Agentic AI-based Framework for Mitigating Premature Diagnostic Handoff and Silent Hallucination in Healthcare Applications
Pith reviewed 2026-06-27 01:18 UTC · model grok-4.3
The pith
Multi-agent framework with OLDCARTS and entropy gates lifts diagnostic precision by 11.3 points on simulated cases.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
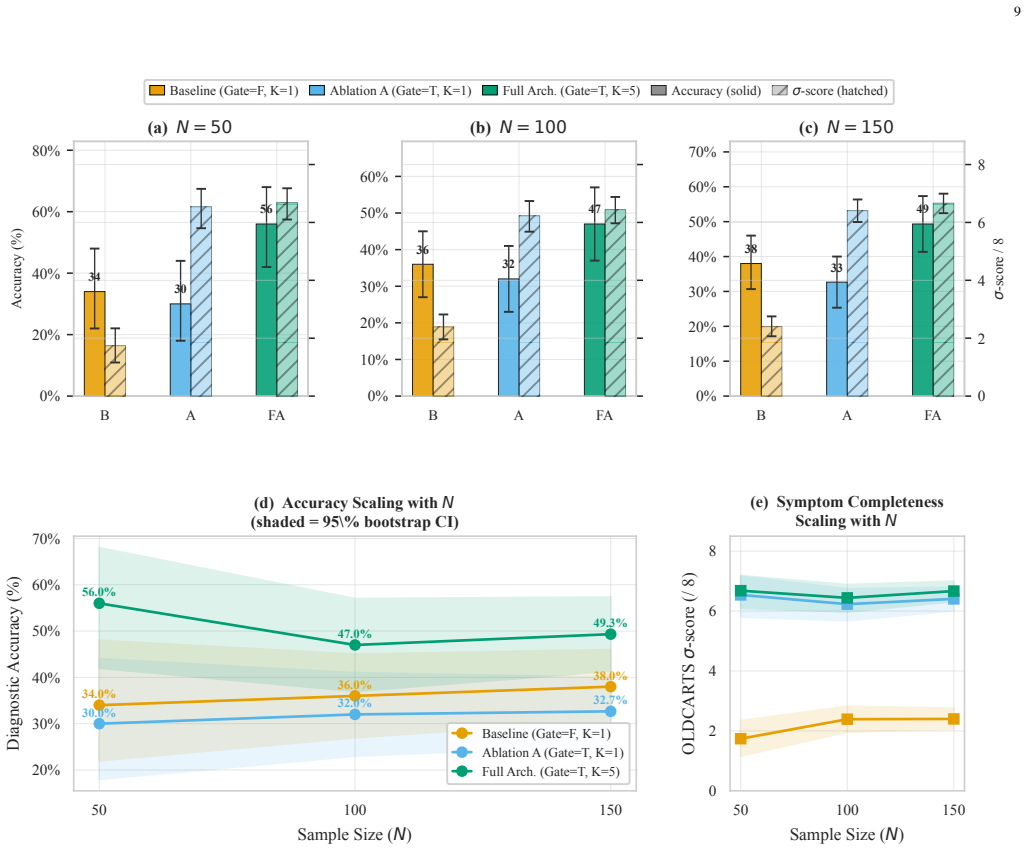
Replacing LLM-as-a-judge routing with deterministic orchestration constraints, the framework deploys a neuro-symbolic state-tracking gate that blocks diagnostic transitions until all OLDCARTS dimensions are collected and an epistemic uncertainty gate that flags high semantic entropy across five samples; on 150 simulated cases this yields 49.3 percent diagnostic precision (11.3 points above baseline) together with a negative correlation (r = -0.181) between completeness and entropy.
