Learning to Refine Hidden States for Reliable LLM Reasoning
Pith reviewed 2026-06-29 01:43 UTC · model grok-4.3
The pith
ReLAR uses reinforcement learning to refine LLM hidden states for more stable reasoning without explicit chain-of-thought.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
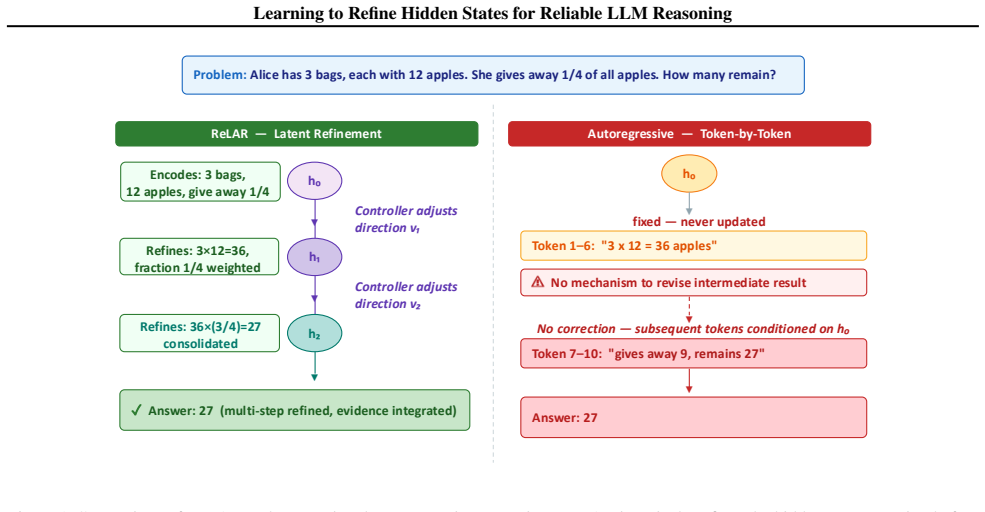
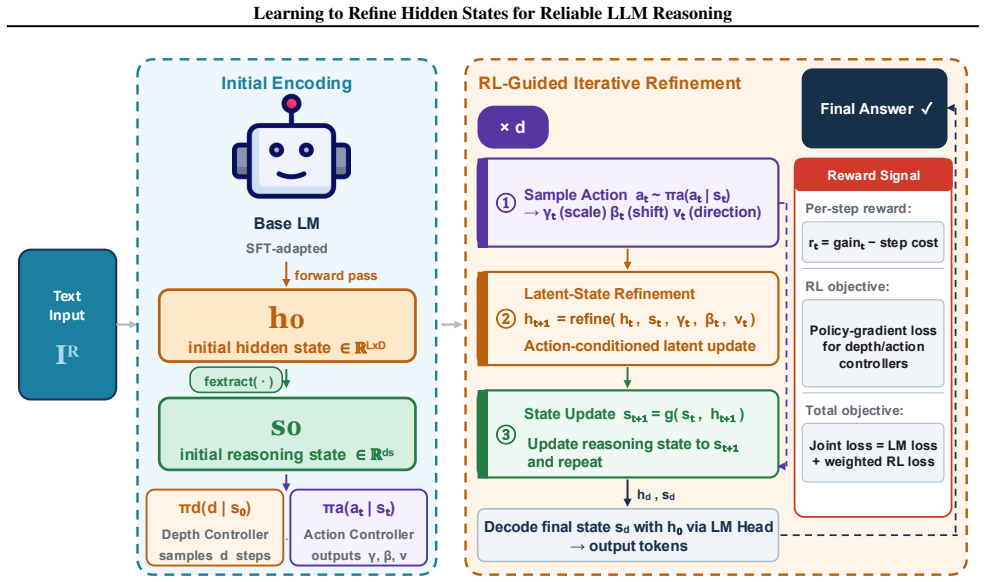
ReLAR maintains a compact latent reasoning state and uses learned depth and action controllers to adaptively determine both the number and direction of refinement steps. The controllers are trained with a policy gradient objective based on step-wise likelihood improvement, enabling efficient input-dependent reasoning without explicit chain-of-thought generation.
What carries the argument
Reinforcement-guided latent refinement with depth and action controllers that update hidden representations before decoding.
