LADBench: A Benchmark for Logical Fault Detection in Images
Pith reviewed 2026-06-27 02:15 UTC · model grok-4.3
The pith
Vision-language models detect logical faults in images at only 70 percent accuracy even with explicit hints.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
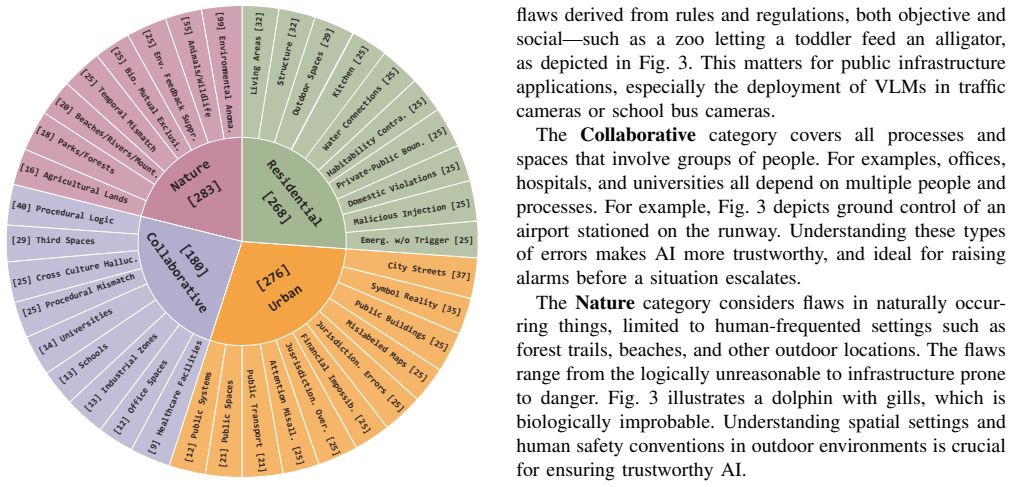
LAD-bench supplies more than 1,000 curated synthetic images containing logical anomalies across Residential, Urban, Collaborative, and Nature domains. A Tiered Prompting Protocol based on progressive disclosure quantifies how much explicit help each model requires to localize and reason about a fault. Evaluation of leading foundation models shows the strongest overall accuracy is 70.11 percent, with many failures persisting even when deeper tiers supply direct hints about the anomaly.
What carries the argument
The Tiered Prompting Protocol, which presents questions at increasing levels of explicit disclosure to measure the assistance needed for logical fault detection and reasoning.
If this is right
- Autonomous visual systems require further advances in sequential multimodal reasoning before they can be considered reliable in open environments.
- Training regimes must incorporate more implicit physical and social common-sense constraints to close the performance gap shown by the benchmark.
- Safety evaluations of vision-language models should include progressive-hint protocols rather than single-shot prompts alone.
- Progress on the benchmark would directly improve the cognitive alignment of systems intended for deployment without constant human oversight.
Where Pith is reading between the lines
- Extending the benchmark to video sequences or interactive agent settings would test whether the same limitations appear in dynamic scenes.
- The tiered protocol could be adapted to diagnose specific failure modes, such as object-relation reasoning versus scene-level consistency.
- If real-world images produce similar results, the benchmark would support targeted data collection focused on underrepresented anomaly types.
Load-bearing premise
The curated synthetic images and selected logical anomalies accurately reflect the physical and social common sense required for real open-world scenes without introducing artifacts that change task difficulty.
What would settle it
Running the same models on a matched set of real photographs that contain comparable logical anomalies and checking whether accuracy remains near 70 percent or drops sharply.
