Continual Self-Improvement with Lightweight Experiential Latent Memories
Pith reviewed 2026-06-27 01:54 UTC · model grok-4.3
The pith
Large language models can learn continually from their own reasoning traces by distilling them into lightweight latent memories using self-generated majority-vote rewards.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
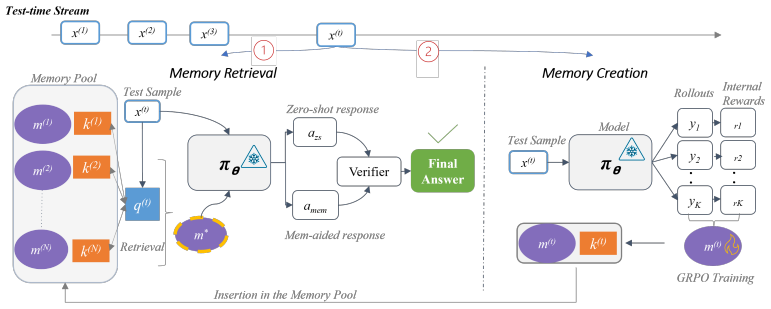
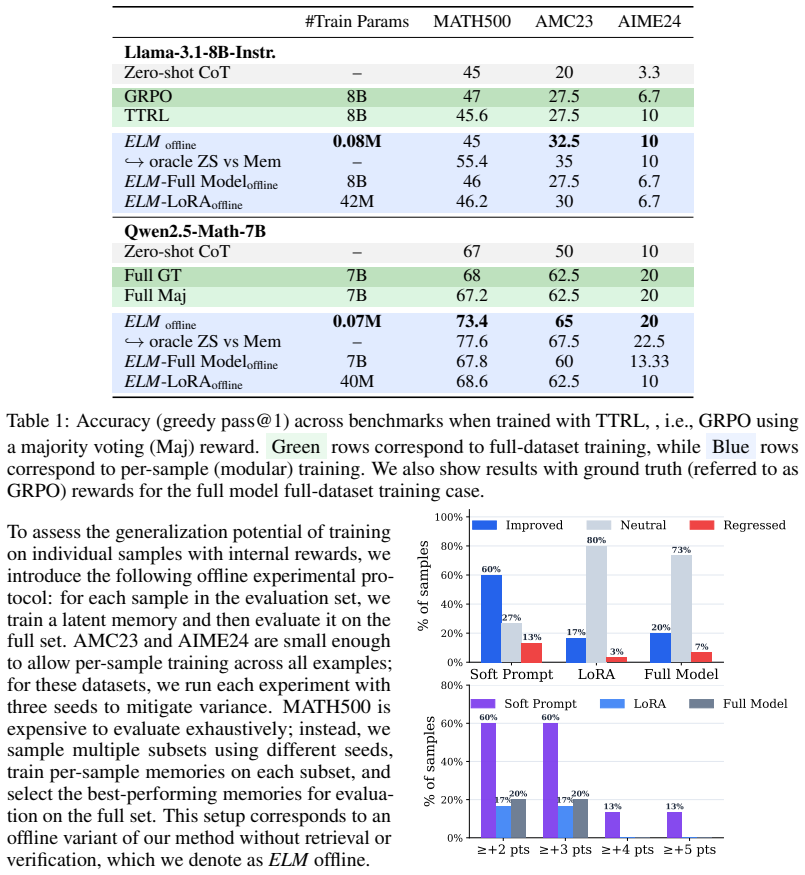
