SPHINX: First Explain, Then Explore
Pith reviewed 2026-06-27 01:47 UTC · model grok-4.3
The pith
SPHINX generates adversarial driving scenarios by first using explainable AI to diagnose specific policy failures, then creating targeted tests from those diagnoses.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SPHINX demonstrates that a framework which first applies explainable AI to surface key visual concepts and decision uncertainties from a driving policy, then uses a vision-language model to rationalize and criticize the identified failure modes, can generate adversarial scenarios that specifically address those modes, yielding more effective policy improvement than methods relying primarily on prior knowledge of large language models.
What carries the argument
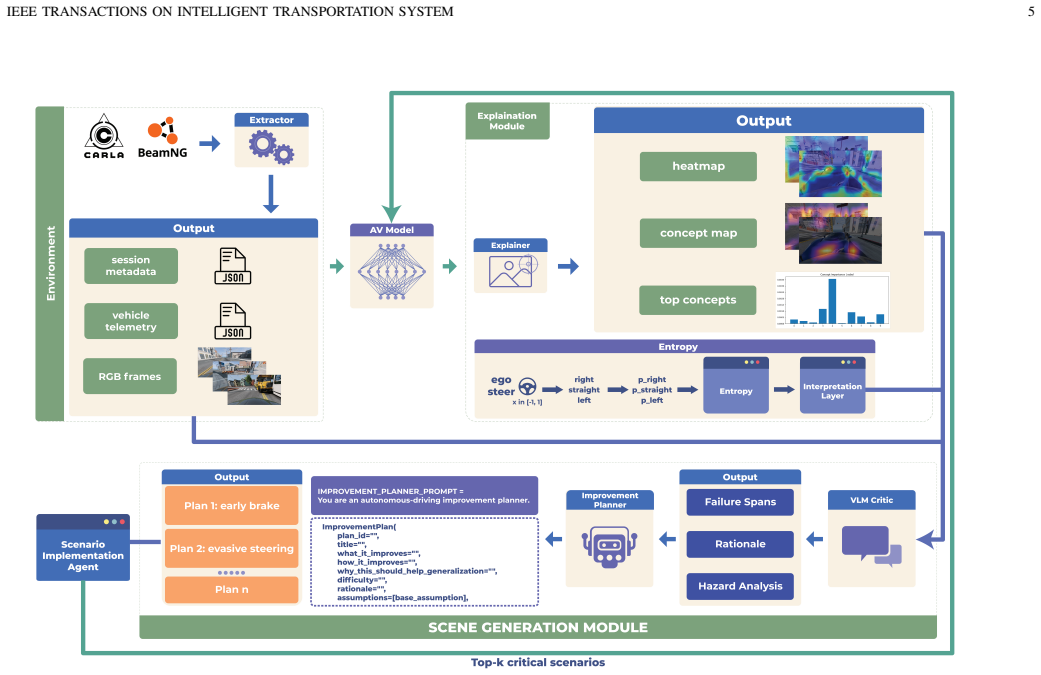
The explain-then-explore loop that converts XAI-derived policy evidence into vision-language model critics and then into targeted adversarial scenarios.
If this is right
- SPHINX supplies an interpretable record of policy failures that other adversarial generation methods do not.
- The framework applies to multiple state-of-the-art autonomous vehicle architectures without modification.
- Retraining with SPHINX-generated scenarios produces consistent robustness gains over existing scenario-generation baselines.
- The closed-loop structure allows iterative refinement where new critics inform subsequent scenario batches.
Where Pith is reading between the lines
- The same diagnosis-first pattern could be tested on other sequential decision systems such as robotic manipulation policies.
- If the extracted concepts prove causal, the method might reduce the number of scenarios needed for meaningful robustness gains.
- Extending the loop to include human review of the generated critics could surface additional failure modes the model overlooks.
Load-bearing premise
Explainable AI methods can reliably surface the visual concepts and decision uncertainties that are causally responsible for the policy failures.
What would settle it
A head-to-head test on the same benchmarks where adversarial scenarios generated without the XAI diagnosis step produce equal or greater robustness improvements than those generated by SPHINX.
