Physics-Constrained Neural Networks for Improved Short-Term Weather Forecasting: A Case Study over the South Pacific
Pith reviewed 2026-06-27 01:42 UTC · model grok-4.3
The pith
Three upgrades to physics-constrained neural networks reduce 1-12 hour forecast errors by 8-22 percent while keeping physical consistency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
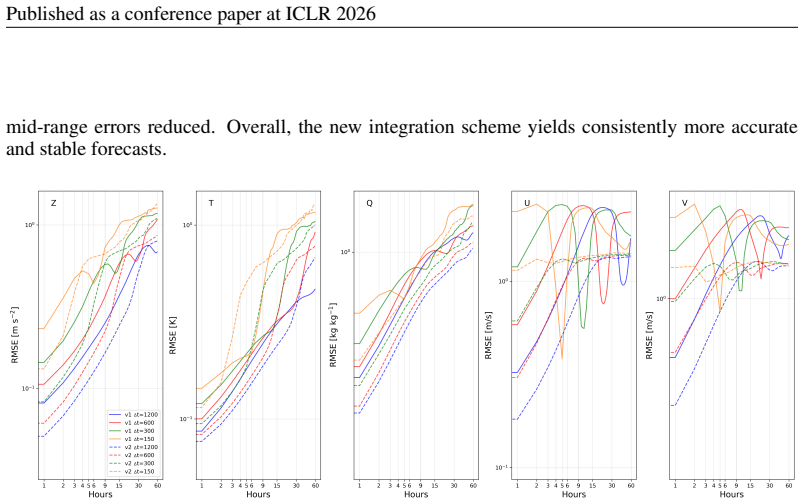
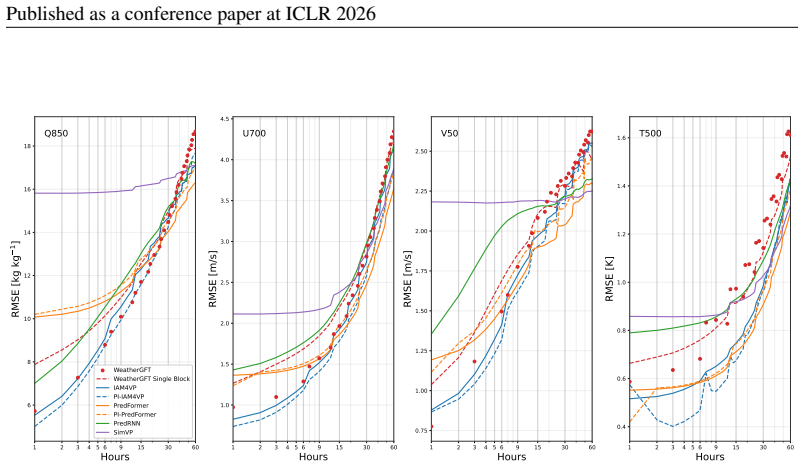
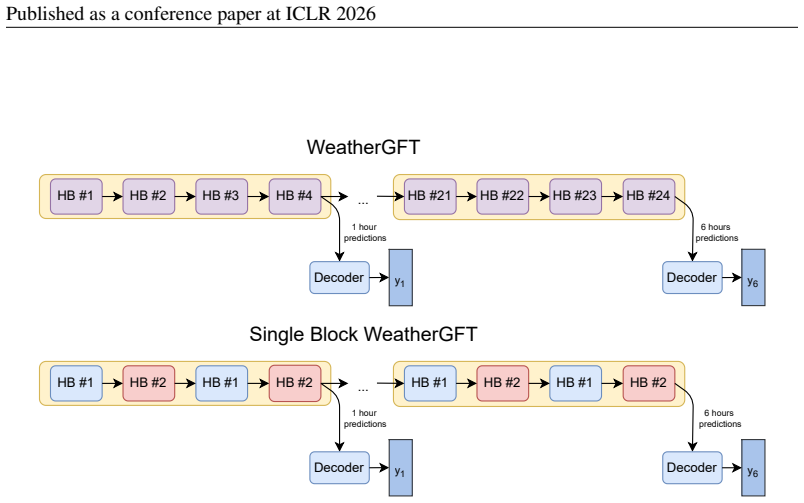
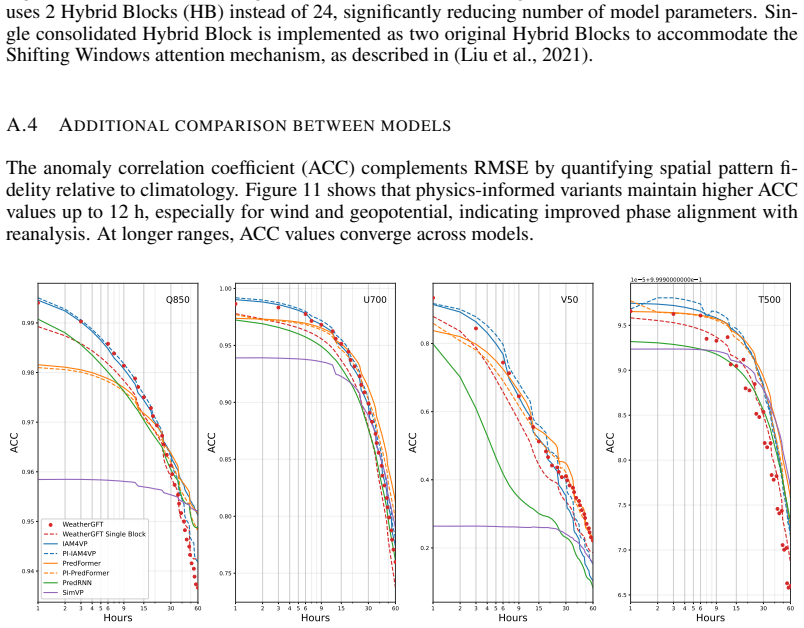
The three innovations—an upgraded fifth-order WENO solver with beta-plane approximation and subgrid viscosity that supports a 1200-second time step, replacement of the original chain of 24 modules by one unified autoregressive hybrid block, and integration of the physical core with PredFormer and IAM4VP backbones—yield hybrid models whose root-mean-squared error at 1-12 hour lead times is 8-22 percent lower than that of the corresponding pure neural models while better preserving physical consistency.
What carries the argument
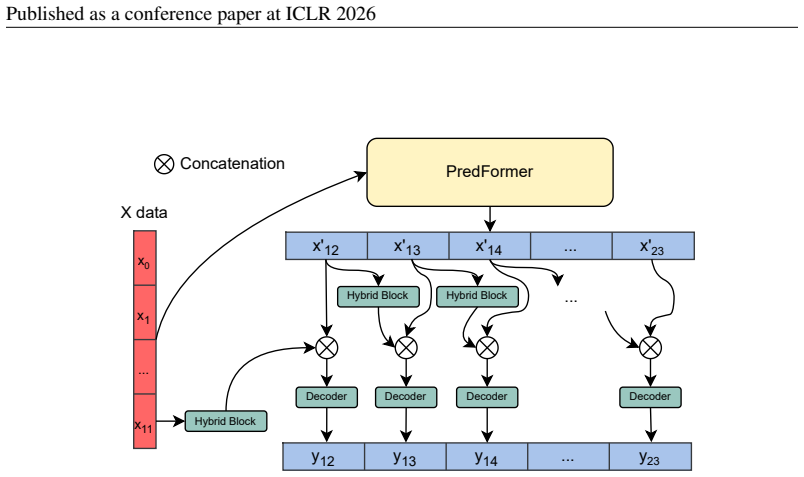
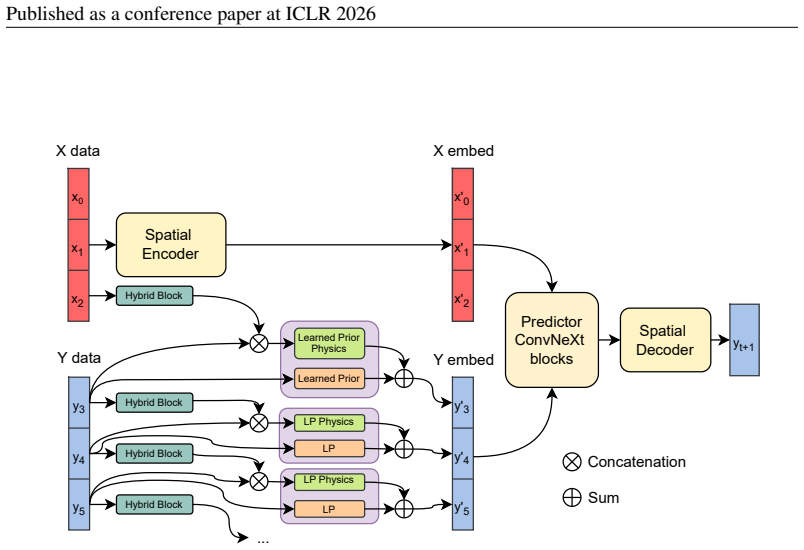
The WeatherGFT-derived hybrid architecture whose numerical solver, autoregressive block, and neural backbone are each upgraded to allow larger steps and remove lead-time specialization.
If this is right
- The fourfold increase in allowable time step lowers computational cost for the same forecast horizon.
- Replacing 24 specialized modules with one unified block removes overfitting to particular lead times.
- The resulting hybrids maintain physical consistency better than the pure neural baselines at short ranges.