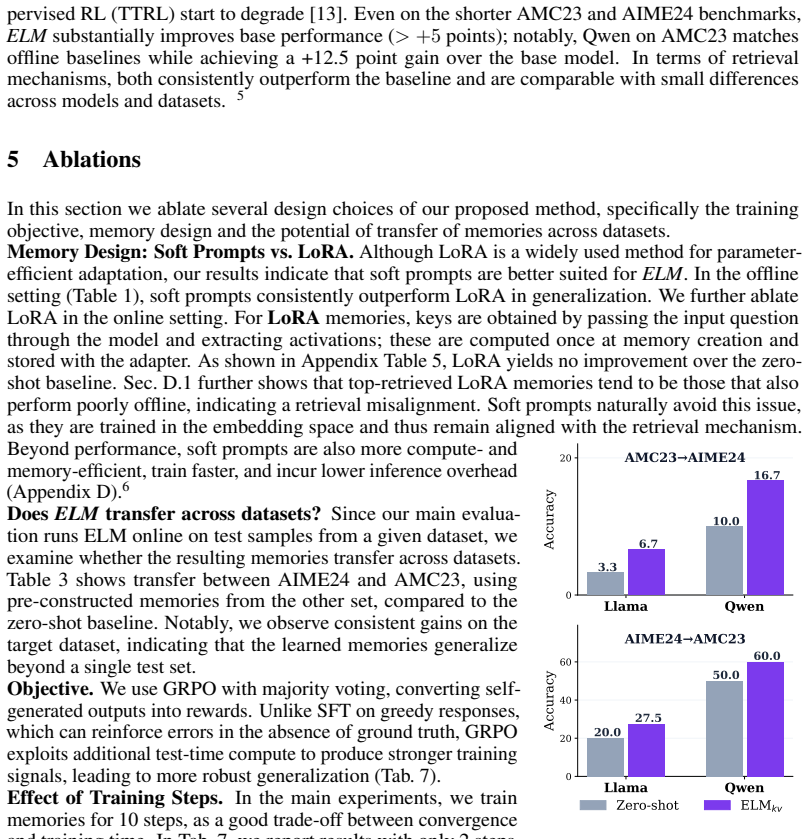
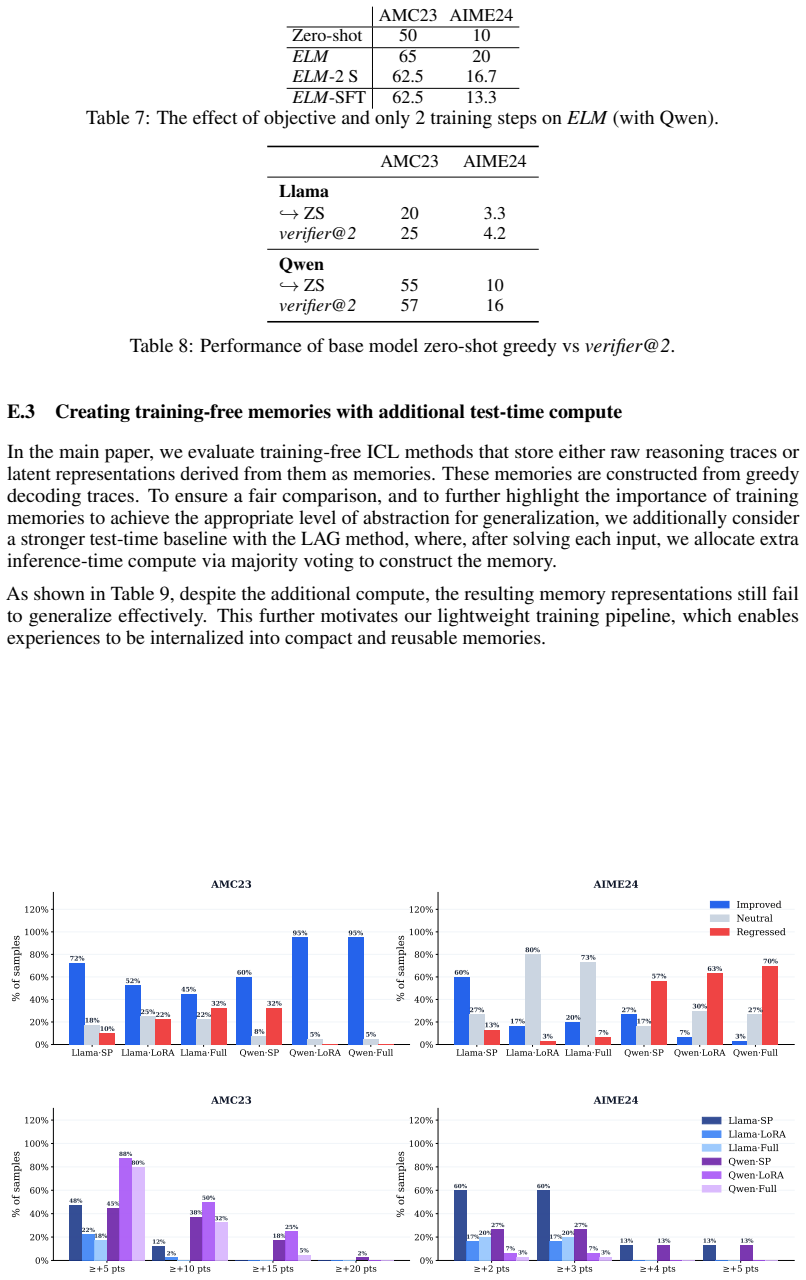
Drawing from unsupervised reinforcement learning ideas, lightweight per-instance training with self-generated test-time signals such as majority voting as rewards yields substantial gains that often surpass full-dataset offline training. This motivates distilling inference-time compute into compact modular latent memories that store the underlying reasoning structure for future use.
