A Neuromorphic Trigger for Efficient Audio Event Detection
Pith reviewed 2026-06-26 23:15 UTC · model grok-4.3
The pith
A lightweight spiking neural network can gate audio streams to cut downstream computation by 42 times while improving detection bounds.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
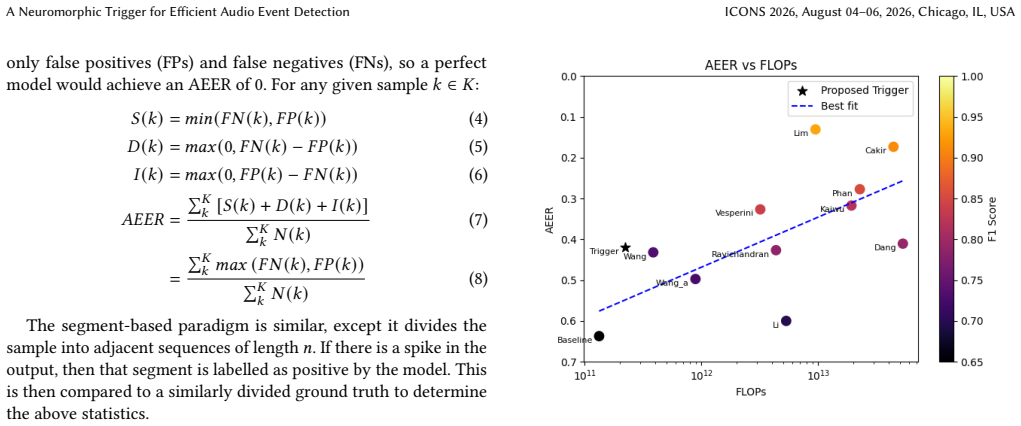
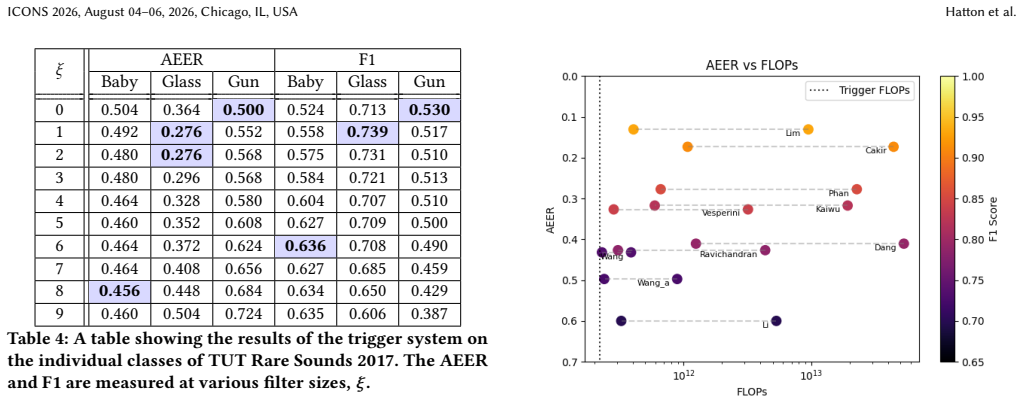
A neuromorphic trigger implemented as a lightweight fully connected spiking neural network with close-open post-processing identifies salient audio segments and gates them to downstream models. On class-agnostic URBAN-SED it reaches a one-second segment F1 of 0.97 for anomalous sound detection. When combined with the Dang classifier on DCASE 2017 Task 2 it yields a potential 42.6 times reduction in FLOPs and lowers the lower bound on event-based error rate from 0.41 to 0.25.
