Vibrato Expression Control for Singing Voice Conversion with Improving Independent Control
Pith reviewed 2026-06-27 02:58 UTC · model grok-4.3
The pith
VibE-SVC2 enables independent control of pitch style and timbre style in singing voice conversion by resolving pitch-energy entanglement and subharmonic F0 issues.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By introducing an Energy Style Converter to address remaining style information in the energy contour, a Zero-shot Pitch Style Converter which mimics the pitch style of reference audio, vibrato rate scaling for independent control of vibrato extent, and a Subharmonic Correction algorithm to refine the F0 contour for subharmonic phonation styles, VibE-SVC2 provides fine-grained independent control over pitch style and timbre style, as demonstrated by comprehensive objective and subjective evaluations that outperform existing methods.
What carries the argument
Energy Style Converter combined with Zero-shot Pitch Style Converter, vibrato rate scaling, and Subharmonic Correction algorithm that separate style information from energy and F0 contours.
If this is right
- Vibrato extent can be scaled independently of other pitch features.
- Pitch style can be transferred zero-shot from a reference audio clip.
- Timbre conversion succeeds for phonation styles that produce subharmonics.
- The overall framework yields measurable gains in both objective metrics and listener preference over prior singing voice conversion systems.
Where Pith is reading between the lines
- The disentanglement approach could support real-time style editing interfaces in music production software.
- Similar correction steps might transfer to other audio tasks that rely on reliable F0 tracking under irregular pitch.