What carries the argument
Modular latent memories implemented as extremely lightweight soft prompts, trained online with majority-voting rewards to capture transferable reasoning structures.
If this is right
- Outperforms zero-shot and raw-data ICL baselines on mathematical reasoning benchmarks.
- Achieves performance competitive with full parametric updates despite using far fewer parameters.
- Transfers effectively across datasets while avoiding catastrophic forgetting through modular design.
- Enables continual improvement by converting transient reasoning traces into persistent reusable knowledge.
Where Pith is reading between the lines
- Such memories could potentially be shared or composed across multiple models if standardized.
- The method might extend to non-mathematical domains where self-consistency signals are available.
- Scaling the number of memories could lead to emergent capabilities in long-term adaptation without retraining the base model.
Load-bearing premise
Majority voting over the model's own outputs provides a sufficiently reliable and generalizable reward signal for distilling transferable reasoning structure into the latent memories.
What would settle it
If replacing majority voting with a random or incorrect reward signal eliminates the performance gains, or if the latent memories fail to improve accuracy on held-out problems from the same distribution.
Figures
read the original abstract
Large language models achieve strong reasoning performance by scaling inference-time compute, yet remain fundamentally stateless, discarding the rich, self-produced reasoning traces generated during this process. We investigate whether models can instead learn online from this experience, converting transient computation (reasoning traces) into persistent reusable knowledge, and without external supervision or access to future data. We show that In-Context Learning (ICL) over raw reasoning traces fails to generalize, reflecting a fundamental limitation of token-level reuse: individual traces lack the abstraction needed for transfer, even after refinement (e.g. self-reflection). In contrast, drawing inspiration from recent works on unsupervised reinforcement learning, we find that lightweight per-instance training with self-generated test-time signals (majority voting) as rewards yields substantial gains, often surpassing full-dataset offline training, motivating a shift from raw traces to learned latent representations. Building on this insight, we propose an online method that distills inference-time compute spent on encountered problems into compact modular latent memories capturing the underlying reasoning structure. These memories are stored and retrieved for future inputs, enabling continual improvement while avoiding catastrophic forgetting through modular design. Importantly, our method is highly efficient, parametrized as extremely lightweight soft prompt memories (~0.001% of model parameters) and trained with only a few gradient steps, yet achieving performance competitive with full parametric updates and offline training. Across challenging mathematical reasoning benchmarks, our approach significantly outperforms zero-shot and raw data ICL baselines, while transferring effectively across datasets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that LLMs can achieve continual self-improvement by distilling self-generated reasoning traces into compact modular latent memories (~0.001% of parameters) via lightweight per-instance training that uses majority voting over the model's own outputs as an unsupervised reward signal. This approach is said to outperform both raw-trace ICL (which fails to generalize) and full-dataset offline training on mathematical reasoning benchmarks, while avoiding catastrophic forgetting through modularity and requiring no external supervision or future data.
Significance. If the empirical claims hold, the work would demonstrate a practical route to converting transient inference-time compute into persistent, transferable knowledge with extreme parameter efficiency. The modular latent-memory design and the reported outperformance of offline training are notable strengths that could influence continual-learning research for stateless models.
major comments (2)
- [Abstract] Abstract, paragraph on unsupervised RL inspiration: the central claim that 'lightweight per-instance training with self-generated test-time signals (majority voting) as rewards yields substantial gains, often surpassing full-dataset offline training' rests on the untested premise that majority voting supplies a sufficiently accurate and generalizable reward; the manuscript provides no analysis or ablation on problem families where the base model exhibits consistent systematic errors, leaving open the possibility that incorrect abstractions are reinforced and stored in the latent memories.
