Monotonic Kolmogorov-Arnold Networks: A Theoretical and Empirical Study of Monotonicity as an Inductive Bias
Pith reviewed 2026-06-27 01:16 UTC · model grok-4.3
The pith
Monotonic KANs enforce hard monotonicity for every parameter value and realize any qualifying feature extractor monotonically at no more than twice the original size.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Any C^K feature extractor, K greater than zero, that induces a ball-shaped semantic-neighborhood partition admits a monotone realization of the equivalent neighborhood structure at N' = N* + k which is at most 2N*, where k is the number of non-monotone coordinates of the original extractor. The bound is architecture-agnostic and supplies a sizing rule for monotone encoders.
What carries the argument
The representation-cost theorem that converts any qualifying feature extractor into an equivalent monotone network at bounded extra size, realized in practice by MKAN's exponential reparameterization of B-spline coefficients together with positive edge weights and a monotone base activation.
If this is right
- Monotonicity holds for every parameter value without constraints or special optimizers.
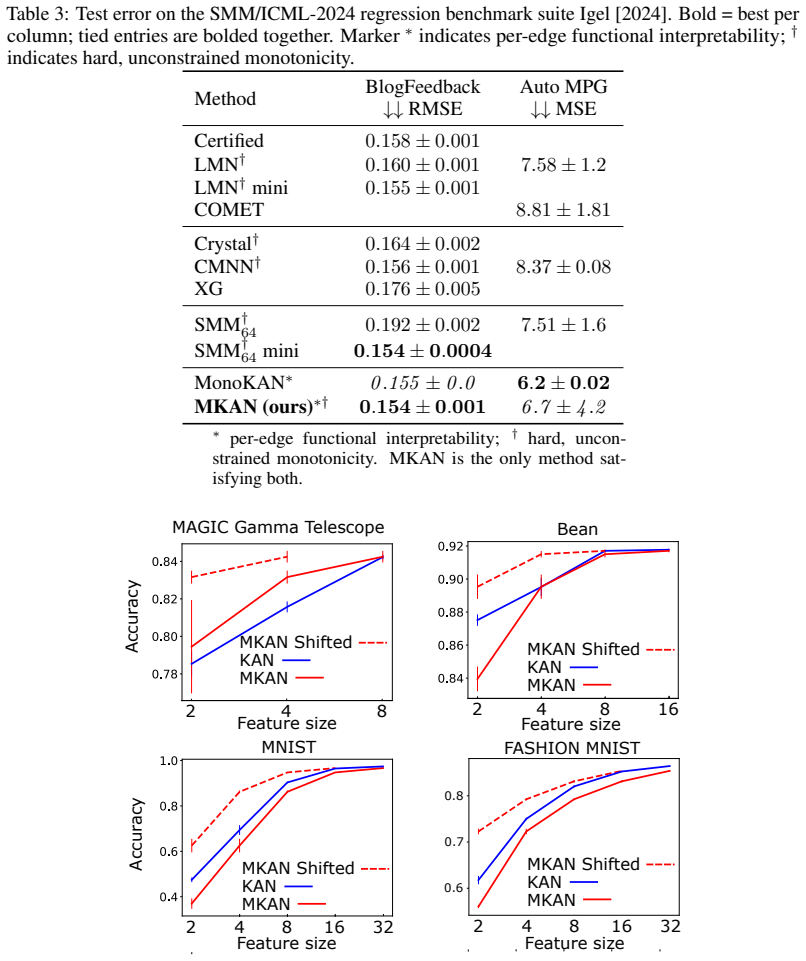
- MKAN matches state-of-the-art monotone networks on the SMM/ICML-2024 benchmark.
- Self-supervised sweeps on four real datasets confirm that twice the original size suffices.
- On controlled monotone-generative data MKAN recovers ground-truth factors with higher Spearman alignment than KAN, MLP, or linear baselines.
Where Pith is reading between the lines
- The size bound offers a practical rule for choosing the width of any monotone encoder once the ball-shaped partition property is verified.
- Per-edge functional transparency may help domain experts inspect which inputs drive monotonic responses in scientific or economic models.
- The same reparameterization technique could be tested on other spline-based or additive architectures beyond KANs.
Load-bearing premise
The starting feature extractor must induce a ball-shaped semantic-neighborhood partition.
What would settle it
A concrete C^K feature extractor with ball-shaped partitions whose smallest monotone realization requires strictly more than twice as many features as the original, or a training run in which MKAN violates monotonicity on held-out data despite using only the reparameterized form.