Figures



read the original abstract
Generating adversarial driving scenarios is critical for evaluating and improving autonomous vehicle decision-making systems in simulation. Recent approaches, such as ChatScene and LLM-Attacker, rely primarily on the prior knowledge of Large Language Models and Vision-Language Models to generate driving scenarios procedurally. We argue that adversarial scenes should be generated based on the failure diagnosis (e.g., indecisiveness, multi-frame inconsistency) of the driving policy to specifically address the policy's weaknesses instead of relying on prior assumptions. In this paper, we propose SPHINX, a closed-loop framework for adversarial scenario synthesis guided by a simple principle: first explain, then explore. Beyond blindly exploring the scenario space, SPHINX leverages explainable artificial intelligence methods to analyze the policy, identifying key visual concepts and their influence on policy outputs, and the uncertainty of the decisions. Given the interpretable evidence extracted from the policy's own decision process, we use a vision language model to rationalize and criticize failure modes of the current policy. These critics are then used to generate targeted adversarial scenarios for policy retraining and improvement. We demonstrate that SPHINX can highlight an interpretable account of policy failures while other adversarial scene generation cannot. Across the evaluated benchmarks and test suites, SPHINX can be applied to diverse state-of-the-art autonomous vehicle architectures and yields consistent robustness improvements over existing scenario-generation methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SPHINX, a closed-loop framework for adversarial scenario synthesis in autonomous driving. It first applies explainable AI methods to diagnose policy failures (e.g., indecisiveness, multi-frame inconsistency) by identifying key visual concepts and decision uncertainty, then uses a vision-language model to generate rationalized critics of those failures. These critics guide the creation of targeted adversarial scenarios for policy retraining. The authors claim that this 'explain then explore' approach produces interpretable failure accounts (unlike prior methods such as ChatScene and LLM-Attacker) and delivers consistent robustness gains across diverse state-of-the-art AV architectures and benchmarks.