- [Abstract] Abstract: the motivation that ICL on raw traces 'fails to generalize, reflecting a fundamental limitation of token-level reuse' is used to justify the shift to latent memories, yet no direct evidence is given that the majority-vote reward mechanism itself escapes the same token-level or abstraction-level failure mode; this assumption is load-bearing for the proposed method's advantage over ICL.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments. We address each major comment below, indicating where revisions to the manuscript are planned.
read point-by-point responses
-
Referee: [Abstract] Abstract, paragraph on unsupervised RL inspiration: the central claim that 'lightweight per-instance training with self-generated test-time signals (majority voting) as rewards yields substantial gains, often surpassing full-dataset offline training' rests on the untested premise that majority voting supplies a sufficiently accurate and generalizable reward; the manuscript provides no analysis or ablation on problem families where the base model exhibits consistent systematic errors, leaving open the possibility that incorrect abstractions are reinforced and stored in the latent memories.
Authors: We agree that the manuscript lacks a dedicated ablation on problem families exhibiting consistent systematic errors in the base model, and that this leaves open the possibility of reinforcing incorrect abstractions. While the reported gains over both ICL and offline training on standard benchmarks provide indirect support for the reliability of the reward signal in the evaluated settings, we will add a new limitations subsection and a targeted ablation simulating systematic biases to directly evaluate this concern. revision: yes
-
Referee: [Abstract] Abstract: the motivation that ICL on raw traces 'fails to generalize, reflecting a fundamental limitation of token-level reuse' is used to justify the shift to latent memories, yet no direct evidence is given that the majority-vote reward mechanism itself escapes the same token-level or abstraction-level failure mode; this assumption is load-bearing for the proposed method's advantage over ICL.
Authors: The consistent outperformance of the latent-memory approach relative to raw-trace ICL across benchmarks constitutes supporting evidence that the method enables abstraction beyond token-level reuse. Nevertheless, we acknowledge the value of more explicit discussion of this distinction. We will revise the abstract and introduction to articulate more clearly how the per-instance latent training with majority-vote rewards facilitates abstraction, and we will add supporting analysis drawn from the existing transfer experiments. revision: partial
Circularity Check
No circularity in claimed derivation
full rationale
The paper presents an empirical method that converts inference-time traces into lightweight latent memories using majority-voting rewards drawn from the model's own outputs. No equations, parameter-fitting steps, or self-citations are described that would make the reported performance gains equivalent to quantities defined by the method's own inputs. The central claims rest on experimental comparisons against baselines rather than any self-definitional or fitted-input reduction, rendering the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
invented entities (1)
-
lightweight experiential latent memories
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Gradient based sample selection for online continual learning.Advances in neural information processing systems, 32, 2019
Rahaf Aljundi, Min Lin, Baptiste Goujaud, and Yoshua Bengio. Gradient based sample selection for online continual learning.Advances in neural information processing systems, 32, 2019
2019
-
[2]
