Improving low-resource ASR using bilingual fine-tuning with language identification: a cross-linguistic evaluation
Pith reviewed 2026-06-27 00:39 UTC · model grok-4.3
The pith
Bilingual fine-tuning with language identification tokens improves ASR for low-resource languages when identification is accurate.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By prepending a language identification token to inputs during bilingual fine-tuning, the model jointly learns language distinction and transcription, resulting in improved ASR performance on low-resource languages provided language identification accuracy is high, with additional gains from supplying the token at inference when identification performance is low.
What carries the argument
Language identification token prepended to training inputs to enable joint language and transcription prediction at inference.
Load-bearing premise
Prepending the language identification token during training enables the model to learn language distinction and transcription without substantial interference between the tasks.
What would settle it
A result showing no ASR improvement from bilingual fine-tuning even in cases of high language identification accuracy would falsify the central benefit.
Figures
read the original abstract
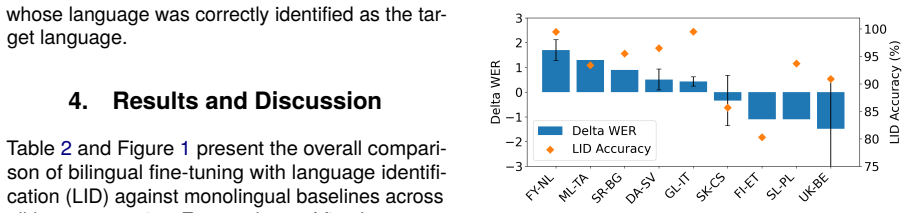
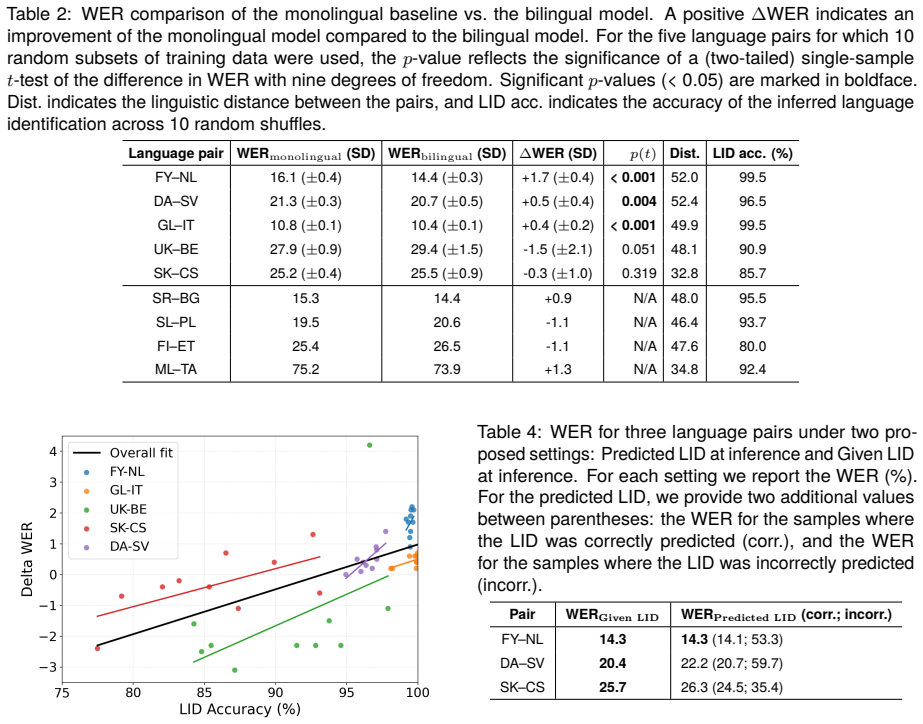
This study explores how bilingual fine-tuning affects automatic speech recognition (ASR) in low-resource languages. We evaluate this method across nine linguistically and geographically diverse language pairs, covering a range of language families and writing systems. To distinguish the two languages, during training, we pre-pend each input text with a language identification token. At inference, the model jointly predicts both the language and transcription from the speech input alone. As texts for which the language is incorrectly determined show low ASR performance, we also conduct a follow-up experiment in which the language identification token is provided both during training and inference. Our results show that bilingual fine-tuning can be beneficial when language identification accuracy is high, and that in cases where language identification performance is low, including the language identification token at inference helps to improve ASR performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript evaluates bilingual fine-tuning for low-resource ASR across nine linguistically diverse language pairs. During training, a language identification (LID) token is prepended to inputs; at inference the model jointly predicts language and transcription from speech alone. A follow-up condition supplies the LID token at inference when LID accuracy is low. The central claim is that bilingual fine-tuning improves ASR when LID accuracy is high, and that supplying the token at inference mitigates performance drops when LID accuracy is low.