Figures


read the original abstract
Large Vision Language Models (VLMs) excel at visual question answering and semantic grounding, but their capacity for autonomous logical reasoning remains underexplored. Existing anomaly benchmarks emphasize visual errors or direct prompting rather than the physical and social common sense needed for open-world deployment. To address this, we introduce LAD-bench, a benchmark of more than 1,000 curated synthetic images with logical anomalies across four domains: Residential, Urban, Collaborative, and Nature. We further propose a Tiered Prompting Protocol based on progressive disclosure, which measures how much explicit assistance a model needs to localize and reason about a logical fault. Evaluating leading foundation models reveals substantial weaknesses: even the best achieves only 70.11% overall accuracy, showing that implicit logical fault detection remains unsolved. Crucially, models often fail to identify anomalies even after receiving explicit hints in deeper tiers. By surfacing these limitations in sequential multimodal reasoning, LAD-Bench offers a rigorous framework for advancing the safety, reliability, and cognitive alignment of autonomous visual systems. Dataset and Code: https://huggingface.co/datasets/SahasraK/LADBench
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LADBench, a benchmark of >1000 curated synthetic images containing logical anomalies across four domains (Residential, Urban, Collaborative, Nature), along with a Tiered Prompting Protocol that progressively discloses information to measure how much explicit assistance VLMs require to localize and reason about faults. Evaluation of leading foundation models shows a best-case overall accuracy of 70.11%, from which the authors conclude that implicit logical fault detection remains unsolved and that models frequently fail even with explicit hints.
Significance. If the dataset and protocol are shown to be free of low-level artifacts and representative of open-world common-sense requirements, the benchmark would provide a useful stress test for multimodal reasoning in safety-critical applications. The tiered protocol itself is a constructive contribution for quantifying reliance on explicit guidance. The work does not include machine-checked proofs or parameter-free derivations.
major comments (3)
- [Dataset construction / §3] Dataset construction section: the manuscript supplies no quantitative validation of the logical anomalies (e.g., inter-annotator agreement, human baseline performance, or controls confirming that anomalies cannot be solved by low-level visual regularities), which is load-bearing for the central claim that 70.11% accuracy demonstrates an unsolved implicit-reasoning problem rather than an artifact of the synthetic generation process.
- [Evaluation / Results] Evaluation protocol and results: no ablation or control is reported for prompt sensitivity, generation-parameter effects, or matched real-vs-synthetic image pairs, leaving open the possibility that the reported performance gap (and the failure even in deeper tiers) is driven by domain-specific cues rather than genuine common-sense deficits.
- [Abstract / §4] Abstract and §4: the headline claim that 'implicit logical fault detection remains unsolved' and the generalization to 'autonomous visual systems' rests on the untested assumption that the four-domain synthetic images accurately capture physical and social common sense without introducing easier or harder artifacts than real scenes; no such controls are described.
minor comments (2)
- [Abstract] The abstract states the 70.11% figure but does not define the exact accuracy metric (e.g., whether it aggregates across all tiers or only the implicit tier).
- [Dataset description] Dataset link is provided, but the paper does not include a table summarizing per-domain image counts, anomaly types, or tier-wise difficulty statistics.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below, indicating where revisions will be made to strengthen the manuscript while preserving the core contributions of LADBench and the Tiered Prompting Protocol.
read point-by-point responses
-
Referee: [Dataset construction / §3] Dataset construction section: the manuscript supplies no quantitative validation of the logical anomalies (e.g., inter-annotator agreement, human baseline performance, or controls confirming that anomalies cannot be solved by low-level visual regularities), which is load-bearing for the central claim that 70.11% accuracy demonstrates an unsolved implicit-reasoning problem rather than an artifact of the synthetic generation process.
Authors: We agree that quantitative validation strengthens the claims. In the revised manuscript we will add inter-annotator agreement statistics for the anomaly curation process and human baseline accuracy on a sampled subset of images. The logical anomalies are defined by construction to require violations of physical or social common sense (e.g., impossible configurations or interactions) rather than low-level visual cues; we will expand §3 with explicit examples and design rationale to clarify this distinction. revision: yes
-
Referee: [Evaluation / Results] Evaluation protocol and results: no ablation or control is reported for prompt sensitivity, generation-parameter effects, or matched real-vs-synthetic image pairs, leaving open the possibility that the reported performance gap (and the failure even in deeper tiers) is driven by domain-specific cues rather than genuine common-sense deficits.