- Further tests on live performance recordings would reveal whether the converters remain stable outside studio conditions.
Load-bearing premise
The proposed Energy Style Converter, Zero-shot Pitch Style Converter, vibrato rate scaling, and Subharmonic Correction algorithm resolve the entanglement and extraction issues without introducing new artifacts or degrading naturalness in unseen styles or recording conditions.
What would settle it
A controlled listening test on unseen singers and recording conditions in which listeners cannot independently vary vibrato extent or in which vocal-fry conversions lose naturalness would falsify the claim of fine-grained independent control.
Figures
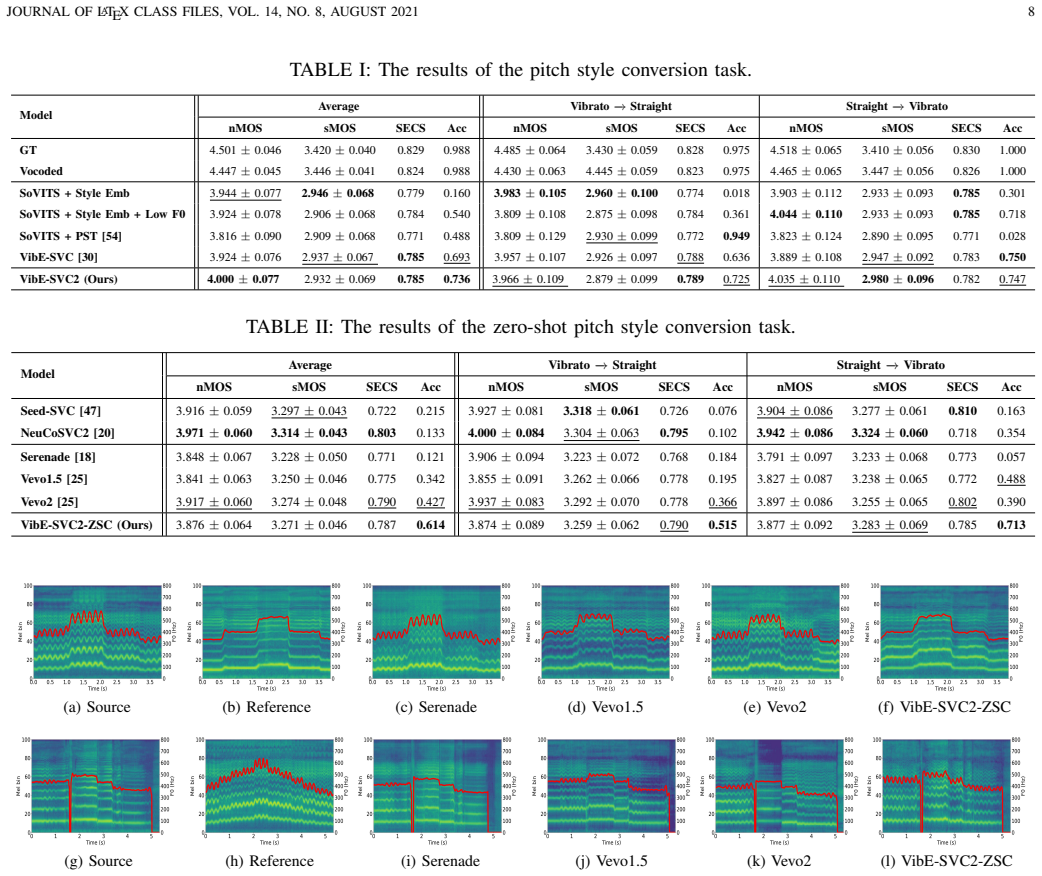
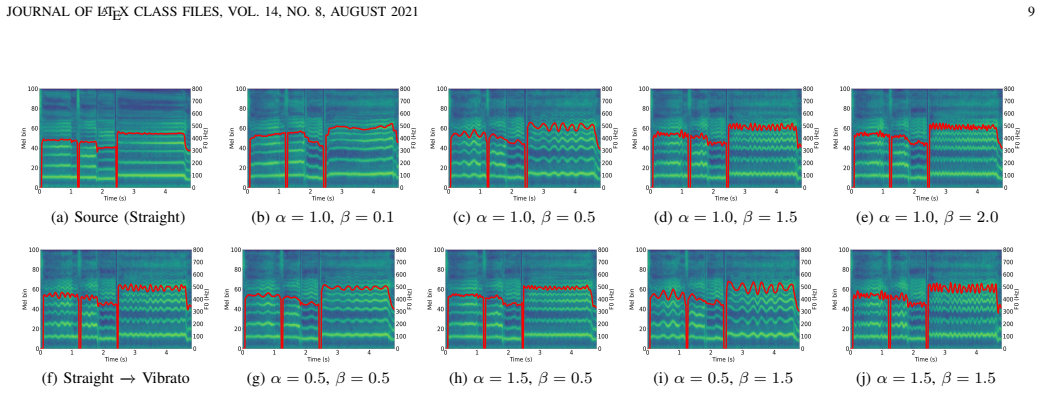
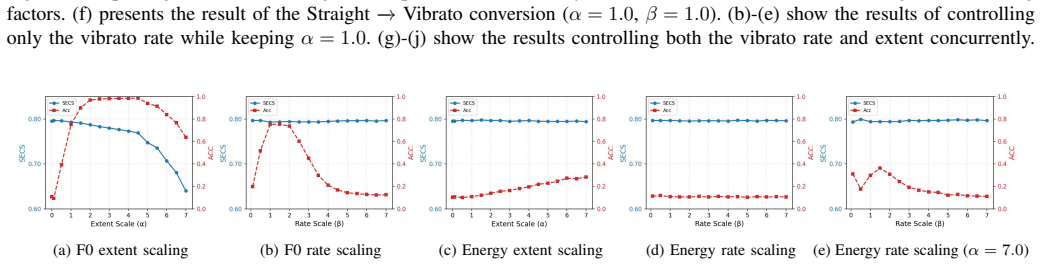
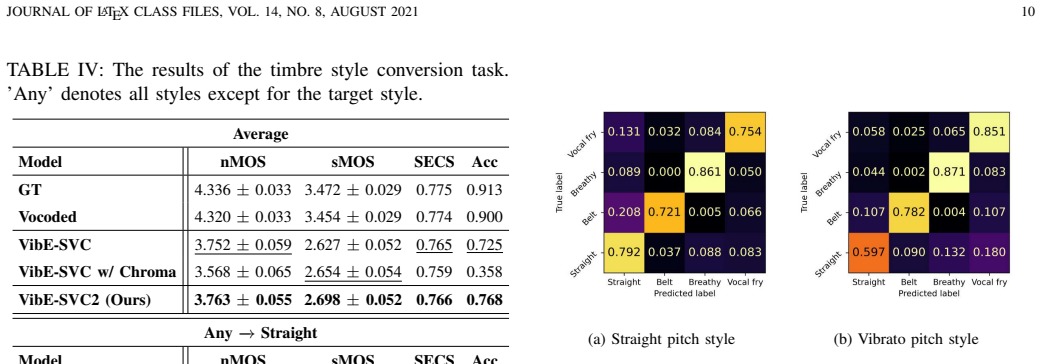
read the original abstract
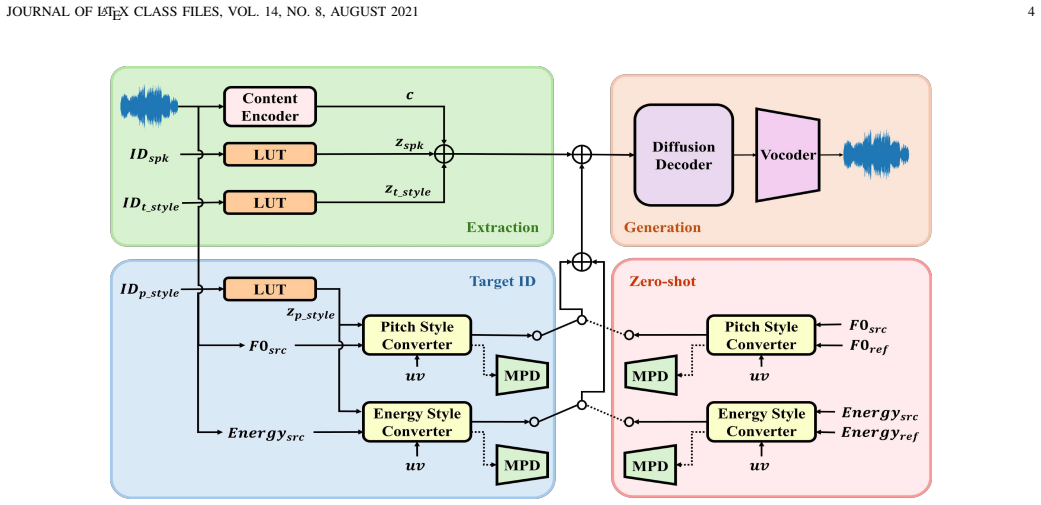
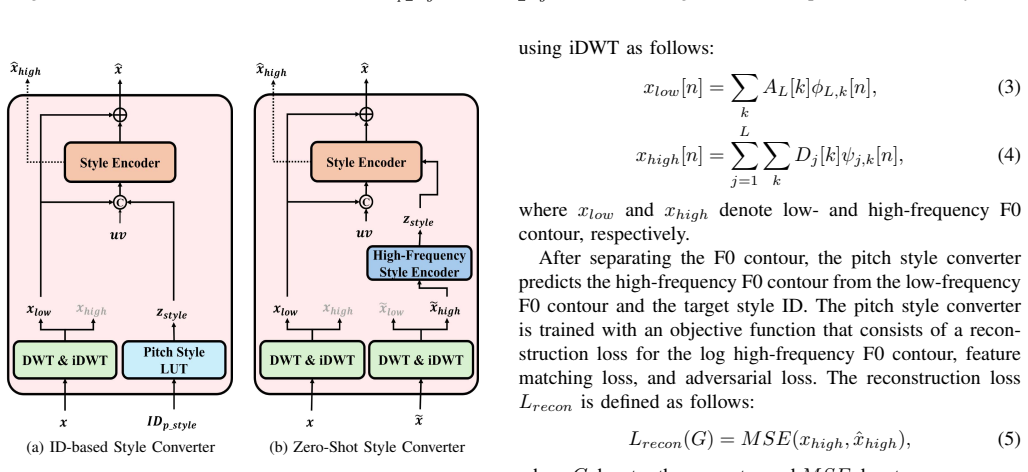
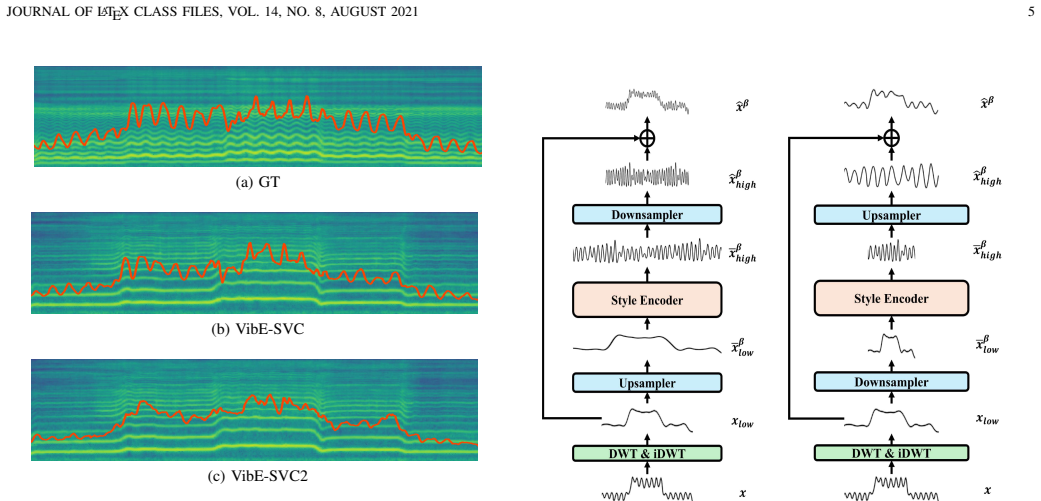
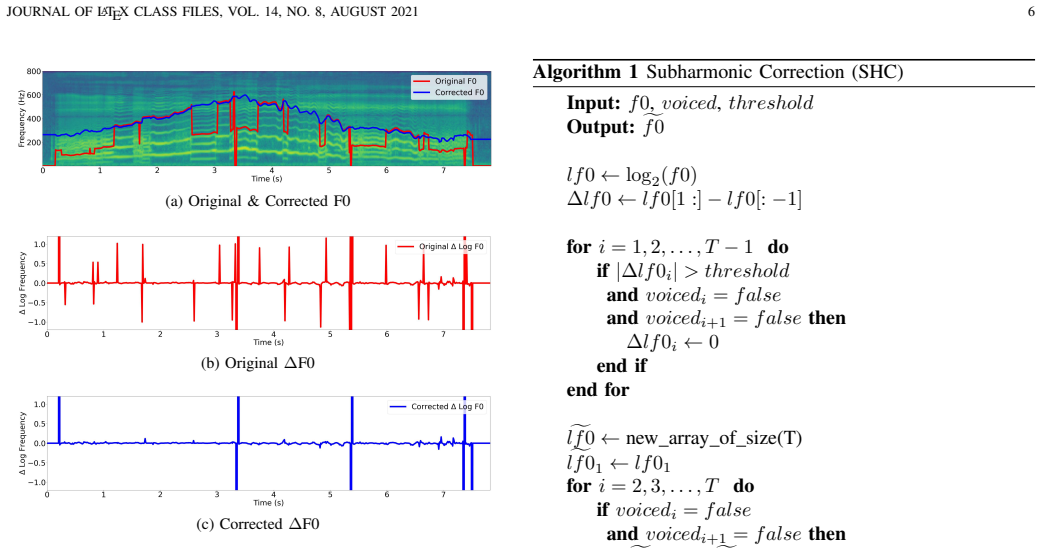
Singing style is a crucial aspect of a natural and expressive singing voice. Singers utilize singing styles to convey the feeling or emotion of the songs. Several works have been proposed to control singing style for making the more expressive singing voice. Recently, VibE-SVC successfully controls vibrato by predicting high-frequency F0 contour. In this paper, we introduce a singing voice conversion framework, called VibE-SVC2, to improve singing style conversion performance and controllability. The model offers control over two types of singing styles: a pitch style and a timbre style. For the pitch style, to resolve the pitch-energy entanglement issue that is