When Rules Learn: A Self-Evolving Agent for Legal Case Retrieval
Pith reviewed 2026-06-27 03:32 UTC · model grok-4.3
The pith
An LLM agent evolves its own query-rewriting rules to improve BM25 legal case retrieval without training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
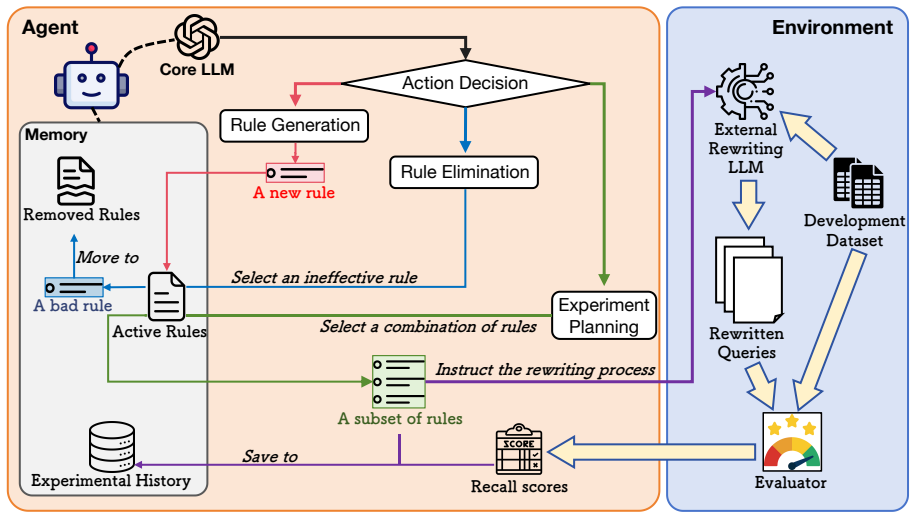
The central claim is that an LLM agent equipped with an automatic evaluation environment can create rewriting rules, plan validation experiments over combinations, and eliminate ineffective rules using historical feedback, yielding a refined rule set that boosts BM25 retrieval on the LeCaRD-v2 benchmark beyond non-evolutionary baselines.
What carries the argument
The LLM-based self-evolving agent that generates rewriting rules, plans validation experiments, and eliminates ineffective rules based on historical feedback.
If this is right
- The evolved rules improve BM25 retrieval without any parameter updates to the retrieval model.
- High-capacity LLMs enable more effective self-evolution and better final rule sets than smaller models.
- The agent's use of prior experimental results and intrinsic knowledge of rule elimination drives refinement of the rule set.
- The framework outperforms both static human-designed rules and greedy rule selection on the evaluated benchmark.
Where Pith is reading between the lines
- If the evaluation loop proves robust, the same agent structure could automate rule discovery for other retrieval or reasoning tasks that currently rely on hand-crafted rules.
- The method hints at LLMs functioning as meta-learners that refine symbolic rules rather than only producing one-off outputs.
- Self-evolution might reduce dependence on domain experts for maintaining rule sets in specialized fields like law.
Load-bearing premise
The automatic evaluation environment used by the agent provides reliable, unbiased feedback on rule combinations that generalizes beyond the specific LeCaRD-v2 splits and does not reward rules that overfit the validation cases.
What would settle it
Applying the final evolved rule set to a fresh legal dataset with different case distributions and measuring whether retrieval metrics still exceed those of human-designed rules and greedy selection.