Significance. If the empirical claims hold, the work offers a principled alternative to prior-knowledge-driven scenario generation by grounding adversarial examples in the policy's own decision process. This could improve both the effectiveness of robustness testing and the interpretability of failure modes, with potential downstream benefits for AV safety validation. The integration of XAI diagnostics with VLM-based criticism is a distinctive contribution, though its value depends on the reliability of the causal link between diagnosed factors and generated scenarios.
major comments (3)
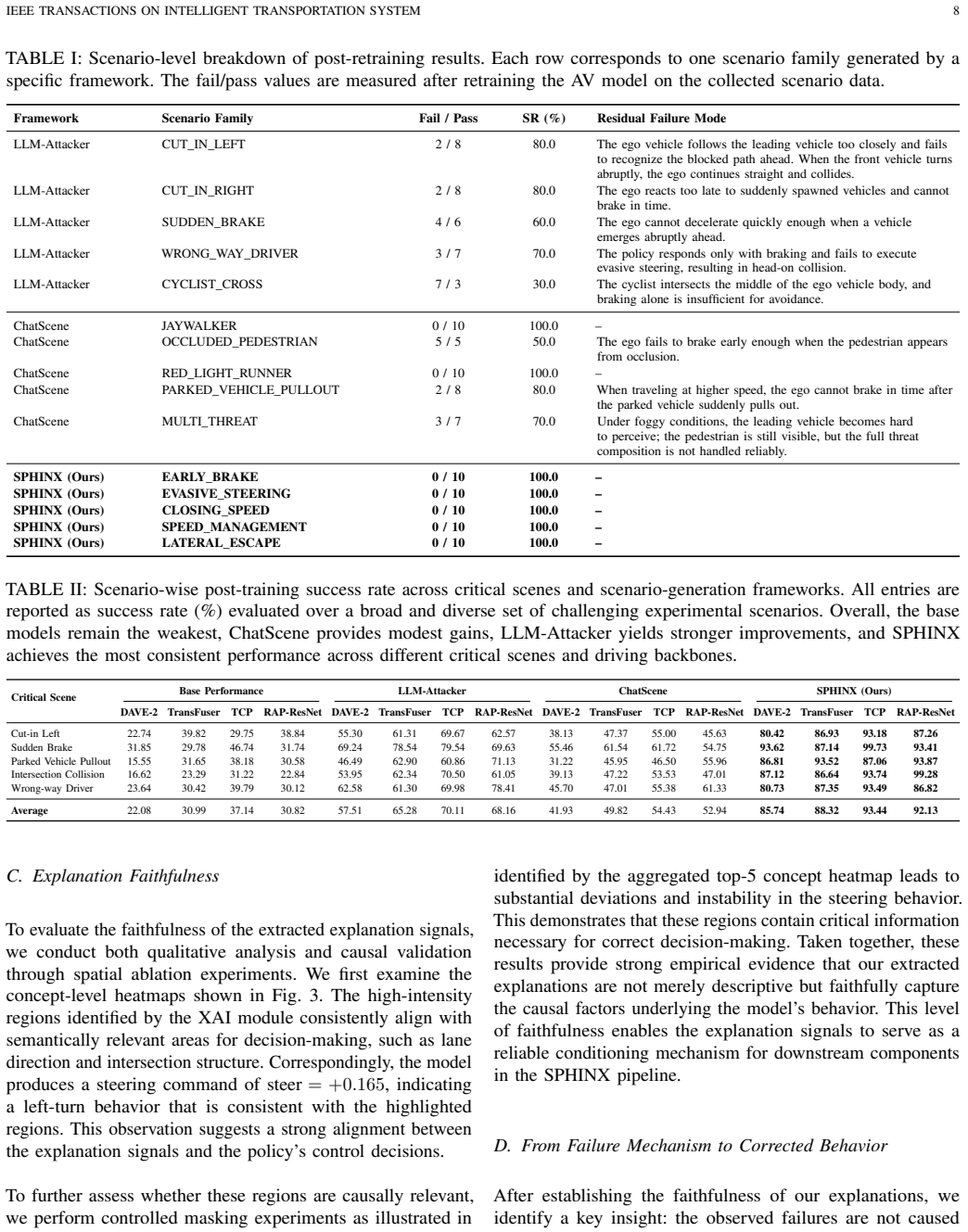
- [Abstract and §4 (Experiments)] Abstract and §4 (Experiments): The central claim of 'consistent robustness improvements over existing scenario-generation methods' is load-bearing yet unsupported by any quantitative metrics, baselines, statistical tests, or error bars in the provided description; without these, the superiority assertion cannot be evaluated.
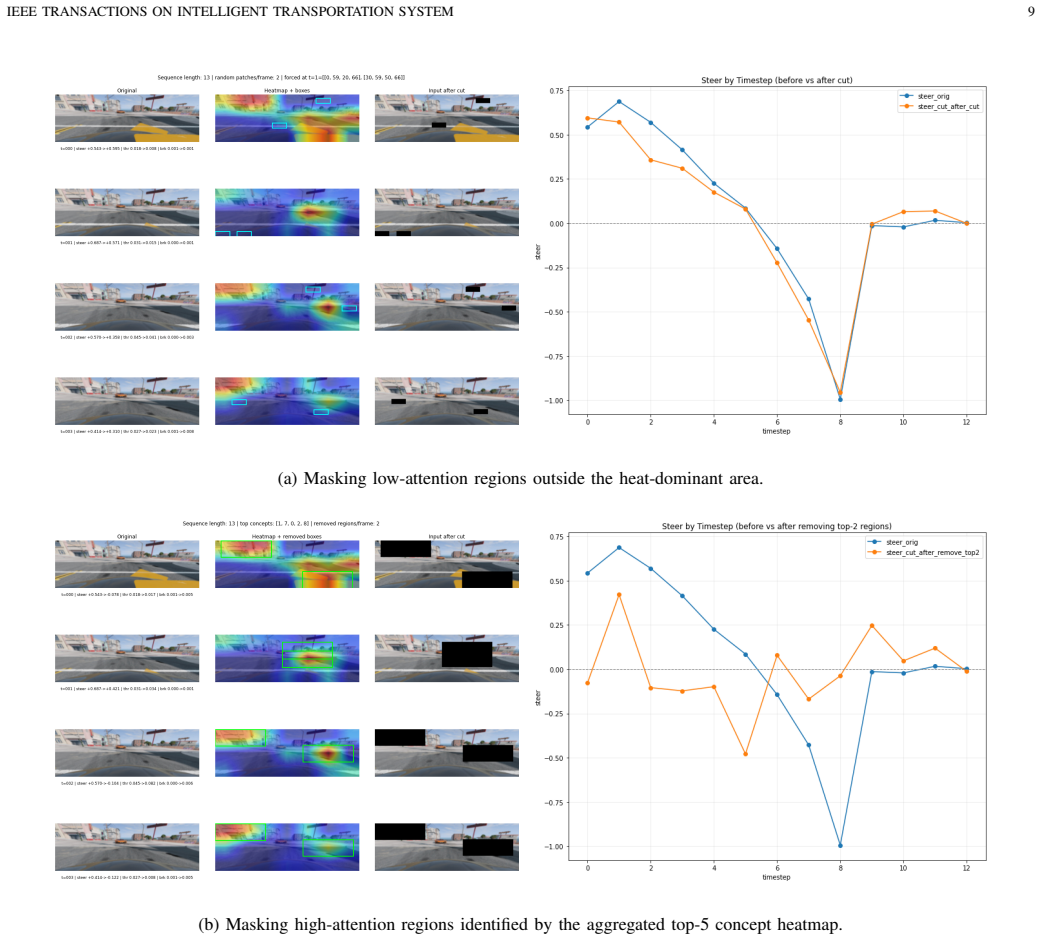
- [§3 (Method)] §3 (Method): The framework assumes XAI methods reliably surface causally responsible visual concepts and uncertainties; this assumption is load-bearing for the 'explain then explore' principle but lacks explicit validation experiments demonstrating that addressing the identified factors produces measurable policy gains beyond what blind exploration achieves.
- [Abstract] Abstract: The claim that SPHINX 'can highlight an interpretable account of policy failures while other adversarial scene generation cannot' requires a concrete metric or user study for interpretability; absent this, the comparative interpretability advantage remains unquantified.
minor comments (2)
- [Abstract] Abstract: Define XAI and VLM on first use for clarity.
- Notation: Ensure consistent use of terms such as 'critics' and 'adversarial scenarios' across sections to avoid ambiguity.
Simulated Author's Rebuttal