unresolved in our previous work, we introduce a novel Energy Style Converter to address remaining style information in the energy contour. In addition, we propose a Zero-shot Pitch Style Converter, which mimics the pitch style of reference audio. To expand the controllability of the model, we propose vibrato rate scaling that is an independent control of vibrato extent, which is unavailable in VibE-SVC. For the timbre style, we extend the model to handle a variety of phonation styles. However, addressing specific styles such as vocal fry poses a challenge, as conventional F0 extraction often fails due to their inherent subharmonic characteristics, which degrades the conversion quality. To address this, we propose a novel Subharmonic Correction algorithm to refine the F0 contour for more natural timbre conversion. Through comprehensive objective and subjective evaluations, we demonstrate that VibE-SVC2 provides fine-grained, independent control over two types of singing styles, outperforming existing methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces VibE-SVC2 as an extension of the authors' prior VibE-SVC framework for singing voice conversion. It proposes an Energy Style Converter to address unresolved pitch-energy entanglement, a Zero-shot Pitch Style Converter to mimic reference pitch styles, vibrato rate scaling for independent vibrato extent control, and a Subharmonic Correction algorithm to refine F0 contours for phonation styles with subharmonics such as vocal fry. The central claim is that these components enable fine-grained, independent control over pitch and timbre styles and outperform existing methods, as demonstrated by comprehensive objective and subjective evaluations.