What carries the argument
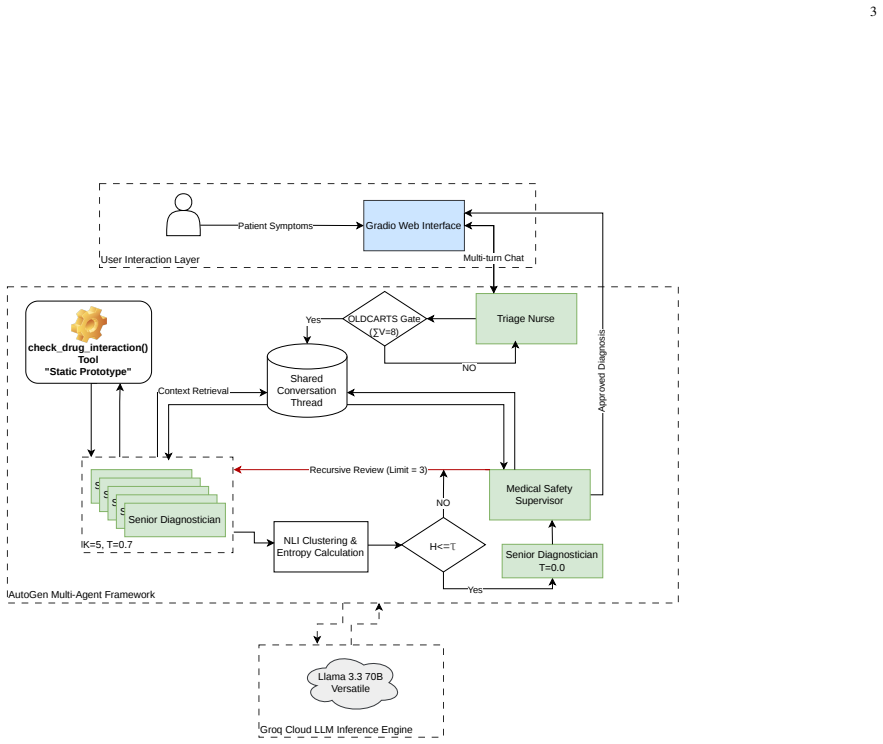
Neuro-symbolic state-tracking gate enforcing OLDCARTS completeness combined with semantic entropy quantification gate across K=5 diagnostic samples.
If this is right
- Diagnostic transitions are blocked until all eight OLDCARTS dimensions have been collected.
- Outputs showing high semantic entropy across five samples are intercepted before reaching the user.
- Higher OLDCARTS completeness is associated with lower diagnostic uncertainty.
- The combined gates produce an 11.3 percentage point gain in diagnostic precision over the baseline.
Where Pith is reading between the lines
- The same deterministic gating approach could be tested in other safety-critical conversational domains that require structured data collection before conclusions.
- Real-world clinical trials would be needed to determine whether the simulated precision and correlation results persist with human patients and physicians.
- The observed correlation suggests that simply improving information completeness may itself reduce hallucination risk even without separate entropy modeling.
Load-bearing premise
The 150 test cases generated by simulated patient agents are representative of real clinical conversations and the measured precision gain and correlation will translate to actual patients and clinicians.
What would settle it
Deploying the full framework with real patients and clinicians and measuring whether the 11.3-point precision improvement and the negative correlation between OLDCARTS completeness and semantic entropy remain present.
Figures



read the original abstract
Recent advances in Large Language Models (LLMs) and multi-agent systems have driven the rise of Agentic AI, showing promise for medical reasoning. However, open-ended conversational agents remain prone to two critical failure modes: premature diagnostic handoff and silent clinical hallucinations that may go undetected before reaching the patient. In this work, we propose a multi-agent framework that addresses both issues by replacing ``LLM-as-a-judge'' routing with deterministic orchestration constraints. The framework incorporates two safety mechanisms. First, a neuro-symbolic state-tracking gate enforces completeness of the OLDCARTS clinical protocol (Onset, Location, Duration, Character, Aggravating/Alleviating factors, Radiation, Timing, and Severity) by blocking diagnostic transitions until all required dimensions are collected. Second, an epistemic uncertainty quantification (UQ) gate computes semantic entropy (H) across K=5 independent diagnostic samples to identify and intercept divergent outputs before delivery. We evaluate the system using simulated patient agents powered by the llama-3.1-70b-instruct model on 150 test cases. The full architecture achieves 49.3% diagnostic precision, representing an absolute improvement of 11.3 percentage points over an unconstrained baseline. Additionally, we observe a statistically significant negative correlation (r = -0.181, p < 0.05) between OLDCARTS completeness (\sigma) and semantic entropy (H), suggesting that structured information gathering is associated with reduced diagnostic uncertainty.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a multi-agent framework for LLM-based medical diagnostic agents that replaces open-ended routing with two deterministic safety mechanisms: a neuro-symbolic gate enforcing completeness of the OLDCARTS clinical protocol before allowing diagnostic handoff, and an epistemic UQ gate that computes semantic entropy across K=5 diagnostic samples to intercept divergent outputs. Evaluated exclusively on 150 test cases generated by simulated patient agents powered by llama-3.1-70b-instruct, the full architecture reports 49.3% diagnostic precision (absolute gain of 11.3 pp over an unconstrained baseline) together with a statistically significant negative correlation (r = -0.181, p < 0.05) between OLDCARTS completeness (σ) and semantic entropy (H).