Figures




read the original abstract
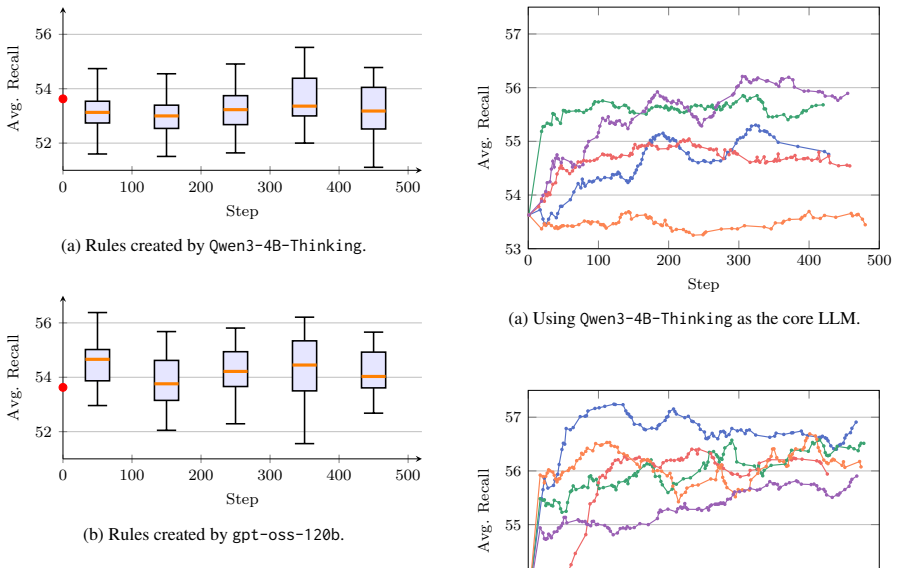
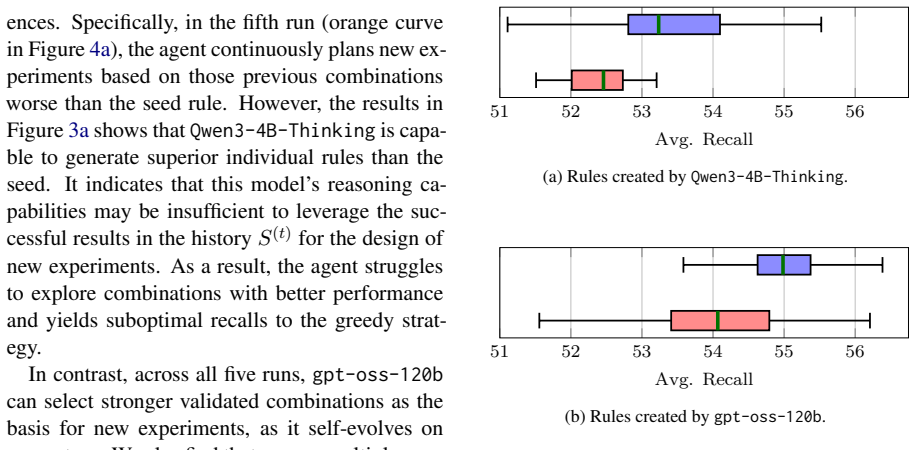
Legal case retrieval remains challenging due to the complexity of legal language and the need for precise lexical alignment between queries and relevant cases. Although dense retrieval models have achieved notable progress, empirical studies show that BM25 continues to serve as a strong baseline in this domain. It motivates us to propose a self-evolving framework for rule-driven query rewriting that enhances BM25 without any parameter training. The framework equips an LLM-based agent with an automatic evaluation environment, enabling it to iteratively create rewriting rules, plan validation experiments over rule combinations, and eliminate ineffective rules based on historical feedbacks. We evaluate our method on the Chinese legal case retrieval benchmark LeCaRD-v2. Experimental results demonstrate that the proposed framework outperforms non-evolutionary baselines, including human-designed rules and greedy rule selection, particularly when powered by a highcapacity core LLM. We also conduct detailed analyses to investigate the mechanisms underlying self-evolution. Our findings reveal that LLM's capabilities to leverage previous experimental results and its intrinsic knowledge of rule elimination play critical roles in refining the rule set via self-evolution.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a self-evolving LLM-based agent framework for rule-driven query rewriting to improve BM25 performance on legal case retrieval. The agent iteratively generates rewriting rules, plans validation experiments over rule combinations, and prunes ineffective rules using feedback from an automatic evaluation environment. Experiments on the LeCaRD-v2 benchmark claim outperformance over non-evolutionary baselines including human-designed rules and greedy selection, with stronger results when using high-capacity core LLMs; additional analyses examine the role of historical feedback and intrinsic rule-elimination knowledge.
Significance. If the reported gains are shown to arise from generalizable rules rather than in-sample optimization, the work would demonstrate a viable parameter-free method for enhancing lexical retrieval in a domain where dense models often underperform BM25. The self-evolution mechanism, if robust, could inform broader efforts to automate rule refinement without parameter training.
major comments (2)
- [Experimental Setup / Evaluation Environment] The manuscript does not explicitly describe whether the validation cases used inside the automatic evaluation environment for rule pruning and combination planning are strictly disjoint from the LeCaRD-v2 test cases used to compute final retrieval metrics. Overlap would reduce the procedure to in-sample rule search, rendering the claimed superiority over human-designed and greedy baselines inconclusive.
- [Experiments and Results] No quantitative details are supplied on the number of rules generated and eliminated, the exact validation protocol (e.g., number of held-out cases per iteration), or statistical significance of the reported improvements. Without these, the central experimental claim cannot be verified or reproduced.
minor comments (1)
- [Abstract] The abstract states that results are 'particularly' strong with high-capacity LLMs but does not name the specific models or provide the corresponding performance deltas.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important aspects of experimental rigor and reproducibility that we will address in revision. We respond to each major comment below.
read point-by-point responses
-
Referee: [Experimental Setup / Evaluation Environment] The manuscript does not explicitly describe whether the validation cases used inside the automatic evaluation environment for rule pruning and combination planning are strictly disjoint from the LeCaRD-v2 test cases used to compute final retrieval metrics. Overlap would reduce the procedure to in-sample rule search, rendering the claimed superiority over human-designed and greedy baselines inconclusive.