Yonatan Belinkov, Nadir Durrani, Fahim Dalvi, Hassan Sajjad, and James Glass. What do neural machine translation models learn about morphology? InProceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 861–872, 2017
2017
-
[3]
Bradley Brown, Jordan Juravsky, Ryan Ehrlich, Ronald Clark, Quoc V Le, Christopher Ré, and Azalia Mirhoseini. Large language monkeys: Scaling inference compute with repeated sampling.arXiv preprint arXiv:2407.21787, 2024
Pith/arXiv arXiv 2024
-
[4]
Peter Baile Chen, Yi Zhang, Dan Roth, Samuel Madden, Jacob Andreas, and Michael Cafarella. Log-augmented generation: Scaling test-time reasoning with reusable computation.arXiv preprint arXiv:2505.14398, 2025
arXiv 2025
-
[5]
Modular memory is the key to continual learning agents.arXiv preprint arXiv:2603.01761, 2026
Vaggelis Dorovatas, Malte Schwerin, Andrew D Bagdanov, Lucas Caccia, Antonio Carta, Laurent Charlin, Barbara Hammer, Tyler L Hayes, Timm Hess, Christopher Kanan, et al. Modular memory is the key to continual learning agents.arXiv preprint arXiv:2603.01761, 2026
Pith/arXiv arXiv 2026
-
[6]
Concise reasoning via reinforcement learning.arXiv preprint arXiv:2504.05185, 2025
Mehdi Fatemi, Banafsheh Rafiee, Mingjie Tang, and Kartik Talamadupula. Concise reasoning via reinforcement learning.arXiv preprint arXiv:2504.05185, 2025
arXiv 2025
-
[7]
Catastrophic forgetting in connectionist networks.Trends in cognitive sciences, 3(4):128–135, 1999
Robert M French. Catastrophic forgetting in connectionist networks.Trends in cognitive sciences, 3(4):128–135, 1999
1999
-
[8]
Jiaxuan Gao, Shusheng Xu, Wenjie Ye, Weilin Liu, Chuyi He, Wei Fu, Zhiyu Mei, Guangju Wang, and Yi Wu. On designing effective rl reward at training time for llm reasoning.arXiv preprint arXiv:2410.15115, 2024
arXiv 2024
-
[9]
Transformer feed-forward layers are key-value memories
Mor Geva, Roei Schuster, Jonathan Berant, and Omer Levy. Transformer feed-forward layers are key-value memories. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 5484–5495, 2021
2021
-
[10]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al- Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024
Pith/arXiv arXiv 2024
-
[11]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
Pith/arXiv arXiv 2025
-
[12]
Shibo Hao, Sainbayar Sukhbaatar, DiJia Su, Xian Li, Zhiting Hu, Jason Weston, and Yuandong Tian. Training large language models to reason in a continuous latent space.arXiv preprint arXiv:2412.06769, 2024
Pith/arXiv arXiv 2024
-
[13]
How far can unsupervised rlvr scale llm training?arXiv preprint arXiv:2603.08660, 2026
Bingxiang He, Yuxin Zuo, Zeyuan Liu, Shangziqi Zhao, Zixuan Fu, Junlin Yang, Cheng Qian, Kaiyan Zhang, Yuchen Fan, Ganqu Cui, et al. How far can unsupervised rlvr scale llm training?arXiv preprint arXiv:2603.08660, 2026
arXiv 2026
-
[14]
Measuring mathematical problem solving with the math dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. InThirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)
-
[15]
Yubo Hou, Zhisheng Chen, Tao Wan, and Zengchang Qin. Flashmem: Distilling intrinsic latent memory via computation reuse.arXiv preprint arXiv:2601.05505, 2026
Pith/arXiv arXiv 2026
-
[16]
Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
2022
-
[17]
Openai o1 system card.arXiv preprint arXiv:2412.16720, 2024
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Hel- yar, Aleksander Madry, Alex Beutel, Alex Carney, et al. Openai o1 system card.arXiv preprint arXiv:2412.16720, 2024
Pith/arXiv arXiv 2024
-
[18]
Compute as teacher: Turning inference compute into reference-free supervision
Dulhan Jayalath, Shashwat Goel, Thomas Foster, Parag Jain, Suchin Gururangan, Cheng Zhang, Anirudh Goyal, and Alan Schelten. Compute as teacher: Turning inference compute into reference-free supervision. arXiv preprint arXiv:2509.14234, 2025. 11
Pith/arXiv arXiv 2025
-
[19]
Measuring faithfulness in chain-of-thought reasoning.arXiv preprint arXiv:2307.13702, 2023