Significance. If the empirical results hold, the work offers a targeted incremental advance in controllable singing voice conversion by resolving specific disentanglement and F0 extraction issues identified in the authors' earlier model. The explicit identification of prior limitations and the introduction of modular fixes (Energy Style Converter, vibrato rate scaling, Subharmonic Correction) constitute a strength in iterative engineering. The potential circularity concern from building directly on the authors' own prior publication does not appear to introduce internal inconsistency or hidden assumptions; the new components are presented as direct responses to stated shortcomings, consistent with standard research progression in the field.
minor comments (3)
- Abstract: The assertion of outperformance via objective and subjective tests would be strengthened by including at least one key quantitative result (e.g., a specific metric improvement) to allow readers to gauge the scale of gains without immediately consulting the experiments section.
- Introduction or §2 (Related Work): The distinction between VibE-SVC and VibE-SVC2 could be summarized in a short table or bullet list of resolved vs. new capabilities to improve readability for readers familiar with the prior work.
- Method sections describing the Energy Style Converter and Subharmonic Correction: Notation for input/output contours (e.g., energy, F0) should be defined consistently on first use to avoid ambiguity when comparing to the baseline VibE-SVC pipeline.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of VibE-SVC2 and the recommendation for minor revision. The report correctly notes the targeted improvements over our prior work in resolving specific disentanglement and F0 issues.