Significance. If substantiated by complete experimental reporting, the work would supply a practical, low-overhead technique for exploiting bilingual data in low-resource ASR and would add cross-linguistic evidence on the interaction between LID accuracy and transcription quality.
major comments (1)
- [Abstract / Results] Abstract and results presentation: no baselines, error bars, dataset sizes, or statistical significance tests are referenced, leaving the magnitude and reliability of the reported gains impossible to assess from the given description.
minor comments (2)
- Clarify the exact inference procedure (joint LID+transcription vs. forced LID token) and how WER is computed on the subset of utterances with incorrect LID predictions.
- Report the nine language pairs explicitly, including language families and writing systems, to allow readers to judge the claimed diversity.
Simulated Author's Rebuttal
We thank the referee for the constructive comment and the recommendation for minor revision. We address the concern about result presentation below.
read point-by-point responses
-
Referee: [Abstract / Results] Abstract and results presentation: no baselines, error bars, dataset sizes, or statistical significance tests are referenced, leaving the magnitude and reliability of the reported gains impossible to assess from the given description.
Authors: We agree that the abstract, as a high-level summary, omits these details. The full manuscript reports dataset sizes and language-pair characteristics in the experimental setup section and compares against monolingual fine-tuning baselines in the results. In the revision we will: (1) add a brief mention of dataset scale and the nine language pairs to the abstract, (2) include error bars on all reported WER figures and tables, and (3) add statistical significance tests (paired t-tests or Wilcoxon) between bilingual and monolingual conditions. These changes will make the magnitude and reliability of the gains directly assessable. revision: yes
Circularity Check
No significant circularity
full rationale
The paper is an empirical evaluation of bilingual ASR fine-tuning with LID tokens across nine language pairs. It reports measured WER improvements conditional on observed LID accuracy and a follow-up condition supplying the token at inference. No equations, derivations, fitted parameters, or self-citation chains are present that would reduce any reported gain to a quantity defined by the paper's own inputs. The described procedure is a standard multi-task fine-tuning pattern whose outcomes are externally falsifiable via the reported metrics.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard neural network fine-tuning assumptions hold for the ASR models used.
Reference graph
Works this paper leans on
-
[1]
The Limits of Interpretation
Umberto Eco. The Limits of Interpretation
-
[2]
Temporal Tagging on Different Domains: Challenges, Strategies, and Gold Standards
Jannik Strötgen and Michael Gertz. Temporal Tagging on Different Domains: Challenges, Strategies, and Gold Standards. Proceedings of the Eight International Conference on Language Resources and Evaluation (LREC'12). 2012
2012
-
[3]
Chercheur
J.L. Chercheur. Case-Based Reasoning. 1994
1994
-
[4]
Castor and L
A. Castor and L. E. Pollux. The use of user modelling to guide inference and learning. Applied Intelligence. 1992
1992
-
[5]
Superman and B
S. Superman and B. Batman and C. Catwoman and S. Spiderman. Superheroes experiences with books. Journal journal journal
-
[6]
Elementary Statistics
Paul Gerhard Hoel. Elementary Statistics. 1971
1971
-
[7]
1954--58
A history of technology. 1954--58
1954
-
[8]
N. Chomsky. Conditions on Transformations. A festschrift for Morris Halle. 1973
1973
-
[9]
Natural Fibre Twines
BSI. Natural Fibre Twines. 1973
1973
-
[10]
Language: Its Nature, Development, and Origin
Otto Jespersen. Language: Its Nature, Development, and Origin
-
[11]
and Smith, A.B
Jones, C.D. and Smith, A.B. and Roberts, E.F. 2003
2003
-
[12]