Tamera Lanham, Anna Chen, Ansh Radhakrishnan, Benoit Steiner, Carson Denison, Danny Hernandez, Dustin Li, Esin Durmus, Evan Hubinger, Jackson Kernion, et al. Measuring faithfulness in chain-of-thought reasoning.arXiv preprint arXiv:2307.13702, 2023
Pith/arXiv arXiv 2023
-
[20]
The power of scale for parameter-efficient prompt tuning
Brian Lester, Rami Al-Rfou, and Noah Constant. The power of scale for parameter-efficient prompt tuning. InProceedings of the 2021 conference on empirical methods in natural language processing, pages 3045–3059, 2021
2021
-
[21]
Numinamath: The largest public dataset in ai4maths with 860k pairs of competition math problems and solutions.Hugging Face repository, 13(9):9, 2024
Jia Li, Edward Beeching, Lewis Tunstall, Ben Lipkin, Roman Soletskyi, Shengyi Huang, Kashif Rasul, Longhui Yu, Albert Q Jiang, Ziju Shen, et al. Numinamath: The largest public dataset in ai4maths with 860k pairs of competition math problems and solutions.Hugging Face repository, 13(9):9, 2024
2024
-
[22]
Prefix-tuning: Optimizing continuous prompts for generation
Xiang Lisa Li and Percy Liang. Prefix-tuning: Optimizing continuous prompts for generation. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 4582– 4597, 2021
2021
-
[23]
A comprehensive survey on test-time adaptation under distribution shifts.International Journal of Computer Vision, 133(1):31–64, 2025
Jian Liang, Ran He, and Tieniu Tan. A comprehensive survey on test-time adaptation under distribution shifts.International Journal of Computer Vision, 133(1):31–64, 2025
2025
-
[24]
Let’s verify step by step
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. InThe twelfth international conference on learning representations, 2023
2023
-
[25]
Understanding r1-zero-like training: A critical perspective.arXiv preprint arXiv:2503.20783, 2025
Zichen Liu, Changyu Chen, Wenjun Li, Penghui Qi, Tianyu Pang, Chao Du, Wee Sun Lee, and Min Lin. Understanding r1-zero-like training: A critical perspective.arXiv preprint arXiv:2503.20783, 2025
Pith/arXiv arXiv 2025
-
[26]
Siru Ouyang, Jun Yan, I Hsu, Yanfei Chen, Ke Jiang, Zifeng Wang, Rujun Han, Long T Le, Samira Daruki, Xiangru Tang, et al. Reasoningbank: Scaling agent self-evolving with reasoning memory.arXiv preprint arXiv:2509.25140, 2025
Pith/arXiv arXiv 2025
-
[27]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
Pith/arXiv arXiv 2024
-
[28]
Scaling llm test-time compute optimally can be more effective than scaling parameters for reasoning
Charlie Victor Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling llm test-time compute optimally can be more effective than scaling parameters for reasoning. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[29]
Dynamic cheatsheet: Test-time learning with adaptive memory.arXiv preprint arXiv:2504.07952, 2025
Mirac Suzgun, Mert Yuksekgonul, Federico Bianchi, Dan Jurafsky, and James Zou. Dynamic cheatsheet: Test-time learning with adaptive memory.arXiv preprint arXiv:2504.07952, 2025
arXiv 2025
-
[30]
Tent: Fully test-time adaptation by entropy minimization.arXiv preprint arXiv:2006.10726, 2020
Dequan Wang, Evan Shelhamer, Shaoteng Liu, Bruno Olshausen, and Trevor Darrell. Tent: Fully test-time adaptation by entropy minimization.arXiv preprint arXiv:2006.10726, 2020
Pith/arXiv arXiv 2006
-
[31]
Yiping Wang, Qing Yang, Zhiyuan Zeng, Liliang Ren, Liyuan Liu, Baolin Peng, Hao Cheng, Xuehai He, Kuan Wang, Jianfeng Gao, et al. Reinforcement learning for reasoning in large language models with one training example.arXiv preprint arXiv:2504.20571, 2025
Pith/arXiv arXiv 2025
-
[32]
Chain-of-thought prompting elicits reasoning in large language models.Advances in neural information processing systems, 35:24824–24837, 2022
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models.Advances in neural information processing systems, 35:24824–24837, 2022