Circularity Check
No significant circularity
full rationale
The manuscript presents VibE-SVC2 as an engineering extension of the authors' prior VibE-SVC work, introducing new modules (Energy Style Converter, Zero-shot Pitch Style Converter, vibrato rate scaling, Subharmonic Correction) to address previously noted issues. Central claims rest on objective and subjective evaluations of the new components rather than any mathematical derivation, parameter fitting, or uniqueness theorem that reduces to self-citation by construction. Self-reference to VibE-SVC is explicit but not load-bearing; the new methods and their performance metrics are independently testable and falsifiable via standard protocols. No self-definitional, fitted-input, or ansatz-smuggling patterns appear in the abstract or described framework.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Disentangling content and fine-grained prosody infor- mation via hybrid asr bottleneck features for voice conversion,
X. Zhaoet al., “Disentangling content and fine-grained prosody infor- mation via hybrid asr bottleneck features for voice conversion,” inProc. IEEE Int. Conf. Acoust., Speech, Signal Process. (ICASSP), 2022, pp. 7022–7026
2022
-
[2]
Prosody-adaptable audio codecs for zero-shot voice conversion via in-context learning,
J. Zhao, X. Wang, and Y . Wang, “Prosody-adaptable audio codecs for zero-shot voice conversion via in-context learning,”arXiv preprint arXiv:2505.15402, 2025
arXiv 2025
-
[3]
Pavits: Exploring prosody-aware vits for end-to-end emotional voice conversion,
T. Qi, W. Zheng, C. Lu, Y . Zong, and H. Lian, “Pavits: Exploring prosody-aware vits for end-to-end emotional voice conversion,” inProc. IEEE Int. Conf. Acoust., Speech, Signal Process. (ICASSP)). IEEE, 2024, pp. 12 697–12 701
2024
-
[4]
Durflex-evc: Duration- flexible emotional voice conversion leveraging discrete representations without text alignment,
H.-S. Oh, S.-H. Lee, D.-H. Cho, and S.-W. Lee, “Durflex-evc: Duration- flexible emotional voice conversion leveraging discrete representations without text alignment,”IEEE Trans. Affect. Comput., 2025
2025
-
[5]
Accent and speaker disentanglement in many-to-many voice conversion,
Z. Wanget al., “Accent and speaker disentanglement in many-to-many voice conversion,” inInt. Symp. Chin. Spok. Lang. Process. (ISCSLP). IEEE, 2021, pp. 1–5
2021
-
[6]
V oice- preserving zero-shot multiple accent conversion,
M. Jin, P. Serai, J. Wu, A. Tjandra, V . Manohar, and Q. He, “V oice- preserving zero-shot multiple accent conversion,” inProc. IEEE Int. Conf. Acoust., Speech, Signal Process. (ICASSP). IEEE, 2023, pp. 1–5
2023
-
[7]
Macst: Multi- accent speech synthesis via text transliteration for accent conversion,
S. Inoue, S. Wang, W. Wang, P. Zhu, M. Bi, and H. Li, “Macst: Multi- accent speech synthesis via text transliteration for accent conversion,” in Proc. IEEE Int. Conf. Acoust., Speech, Signal Process. (ICASSP), 2025, pp. 1–5
2025
-
[8]
Vits-based singing voice conversion leveraging whisper and multi-scale f0 modeling,
Z. Ning, Y . Jiang, Z. Wang, B. Zhang, and L. Xie, “Vits-based singing voice conversion leveraging whisper and multi-scale f0 modeling,” in Proc. IEEE Autom. Speech Recognit. Underst. Workshop (ASRU). IEEE, 2023, pp. 1–8
2023
-
[9]
Vits-based singing voice conversion system with dspgan post-processing for svcc2023,
Y . Zhou, M. Chen, Y . Lei, J. Zhu, and W. Zhao, “Vits-based singing voice conversion system with dspgan post-processing for svcc2023,” in Proc. IEEE Autom. Speech Recognit. Underst. Workshop (ASRU). IEEE, 2023, pp. 1–8
2023
-
[10]
Freesvc: Towards zero-shot multilingual singing voice conversion,
A. I. Ferreiraet al., “Freesvc: Towards zero-shot multilingual singing voice conversion,” inProc. IEEE Int. Conf. Acoust., Speech, Signal Process. (ICASSP). IEEE, 2025, pp. 1–5
2025
-
[11]
Diffsvc: A diffusion probabilistic model for singing voice conversion,
S. Liu, Y . Cao, D. Su, and H. Meng, “Diffsvc: A diffusion probabilistic model for singing voice conversion,” inProc. IEEE Autom. Speech Recognit. Underst. Workshop (ASRU). IEEE, 2021
2021
-
[12]
Ldm-svc: Latent diffusion model based zero-shot any-to- any singing voice conversion with singer guidance,
S. Chenet al., “Ldm-svc: Latent diffusion model based zero-shot any-to- any singing voice conversion with singer guidance,” inProc. Interspeech, 2024, pp. 2770–2774
2024
-
[13]
Comosvc: Consistency model-based singing voice conversion,