Thank you for the detailed and constructive review. We address each major comment point by point below, agreeing where revisions are needed to strengthen empirical support and clarify claims. We will update the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract and §4 (Experiments)] Abstract and §4 (Experiments): The central claim of 'consistent robustness improvements over existing scenario-generation methods' is load-bearing yet unsupported by any quantitative metrics, baselines, statistical tests, or error bars in the provided description; without these, the superiority assertion cannot be evaluated.
Authors: We agree that the abstract and experiments section would benefit from more explicit quantitative presentation. Section 4 already reports robustness metrics on AV benchmarks with comparisons to baselines including ChatScene and LLM-Attacker. In the revision we will add error bars from multiple runs, report the exact numerical values, and include statistical significance tests (e.g., paired t-tests) to allow direct evaluation of the claimed gains. revision: yes
-
Referee: [§3 (Method)] §3 (Method): The framework assumes XAI methods reliably surface causally responsible visual concepts and uncertainties; this assumption is load-bearing for the 'explain then explore' principle but lacks explicit validation experiments demonstrating that addressing the identified factors produces measurable policy gains beyond what blind exploration achieves.
Authors: This is a fair observation. While the end-to-end results support the overall approach, we acknowledge the value of isolating the contribution of the XAI diagnostics. In the revised manuscript we will add an ablation comparing SPHINX against a blind-exploration baseline that generates scenarios without the XAI-derived critics, thereby quantifying the incremental benefit of the diagnosed factors. revision: yes
-
Referee: [Abstract] Abstract: The claim that SPHINX 'can highlight an interpretable account of policy failures while other adversarial scene generation cannot' requires a concrete metric or user study for interpretability; absent this, the comparative interpretability advantage remains unquantified.