Authors: We will add an ablation on prompt sensitivity by evaluating small variations of the tiered prompts. Generation parameters followed standard model defaults, which we will state explicitly. Matched real-versus-synthetic pairs lie outside the current controlled synthetic scope; we will add a dedicated limitations paragraph discussing this gap and its implications for generalization. revision: partial
-
Referee: [Abstract / §4] Abstract and §4: the headline claim that 'implicit logical fault detection remains unsolved' and the generalization to 'autonomous visual systems' rests on the untested assumption that the four-domain synthetic images accurately capture physical and social common sense without introducing easier or harder artifacts than real scenes; no such controls are described.
Authors: The synthetic design isolates logical anomalies that demand common-sense reasoning, which is the benchmark's intended focus. We will revise the abstract and §4 to qualify the generalization, explicitly noting the synthetic setting and the assumption that the chosen domains reflect representative common-sense requirements, while retaining the empirical observation that even explicit hints yield limited performance. revision: yes
Circularity Check
Empirical benchmark creation with no derivation chain or self-referential reductions
full rationale
The paper introduces a new benchmark dataset of synthetic images and evaluates existing VLMs on it using a tiered prompting protocol. No equations, fitted parameters, or mathematical derivations are present. Claims rest on direct empirical accuracy measurements rather than any reduction to prior self-citations or constructed quantities. The work is self-contained against external model evaluations and does not invoke uniqueness theorems or ansatzes from the authors' prior work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Synthetic images with curated logical anomalies can serve as a valid proxy for real-world physical and social common sense required in open-world deployment.
Reference graph
Works this paper leans on
-
[1]
A. Singh, A. Fry, A. Perelman, A. Tart, A. Ganesh, A. El-Kishky, A. McLaughlin, A. Low, A. Ostrow, A. Ananthramet al., “Openai gpt-5 system card,”arXiv preprint arXiv:2601.03267, 2025
Pith/arXiv arXiv 2025
-
[2]
Gem- ini: a family of highly capable multimodal models,
G. Team, R. Anil, S. Borgeaud, J.-B. Alayrac, J. Yu, R. Soricut, J. Schalkwyk, A. M. Dai, A. Hauth, K. Millicanet al., “Gem- ini: a family of highly capable multimodal models,”arXiv preprint arXiv:2312.11805, 2023
Pith/arXiv arXiv 2023
-
[3]
Mmbench: Is your multi-modal model an all-around player?
Y . Liu, H. Duan, Y . Zhang, B. Li, S. Zhang, W. Zhao, Y . Yuan, J. Wang, C. He, Z. Liuet al., “Mmbench: Is your multi-modal model an all-around player?” inEuropean conference on computer vision. Springer, 2024, pp. 216–233
2024
-
[4]
Logic unseen: Revealing the logical blindspots of vision-language models,
Y . Zhou, J. Tang, S. Yang, X. Xiao, Y . Dai, W. Yang, C. Gou, X. Xia, and T.-S. Chua, “Logic unseen: Revealing the logical blindspots of vision-language models,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 40, no. 34, 2026, pp. 29 062–29 070
2026
-
[5]
Logicqa: Logical anomaly detection with vision language model generated questions,
Y . Kwon, D. Moon, Y . Oh, and H. Yoon, “Logicqa: Logical anomaly detection with vision language model generated questions,” inPro- ceedings of the 63rd Annual Meeting of the Association for Compu- tational Linguistics (Volume 6: Industry Track), 2025, pp. 411–432
2025
-
[6]
Vision-language models can’t see the obvious,