Significance. If the simulation faithfully reproduces real clinical dialogue distributions, the neuro-symbolic OLDCARTS gate and semantic-entropy gate would constitute a concrete, reproducible method for adding verifiable safety constraints to agentic medical systems, directly addressing two failure modes that current LLM-as-a-judge approaches leave unmitigated. The reported correlation between structured information gathering and reduced output divergence is a falsifiable empirical observation that could guide future hybrid neuro-symbolic designs.
major comments (3)
- [Evaluation] Evaluation paragraph: the 11.3 pp precision gain is reported relative to an 'unconstrained baseline' whose precise architecture, prompting strategy, and use (or non-use) of any gates is never defined, so it is impossible to determine which component of the proposed framework produces the measured improvement.
- [Evaluation] Evaluation paragraph: all 150 test cases are generated by patient agents powered by the identical llama-3.1-70b-instruct model used for the diagnostic agents, with no description of case construction, symptom-distribution statistics, human validation of realism, or cross-model checks; this untested modeling assumption is load-bearing for any claim that the observed precision or correlation will translate to interactions with actual patients and clinicians.
- [Abstract/Evaluation] Abstract and Evaluation: the semantic entropy H is computed across K=5 samples, yet the manuscript supplies neither the exact procedure for determining semantic equivalence/divergence among samples nor any variance or error bars on the 49.3 % precision figure, rendering the central numeric claims non-reproducible from the given description.
minor comments (2)
- [Abstract] Abstract: the symbols σ (OLDCARTS completeness) and H (semantic entropy) are used before any definition is supplied.
- [Abstract] Abstract: the phrase 'statistically significant' is attached to r = -0.181 without stating the exact test, degrees of freedom, or any correction for multiple comparisons.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the evaluation methodology. We address each major comment below and commit to revisions that improve clarity, reproducibility, and acknowledgment of limitations without overstating the simulation results.
read point-by-point responses
-
Referee: [Evaluation] Evaluation paragraph: the 11.3 pp precision gain is reported relative to an 'unconstrained baseline' whose precise architecture, prompting strategy, and use (or non-use) of any gates is never defined, so it is impossible to determine which component of the proposed framework produces the measured improvement.
Authors: We agree the baseline description is insufficient. In the revised manuscript we will explicitly define the unconstrained baseline as a single diagnostic agent using the identical llama-3.1-70b-instruct model and standard prompting, with neither the OLDCARTS neuro-symbolic gate nor the semantic-entropy gate applied. This will allow readers to attribute the 11.3 pp gain specifically to the two proposed safety mechanisms. revision: yes
-
Referee: [Evaluation] Evaluation paragraph: all 150 test cases are generated by patient agents powered by the identical llama-3.1-70b-instruct model used for the diagnostic agents, with no description of case construction, symptom-distribution statistics, human validation of realism, or cross-model checks; this untested modeling assumption is load-bearing for any claim that the observed precision or correlation will translate to interactions with actual patients and clinicians.
Authors: The study is deliberately conducted in a controlled simulation to isolate the effect of the deterministic gates. We will add a detailed description of case construction and the symptom-distribution statistics used to generate the 150 cases. Because human validation of realism and cross-model checks were not performed, we will insert an explicit limitations paragraph stating that generalizability to real patients and clinicians remains untested and requires future work with human subjects and heterogeneous models. We will also moderate any language implying direct clinical translation. revision: partial
-
Referee: [Abstract/Evaluation] Abstract and Evaluation: the semantic entropy H is computed across K=5 samples, yet the manuscript supplies neither the exact procedure for determining semantic equivalence/divergence among samples nor any variance or error bars on the 49.3 % precision figure, rendering the central numeric claims non-reproducible from the given description.
Authors: We accept that the semantic-equivalence procedure and statistical reporting are underspecified. The revised manuscript will include the precise algorithm used to classify semantic equivalence or divergence across the K=5 samples (including the embedding model and similarity threshold) and will report standard error or bootstrap confidence intervals around the 49.3 % precision figure computed over the 150 cases. revision: yes
Circularity Check
No circularity; empirical measurements are direct observations
full rationale
The paper presents a multi-agent framework evaluated via direct measurement on 150 simulated cases, reporting precision (49.3%), improvement over baseline (+11.3 pp), and an observed correlation (r = -0.181). No equations, fitted parameters, or self-citations are shown that reduce these quantities to inputs by construction. The OLDCARTS gate and semantic entropy gate are described as deterministic mechanisms whose effects are measured externally rather than defined in terms of the reported outcomes. This is a standard empirical evaluation without self-definitional or load-bearing circular steps.