What carries the argument
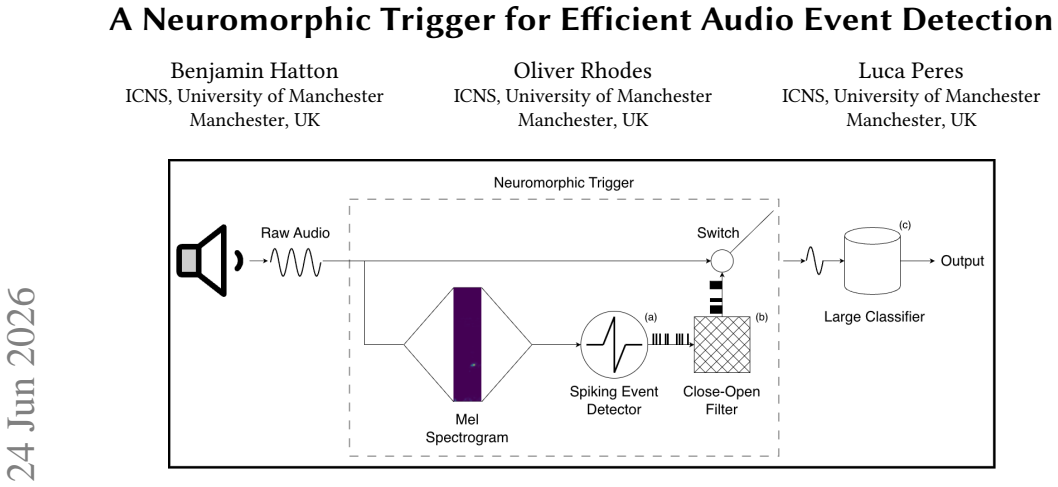
lightweight fully connected spiking neural network (SNN) with close-open filter post-processing that selectively gates input segments to a heavier downstream model
If this is right
- The trigger can be inserted as a low-cost front-end before any computationally heavy audio classifier.
- On the DCASE 2017 Task 2 benchmark the combination lowers the event-error lower bound while cutting FLOPs by a factor of 42.6.
- The same architecture delivers 0.97 segment-based F1 on class-agnostic URBAN-SED for anomalous sound detection.
- Selective gating makes real-time, resource-constrained audio event detection practical by processing only the identified salient segments.
Where Pith is reading between the lines
- If the trigger generalizes, similar front-ends could be applied to other continuous sensor streams such as vibration or environmental monitoring.
- The approach opens the possibility of running multiple specialized classifiers only on demand rather than in parallel.
- Energy measurements on actual neuromorphic hardware would be needed to confirm that the FLOP reduction produces proportional power savings.
Load-bearing premise
The SNN trigger will catch nearly all relevant audio events across varied real-world conditions without missing too many, so that the reported FLOP savings translate into actual system-level gains rather than being offset by undetected events.
What would settle it
A deployment test on continuous noisy audio in which the fraction of missed events causes the combined system's overall error rate to exceed the error rate of the downstream classifier running without any trigger.
Figures


read the original abstract
Efficient processing of continuous audio streams remains a key challenge for real-time and resource-constrained systems. This paper introduces a neuromorphic trigger for audio event detection, based on a spiking neural network (SNN) that selectively gates input to downstream models. The proposed neuromorphic trigger acts as a flexible low-cost front-end, identifying salient audio segments and enabling these to be processed by a more computationally intensive model for tasks such as classification. The trigger is implemented as a lightweight fully connected SNN using a close-open filter for postprocessing, and is evaluated on two representative tasks: Anomalous Sound Detection (ASD) and Sound Event Detection (SED). For ASD, the trigger achieves a one-second segment-based F1 score of 0.97 on a class-agnostic form of the URBAN-SED dataset, demonstrating high reliability in identifying relevant audio regions. For SED, the trigger is combined with the Dang classifier on the DCASE 2017 Challenge Task 2 dataset, showing a potential $42.6\times$ reduction in FLOPs while reducing the lower bound of the event-based error rate from 0.41 to 0.25. These results highlight the potential of neuromorphic triggers as real-time, energy-efficient front-end filters, enabling substantial reductions in computational cost.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a neuromorphic trigger implemented as a lightweight fully connected spiking neural network (SNN) with a close-open filter postprocessor. This acts as a low-cost front-end to identify salient audio segments and gate them to downstream models for anomalous sound detection (ASD) and sound event detection (SED). On a class-agnostic URBAN-SED dataset the trigger reports a one-second segment-based F1 of 0.97; when paired with the Dang classifier on DCASE 2017 Task 2 it claims a 42.6× FLOPs reduction while lowering the event-based error-rate lower bound from 0.41 to 0.25.