Y . Lu, Z. Ye, W. Xue, X. Tan, Q. Liu, and Y . Guo, “Comosvc: Consistency model-based singing voice conversion,” inIEEE Int. Symp. Chin. Spok. Lang. Process. (ISCSLP), 2024, pp. 184–188
2024
-
[14]
Lcm-svc: Latent diffusion model based singing voice conversion with inference acceleration via latent consistency distillation,
S. Chen, Y . Gu, J. Cui, J. Zhang, R. Chen, and L. Dai, “Lcm-svc: Latent diffusion model based singing voice conversion with inference acceleration via latent consistency distillation,” inIEEE Int. Symp. Chin. Spok. Lang. Process. (ISCSLP), 2024, pp. 309–313
2024
-
[15]
Midi-voice: Expressive zero-shot singing voice synthesis via midi-driven priors,
D.-M. Byun, S.-H. Lee, J.-S. Hwang, and S.-W. Lee, “Midi-voice: Expressive zero-shot singing voice synthesis via midi-driven priors,” in Proc. IEEE Int. Conf. Acoust., Speech, Signal Process. (ICASSP). IEEE, 2024, pp. 12 622–12 626
2024
-
[16]
Hierarchical diffusion model for zero-shot singing voice synthesis with midi priors,
D.-M. Byun, S.-B. Kim, and S.-W. Lee, “Hierarchical diffusion model for zero-shot singing voice synthesis with midi priors,”IEEE Trans. Audio, Speech, Lang. Process., 2025
2025
-
[17]
Dafmsvc: One-shot singing voice conversion with dual attention mechanism and flow matching,
W. Chenet al., “Dafmsvc: One-shot singing voice conversion with dual attention mechanism and flow matching,”arXiv preprint arXiv:2508.05978, 2025
arXiv 2025
-
[18]
Serenade: A singing style conversion framework based on audio infilling,
L. P. Violeta, W.-C. Huang, and T. Toda, “Serenade: A singing style conversion framework based on audio infilling,”arXiv preprint arXiv:2503.12388, 2025
arXiv 2025
-
[19]
Syki-svc: Advancing singing voice conversion with post-processing innovations and an open-source professional testset,
Y . Zhouet al., “Syki-svc: Advancing singing voice conversion with post-processing innovations and an open-source professional testset,” in Proc. IEEE Int. Conf. Acoust., Speech, Signal Process. (ICASSP). IEEE, 2025, pp. 1–5
2025
-
[20]
Neural concatenative singing voice conversion: Rethinking concatenation-based approach for one-shot singing voice conversion,
B. Sha, X. Li, Z. Wu, Y . Shan, and H. Meng, “Neural concatenative singing voice conversion: Rethinking concatenation-based approach for one-shot singing voice conversion,” inProc. IEEE Int. Conf. Acoust., Speech, Signal Process. (ICASSP). IEEE, 2024, pp. 12 577–12 581
2024
-
[21]
Robustsvc: Hubert-based melody extractor and adversarial learning for robust singing voice conversion,
W. Chen, X. Zhao, J. Chen, B. Sha, Z. Lin, and Z. Wu, “Robustsvc: Hubert-based melody extractor and adversarial learning for robust singing voice conversion,” inIEEE Int. Symp. Chin. Spok. Lang. Process. (ISCSLP). IEEE, 2024, pp. 164–168
2024
-
[22]
knn-svc: Robust zero- shot singing voice conversion with additive synthesis and concatenation smoothness optimization,
K. Shao, K. Chen, M. Baas, and S. Dubnov, “knn-svc: Robust zero- shot singing voice conversion with additive synthesis and concatenation smoothness optimization,” inProc. IEEE Int. Conf. Acoust., Speech, Signal Process. (ICASSP). IEEE, 2025, pp. 1–5
2025
-
[23]
Lhq-svc: Lightweight and high quality singing voice conversion modeling,
Y . Huanget al., “Lhq-svc: Lightweight and high quality singing voice conversion modeling,” inProc. IEEE Int. Conf. Acoust., Speech, Signal Process. (ICASSP), 2025, pp. 1–5
2025
-
[24]
Esvc: Combining adaptive style fusion and multi-level feature disentanglement for expressive singing voice conversion,
Z. Yanget al., “Esvc: Combining adaptive style fusion and multi-level feature disentanglement for expressive singing voice conversion,” in Proc. IEEE Int. Conf. Acoust., Speech, Signal Process. (ICASSP), 2024, pp. 12 161–12 165
2024
-
[25]
Vevo2: Bridging controllable speech and singing voice generation via unified prosody learning,
X. Zhanget al., “Vevo2: Bridging controllable speech and singing voice generation via unified prosody learning,”arXiv preprint arXiv:2508.16332, 2025
arXiv 2025
-
[26]
L. P. Violetaet al., “The singing voice conversion challenge 2025: From singer identity conversion to singing style conversion,”arXiv preprint arXiv:2509.15629, 2025
Pith/arXiv arXiv 2025
-
[27]
The psychology of music,
C. E. Seashore, “The psychology of music,”Music Educ. J., vol. 23, no. 4, pp. 30–33, 1937
1937
-
[28]