Authors: We agree that this distinction must be stated explicitly. The validation cases employed for rule pruning and combination planning were drawn from a held-out portion of LeCaRD-v2 that is strictly disjoint from the official test cases used for final metric computation. In the revised manuscript we will add a dedicated paragraph in the Experimental Setup section describing the data partitioning protocol and confirming the out-of-sample nature of the evolution process. revision: yes
-
Referee: [Experiments and Results] No quantitative details are supplied on the number of rules generated and eliminated, the exact validation protocol (e.g., number of held-out cases per iteration), or statistical significance of the reported improvements. Without these, the central experimental claim cannot be verified or reproduced.
Authors: We acknowledge that the current version omits these quantitative details. The revised manuscript will report: (i) the total number of rules generated and the number pruned at each iteration, (ii) the precise validation protocol including the number of held-out cases used per iteration, and (iii) statistical significance tests (paired t-test and bootstrap confidence intervals) on the reported retrieval improvements. These additions will appear in the Experiments and Results section together with the existing analyses. revision: yes
Circularity Check
No significant circularity; empirical evaluation on external benchmark
full rationale
The paper describes an empirical iterative process in which an LLM agent generates, validates, and prunes rewriting rules against an automatic evaluation environment on the LeCaRD-v2 benchmark. No equations, fitted parameters, or mathematical derivations are present. The claimed outperformance is measured by direct comparison to non-evolutionary baselines on the same external dataset; the result is not forced by definition, self-citation chains, or renaming of inputs. The evaluation loop uses historical feedback from the benchmark, which is independent of the final reported metrics under the paper's stated protocol.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption BM25 remains a strong baseline that can be improved by query rewriting without parameter training.
- ad hoc to paper The automatic evaluation environment supplies unbiased feedback sufficient for rule elimination.
invented entities (1)
-
Self-evolving LLM agent with automatic evaluation environment
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Jianlyu Chen, Shitao Xiao, Peitian Zhang, Kun Luo, Defu Lian, and Zheng Liu. 2024. https://doi.org/10.18653/v1/2024.findings-acl.137 M 3-embedding: Multi-linguality, multi-functionality, multi-granularity text embeddings through self-knowledge distillation . In Findings of the Association for Computational Linguistics: ACL 2024, pages 2318--2335, Bangkok,...
-
[2]
DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, and 181 others. 2025. https://arxiv.org/abs/2501.12948 Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement lea...
Pith/arXiv arXiv 2025
-
[3]
Chenlong Deng, Zhicheng Dou, Yujia Zhou, Peitian Zhang, and Kelong Mao. 2024. https://aclanthology.org/2024.findings-acl.139/ An element is worth a thousand words: Enhancing legal case retrieval by incorporating legal elements . In Findings of the Association for Computational Linguistics: ACL 2024, pages 2354--2365, Bangkok, Thailand. Association for Com...
2024
-
[4]
Gemma Team , Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ramé, Morgane Rivière, Louis Rouillard, Thomas Mesnard, Geoffrey Cideron, Jean bastien Grill, Sabela Ramos, Edouard Yvinec, Michelle Casbon, Etienne Pot, Ivo Penchev, and 197 others. 2025. https://arxiv.org/abs/2503.1978...
Pith/arXiv arXiv 2025
-
[5]
Yutong Hu, Kangcheng Luo, and Yansong Feng. 2024. https://doi.org/10.18653/v1/2024.acl-demos.36 ELLA : Empowering LLM s for interpretable, accurate and informative legal advice . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations), pages 374--387, Bangkok, Thailand. Association for C...
-
[6]
Haitao Li, Qingyao Ai, Jia Chen, Qian Dong, Yueyue Wu, Yiqun Liu, Chong Chen, and Qi Tian. 2023. https://doi.org/10.1145/3539618.3591761 Sailer: Structure-aware pre-trained language model for legal case retrieval . In Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR '23, page 1035–1044,...
-
[7]
Haitao Li, Yunqiu Shao, Yueyue Wu, Qingyao Ai, Yixiao Ma, and Yiqun Liu. 2024. https://doi.org/10.1145/3626772.3657887 Lecardv2: A large-scale chinese legal case retrieval dataset . In Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR '24, page 2251–2260, New York, NY, USA. Association f...
-
[8]
Jimmy Lin, Xueguang Ma, Sheng-Chieh Lin, Jheng-Hong Yang, Ronak Pradeep, and Rodrigo Nogueira. 2021. Pyserini : A Python toolkit for reproducible information retrieval research with sparse and dense representations. In Proceedings of the 44th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR 2021), pages...