Authors: We accept that the interpretability advantage should be quantified rather than asserted qualitatively. The current manuscript illustrates the difference through concrete failure-account examples. In revision we will introduce a simple quantitative proxy (e.g., specificity and actionability scores assigned to the generated critics) and, if space permits, report results from a small human evaluation; otherwise we will tone down the claim to reflect the available evidence. revision: partial
Circularity Check
No significant circularity identified
full rationale
The paper's central chain relies on external XAI tools to surface policy uncertainties and a separate VLM to translate those into critics and scenarios; the robustness gains are framed as empirical outcomes on benchmarks rather than any derivation that reduces to fitted parameters or self-referential definitions. No equations, uniqueness theorems, or load-bearing self-citations appear in the provided text that would make a prediction equivalent to its inputs by construction. The argument is therefore self-contained against external benchmarks and does not exhibit any of the enumerated circular patterns.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption XAI methods can extract interpretable evidence of policy failures from visual inputs and decision uncertainty
- domain assumption Vision-language models can produce useful critics and scenarios from XAI-derived evidence
Reference graph
Works this paper leans on
-
[1]
End to end learning for self-driving cars,
M. Bojarski, D. D. Testa, D. Dworakowski, B. Firner, B. Flepp, P. Goyal, L. D. Jackel, M. Monfort, U. Muller, J. Zhang, X. Zhang, J. Zhao, and K. Zieba, “End to end learning for self-driving cars,” 2016. [Online]. Available: https://arxiv.org/abs/1604.07316
Pith/arXiv arXiv 2016
-
[2]
Model-based imitation learning for urban driving,
A. Hu, G. Corrado, N. Griffiths, Z. Murez, C. Gurau, H. Yeo, A. Kendall, R. Cipolla, and J. Shotton, “Model-based imitation learning for urban driving,”Advances in Neural Information Processing Systems, vol. 35, pp. 20 703–20 716, 2022
2022
-
[3]
Chitta, A
K. Chitta, A. Prakash, B. Jaeger, Z. Yu, K. Renz, and A. Geiger, “Trans- fuser: Imitation with transformer-based sensor fusion for autonomous IEEE TRANSACTIONS ON INTELLIGENT TRANSPORTATION SYSTEM 12 (a) After fine-tuning with SPHINX, the model focuses on the approaching wrong-way vehicle and produces a smoother avoidance response across frames 158–173: s...
2022
-
[4]
RAP: 3d rasterization augmented end-to-end planning,
L. Feng, Y . Gao, E. Zablocki, Q. Li, W. Li, S. Liu, M. Cord, and A. Alahi, “RAP: 3d rasterization augmented end-to-end planning,” in The Fourteenth International Conference on Learning Representations,
-
[5]
Available: https://openreview.net/forum?id=a9bOgeqbdB
[Online]. Available: https://openreview.net/forum?id=a9bOgeqbdB
-
[6]
Chatscene: Knowledge-enabled safety- critical scenario generation for autonomous vehicles,
J. Zhang, C. Xu, and B. Li, “Chatscene: Knowledge-enabled safety- critical scenario generation for autonomous vehicles,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 15 459–15 469
2024
-
[7]
Llm-attacker: Enhancing closed- loop adversarial scenario generation for autonomous driving with large language models,
Y . Mei, T. Nie, J. Sun, and Y . Tian, “Llm-attacker: Enhancing closed- loop adversarial scenario generation for autonomous driving with large language models,”IEEE Transactions on Intelligent Transportation Systems, 2025
2025
-
[8]
M. Peng, Y . Xie, X. Guo, R. Yao, H. Yang, and J. Ma, “Ld-scene: Llm-guided diffusion for controllable generation of adversarial safety-critical driving scenarios,” 2025. [Online]. Available: https://arxiv.org/abs/2505.11247
arXiv 2025
-
[9]
Breach, a toolbox for verification and parameter synthesis of hybrid systems,
A. Donzé, “Breach, a toolbox for verification and parameter synthesis of hybrid systems,” inComputer Aided Verification, T. Touili, B. Cook, and P. Jackson, Eds. Berlin, Heidelberg: Springer Berlin Heidelberg, 2010, pp. 167–170
2010
-
[10]
S-taliro: A tool for temporal logic falsification for hybrid systems,
Y . Annpureddy, C. Liu, G. Fainekos, and S. Sankaranarayanan, “S-taliro: A tool for temporal logic falsification for hybrid systems,” inTools and Algorithms for the Construction and Analysis of Systems, P. A. Abdulla and K. R. M. Leino, Eds. Berlin, Heidelberg: Springer Berlin Heidelberg, 2011, pp. 254–257