Singing voice synthesis with vibrato modeling and latent energy representation,
Y . Songet al., “Singing voice synthesis with vibrato modeling and latent energy representation,” inProc. IEEE Intl. Workshop Multimed. Signal Process. (MMSP). IEEE, 2022, pp. 1–6. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 13
2022
-
[29]
Vibrato learning in multi-singer singing voice synthesis,
R. Liu, X. Wen, C. Lu, L. Song, and J. S. Sung, “Vibrato learning in multi-singer singing voice synthesis,” inProc. IEEE Autom. Speech Recognit. Underst. Workshop (ASRU). IEEE, 2021, pp. 773–779
2021
-
[30]
VibE-SVC: Vibrato Extraction with High-frequency F0 Contour for Singing V oice Conver- sion,
J.-S. Choi, D.-M. Byun, H.-S. Oh, and S.-W. Lee, “VibE-SVC: Vibrato Extraction with High-frequency F0 Contour for Singing V oice Conver- sion,” inProc. Interspeech, 2025, pp. 1233–1237
2025
-
[31]
Controllable singing voice synthesis us- ing phoneme-level energy sequence,
Y . Ryu, I. Shin, and C. Kim, “Controllable singing voice synthesis us- ing phoneme-level energy sequence,”arXiv preprint arXiv:2509.07038, 2025
arXiv 2025
-
[32]
Neural analysis and synthesis: Reconstructing speech from self-supervised representa- tions,
H.-S. Choi, J. Lee, W. Kim, J. Lee, H. Heo, and K. Lee, “Neural analysis and synthesis: Reconstructing speech from self-supervised representa- tions,”Neural Inf. Process. Syst. (NeurIPS), vol. 34, pp. 16 251–16 265, 2021
2021
-
[33]
Gci detection from raw speech using a fully-convolutional network,
L. Ardaillon and A. Roebel, “Gci detection from raw speech using a fully-convolutional network,” inProc. IEEE Int. Conf. Acoust., Speech, Signal Process. (ICASSP). IEEE, 2020, pp. 6739–6743
2020
-
[34]
Analysis and detection of singing techniques in repertoires of j-pop solo singers,
Y . Yamamoto, J. Nam, and H. Terasawa, “Analysis and detection of singing techniques in repertoires of j-pop solo singers,” inProc. Int. Soc. Music Inf. Retrieval Conf. (ISMIR), 2022
2022
-
[35]
Sintechsvs: A singing tech- nique controllable singing voice synthesis system,
J. Zhao, L. Q. H. Chetwin, and Y . Wang, “Sintechsvs: A singing tech- nique controllable singing voice synthesis system,”IEEE/ACM Trans. Audio, Speech, Lang. Process., vol. 32, pp. 2641–2653, 2024
2024
-
[36]
V ocalset: A singing voice dataset
J. Wilkins, P. Seetharaman, A. Wahl, and B. Pardo, “V ocalset: A singing voice dataset.” inProc. Int. Soc. Music Inf. Retrieval Conf. (ISMIR), 2018, pp. 468–474
2018
-
[37]
Stylepitcher: Generating style-following and expressive pitch curves for versatile singing tasks,
J. Huang, Q. Yang, F.-Y . Chen, J. McAuley, R. Leistikow, P. R. Cook, and Y . Zang, “Stylepitcher: Generating style-following and expressive pitch curves for versatile singing tasks,” inProc. IEEE Int. Conf. Acoust., Speech, Signal Process. (ICASSP). IEEE, 2026, pp. 15 737–15 741
2026
-
[38]
Comelsinger: Discrete token- based zero-shot singing synthesis with structured melody control and guidance,
J. Zhao, W. Zeng, T. Lyu, and Y . Wang, “Comelsinger: Discrete token- based zero-shot singing synthesis with structured melody control and guidance,”IEEE Trans. Audio, Speech, Lang. Process., 2026
2026
-
[39]
A laminagraphic study of pulse (vocal fry) register phonation,
E. L. Allen and H. Hollien, “A laminagraphic study of pulse (vocal fry) register phonation,”F olia Phoniatr . Logop., vol. 25, no. 4, pp. 241–250, 1973
1973
-
[40]
Acoustic properties of different kinds of creaky voice
P. A. Keatinget al., “Acoustic properties of different kinds of creaky voice.” inProc. Int. Congr . Phon. Sci. (ICPhS), vol. 1, 2015, pp. 2–7
2015
-
[41]
DeepFry: Identifying V ocal Fry Using Deep Neural Networks,
B. R. Chernyaket al., “DeepFry: Identifying V ocal Fry Using Deep Neural Networks,” inProc. Interspeech, 2022, pp. 3578–3582
2022
-
[42]
Creapy: A python-based tool for the detection of creak in conversational speech,
M. Paierl, T. R ¨ock, S. Wepner, A. Kelterer, and B. Schuppler, “Creapy: A python-based tool for the detection of creak in conversational speech,” inProc. Int. Congr . Phon. Sci., 2023
2023
-
[43]
Prosody-controllable spontaneous tts with neural hmms,
H. Lameris, S. Mehta, G. E. Henter, J. Gustafson, and ´E. Sz ´ekely, “Prosody-controllable spontaneous tts with neural hmms,” inProc. IEEE Int. Conf. Acoust., Speech, Signal Process. (ICASSP). IEEE, 2023, pp. 1–5
2023
-
[44]
CreakVC: a voice conver- sion tool for modulating creaky voice,