Significance. If the empirical claims are substantiated with complete methodology and hardware validation, the work would demonstrate a practical neuromorphic front-end that materially reduces compute for continuous audio pipelines while preserving detection performance, addressing a recognized bottleneck in real-time, resource-constrained audio systems.
major comments (2)
- [Evaluation / ASD results] Evaluation / ASD results: the abstract states a segment-based F1 of 0.97 on class-agnostic URBAN-SED, yet no training procedure, validation splits, hyper-parameter search, or error bars are supplied; without these the headline reliability claim cannot be assessed and is load-bearing for the central efficiency argument.
- [SED combination results] SED combination results: the reported 42.6× FLOPs reduction and error-rate improvement (0.41 → 0.25) do not state whether trigger overhead is included in the count, nor do they provide neuromorphic-hardware energy measurements or stress tests under noise/domain shift; both omissions directly affect the practical-efficiency claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and outline the revisions that will be incorporated to improve clarity and completeness.
read point-by-point responses
-
Referee: [Evaluation / ASD results] Evaluation / ASD results: the abstract states a segment-based F1 of 0.97 on class-agnostic URBAN-SED, yet no training procedure, validation splits, hyper-parameter search, or error bars are supplied; without these the headline reliability claim cannot be assessed and is load-bearing for the central efficiency argument.
Authors: We agree that the current manuscript does not provide adequate detail on the training procedure, validation splits, hyper-parameter search, or error bars for the reported 0.97 segment-based F1 on class-agnostic URBAN-SED. These elements are required to substantiate the reliability of the result. In the revised manuscript we will add a dedicated experimental setup subsection that specifies the data partitioning, the hyper-parameter selection process, the optimization details, and error bars obtained across multiple random seeds. This addition will directly support assessment of the headline claim. revision: yes
-
Referee: [SED combination results] SED combination results: the reported 42.6× FLOPs reduction and error-rate improvement (0.41 → 0.25) do not state whether trigger overhead is included in the count, nor do they provide neuromorphic-hardware energy measurements or stress tests under noise/domain shift; both omissions directly affect the practical-efficiency claim.
Authors: We will revise the text to explicitly state that the 42.6× FLOPs reduction figure incorporates the computational overhead of the trigger, obtained by comparing total operations in the gated pipeline against the ungated baseline. However, the evaluation remains at the level of algorithmic simulation; no neuromorphic hardware energy measurements were performed. Likewise, while the URBAN-SED experiments include some acoustic variability, dedicated stress tests under additional noise or domain-shift conditions were not conducted. We will add a limitations paragraph in the discussion to acknowledge these points and thereby qualify the practical-efficiency claims. revision: partial
Circularity Check
No circularity: empirical results on public datasets with no self-referential derivations.
full rationale
The paper reports empirical F1 scores, error rates, and FLOPs reductions from evaluations on standard public datasets (URBAN-SED, DCASE 2017 Task 2). No equations, predictions, or uniqueness claims reduce by construction to fitted inputs or self-citations. The trigger is a lightweight FC-SNN with close-open filter; performance metrics are measured outcomes, not tautological. No load-bearing self-citation chains or ansatzes imported from prior author work appear in the provided text. This is a standard empirical systems paper whose central claims rest on external benchmarks rather than internal redefinitions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A lightweight fully connected spiking neural network can serve as an effective front-end trigger for identifying salient audio segments.
invented entities (1)
-
neuromorphic trigger
no independent evidence
Reference graph
Works this paper leans on
-
[1]
L. F. Abbott. 1999. Lapicque’s Introduction of the Integrate-and-Fire Model Neuron (1907).Brain Research Bulletin50, 5–6 (1999), 303–304. doi:10.1016/S0361- 9230(99)00161-6
-
[2]
Sharath Adavanne, Giambattista Parascandolo, Pasi Pertilä, Toni Heittola, and Tuomas Virtanen. 2017. Sound Event Detection in Multichannel Audio Using Spatial and Harmonic Features. arXiv:1706.02293 [cs.SD] https://arxiv.org/abs/ 1706.02293
Pith/arXiv arXiv 2017
-
[3]
Christopher M. Bishop. 2006.Pattern Recognition and Machine Learning. Springer
2006
-
[4]
Peter Blouw, Xuan Choo, Eric Hunsberger, and Chris Eliasmith. 2019. Benchmark- ing Keyword Spotting Efficiency on Neuromorphic Hardware. InProceedings of the 7th Annual Neuro-Inspired Computational Elements Workshop (NICE ’19). Association for Computing Machinery, Article 1. doi:10.1145/3320288.3320304
-
[5]
2017.Convolutional Recurrent Neural Networks for Rare Sound Event Detection
Emre Cakir and Tuomas Virtanen. 2017.Convolutional Recurrent Neural Networks for Rare Sound Event Detection. Technical Report. DCASE2017 Challenge
2017
-
[6]
Gianmarco Cerutti, Renzo Andri, Lukas Cavigelli, Elisabetta Farella, Michele Magno, and Luca Benini. 2020. Sound event detection with binary neural net- works on tightly power-constrained IoT devices. InProceedings of the ACM/IEEE International Symposium on Low Power Electronics and Design (ISLPED ’20). Asso- ciation for Computing Machinery, 19–24. doi:10...