- Incremental refinement of hybrid components is presented as a practical path to more accurate short-range forecasting.
Where Pith is reading between the lines
- The same solver and block upgrades could be tested on global rather than regional domains to check whether the error reductions generalize.
- Extending the unified autoregressive block to multi-day leads might reveal whether the overfitting problem reappears at longer horizons.
- Pairing the physical core with still newer neural architectures could be compared directly against the two chosen backbones to isolate the contribution of each backbone.
- If the physical-consistency advantage holds under distribution shift, the hybrids might serve as more trustworthy emulators inside larger ensemble systems.
Load-bearing premise
Performance gains on the 2000-2004 WeatherBench South Pacific subset are caused by the three listed changes rather than by dataset-specific tuning or unstated differences in the baseline implementations.
What would settle it
Retraining the same upgraded hybrids on a held-out later period or different geographic domain and measuring whether the 8-22 percent RMSE reduction and physical-consistency advantage both disappear.
Figures


read the original abstract
This study introduces enhancements to physics-constrained neural networks (PCNNs) that improve the accuracy and stability of hybrid short-term weather forecasting models. Building on the WeatherGFT architecture, three innovations are proposed. First, an upgraded numerical solver, combining a fifth-order weighted essentially non-oscillatory scheme (WENO-5), a beta-plane approximation, and subgrid-scale viscosity, permits a fourfold increase in the integration time step to 1200 s while reducing the daily mean squared error by up to 26%. Second, a unified autoregressive hybrid block replaces the original chain of 24 specialised modules, eliminating overfitting to specific lead times. Third, the physical core is integrated with two state-of-the-art neural backbones, resulting in PI-PredFormer and PI-IAM4VP. Evaluation on the WeatherBench South Pacific subset from 2000 to 2004 shows that these hybrids reduce root mean squared error at 1-12 h lead times by 8-22% compared to purely neural counterparts, while better preserving physical consistency. These results demonstrate that incremental refinement of hybrid components offers a practical route toward more accurate and efficient short-range weather forecasting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes three enhancements to physics-constrained neural networks based on the WeatherGFT architecture for short-term weather forecasting: (1) an upgraded numerical solver combining WENO-5, beta-plane approximation, and subgrid-scale viscosity that allows a 1200 s timestep and reduces daily MSE by up to 26%; (2) a unified autoregressive hybrid block replacing a chain of 24 specialized modules; and (3) integration of the physical core with PredFormer and IAM4VP to produce PI-PredFormer and PI-IAM4VP. On the WeatherBench South Pacific subset (2000-2004), the hybrids are reported to reduce RMSE by 8-22% at 1-12 h lead times relative to purely neural counterparts while improving physical consistency.