Figures

read the original abstract
Monotonicity has been a long-running architectural inductive bias for neural networks, motivated by tabular, scientific, and economic settings where outputs are known to respond monotonically to certain inputs. Existing approaches are MLP- or flow-based and lack per-edge functional transparency; the only Kolmogorov--Arnold Network (KAN) variant with monotonicity, MonoKAN, enforces the constraint only on a restricted parameter subset and requires a projection-style training procedure. We close this gap with \textbf{MKAN}, a KAN with hard monotonicity guaranteed for \emph{all} parameter values via exponential reparameterization of B-spline coefficients, positive edge weights, and a monotone base activation. Training reduces to standard unconstrained gradient descent. Our headline theoretical contribution is a \emph{representation-cost} theorem: any $C^K, K >0$ feature extractor inducing a ball-shaped semantic-neighborhood partition admits a monotone realization of the equivalent neighborhood structure at $N' = N^* + k \le 2N^*$, where $k$ is the number of non-monotone coordinates of the original. The bound is architecture-agnostic and gives a principled sizing rule for monotone encoders. Empirically, MKAN is competitive with state-of-the-art monotone NNs on the SMM/ICML-2024 benchmark while being the only method that combines hard unconstrained monotonicity with KAN's per-edge functional transparency; the $2N^*$ prediction is validated in a self-supervised feature-size sweep on four real datasets, and on a controlled monotone-generative dataset MKAN recovers ground-truth factors with substantially higher Spearman alignment than KAN, MLP, and linear baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MKAN, a Kolmogorov-Arnold Network variant enforcing hard monotonicity for all parameter values via exponential reparameterization of B-spline coefficients, positive edge weights, and a monotone base activation, reducing training to unconstrained gradient descent. Its headline theoretical contribution is a representation-cost theorem: any C^K (K>0) feature extractor inducing a ball-shaped semantic-neighborhood partition admits a monotone realization of the equivalent neighborhood structure at size N' = N^* + k ≤ 2N^*, where k counts non-monotone coordinates of the original. Empirically, MKAN matches state-of-the-art monotone NNs on the SMM/ICML-2024 benchmark, validates the 2N^* sizing rule via self-supervised feature-size sweeps on four real datasets, and recovers ground-truth factors with higher Spearman alignment than KAN, MLP, and linear baselines on a controlled monotone-generative dataset.
Significance. If the representation-cost theorem holds under its premise, the work supplies an architecture-agnostic sizing rule for monotone encoders and demonstrates that MKAN uniquely pairs hard monotonicity with KAN-style per-edge transparency. The empirical competitiveness on the SMM benchmark and the controlled recovery experiment provide concrete support for the practical value of the inductive bias. The explicit theorem statement and the self-supervised validation of the 2N^* prediction are strengths that would be retained under revision.
major comments (2)
- [representation-cost theorem] Representation-cost theorem (abstract and theoretical section): the bound N' ≤ 2N^* is conditioned on the premise that the C^K feature extractor induces a ball-shaped semantic-neighborhood partition, yet the manuscript provides neither a derivation of this property from the extractor architecture nor empirical verification that it holds for the extractors used in the benchmark and sweep experiments; this premise is load-bearing for the claimed architecture-agnostic generality.
- [empirical validation] Empirical validation of the 2N^* prediction (self-supervised feature-size sweep): the abstract states that the prediction is validated on four real datasets, but no error-bar details, statistical significance tests, or description of how the 2N^* threshold was operationally tested are supplied, weakening the link between the theorem and the reported empirical support.
minor comments (1)
- The abstract claims MKAN is 'the only method that combines hard unconstrained monotonicity with KAN's per-edge functional transparency'; a short comparison table in the introduction or related-work section would make the positioning against MonoKAN and MLP/flow baselines more precise.
Simulated Author's Rebuttal
We thank the referee for their thoughtful comments on our manuscript. We address each major comment below, providing clarifications and proposing revisions to enhance the clarity of our theoretical and empirical contributions.
read point-by-point responses
-
Referee: [representation-cost theorem] Representation-cost theorem (abstract and theoretical section): the bound N' ≤ 2N^* is conditioned on the premise that the C^K feature extractor induces a ball-shaped semantic-neighborhood partition, yet the manuscript provides neither a derivation of this property from the extractor architecture nor empirical verification that it holds for the extractors used in the benchmark and sweep experiments; this premise is load-bearing for the claimed architecture-agnostic generality.
Authors: The representation-cost theorem is explicitly conditioned on the premise that the feature extractor induces a ball-shaped semantic-neighborhood partition. The architecture-agnostic nature of the result lies in the fact that the bound N' ≤ 2N^* holds for any C^K extractor satisfying this premise, independent of the specific architecture details. We acknowledge that the manuscript does not derive the premise for the particular extractors employed in the experiments nor provide direct empirical verification of the partition shape. This is because the theorem is presented as a general result applicable when the condition is met. In the revised version, we will add a paragraph in the theoretical section discussing the plausibility of the premise for common feature extractors, particularly those trained via self-supervision on semantic neighborhoods, which often exhibit approximately ball-shaped structures in latent space due to the properties of contrastive or reconstruction objectives. We will also reference relevant literature on neighborhood structures in representation learning. revision: partial
-
Referee: [empirical validation] Empirical validation of the 2N^* prediction (self-supervised feature-size sweep): the abstract states that the prediction is validated on four real datasets, but no error-bar details, statistical significance tests, or description of how the 2N^* threshold was operationally tested are supplied, weakening the link between the theorem and the reported empirical support.