Amooie, Reihaneh and de Vries, Wietse and Hao, Yun and Dijkstra, Jelske and Coler, Matt and Wieling, Martijn , journal=
-
[13]
Babu, Arun and Wang, Changhan and Tjandra, Andros and Lakhotia, Kushal and Xu, Qiantong and Goyal, Naman and Singh, Kritika and Von Platen, Patrick and Saraf, Yatharth and Pino, Juan and others , journal=
-
[14]
Reihaneh Amooie and Wietse de Vries and Yun Hao and Jelske Dijkstra and Matt Coler and Martijn Wieling , year=. 2502.04883 , archivePrefix=
-
[15]
Hou, Wenxin and Dong, Yue and Zhuang, Bairong and Yang, Longfei and Shi, Jiatong and Shinozaki, Takahiro , journal=
-
[16]
2023 , organization=
Liu, Qianying and Gong, Zhuo and Yang, Zhengdong and Yang, Yuhang and Li, Sheng and Ding, Chenchen and Minematsu, Nobuaki and Huang, Hao and Cheng, Fei and Chu, Chenhui and others , booktitle=. 2023 , organization=
2023
-
[17]
2015 , publisher=
Chen, Dongpeng and Mak, Brian Kan-Wing , journal=. 2015 , publisher=
2015
-
[18]
Winata, Genta Indra and Wang, Guangsen and Xiong, Caiming and Hoi, Steven , journal=
-
[19]
2021 , organization=
Hou, Wenxin and Wang, Yidong and Gao, Shengzhou and Shinozaki, Takahiro , booktitle=. 2021 , organization=
2021
-
[20]
Xiao, Yubei and Gong, Ke and Zhou, Pan and Zheng, Guolin and Liang, Xiaodan and Lin, Liang , booktitle=
-
[21]
Kannan, Anjuli and Datta, Arindrima and Sainath, Tara N and Weinstein, Eugene and Ramabhadran, Bhuvana and Wu, Yonghui and Bapna, Ankur and Chen, Zhifeng and Lee, Seungji , journal=
-
[22]
2020 , organization=
Hsu, Jui-Yang and Chen, Yuan-Jui and Lee, Hung-yi , booktitle=. 2020 , organization=
2020
-
[23]
Proceedings of the twelfth language resources and evaluation conference , pages=
Common voice: A massively-multilingual speech corpus , author=. Proceedings of the twelfth language resources and evaluation conference , pages=
-
[24]
2023 , organization=
Yang, Mu and Tjandra, Andros and Liu, Chunxi and Zhang, David and Le, Duc and Kalinli, Ozlem , booktitle=. 2023 , organization=
2023
-
[25]
2019 , organization=
Waters, Austin and Gaur, Neeraj and Haghani, Parisa and Moreno, Pedro and Qu, Zhongdi , booktitle=. 2019 , organization=
2019
-
[26]
2023 , organization=
Kwon, Yoohwan and Chung, Soo-Whan , booktitle=. 2023 , organization=
2023
-
[27]
San, Nay and Paraskevopoulos, Georgios and Arora, Aryaman and He, Xiluo and Kaur, Prabhjot and Adams, Oliver and Jurafsky, Dan , journal=
-
[28]
2023 , organization=
Chen, William and Yan, Brian and Shi, Jiatong and Peng, Yifan and Maiti, Soumi and Watanabe, Shinji , booktitle=. 2023 , organization=
2023
-
[29]
2010 , publisher=
Wichmann, S. 2010 , publisher=
2010
-
[30]
De Vries, Wietse and Bartelds, Martijn and Nissim, Malvina and Wieling, Martijn , journal=
-
[31]
Moore and Lucy Skidmore , title=
Roger K. Moore and Lucy Skidmore , title=
-
[32]
Baevski, Alexei and Zhou, Yuhao and Mohamed, Abdelrahman and Auli, Michael , journal=
-
[33]
ICASSP 2021-2021 IEEE international conference on acoustics, Speech and Signal Processing (ICASSP) , pages=
Meta-adapter: Efficient cross-lingual adaptation with meta-learning , author=. ICASSP 2021-2021 IEEE international conference on acoustics, Speech and Signal Processing (ICASSP) , pages=. 2021 , organization=
2021
-
[34]
arXiv preprint arXiv:1909.05330 , year=
Large-scale multilingual speech recognition with a streaming end-to-end model , author=. arXiv preprint arXiv:1909.05330 , year=
arXiv 1909
-
[35]
ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
Mole: Mixture of language experts for multi-lingual automatic speech recognition , author=. ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2023 , organization=
2023
-
[36]
Moore and Lucy Skidmore , title=
Roger K. Moore and Lucy Skidmore , title=. Proc
-
[37]
doi:10.5281/zenodo.14006617 , url =
Harald Hammarström and Robert Forkel and Martin Haspelmath and Sebastian Bank , title =. doi:10.5281/zenodo.14006617 , url =
-
[38]
doi:10.5281/zenodo.13950591 , url =
Matthew Dryer and Martin Haspelmath , title =. doi:10.5281/zenodo.13950591 , url =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.