Significance. If the reported RMSE reductions prove robustly attributable to the three listed innovations under controlled conditions, the work would provide concrete evidence that targeted upgrades to the numerical solver and autoregressive structure can improve both accuracy and stability in hybrid weather models. Such incremental refinements address a practical bottleneck in short-range forecasting and could inform similar physics-ML integrations in other domains.
major comments (3)
- [Abstract] Abstract: the central claim of 8-22% RMSE reduction at 1-12 h lead times is presented without error bars, statistical significance tests, or any description of baseline training protocols (e.g., hyperparameter search budget, random seeds, or data exclusion rules), so it is impossible to verify that the gains are caused by the three innovations rather than implementation differences.
- [Evaluation] Evaluation description: the study is confined to a single 5-year regional subset with no ablation experiments isolating the contribution of the WENO-5 solver, the unified autoregressive block, or the specific backbone integrations, leaving the attribution of performance gains to the proposed changes untested.
- [Methods] Methods (solver upgrade): while the abstract states that the new solver permits a fourfold timestep increase and up to 26% daily MSE reduction, no quantitative comparison is supplied showing that these solver changes, rather than downstream neural components, drive the reported 1-12 h RMSE improvements.
minor comments (1)
- [Abstract] The abstract refers to 'daily mean squared error' and 'root mean squared error' without clarifying whether these are computed on the same fields or normalized identically across comparisons.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which identify key areas where additional rigor is needed to strengthen the attribution of results. We address each major comment below and will incorporate the suggested changes in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of 8-22% RMSE reduction at 1-12 h lead times is presented without error bars, statistical significance tests, or any description of baseline training protocols (e.g., hyperparameter search budget, random seeds, or data exclusion rules), so it is impossible to verify that the gains are caused by the three innovations rather than implementation differences.
Authors: We agree that the abstract and main text should provide more information to support the robustness of the reported gains. In the revised manuscript we will add error bars to all RMSE results, include statistical significance tests for the 8-22% reductions, and expand the methods section with a full description of baseline training protocols, including hyperparameter search budget, random seeds, and data exclusion rules. revision: yes
-
Referee: [Evaluation] Evaluation description: the study is confined to a single 5-year regional subset with no ablation experiments isolating the contribution of the WENO-5 solver, the unified autoregressive block, or the specific backbone integrations, leaving the attribution of performance gains to the proposed changes untested.
Authors: We acknowledge that the current evaluation does not include explicit ablation studies isolating each component. In the revised manuscript we will add ablation experiments that separately evaluate the WENO-5 solver upgrade, the unified autoregressive block, and each backbone integration to provide clearer attribution of the observed improvements. revision: yes
-
Referee: [Methods] Methods (solver upgrade): while the abstract states that the new solver permits a fourfold timestep increase and up to 26% daily MSE reduction, no quantitative comparison is supplied showing that these solver changes, rather than downstream neural components, drive the reported 1-12 h RMSE improvements.
Authors: We will revise the methods and results sections to include direct quantitative comparisons of the upgraded solver versus the original solver within otherwise identical hybrid configurations. These comparisons will isolate the solver's contribution to the 1-12 h RMSE reductions. revision: yes
Circularity Check
No significant circularity; empirical claims rest on held-out evaluation
full rationale
The paper reports RMSE reductions from three explicit architectural changes (WENO-5 solver upgrade, unified autoregressive block, and PI-PredFormer/PI-IAM4VP integration) measured on a fixed held-out 2000-2004 WeatherBench South Pacific test subset. These performance numbers are not defined in terms of the fitted parameters themselves, nor do any equations reduce the claimed gains to quantities that were inputs to the fit. The evaluation protocol separates training from testing, and no self-citation chain or uniqueness theorem is invoked to justify the core results. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The beta-plane approximation remains adequate for the South Pacific domain at the chosen resolution and time step.