-
[7]
Iulia-Maria Comşa, Luca Versari, Thomas Fischbacher, and Jyrki Alakuijala. 2021. Spiking Autoencoders With Temporal Coding.Frontiers in NeuroscienceVolume 15 - 2021 (2021). doi:10.3389/fnins.2021.712667
-
[8]
Benjamin Cramer, Yannik Stradmann, Johannes Schemmel, and Friedemann Zenke. 2022. The Heidelberg Spiking Data Sets for the Systematic Evaluation of Spiking Neural Networks.IEEE Transactions on Neural Networks and Learning Systems33, 7 (July 2022), 2744–2757. doi:10.1109/tnnls.2020.3044364
-
[9]
2017.Deep Learning for DCASE2017 Challenge
An Dang, Toan Vu, and Jia-Ching Wang. 2017.Deep Learning for DCASE2017 Challenge. Technical Report. DCASE2017 Challenge
2017
- [10]
-
[11]
Jason K Eshraghian, Max Ward, Emre Neftci, Xinxin Wang, Gregor Lenz, Girish Dwivedi, Mohammed Bennamoun, Doo Seok Jeong, and Wei D Lu. 2023. Training spiking neural networks using lessons from deep learning.Proc. IEEE111, 9 (2023), 1016–1054
2023
-
[12]
2016.Deep Learning
Ian Goodfellow, Yoshua Bengio, and Aaron Courville. 2016.Deep Learning. MIT Press
2016
-
[13]
Song Han, Jeff Pool, John Tran, and William J. Dally. 2015. Learning both weights and connections for efficient neural networks. InProceedings of the 29th Interna- tional Conference on Neural Information Processing Systems - Volume 1(Montreal, Canada)(NIPS’15). MIT Press, Cambridge, MA, USA, 1135–1143
2015
-
[14]
Soroush Heydari and Qusay H. Mahmoud. 2025. Tiny Machine Learning and On- Device Inference: A Survey of Applications, Challenges, and Future Directions. Sensors25, 10 (2025). doi:10.3390/s25103191
-
[15]
Yohei Kawaguchi and Takashi Endo. 2017. How can we detect anomalies from subsampled audio signals?. In2017 IEEE 27th International Workshop on Machine Learning for Signal Processing (MLSP). 1–6. doi:10.1109/MLSP.2017.8168164
-
[16]
Seijoon Kim, Seongsik Park, Byunggook Na, and Sungroh Yoon. 2020. Spiking- YOLO: Spiking Neural Network for Energy-Efficient Object Detection.Proceedings of the AAAI Conference on Artificial Intelligence34 (04 2020), 11270–11277. doi:10. 1609/aaai.v34i07.6787
2020
-
[17]
Naoki Koga, Yoshiaki Bando, and Keisuke Imoto. 2024. LEAD Dataset: How Can Labels for Sound Event Detection Vary Depending on Annotators?. In2024 Asia Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC). 1–6. doi:10.1109/APSIPAASC63619.2025.10848643
-
[18]
Edgar Lemaire, Loïc Cordone, Andrea Castagnetti, Pierre-Emmanuel Novac, Jonathan Courtois, and Benoît Miramond. 2022. An Analytical Estimation of Spiking Neural Networks Energy Efficiency. InNeural Information Processing. Springer, 574–587. doi:10.1007/978-3-031-30105-6_48
-
[19]
2017.The SEIE-SCUT Systems for IEEE AASP Chal- lenge on DCASE 2017: Deep Learning Techniques for Audio Representation and Classification
Yanxiong Li and Xianku Li. 2017.The SEIE-SCUT Systems for IEEE AASP Chal- lenge on DCASE 2017: Deep Learning Techniques for Audio Representation and Classification. Technical Report. DCASE2017 Challenge
2017
-
[20]
2017.Rare Sound Event Detection Using 1D Convolutional Recurrent Neural Networks