If this is right
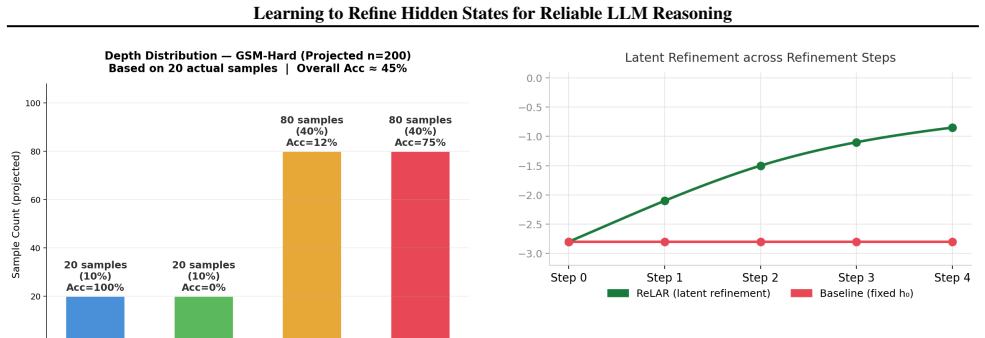
- Experiments show improved accuracy on medical, mathematical, multi-hop reasoning, and open-ended generation benchmarks.
- Reasoning stability increases compared to standard LLM decoding.
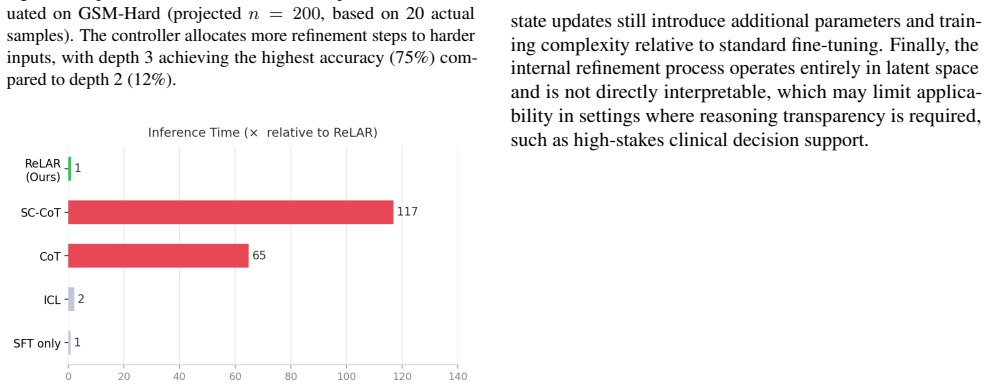
- Inference overhead is substantially lower than explicit reasoning baselines like chain-of-thought.
- Generation quality improves without the need for explicit supervision on step quality.
Where Pith is reading between the lines
- The method could be tested on tasks with even longer reasoning chains where error propagation is more severe.
- It may reduce the need for large context windows in some applications by handling refinements internally.
- Similar controllers might be applied to other generative models to stabilize outputs.
Load-bearing premise
The policy gradient objective based on step-wise likelihood improvement will produce controllers that yield better final reasoning outcomes without explicit supervision on reasoning correctness or step quality.
What would settle it
A controlled experiment where ReLAR is applied to a multi-step math benchmark and shows no improvement in final answer accuracy over a standard LLM baseline despite the added refinement steps.
Figures

read the original abstract
Large language models show strong reasoning ability, but their internal reasoning process can remain unstable in complex multi-step settings, where early hidden-state errors may propagate to incorrect predictions. We propose ReLAR, a reinforcement-guided latent refinement framework that iteratively updates hidden representations before decoding. ReLAR maintains a compact latent reasoning state and uses learned depth and action controllers to adaptively determine both the number and direction of refinement steps. The controllers are trained with a policy gradient objective based on step-wise likelihood improvement, enabling efficient input-dependent reasoning without explicit chain-of-thought generation. Experiments on medical, mathematical, multi-hop reasoning, and open-ended generation benchmarks show that ReLAR improves accuracy, generation quality, and reasoning stability with substantially lower inference overhead than explicit reasoning baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ReLAR, a reinforcement-guided latent refinement framework for LLMs. It maintains a compact latent reasoning state and uses learned depth and action controllers, trained via policy gradient on step-wise likelihood improvement, to adaptively refine hidden representations before decoding. This is claimed to yield better accuracy, generation quality, and reasoning stability than explicit reasoning baselines, with lower inference overhead, across medical, mathematical, multi-hop, and open-ended generation benchmarks.