Reference graph
Works this paper leans on
-
[1]
ISSN 1477-870X. doi: 10.1002/qj.4755. URLhttp://dx.doi.org/10.1002/ qj.4755. Yan Han, Lihua Mi, Lian Shen, C.S. Cai, Yuchen Liu, Kai Li, and Guoji Xu. A short-term wind speed prediction method utilizing novel hybrid deep learning algorithms to correct nu- merical weather forecasting.Applied Energy, 312:118777, April
-
[2]
doi: 10.1016/j.apenergy.2022.118777
ISSN 0306-2619. doi: 10.1016/j.apenergy.2022.118777. URLhttp://dx.doi.org/10.1016/j.apenergy. 2022.118777. Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV),
-
[3]
and Scher, Sebastian and Weyn, Jonathan A
ISSN 1942-2466. doi: 10.1029/2020ms002203. URLhttp://dx.doi.org/10.1029/2020MS002203. Minseok Seo, Hakjin Lee, Doyi Kim, and Junghoon Seo. Implicit stacked autoregressive model for video prediction,
-
[4]
URLhttps://arxiv.org/abs/2303.07849. Ben Stevens and Tim Colonius. Enhancement of shock-capturing methods via machine learn- ing.Theoretical and Computational Fluid Dynamics, 34(4):483–496, May
-
[5]
doi: 10.1007/s00162-020-00531-1
ISSN 1432-2250. doi: 10.1007/s00162-020-00531-1. URLhttp://dx.doi.org/10.1007/ s00162-020-00531-1. Yujin Tang, Lu Qi, Fei Xie, Xiangtai Li, Chao Ma, and Ming-Hsuan Yang. Predformer: Trans- formers are effective spatial-temporal predictive learners,
-
[6]
URLhttps://arxiv.org/ abs/2410.04733. 10 Published as a conference paper at ICLR 2026 Kianusch Vahid Yousefnia, Tobias B¨olle, Isabella Z ¨obisch, and Thomas Gerz. A machine-learning approach to thunderstorm forecasting through post-processing of simulation data.Quarterly Jour- nal of the Royal Meteorological Society, 150(763):3495–3510, June
arXiv 2026
-
[7]
ISSN 1477-870X. doi: 10.1002/qj.4777. URLhttp://dx.doi.org/10.1002/qj.4777. Fr´ed´eric Vitart and Yuhei Takaya. Lagged ensembles in sub-seasonal predictions.Quarterly Journal of the Royal Meteorological Society, 147(739):3227–3242, July
-
[8]
ISSN 1477-870X. doi: 10.1002/qj.4125. URLhttp://dx.doi.org/10.1002/qj.4125. Yunbo Wang, Mingsheng Long, Jianmin Wang, Zhifeng Gao, and Philip S. Yu. Predrnn: recurrent neural networks for predictive learning using spatiotemporal lstms. InProceedings of the 31st International Conference on Neural Information Processing Systems, NIPS’17, pp. 879–888, Red Ho...