Authors: We agree that providing more details on the empirical validation would strengthen the connection between the theorem and the experiments. In the revised manuscript, we will expand the description of the self-supervised feature-size sweep to include: (1) error bars computed from 5 independent runs with different random seeds, (2) statistical significance tests (e.g., paired t-tests) comparing performance at N' = 2N^* versus larger sizes, and (3) an explicit operational definition of the threshold test, namely that the minimal N' achieving within 5% of the maximum performance is ≤ 2N^* for each dataset. These additions will be incorporated into the experimental section and the abstract if space permits. revision: yes
Circularity Check
No significant circularity detected; theorem takes premise as given and bound follows from definition of k.
full rationale
The representation-cost theorem explicitly invokes the ball-shaped semantic-neighborhood partition as its starting premise rather than deriving it internally, and states the sizing bound N' = N* + k ≤ 2N* where k counts non-monotone coordinates (hence k ≤ N* by definition). No equations or self-citations reduce the existence claim or the 2N* rule back to fitted parameters, prior author results, or ansatzes; the empirical 2N* validation on datasets is presented as external confirmation. The derivation chain is therefore self-contained with no load-bearing steps that collapse to the inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The feature extractor induces a ball-shaped semantic-neighborhood partition
Reference graph
Works this paper leans on
-
[1]
Julia Angwin, Jeff Larson, Surya Mattu, and Lauren Kirchner
DOI: https://doi.org/10.24432/C50S4B. Julia Angwin, Jeff Larson, Surya Mattu, and Lauren Kirchner. Machine bias. InEthics of data and analytics, pages 254–264. Auerbach Publications,
-
[2]
Sanjeev Arora, Nadav Cohen, Noah Golowich, and Wei Hu. A convergence analysis of gradient descent for deep linear neural networks.arXiv preprint arXiv:1810.02281,
-
[3]
Understanding disentangling in $\beta$-VAE
DOI: https://doi.org/10.24432/C52C8B. Christopher P Burgess, Irina Higgins, Arka Pal, Loic Matthey, Nick Watters, Guillaume Des- jardins, and Alexander Lerchner. Understanding disentangling in beta-vae.arXiv preprint arXiv:1804.03599,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.24432/c52c8b
-
[4]
Convergence of gradient descent for deep neural networks.arXiv preprint arXiv:2203.16462,
Sourav Chatterjee. Convergence of gradient descent for deep neural networks.arXiv preprint arXiv:2203.16462,
-
[5]
Avoiding resentment via monotonic fairness.arXiv preprint arXiv:1909.01251,
Guy W Cole and Sinead A Williamson. Avoiding resentment via monotonic fairness.arXiv preprint arXiv:1909.01251,
arXiv 1909
-
[6]
Neural autoregressive flows
Chin-Wei Huang, David Krueger, Alexandre Lacoste, and Aaron Courville. Neural autoregressive flows. InInternational Conference on Machine Learning (ICML), pages 2078–2087,
2078
-
[7]
Abhishek Kumar, Prasanna Sattigeri, and Avinash Balakrishnan. Variational inference of disentangled latent concepts from unlabeled observations.arXiv preprint arXiv:1711.00848,
-
[8]
Deontological ethics by monotonicity shape constraints
Serena Wang and Maya Gupta. Deontological ethics by monotonicity shape constraints. InInterna- tional conference on artificial intelligence and statistics, pages 2043–2054. PMLR,
2043
-
[9]
11 A MKAN architecture A.1 Enforcing Monotonicity in KANs (MKAN) In this subsection, we describe how to enforce monotonicity in KANs to enhance interpretability. To enforce monotonicity, we require: (1) each spline ϕ′ ij to be monotonically increasing, (2) all scaling weights to be positive, and (3) the base activation to be monotonically increasing. This...
1978
-
[10]
MKAN layer.Combining monotonic splines with positive weight constraints and a monotonic activation, the MKAN layer is defined as: F ′(j)(x1,
This normalization insures that Eγ ′(K+p) ij =−Eγ ′(1) ij =σ becauseEe n(k) i,j = √e. MKAN layer.Combining monotonic splines with positive weight constraints and a monotonic activation, the MKAN layer is defined as: F ′(j)(x1, . . . , xNin ) = NinX i=1 exp(w′(s) ij )ϕ ′ ij(xi) + exp(w ′(b) ij ) ReLU(xi) +b j,(14) where the exponential ensures positivity o...