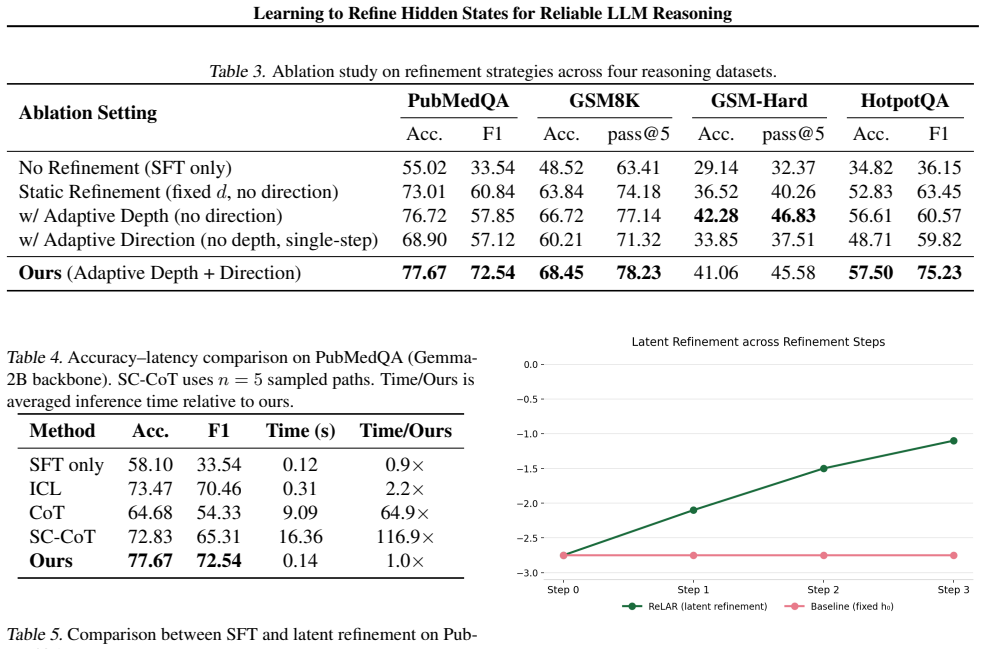
Significance. If the surrogate reward reliably produces controllers that improve final outputs, the method could provide an efficient latent-space alternative to chain-of-thought prompting. The approach is notable for avoiding explicit CoT generation while claiming input-dependent reasoning depth. However, the central result hinges on whether step-wise likelihood gains translate to benchmark improvements without explicit supervision on reasoning quality.
major comments (2)
- [Abstract] Abstract (training objective description): The policy gradient reward is defined solely on step-wise likelihood improvement with no explicit term for final answer correctness or step quality. For the central claim to hold, this surrogate must produce controllers whose refinements increase benchmark accuracy; likelihood sharpening on incorrect paths remains possible without additional constraints or ablations demonstrating alignment.
- [Experiments] Experiments (benchmark results): The abstract states that ReLAR improves accuracy and stability, but provides no details on statistical tests, variance across runs, or ablations isolating the effect of the likelihood-based reward versus other design choices. This makes it impossible to verify whether reported gains are attributable to the refinement mechanism or to confounding factors.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We respond to each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract (training objective description): The policy gradient reward is defined solely on step-wise likelihood improvement with no explicit term for final answer correctness or step quality. For the central claim to hold, this surrogate must produce controllers whose refinements increase benchmark accuracy; likelihood sharpening on incorrect paths remains possible without additional constraints or ablations demonstrating alignment.
Authors: The reward is defined on step-wise likelihood improvement to train the controllers without explicit reasoning supervision or final-answer labels. The manuscript reports that this yields benchmark gains, but we acknowledge the absence of ablations testing alignment against variants that add explicit correctness terms. We will add such ablations in the revision to demonstrate that the surrogate does not favor incorrect paths. revision: yes
-
Referee: [Experiments] Experiments (benchmark results): The abstract states that ReLAR improves accuracy and stability, but provides no details on statistical tests, variance across runs, or ablations isolating the effect of the likelihood-based reward versus other design choices. This makes it impossible to verify whether reported gains are attributable to the refinement mechanism or to confounding factors.