-
[9]
Wanghan Xu, Fenghua Ling, Wenlong Zhang, Tao Han, Hao Chen, Wanli Ouyang, and Lei Bai
URLhttps://arxiv.org/abs/2301.00808. Wanghan Xu, Fenghua Ling, Wenlong Zhang, Tao Han, Hao Chen, Wanli Ouyang, and Lei Bai. Generalizing weather forecast to fine-grained temporal scales via physics-ai hybrid modeling,
-
[10]
URLhttps://arxiv.org/abs/2405.13796. G¨unther Z¨angl. Adaptive tuning of uncertain parameters in a numerical weather prediction model based upon data assimilation.Quarterly Journal of the Royal Meteorological Society, 149(756): 2861–2880, August
-
[11]
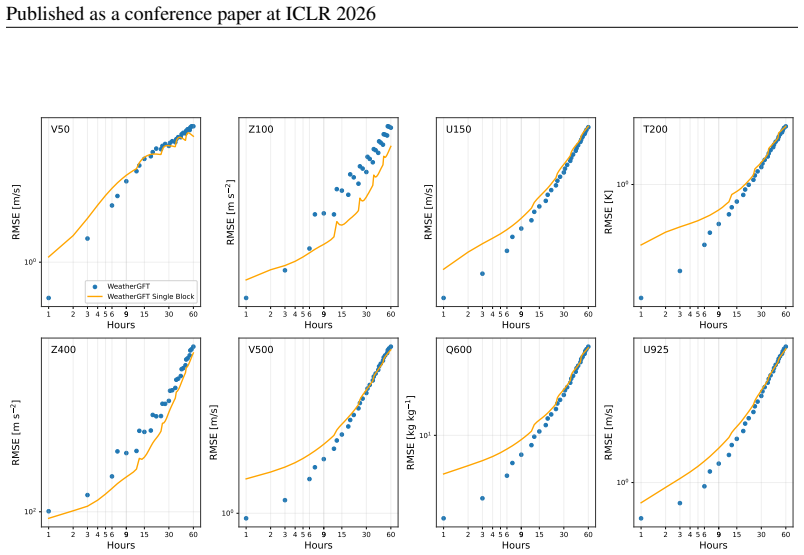
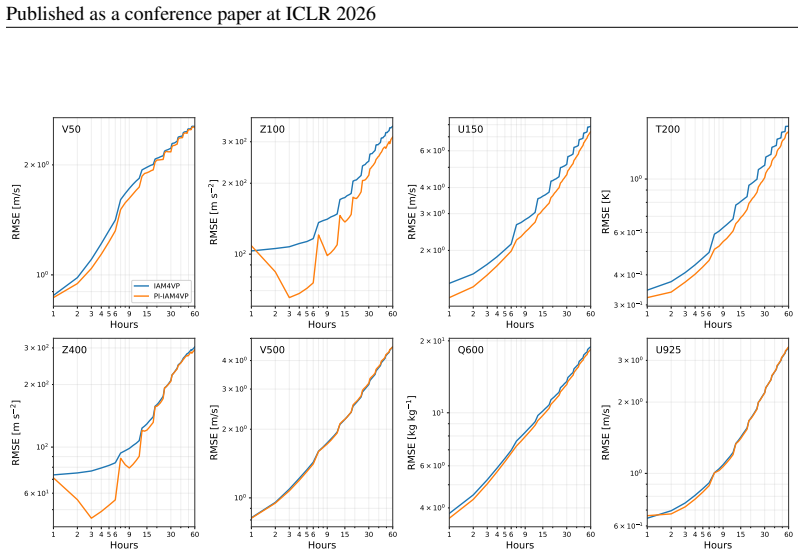
ISSN 1477-870X. doi: 10.1002/qj.4535. URLhttp://dx.doi. org/10.1002/qj.4535. A APPENDIX A.1 COMPARISONS BETWEEN NEW ARCHITECTURES AND ITS ORIGINAL VARIANTS 1 2 3 4 5 6 9 15 30 60 Hours 1.2 × 100 1.4 × 100 1.6 × 100 1.8 × 100 2 × 100 2.2 × 100 2.4 × 100 RMSE [m/s] V50 PredFormer PI-PredFormer 1 2 3 4 5 6 9 15 30 60 Hours 102 6 × 101 2 × 102 3 × 102 RMSE [m...