Hyungui Lim, Jeongsoo Park, and Yoonchang Han. 2017.Rare Sound Event Detection Using 1D Convolutional Recurrent Neural Networks. Technical Report. DCASE2017 Challenge
2017
-
[21]
Rui Lu. 2017. BIDIRECTIONAL GRU FOR SOUND EVENT DETECTION. https: //api.semanticscholar.org/CorpusID:209452474
2017
-
[22]
Iván López-Espejo, Zheng-Hua Tan, John H. L. Hansen, and Jesper Jensen. 2022. Deep Spoken Keyword Spotting: An Overview.IEEE Access10 (2022), 4169–4199. doi:10.1109/ACCESS.2021.3139508
-
[23]
Wolfgang Maass. 1997. Networks of spiking neurons: The third generation of neural network models.Neural Networks10, 9 (1997), 1659–1671. doi:10.1016/ S0893-6080(97)00011-7
1997
-
[24]
1975.Random Sets and Integral Geometry
Georges Matheron. 1975.Random Sets and Integral Geometry. Wiley
1975
-
[25]
Mesaros, A
A. Mesaros, A. Diment, B. Elizalde, T. Heittola, E. Vincent, B. Raj, and T. Virtanen
-
[26]
Sound event detection in the DCASE 2017 Challenge.IEEE/ACM Transac- tions on Audio, Speech, and Language Processing(2019). doi:10.1109/TASLP.2019. 2907016 In press
-
[27]
Annamaria Mesaros, Toni Heittola, Aleksandr Diment, Benjamin Elizalde, Ankit Shah, Emmanuel Vincent, Bhiksha Raj, and Tuomas Virtanen. 2017. DCASE 2017 Challenge setup: Tasks, datasets and baseline system. InDCASE 2017 - Workshop on Detection and Classification of Acoustic Scenes and Events. Munich, Germany. https://inria.hal.science/hal-01627981
2017
-
[28]
Annamaria Mesaros, Toni Heittola, and Tuomas Virtanen. 2016. Metrics for Polyphonic Sound Event Detection.Applied Sciences6, 6 (2016). doi:10.3390/ app6060162
2016
-
[29]
Neftci, Hesham Mostafa, and Friedemann Zenke
Emre O. Neftci, Hesham Mostafa, and Friedemann Zenke. 2019. Surrogate Gradi- ent Learning in Spiking Neural Networks: Bringing the Power of Gradient-Based Optimization to Spiking Neural Networks.IEEE Signal Processing Magazine36, 6 (2019), 51–63. doi:10.1109/MSP.2019.2931595
-
[30]
Huy Phan, Martin Krawczyk-Becker, Timo Gerkmann, and Alfred Mertins. 2017. DNN and CNN with Weighted and Multi-Task Loss Functions for Audio Event Detection. Technical Report. DCASE2017 Challenge
2017
-
[31]
2017.Bosch Rare Sound Events Detection Systems for DCASE2017 Challenge
Anravich Ravichandran and Samarjit Das. 2017.Bosch Rare Sound Events Detection Systems for DCASE2017 Challenge. Technical Report. DCASE2017 Challenge
2017
-
[32]
Justin Salamon, Christopher Jacoby, and Juan Pablo Bello. 2014. A Dataset and Tax- onomy for Urban Sound Research. InProceedings of the 22nd ACM International Conference on Multimedia(Orlando, Florida, USA)(MM ’14). Association for Com- puting Machinery, New York, NY, USA, 1041–1044. doi:10.1145/2647868.2655045
-
[33]
2024.IMPROVING AUDIO SPECTROGRAM TRANSFORMERS FOR SOUND EVENT DETECTION THROUGH MULTI-STAGE TRAINING
Florian Schmid, Paul Primus, Tobias Morocutti, Jonathan Greif, and Gerhard Wid- mer. 2024.IMPROVING AUDIO SPECTROGRAM TRANSFORMERS FOR SOUND EVENT DETECTION THROUGH MULTI-STAGE TRAINING. Technical Report. DCASE2024 Challenge
2024
-
[34]
1982.Image Analysis and Mathematical Morphology
