet existing benchmarks lack ground truth across the full retrieval-screening-synthesis pipeline. We introduce MetaSyn, a dataset of 442 expert-curated meta-analyses from Nature Portfolio journals. Each entry pairs a research question with PI/ECO criteria, a retrieval corpus of 140k PubMed articles, verified positive studies, hard negatives that are topically similar but PI/ECO-ineligible, and complete search strategies and date bounds. Benchmarking twelve pipeline configurations (nine RAG variants and a protocol-driven agent) reveals a critical screening bottleneck: despite a retrieval ceiling of 90.9% recall at K=200, no system recovers more than 52.7% of ground-truth included literature. Current LLMs fail to reliably separate eligible studies from PI/ECO-failing distractors in pools of comparable topical relevance. Stage-attributed metrics capture where systems succeed and fail; a single end-to-end score does not.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the MetaSyn dataset of 442 expert-curated meta-analyses from Nature Portfolio journals. Each entry supplies a research question with PI/ECO criteria, a 140k PubMed retrieval corpus, verified positive studies, hard negatives (topically similar but PI/ECO-ineligible), and complete search strategies. Benchmarking twelve LLM pipeline configurations (nine RAG variants plus one protocol-driven agent) shows a screening bottleneck: retrieval recall reaches 90.9% at K=200, yet no system recovers more than 52.7% of ground-truth included literature. The work attributes the gap to LLMs' inability to separate eligible studies from comparable distractors and advocates stage-attributed metrics over single end-to-end scores.
Significance. If the central result holds, MetaSyn supplies a valuable, reproducible benchmark with full-pipeline ground truth and hard negatives, enabling precise diagnosis of where LLM agents succeed or fail on structured scientific reasoning. The explicit separation of retrieval, screening, and synthesis stages, together with the provision of verified positives and distractors, is a clear strength that prior benchmarks lack. The reported screening ceiling of 52.7% would, if generalizable, usefully constrain expectations for automated evidence synthesis and motivate targeted improvements in PI/ECO-guided filtering.
major comments (2)
- [§3 (Dataset Construction)] §3 (Dataset Construction): The headline claim that 'Current LLMs fail to reliably separate eligible studies from PI/ECO-failing distractors' is load-bearing on the assumption that the 442 Nature Portfolio meta-analyses and their 140k PubMed corpora are representative of real-world screening difficulty. No analysis is supplied comparing the distribution of screening difficulty, search-strategy complexity, or corpus completeness against meta-analyses from other publishers or the original author-conducted searches.
- [Results (§5)] Results (§5): The 52.7% recovery and 90.9% recall figures are reported without accompanying statistical methods, confidence intervals, or sensitivity checks for curation/selection effects in the 442 examples. This directly affects the robustness of the screening-bottleneck conclusion.
minor comments (1)
- [Abstract] Abstract: The phrase 'Stage-attributed metrics capture where systems succeed and fail' is used without a one-sentence definition or pointer to the relevant table/figure, reducing immediate clarity for readers.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on dataset construction and statistical reporting. We address each major comment below.
read point-by-point responses
-
Referee: [§3 (Dataset Construction)] The headline claim that 'Current LLMs fail to reliably separate eligible studies from PI/ECO-failing distractors' is load-bearing on the assumption that the 442 Nature Portfolio meta-analyses and their 140k PubMed corpora are representative of real-world screening difficulty. No analysis is supplied comparing the distribution of screening difficulty, search-strategy complexity, or corpus completeness against meta-analyses from other publishers or the original author-conducted searches.
Authors: Nature Portfolio journals were selected specifically because they supply meta-analyses with expert-verified PI/ECO criteria, complete search strategies, and date bounds, which are required to construct verified positives, hard negatives, and full-pipeline ground truth. This choice prioritizes curation quality over breadth. We agree that the absence of a comparative analysis across publishers means we cannot claim the observed screening difficulty is representative of all meta-analyses. In revision we will add an explicit limitations paragraph noting this scope restriction and recommending extension to other corpora as future work. revision: partial
-
Referee: [Results (§5)] The 52.7% recovery and 90.9% recall figures are reported without accompanying statistical methods, confidence intervals, or sensitivity checks for curation/selection effects in the 442 examples. This directly affects the robustness of the screening-bottleneck conclusion.
Authors: We accept that the key aggregate metrics require statistical characterization. In the revised manuscript we will report bootstrap confidence intervals computed over the 442 meta-analyses, describe the resampling procedure, and add sensitivity checks that vary inclusion criteria or corpus subsampling to assess curation effects. revision: yes
Circularity Check
No circularity; results rest on external expert-curated ground truth
full rationale
The paper introduces MetaSyn, a dataset of 442 expert-curated meta-analyses with verified positives, hard negatives, and retrieval corpora. The central claim (no system exceeds 52.7% recovery of ground-truth inclusions despite 90.9% retrieval recall at K=200) is obtained by direct measurement against this externally provided ground truth. No equations, fitted parameters, self-citations, or ansatzes appear in the derivation chain; the evaluation pipeline is a straightforward empirical comparison rather than any reduction to the paper's own inputs or prior self-referential results. This is the most common honest non-finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The PI/ECO framework provides the correct standard for determining study eligibility in meta-analyses
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.