-
[12]
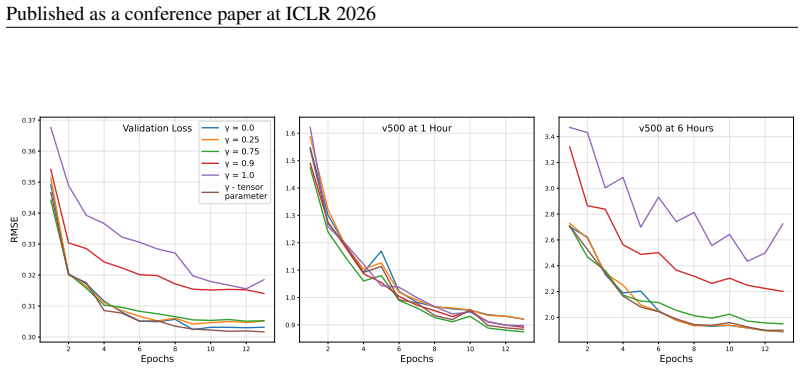
12 Published as a conference paper at ICLR 2026 2 4 6 8 10 12 Epochs 0.30 0.31 0.32 0.33 0.34 0.35 0.36 0.37RMSE Validation Loss = 0.0 = 0.25 = 0.75 = 0.9 = 1.0 - tensor parameter 2 4 6 8 10 12 Epochs 0.9 1.0 1.1 1.2 1.3 1.4 1.5 1.6 v500 at 1 Hour 2 4 6 8 10 12 Epochs 2.0 2.2 2.4 2.6 2.8 3.0 3.2 3.4 v500 at 6 Hours Figure 8: Effect of varying the weight o...
2026
-
[13]
All neural components are trained using the AdamW optimizer with cosine annealing learning-rate schedule
is a recurrent architecture with spatiotemporal memory, widely used as a benchmark in neural weather forecasting. All neural components are trained using the AdamW optimizer with cosine annealing learning-rate schedule. The initial learning rate is set to10 −4 for PredFormer-based models and5·10 −4 for the other architectures. Batch size is 2 for PredForm...
2026
-
[14]
These visual diagnostics confirm that hybrid approaches achieve a favorable balance between physical fidelity and adaptability to data
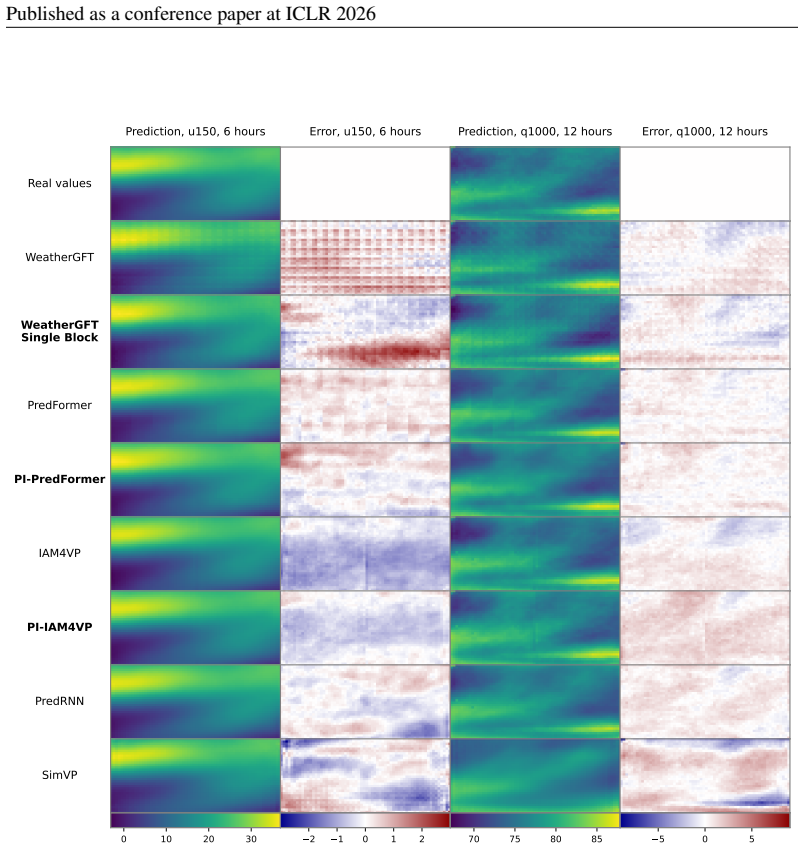
5M CNN baseline MIMO Lightweight fully convo- lutional model show grid artifacts or excessive smoothing. These visual diagnostics confirm that hybrid approaches achieve a favorable balance between physical fidelity and adaptability to data. At longer horizons (24–60 h), purely data-driven models—especially PredFormer—outperform their hybrid counterparts a...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.