Jean Serra. 1982.Image Analysis and Mathematical Morphology. Academic Press, London
1982
-
[35]
Jaime Sevilla, Lennart Heim, Anson Ho, Tamay Besiroglu, Marius Hobbhahn, and Pablo Villalobos. 2022. Compute Trends Across Three Eras of Machine Learning. In2022 International Joint Conference on Neural Networks (IJCNN). 1–8. doi:10.1109/IJCNN55064.2022.9891914
- [36]
-
[37]
Guangzhi Tang, Kanishkan Vadivel, Yingfu Xu, Refik Bilgic, Kevin Shidqi, Paul Detterer, Stefano Traferro, Mario Konijnenburg, Manolis Sifalakis, Gert-Jan van Schaik, and Amirreza Yousefzadeh. 2023. SENECA: building a fully digital neuro- morphic processor, design trade-offs and challenges.Frontiers in Neuroscience Volume 17 (2023). doi:10.3389/fnins.2023.1187252
-
[38]
M. C. W. Van Rossum. 2001. A Novel Spike Distance.Neural Comput.13, 4 (April 2001), 751–763
2001
-
[39]
Satvik Venkatesh, David Moffat, and Eduardo Reck Miranda. 2022. You Only Hear Once: A YOLO-like Algorithm for Audio Segmentation and Sound Event Detection.Applied Sciences12, 7 (2022). doi:10.3390/app12073293
-
[40]
2017.Transfer Learning Based DNN-HMM Hybrid System for Rare Sound Event Detection
Jianfei Wang, Weiqiang Zhang, and Jia Liu. 2017.Transfer Learning Based DNN-HMM Hybrid System for Rare Sound Event Detection. Technical Report. DCASE2017 Challenge
2017
-
[41]
2025.PRE-TRAINED MODEL ENHANCED ANOMALOUS SOUND DETECTION SYSTEM FOR DCASE2025 TASK2
Lei Wang. 2025.PRE-TRAINED MODEL ENHANCED ANOMALOUS SOUND DETECTION SYSTEM FOR DCASE2025 TASK2. Technical Report. DCASE2025 Challenge
2025
-
[42]
Yaoguang Wang, Yaohao Zheng, Yunxiang Zhang, Yongsheng Xie, Sen Xu, Ying Hu, and Liang He. 2021. Unsupervised Anomalous Sound Detection for Machine Condition Monitoring Using Classification-Based Methods.Applied Sciences11, 23 (2021). doi:10.3390/app112311128
-
[43]
2023.calflops: a FLOPs and Params calculate tool for neural networks in pytorch framework
xiaoju ye. 2023.calflops: a FLOPs and Params calculate tool for neural networks in pytorch framework. https://github.com/MrYxJ/calculate-flops.pytorch
2023
-
[44]
2025.A TWO STAGE FUSION ANOMALY DETECTION APPROACH FOR TASK2
Jie Yang. 2025.A TWO STAGE FUSION ANOMALY DETECTION APPROACH FOR TASK2. Technical Report. DCASE2025 Challenge
2025
-
[45]
Yukun Yang, Wenrui Zhang, and Peng Li. 2021. Backpropagated Neighborhood Aggregation for Accurate Training of Spiking Neural Networks. InInternational Conference on Machine Learning. https://api.semanticscholar.org/CorpusID: 235826047
2021
-
[46]
Zhirong Ye, Xiangdong Wang, Hong Liu, Yueliang Qian, Rui Tao, Long Yan, and Kazushige Ouchi. 2021. Sound Event Detection Transformer: An Event- based End-to-End Model for Sound Event Detection. arXiv:2110.02011 [cs.SD] https://arxiv.org/abs/2110.02011
arXiv 2021
-
[47]
Wenrui Zhang and Peng Li. 2020. Temporal spike sequence learning via back- propagation for deep spiking neural networks(NIPS ’20). Curran Associates Inc., Red Hook, NY, USA, Article 1008. Received 31 March 2026; accepted 8 June 2026; revised 24 June 2026
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.