Axiom & Free-Parameter Ledger
free parameters (1)
- K =
5
axioms (1)
- domain assumption OLDCARTS supplies a complete and sufficient set of dimensions for clinical history taking
Reference graph
Works this paper leans on
-
[1]
Triageagent: Towards better multi- agents collaborations for large language model-based clinical triage,
M. Lu, B. Ho, D. Ren, and X. Wang, “Triageagent: Towards better multi- agents collaborations for large language model-based clinical triage,” inFindings of the Association for Computational Linguistics: EMNLP 2024, 2024, pp. 5747–5764
2024
-
[2]
Exploring agentic ai in healthcare: A study on its working mechanism,
P. N. Srinivasu, G. L. Aruna Kumari, S. Ahmed, and A. Alhumam, “Exploring agentic ai in healthcare: A study on its working mechanism,” Frontiers in Medicine, vol. 12, p. 1753443, 2026
2026
-
[3]
A generalist medical language model for disease diagnosis assistance,
X. Liu, H. Liu, G. Yang, Z. Jiang, S. Cui, Z. Zhang, H. Wang, L. Tao, Y . Sun, Z. Song, T. Hong, J. Yang, T. Gao, J. Zhang, X. Li, J. Zhang, Y . Sang, Z. Yang, K. Xue, and G. Wang, “A generalist medical language model for disease diagnosis assistance,”Nature Medicine, vol. 31, no. 3, pp. 932–942, 2025
2025
-
[4]
Adapted large language models can outperform medical experts in clinical text summarization,
D. Van Veen, C. Van Uden, L. Blankemeier, J.-B. Delbrouck, A. Aali, C. Bluethgen, A. Pareek, M. Polacin, E. P. Reis, A. Seehofnerov ´a, N. Rohatgi, P. Hosamani, W. Collins, N. Ahuja, C. P. Langlotz, J. Hom, S. Gatidis, J. Pauly, and A. S. Chaudhari, “Adapted large language models can outperform medical experts in clinical text summarization,” Nature Medic...
2024
-
[5]
Radgpt: A system based on a large language model that generates sets of patient-centered materials to explain radiology report information,
S. E. Herwaldet al., “Radgpt: A system based on a large language model that generates sets of patient-centered materials to explain radiology report information,”Journal of the American College of Radiology, vol. 22, no. 9, pp. 1050–1059, 2025
2025
-
[6]
Mapping the susceptibility of large language models to medical misinformation across clinical notes and social media: a cross- sectional benchmarking analysis,
M. Omaret al., “Mapping the susceptibility of large language models to medical misinformation across clinical notes and social media: a cross- sectional benchmarking analysis,”The Lancet Digital Health, vol. 8, no. 1, p. 100949, 2025
2025
-
[7]
Bickley and P
L. Bickley and P. G. Szilagyi,Bates’ Guide to Physical Examination and History-Taking. Lippincott Williams & Wilkins, 2012
2012
-
[8]
What disease does this patient have? a large-scale open domain question answering dataset from medical exams,
D. Jin, E. Pan, N. Oufattole, W.-H. Weng, H. Fang, and P. Szolovits, “What disease does this patient have? a large-scale open domain question answering dataset from medical exams,”Applied Sciences, vol. 11, no. 14, p. 6421, 2021
2021
-
[9]
Towards expert-level medical question answering with large language models,
K. Singhalet al., “Towards expert-level medical question answering with large language models,” 2023
2023
-
[10]
Capabilities of GPT-4 on Medical Challenge Problems
H. Nori, N. King, S. M. McKinney, D. Carignan, and E. Horvitz, “Capabilities of GPT-4 on medical challenge problems,”arXiv preprint arXiv:2303.13375, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
Conversational health agents: A personalized LLM- powered agent framework,
M. Abbasianet al., “Conversational health agents: A personalized LLM- powered agent framework,” 2023
2023
-
[12]
Judging LLM-as-a-judge with MT-Bench and chat- bot arena,
L. Zhenget al., “Judging LLM-as-a-judge with MT-Bench and chat- bot arena,” inAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[13]
AutoGen: Enabling next-gen LLM applications via multi-agent conversation framework,
Microsoft Research, “AutoGen: Enabling next-gen LLM applications via multi-agent conversation framework,” https://autogen-ai.github.io, 2024
2024
-
[14]
L. Kuhn, Y . Gal, and S. Farquhar, “Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation,” inProceedings of the International Conference on Learning Represen- tations (ICLR), 2023, arXiv:2302.09664
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
DeBERTaV3: Improving DeBERTa using ELECTRA-style pre-training with gradient-disentangled embedding sharing,
P. Heet al., “DeBERTaV3: Improving DeBERTa using ELECTRA-style pre-training with gradient-disentangled embedding sharing,” 2021
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.