Authors: The current manuscript does not report run-to-run variance, statistical tests, or reward-specific ablations. We will revise the experiments section to include standard deviations across seeds, appropriate significance tests, and ablations that isolate the policy-gradient reward from other design elements. revision: yes
Circularity Check
No circularity identified in derivation chain
full rationale
The provided abstract and description outline a reinforcement-guided latent refinement framework whose controllers are trained via a standard policy-gradient objective on step-wise likelihood improvement. No equations, derivations, self-citations, or fitted quantities are shown that reduce any claimed prediction or result to its inputs by construction. Experimental improvements on benchmarks are presented as empirical outcomes rather than closed-form equivalences, rendering the approach self-contained against external validation.
Axiom & Free-Parameter Ledger
free parameters (2)
- depth controller parameters
- action controller parameters
axioms (1)
- domain assumption Step-wise likelihood improvement is a reliable proxy for improved final reasoning correctness
invented entities (1)
-
compact latent reasoning state
no independent evidence
Reference graph
Works this paper leans on
-
[1]
doi: 10.1016/j. xdss.2025.100123. Christophe, C., Kanithi, P. K., Munjal, P., Raha, T., Hayat, N., Rajan, R., Al-Mahrooqi, A., Gupta, A., Salman, M. U., Gosal, G., et al. Med42–evaluating fine-tuning strategies for medical llms: full-parameter vs. parameter- efficient approaches.arXiv preprint arXiv:2404.14779,
work page doi:10.1016/j 2025
-
[2]
Training Verifiers to Solve Math Word Problems
Cobbe, K., Kosaraju, V ., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Y ., Zhou, W., Shen, M., Zhou, P., Bhagavatula, C., Choi, Y ., and Ren, X
Lin, B. Y ., Zhou, W., Shen, M., Zhou, P., Bhagavatula, C., Choi, Y ., and Ren, X. Commongen: A constrained text generation challenge for generative commonsense reason- ing. InFindings of the Association for Computational Linguistics: EMNLP 2020, pp. 1823–1840,
2020
-
[4]
Lucas, M. M. et al. Reasoning with large language models for medical question answering.Journal of the American Medical Informatics Association, 31(9):1964–1976,
1964
-
[5]
doi: 10.1093/jamia/ocae102. Lyu, Q., Stein, A., et al. Faithful chain-of-thought reasoning. InIJCNLP-AACL,
-
[6]
Reasoning with latent thoughts: On the power of looped transformers
Saunshi, N., Dikkala, N., Li, Z., Kumar, S., and J Reddi, S. Reasoning with latent thoughts: On the power of looped transformers. InInternational Conference on Learning Representations, volume 2025, pp. 14855–14881,
2025
-
[7]
Sellergren, A., Kazemzadeh, S., Jaroensri, T., Kiraly, A., Traverse, M., Kohlberger, T., Xu, S., Jamil, F., Hughes, C., Lau, C., et al. Medgemma technical report.arXiv preprint arXiv:2507.05201,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Improving instruction-following in language models through activation steering
Stolfo, A., Balachandran, V ., Yousefi, S., Horvitz, E., and Nushi, B. Improving instruction-following in language models through activation steering. InInternational Con- ference on Learning Representations, volume 2025, pp. 55790–55823,
2025
-
[9]
J., Nori, H., Hwang, T
10 Learning to Refine Hidden States for Reliable LLM Reasoning Thirunavukarasu, A. J., Nori, H., Hwang, T. J., et al. Large language models in medicine.Nature Medicine, 29:1939– 1951,
1939
-
[10]
Steering Language Models With Activation Engineering
Turner, A. M., Thiergart, L., Leech, G., Udell, D., Vazquez, J. J., Mini, U., and MacDiarmid, M. Steering lan- guage models with activation engineering.arXiv preprint arXiv:2308.10248,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Semantics-adaptive acti- vation intervention for llms via dynamic steering vectors
Wang, W., Yang, J., and Peng, W. Semantics-adaptive acti- vation intervention for llms via dynamic steering vectors. InInternational Conference on Learning Representations, volume 2025, pp. 79334–79351,
2025
-
[12]
Yang, Z., Qi, P., Zhang, S., Bengio, Y ., Cohen, W., Salakhut- dinov, R., and Manning, C. D. Hotpotqa: A dataset for diverse, explainable multi-hop question answering. In Proceedings of the 2018 Conference on Empirical Meth- ods in Natural Language Processing, pp. 2369–2380,
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.