2021
-
[9]
Mistral-AI, Abhinav Rastogi, Albert Q. Jiang, Andy Lo, Gabrielle Berrada, Guillaume Lample, Jason Rute, Joep Barmentlo, Karmesh Yadav, Kartik Khandelwal, Khyathi Raghavi Chandu, Léonard Blier, Lucile Saulnier, Matthieu Dinot, Maxime Darrin, Neha Gupta, Roman Soletskyi, Sagar Vaze, Teven Le Scao, and 81 others. 2025. https://arxiv.org/abs/2506.10910 Magist...
arXiv 2025
-
[10]
OpenAI, Sandhini Agarwal, Lama Ahmad, Jason Ai, Sam Altman, Andy Applebaum, Edwin Arbus, Rahul K. Arora, Yu Bai, Bowen Baker, Haiming Bao, Boaz Barak, Ally Bennett, Tyler Bertao, Nivedita Brett, Eugene Brevdo, Greg Brockman, Sebastien Bubeck, Che Chang, and 107 others. 2025. https://arxiv.org/abs/2508.10925 gpt-oss-120b & gpt-oss-20b model card . Preprint...
Pith/arXiv arXiv 2025
-
[11]
Stephen Robertson and Hugo Zaragoza. 2009. https://doi.org/10.1561/1500000019 The probabilistic relevance framework: Bm25 and beyond . Found. Trends Inf. Retr., 3(4):347–369
-
[12]
Guilherme Moraes Rosa, Ruan Chaves Rodrigues, Roberto Lotufo, and Rodrigo Nogueira. 2021. https://arxiv.org/abs/2105.05686 Yes, bm25 is a strong baseline for legal case retrieval . Preprint, arXiv:2105.05686
arXiv 2021
-
[13]
Weihang Su, Qingyao Ai, Yueyue Wu, Yixiao Ma, Haitao Li, Yiqun Liu, Zhijing Wu, and Min Zhang. 2024. https://arxiv.org/abs/2311.00333 Caseformer: Pre-training for legal case retrieval based on inter-case distinctions . Preprint, arXiv:2311.00333
arXiv 2024
-
[14]
Mirac Suzgun, Mert Yuksekgonul, Federico Bianchi, Dan Jurafsky, and James Zou. 2025. https://arxiv.org/abs/2504.07952 Dynamic cheatsheet: Test-time learning with adaptive memory . Preprint, arXiv:2504.07952
arXiv 2025
-
[15]
Yanran Tang, Ruihong Qiu, Xue Li, and Zi Huang. 2025. https://arxiv.org/abs/2510.26178 Reakase-8b: Legal case retrieval via knowledge and reasoning representations with llms . Preprint, arXiv:2510.26178
arXiv 2025
-
[16]
Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V Le, Ed H. Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. 2023. https://openreview.net/forum?id=1PL1NIMMrw Self-consistency improves chain of thought reasoning in language models . In The Eleventh International Conference on Learning Representations
2023
-
[17]
Chi, Quoc V Le, and Denny Zhou
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, brian ichter, Fei Xia, Ed H. Chi, Quoc V Le, and Denny Zhou. 2022. https://openreview.net/forum?id=_VjQlMeSB_J Chain of thought prompting elicits reasoning in large language models . In Advances in Neural Information Processing Systems
2022
-
[18]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, and 41 others. 2025. https://arxiv.org/abs/2505.09388 Qwen3 technical report . Preprint, arXiv:2505.09388
Pith/arXiv arXiv 2025
-
[19]
Yunpeng Zhai, Shuchang Tao, Cheng Chen, Anni Zou, Ziqian Chen, Qingxu Fu, Shinji Mai, Li Yu, Jiaji Deng, Zouying Cao, Zhaoyang Liu, Bolin Ding, and Jingren Zhou. 2025. https://arxiv.org/abs/2511.10395 Agentevolver: Towards efficient self-evolving agent system . Preprint, arXiv:2511.10395
arXiv 2025
-
[20]
Ding-Chu Zhang, Yida Zhao, Jialong Wu, Liwen Zhang, Baixuan Li, Wenbiao Yin, Yong Jiang, Yu-Feng Li, Kewei Tu, Pengjun Xie, and Fei Huang. 2025 a . https://doi.org/10.18653/v1/2025.emnlp-main.663 E volve S earch: An iterative self-evolving search agent . In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 13134...
-
[21]
Qizheng Zhang, Changran Hu, Shubhangi Upasani, Boyuan Ma, Fenglu Hong, Vamsidhar Kamanuru, Jay Rainton, Chen Wu, Mengmeng Ji, Hanchen Li, Urmish Thakker, James Zou, and Kunle Olukotun. 2025 b . https://arxiv.org/abs/2510.04618 Agentic context engineering: Evolving contexts for self-improving language models . Preprint, arXiv:2510.04618
Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.