2022
-
[33]
Genius: A generalizable and purely unsupervised self-training framework for advanced reasoning
Fangzhi Xu, Hang Yan, Chang Ma, Haiteng Zhao, Qiushi Sun, Kanzhi Cheng, Junxian He, Jun Liu, and Zhiyong Wu. Genius: A generalizable and purely unsupervised self-training framework for advanced reasoning. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 13153–13167, 2025
2025
-
[34]
An Yang, Beichen Zhang, Binyuan Hui, Bofei Gao, Bowen Yu, Chengpeng Li, Dayiheng Liu, Jianhong Tu, Jingren Zhou, Junyang Lin, et al. Qwen2. 5-math technical report: Toward mathematical expert model via self-improvement.arXiv preprint arXiv:2409.12122, 2024
Pith/arXiv arXiv 2024
-
[35]
Weihao Zeng, Yuzhen Huang, Qian Liu, Wei Liu, Keqing He, Zejun Ma, and Junxian He. Simplerl-zoo: Investigating and taming zero reinforcement learning for open base models in the wild.arXiv preprint arXiv:2503.18892, 2025
Pith/arXiv arXiv 2025
-
[36]
Guibin Zhang, Muxin Fu, and Shuicheng Yan. Memgen: Weaving generative latent memory for self- evolving agents.arXiv preprint arXiv:2509.24704, 2025. 12
arXiv 2025
-
[37]
Agentic context engineering: Evolving contexts for self-improving language models.The Fourteenth International Conference on Learning Representations, 2026
Qizheng Zhang, Changran Hu, Shubhangi Upasani, Boyuan Ma, Fenglu Hong, Vamsidhar Kamanuru, Jay Rainton, Chen Wu, Mengmeng Ji, Hanchen Li, et al. Agentic context engineering: Evolving contexts for self-improving language models.The Fourteenth International Conference on Learning Representations, 2026
2026
-
[38]
No free lunch: Rethinking internal feedback for llm reasoning.arXiv preprint arXiv:2506.17219, 2025
Yanzhi Zhang, Zhaoxi Zhang, Haoxiang Guan, Yilin Cheng, Yitong Duan, Chen Wang, Yue Wang, Shuxin Zheng, and Jiyan He. No free lunch: Rethinking internal feedback for llm reasoning.arXiv preprint arXiv:2506.17219, 2025
arXiv 2025
-
[39]
American invitational mathematics examination (aime) 2024, 2024
Yifan Zhang and Team Math-AI. American invitational mathematics examination (aime) 2024, 2024
2024
-
[40]
Yunjian Zhang, Sudong Wang, Yang Li, Peiran Xu, Conghao Zhou, Xiaoyue Ma, Jianing Li, and Yao Zhu. Resource-efficient reinforcement for reasoning large language models via dynamic one-shot policy refinement.arXiv preprint arXiv:2602.00815, 2026
Pith/arXiv arXiv 2026
-
[41]
The lessons of developing process reward models in mathematical reasoning
Zhenru Zhang, Chujie Zheng, Yangzhen Wu, Beichen Zhang, Runji Lin, Bowen Yu, Dayiheng Liu, Jingren Zhou, and Junyang Lin. The lessons of developing process reward models in mathematical reasoning. In Findings of the Association for Computational Linguistics: ACL 2025, pages 10495–10516, 2025
2025
-
[42]
Absolute zero: Reinforced self-play reasoning with zero data.arXiv preprint arXiv:2505.03335, 2025
Andrew Zhao, Yiran Wu, Yang Yue, Tong Wu, Quentin Xu, Matthieu Lin, Shenzhi Wang, Qingyun Wu, Zilong Zheng, and Gao Huang. Absolute zero: Reinforced self-play reasoning with zero data.arXiv preprint arXiv:2505.03335, 2025
Pith/arXiv arXiv 2025
-
[43]
Learning to reason without external rewards.arXiv preprint arXiv:2505.19590, 2025
Xuandong Zhao, Zhewei Kang, Aosong Feng, Sergey Levine, and Dawn Song. Learning to reason without external rewards.arXiv preprint arXiv:2505.19590, 2025
Pith/arXiv arXiv 2025
-
[44]
Ttrl: Test-time reinforcement learning.arXiv preprint arXiv:2504.16084, 2025
Yuxin Zuo, Kaiyan Zhang, Li Sheng, Shang Qu, Ganqu Cui, Xuekai Zhu, Haozhan Li, Yuchen Zhang, Xinwei Long, Ermo Hua, et al. Ttrl: Test-time reinforcement learning.arXiv preprint arXiv:2504.16084, 2025. 13 #Trainable Params AMC23 AIME24 Llama-3.1-8B-Instr. ELM-SoftPromptoffline 0.08M 32.5 10 ELM-LoRAoffline 42M 30 6.7 ELM-PrefixTuningoffline 6.5B 30 10 Qwe...
Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.