2011
-
[11]
Formal scenario-based testing of autonomous vehicles: From simulation to the real world,
D. J. Fremont, E. Kim, Y . V . Pant, S. A. Seshia, A. Acharya, X. Bruso, P. Wells, S. Lemke, Q. Lu, and S. Mehta, “Formal scenario-based testing of autonomous vehicles: From simulation to the real world,” in2020 IEEE 23rd International Conference on Intelligent Transportation Systems (ITSC). IEEE, 2020, pp. 1–8
2020
-
[12]
Adaptive stress testing for autonomous vehicles,
M. Koren, S. Alsaif, R. Lee, and M. J. Kochenderfer, “Adaptive stress testing for autonomous vehicles,” in2018 IEEE Intelligent Vehicles Symposium (IV). IEEE, 2018, pp. 1–7
2018
-
[13]
A novel framework for adaptive stress testing of autonomous vehicles in multi-lane roads,
L. Trinh, Q.-H. Luu, T. M. Nguyen, and H. L. Vu, “A novel framework for adaptive stress testing of autonomous vehicles in multi-lane roads,”
-
[14]
Available: https://arxiv.org/abs/2402.11813
[Online]. Available: https://arxiv.org/abs/2402.11813
-
[15]
Critical concrete scenario generation using scenario-based falsification,
D. Karunakaran, J. S. Berrio, S. Worrall, and E. Nebot, “Critical concrete scenario generation using scenario-based falsification,” in2022 IEEE International Conference on Recent Advances in Systems Science and Engineering (RASSE). IEEE, 2022, pp. 1–8
2022
-
[16]
Test scenario generation for autonomous driving systems with reinforcement learning,
C. Lu, “Test scenario generation for autonomous driving systems with reinforcement learning,” in2023 IEEE/ACM 45th International Conference on Software Engineering: Companion Proceedings (ICSE- Companion), 2023, pp. 317–319
2023
-
[17]
Trafficgen: Learning to generate diverse and realistic traffic scenarios,
L. Feng, Q. Li, Z. Peng, S. Tan, and B. Zhou, “Trafficgen: Learning to generate diverse and realistic traffic scenarios,” in2023 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2023, pp. 3567–3575
2023
-
[18]
Scenediffuser++: City-scale traffic simulation via a generative world model,
S. Tan, J. Lambert, H. Jeon, S. Kulshrestha, Y . Bai, J. Luo, D. Anguelov, M. Tan, and C. M. Jiang, “Scenediffuser++: City-scale traffic simulation via a generative world model,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 1570–1580
2025
-
[19]
S. Tang, Z. Zhang, J. Zhou, L. Lei, Y . Zhou, and Y . Xue, “Legend: A top-down approach to scenario generation of autonomous driving systems IEEE TRANSACTIONS ON INTELLIGENT TRANSPORTATION SYSTEM 13 TABLE III: Case study corresponding to the wrong-way collision sequence shown in Fig. 4a and the corrected behavior shown in Fig. 5a. The table summarizes how...
2024
-
[20]
Generating out-of-distribution scenarios using language models,
E. Aasi, P. Nguyen, S. Sreeram, G. Rosman, S. Karaman, and D. Rus, “Generating out-of-distribution scenarios using language models,” in2025 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2025, pp. 10 616–10 623
2025
-
[21]
Txt2sce: Scenario generation for autonomous driving system testing based on textual reports,
P. Ji, Y . Feng, Z. Li, X. Zhou, J. Liu, J. Sun, and Z. Zhao, “Txt2sce: Scenario generation for autonomous driving system testing based on textual reports,” 2025. [Online]. Available: https: //arxiv.org/abs/2509.02150
arXiv 2025
-
[22]
Arise – adaptive refinement and iterative scenario engineering,
K. Poddubnyy, I. V ozniak, I. Burmistrov, N. Lipp, D. Hovhannisyan, C. Mueller, and P. Slusallek, “Arise – adaptive refinement and iterative scenario engineering,” 2026. [Online]. Available: https: //arxiv.org/abs/2601.14743
arXiv 2026
-
[23]
Craft: Concept recursive activation factorization for explainability,
T. Fel, A. Picard, L. Bethune, T. Boissin, D. Vigouroux, J. Colin, R. Cadénc, and T. Serre, “Craft: Concept recursive activation factorization for explainability,” in2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2023, pp. 2711–2721
2023
-
[24]
Bench2drive: Towards multi- ability benchmarking of closed-loop end-to-end autonomous driving,
X. Jia, Z. Yang, Q. Li, Z. Zhang, and J. Yan, “Bench2drive: Towards multi- ability benchmarking of closed-loop end-to-end autonomous driving,” Advances in Neural Information Processing Systems, vol. 37, pp. 819–844, 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.