H. Lameris, J. Gustafson, and ´Eva Sz´ekely, “CreakVC: a voice conver- sion tool for modulating creaky voice,” inProc. Interspeech, 2024, pp. 1005–1006
2024
-
[45]
Techsinger: Technique controllable multilingual singing voice synthesis via flow matching,
W. Guoet al., “Techsinger: Technique controllable multilingual singing voice synthesis via flow matching,” inProc. AAAI Conf. Artif. Intell. (AAAI), vol. 39, no. 22, 2025, pp. 23 978–23 986
2025
-
[46]
TCSinger: Zero-shot singing voice synthesis with style transfer and multi-level style control,
Y . Zhanget al., “TCSinger: Zero-shot singing voice synthesis with style transfer and multi-level style control,” inProc. Empir . Methods Nat. Lang. Process. (EMNLP). Association for Computational Linguistics, 2024, pp. 1960–1975
2024
-
[47]
Zero-shot voice conversion with diffusion transformers,
S. Liu, “Zero-shot voice conversion with diffusion transformers,”arXiv preprint arXiv:2411.09943, 2024
arXiv 2024
-
[48]
Source-filter hifi-gan: Fast and pitch controllable high-fidelity neural vocoder,
R. Yoneyama, Y .-C. Wu, and T. Toda, “Source-filter hifi-gan: Fast and pitch controllable high-fidelity neural vocoder,” inProc. IEEE Int. Conf. Acoust., Speech, Signal Process. (ICASSP). IEEE, 2023, pp. 1–5
2023
-
[49]
Gtsinger: A global multi-technique singing corpus with realistic music scores for all singing tasks,
Y . Zhanget al., “Gtsinger: A global multi-technique singing corpus with realistic music scores for all singing tasks,”Neural Inf. Process. Syst. (NeurIPS), vol. 37, pp. 1117–1140, 2024
2024
-
[50]
Rmvpe: A robust model for vocal pitch estimation in polyphonic music,
H. Wei, X. Cao, T. Dan, and Y . Chen, “Rmvpe: A robust model for vocal pitch estimation in polyphonic music,” inProc. Interspeech, 2023, pp. 5421–5425
2023
-
[51]
A comparison of discrete and soft speech units for improved voice conversion,
B. Van Niekerk, M.-A. Carbonneau, J. Za ¨ıdi, M. Baas, H. Seut ´e, and H. Kamper, “A comparison of discrete and soft speech units for improved voice conversion,” inProc. IEEE Int. Conf. Acoust., Speech, Signal Process. (ICASSP). IEEE, 2022, pp. 6562–6566
2022
-
[52]
BigV- GAN: A universal neural vocoder with large-scale training,
S. gil Lee, W. Ping, B. Ginsburg, B. Catanzaro, and S. Yoon, “BigV- GAN: A universal neural vocoder with large-scale training,” inInt. Conf. Learn. Represent. (ICLR), 2023
2023
-
[53]
Meta-stylespeech: Multi- speaker adaptive text-to-speech generation,
D. Min, D. B. Lee, E. Yang, and S. J. Hwang, “Meta-stylespeech: Multi- speaker adaptive text-to-speech generation,” inProc. Int. Conf. Mach. Learn. (ICML). PMLR, 2021, pp. 7748–7759
2021
-
[54]
Many-to-many singing performance style transfer on pitch and energy contours,
Y .-T. Hsu, J.-Y . Wang, and J.-S. R. Jang, “Many-to-many singing performance style transfer on pitch and energy contours,”IEEE Signal Process. Lett., 2024
2024
-
[55]
Robust speech recognition via large-scale weak super- vision,
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large-scale weak super- vision,” inProc. Int. Conf. Mach. Learn. (ICML). PMLR, 2023, pp. 28 492–28 518
2023
-
[56]
Wavlm: Large-scale self-supervised pre-training for full stack speech processing,
S. Chenet al., “Wavlm: Large-scale self-supervised pre-training for full stack speech processing,”IEEE J. Sel. Top. Signal Process., vol. 16, no. 6, pp. 1505–1518, 2022
2022
-
[57]
X. Shiet al., “Qwen3-asr technical report,”arXiv preprint arXiv:2601.21337, 2026
Pith/arXiv arXiv 2026
-
[58]
MERT: Acoustic music understanding model with large- scale self-supervised training,
Y . LIet al., “MERT: Acoustic music understanding model with large- scale self-supervised training,” inInt. Conf. Learn. Represent. (ICLR), 2024
2024
-
[59]
Introducing parselmouth: A python interface to praat,
Y . Jadoul, B. Thompson, and B. De Boer, “Introducing parselmouth: A python interface to praat,”J. Phon., vol. 71, pp. 1–15, 2018
2018
-
[60]
World: a vocoder-based high- quality speech synthesis system for real-time applications,
M. Morise, F. Yokomori, and K. Ozawa, “World: a vocoder-based high- quality speech synthesis system for real-time applications,”IEICE Trans. Inf. Syst., vol. 99, no. 7, pp. 1877–1884, 2016. Joon-Seung Choireceived the B.S. degree in com- puter science from the Inha University, Incheon, South Korea, in 2024. He is currently pursuing toward the master’s deg...
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.