2023
-
[11]
The input data consist of three-dimensional vectors (x1, x2, x3), where x1 ∼ 0.5N(0,1) + 0.5N(10,1),x 3 ∼ N(0,1), andx 2 =r+x 3 , r∼0.5N(0,1) + 0.5N(10,1)
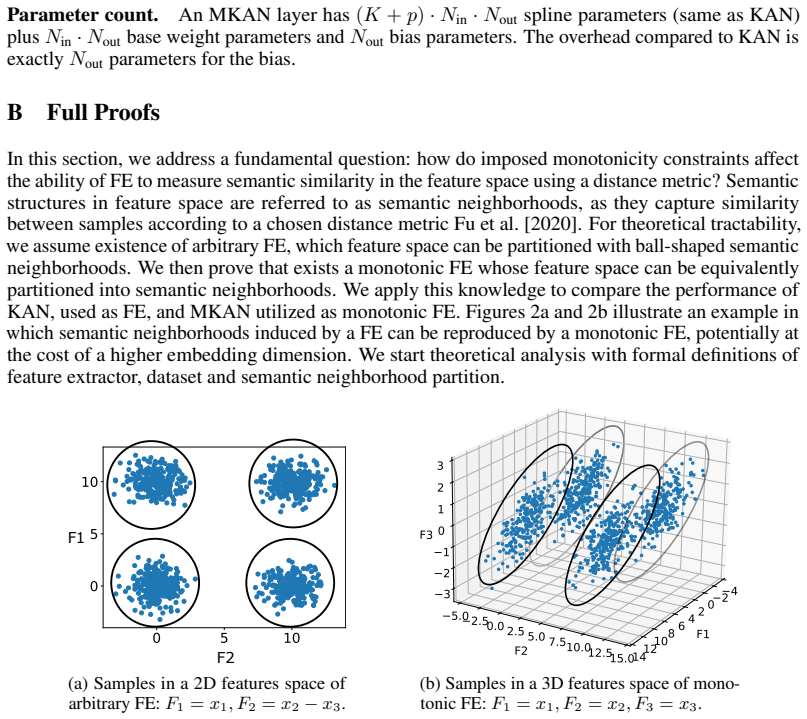
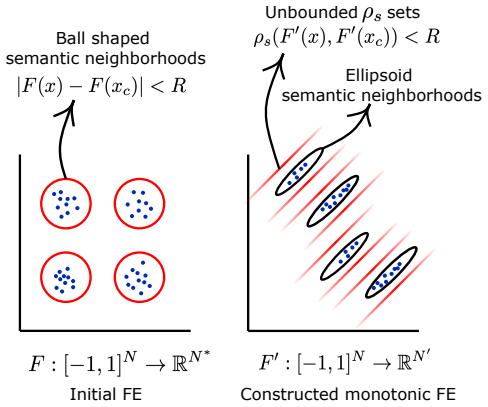
Figure 2: An example of how semantic neighborhoods in arbitrary features space can be reproduced in a monotonic one. The input data consist of three-dimensional vectors (x1, x2, x3), where x1 ∼ 0.5N(0,1) + 0.5N(10,1),x 3 ∼ N(0,1), andx 2 =r+x 3 , r∼0.5N(0,1) + 0.5N(10,1). B.1 Definitions Definition 1(Feature extractor).Afeature extractoris a C K, K >0 map...
2022
-
[12]
Therefore, the neighborhoods {C ′ i}C i=1 inF ′-space induce the same partition as{C i}C i=1 inF-space
that contains all data points from Ci and is contained within C ′ is. Therefore, the neighborhoods {C ′ i}C i=1 inF ′-space induce the same partition as{C i}C i=1 inF-space. C Additional Experimental Details C.1 Supervised Experiments In this section, we describe the MKAN configurations used in the supervised setting. An MKAN layer is specified in the for...
2024
-
[13]
Here, we also provide a short description and motivation for the datasets
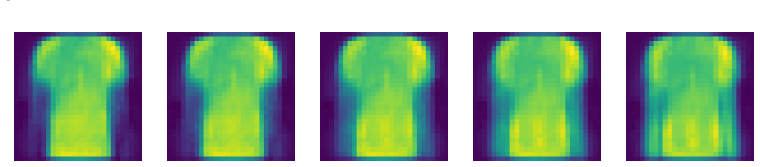
Figure 5: The figure demonstrates the evolution of the initial observation, an image of t-shirt, obtained through the MKAN decoder from trained V AE, to an image of pullover, while increasing the value of one of the latent components. Here, we also provide a short description and motivation for the datasets. We utilize MNIST, Fashion MNIST, Dry Bean dry [...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.