N. D. Huynh, P. H. Le-Khac, W. R. Para, A. Singh, and S. Narayan, “Vision-language models can’t see the obvious,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 24 159–24 169
2025
-
[7]
U. Grover, R. Ranjan, M. Mao, T. T. Dong, S. Praveen, Z. Wu, J. M. Chang, T. Mohsenin, Y . Sheng, A. Polyzou, and X. Lin, “Embodied foundation models at the edge: A survey of deployment constraints and mitigation strategies,” inarXiv preprint arXiv:2603.16952, 2026
arXiv 2026
-
[8]
Spotting the unexpected (stu): A 3d lidar dataset for anomaly seg- mentation in autonomous driving,
A. Nekrasov, M. Burdorf, S. Worrall, B. Leibe, and J. S. B. Perez, “Spotting the unexpected (stu): A 3d lidar dataset for anomaly seg- mentation in autonomous driving,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 11 875–11 885
2025
-
[9]
gpt-5-nano,
OpenAI, “gpt-5-nano,” Accessed: 3/3/2026, 2025, vision Capabable Large Language Model. [Online]. Available: https://developers.openai. com/api/docs/models/gpt-5-nano
2026
-
[10]
Plovad: Prompting vision- language models for open vocabulary video anomaly detection,
C. Xu, K. Xu, X. Jiang, and T. Sun, “Plovad: Prompting vision- language models for open vocabulary video anomaly detection,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 35, no. 6, pp. 5925–5938, 2025
2025
-
[11]
Video anomaly detection in 10 years: A survey and outlook,
M. Abdalla, S. Javed, M. Al Radi, A. Ulhaq, and N. Werghi, “Video anomaly detection in 10 years: A survey and outlook,”Neural Com- puting and Applications, vol. 37, no. 32, pp. 26 321–26 364, 2025
2025
-
[12]
Nesylad: A neuro-symbolic approach for unsupervised logi- cal anomaly detection,
M. Dahmardeh, M. Saadatpour, F. Manigrasso, L. Morra, and F. Setti, “Nesylad: A neuro-symbolic approach for unsupervised logi- cal anomaly detection,” inInternational Conference on Image Analysis and Processing. Springer, 2025, pp. 598–610
2025
-
[13]
Towards training-free anomaly detection with vision and language foundation models,
J. Zhang, G. Wang, Y . Jin, and D. Huang, “Towards training-free anomaly detection with vision and language foundation models,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025, pp. 15 204–15 213
2025
-
[14]
Madclip: few-shot medical anomaly detection with clip,
M. Shiri, C. Beyan, and V . Murino, “Madclip: few-shot medical anomaly detection with clip,” inInternational Conference on Medical Image Computing and Computer-Assisted Intervention. Springer, 2025, pp. 416–426
2025
-
[15]
Adapting visual-language models for generalizable anomaly detection in medical images,
C. Huang, A. Jiang, J. Feng, Y . Zhang, X. Wang, and Y . Wang, “Adapting visual-language models for generalizable anomaly detection in medical images,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 11 375–11 385
2024
-
[16]
Smarthome-bench: A comprehensive benchmark for video anomaly detection in smart homes using multi-modal large language models,
X. Zhao, C. Zhang, P. Guo, W. Li, L. Chen, C. Zhao, and S. Huang, “Smarthome-bench: A comprehensive benchmark for video anomaly detection in smart homes using multi-modal large language models,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 3975–3985
2025
-
[17]
Sequential keypoint density estimator: an overlooked baseline of skeleton-based video anomaly detection,
A. Deli ´c, M. Grcic, and S. ˇSegvi´c, “Sequential keypoint density estimator: an overlooked baseline of skeleton-based video anomaly detection,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 11 579–11 589
2025
-
[18]
Vane-bench: Video anomaly evaluation benchmark for conversational lmms,
H. Gani, R. Bharadwaj, M. Naseer, F. S. Khan, and S. Khan, “Vane-bench: Video anomaly evaluation benchmark for conversational lmms,” inFindings of the Association for Computational Linguistics: NAACL 2025, 2025, pp. 3123–3140
2025
-
[19]
Logicad: Explainable anomaly detection via vlm-based text feature extraction,
E. Jin, Q. Feng, Y . Mou, G. Lakemeyer, S. Decker, O. Simons, and J. Stegmaier, “Logicad: Explainable anomaly detection via vlm-based text feature extraction,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 4, 2025, pp. 4129–4137
2025
-
[20]
Gpt-4v-ad: Exploring grounding potential of vqa-oriented gpt- 4v for zero-shot anomaly detection,
J. Zhang, H. He, X. Chen, Z. Xue, Y . Wang, C. Wang, L. Xie, and Y . Liu, “Gpt-4v-ad: Exploring grounding potential of vqa-oriented gpt- 4v for zero-shot anomaly detection,” inInternational Joint Conference on Artificial Intelligence. Springer, 2024, pp. 3–16
2024
-
[21]
Vbench: Comprehensive benchmark suite for video generative models,
Z. Huang, Y . He, J. Yu, F. Zhang, C. Si, Y . Jiang, Y . Zhang, T. Wu, Q. Jin, N. Chanpaisitet al., “Vbench: Comprehensive benchmark suite for video generative models,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 21 807–21 818
2024
-
[22]
Multi-rag: A multimodal retrieval- augmented generation system for adaptive video understanding,
M. Mao, M. M. Perez-Cabarcas, U. Kallakuri, N. R. Waytowich, X. Lin, and T. Mohsenin, “Multi-rag: A multimodal retrieval- augmented generation system for adaptive video understanding,” in Pacific-Asia Conference on Knowledge Discovery and Data Mining. Springer, 2026
2026
-
[23]
Cave: Detecting and explaining commonsense anomalies in visual environments,
R. Bhagwatkar, S. Montariol, A. Romanou, B. Borges, I. Rish, and A. Bosselut, “Cave: Detecting and explaining commonsense anomalies in visual environments,” inProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, 2025, pp. 27 098–27 139
2025
-
[24]
Fam-bench: A multimodal benchmark for condition-aware food-as-medicine reasoning,
M. Mao, B. R. Medisetti, U. Grover, T. Ibrahim, W. Li, T. Zhang, and X. Lin, “Fam-bench: A multimodal benchmark for condition-aware food-as-medicine reasoning,”arXiv preprint arXiv:2605.31410, 2026
Pith/arXiv arXiv 2026
-
[25]
gpt-image-1,
OpenAI, “gpt-image-1,” Accessed: 3/3/2026, 2025, vision Capabable Large Language Model. [Online]. Available: https://developers.openai. com/api/docs/models/gpt-image-1
2026
-
[26]
gpt-5-mini,
——, “gpt-5-mini,” Accessed: 3/3/2026, 2025, vision Capabable Large Language Model. [Online]. Available: https://developers.openai.com/ api/docs/models/gpt-5-mini
2026
-
[27]
[Online]
——, “gpt-5,” Accessed: 3/3/2026, 2025, vision Capabable Large Language Model. [Online]. Available: https://developers.openai.com/ api/docs/models/gpt-5
2026
-
[28]
claude-sonnet-4-6,
Anthropic, “claude-sonnet-4-6,” Accessed: 3/3/2026, 2026, vision Capabable Large Language Model. [Online]. Available: https: //www.anthropic.com/claude/sonnet
2026
-
[29]
gemini-3-flash-preview,
Google, “gemini-3-flash-preview,” Accessed: 3/3/2026, 2025, vision Capabable Large Language Model. [Online]. Available: https://docs. cloud.google.com/vertex-ai/generative-ai/docs/models/gemini/3-flash
2026
-
[30]
grok-4.1-fast-reasoning,
XAI, “grok-4.1-fast-reasoning,” Accessed: 3/3/2026, Year, vision Capabable Large Language Model. [Online]. Available: https: //docs.x.ai/developers/models/grok-4-1-fast-reasoning
2026
-
[31]
A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al- Dahle, A. Letman, A. Mathur, A. Schelten, A. Vaughanet al., “The llama 3 herd of models,”arXiv preprint arXiv:2407.21783, 2024
Pith/arXiv arXiv 2024
-
[32]
S. e. a. Bai, “Qwen3-vl technical report,”arXiv:2511.21631, 2025. [Online]. Available: https://arxiv.org/abs/2511.21631
Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.