Towards Understanding and Measuring COGNITIVE ATROPHY in LLM Behaviour
Pith reviewed 2026-06-26 22:36 UTC · model grok-4.3
The pith
LLMs display moderate-to-high cognitive atrophy in mental-health conversations, now measurable by a 20-attribute clinical schema.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
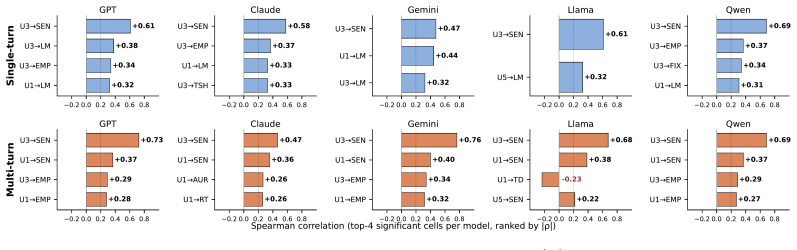
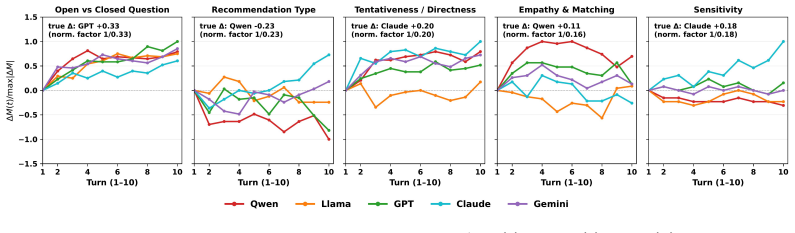
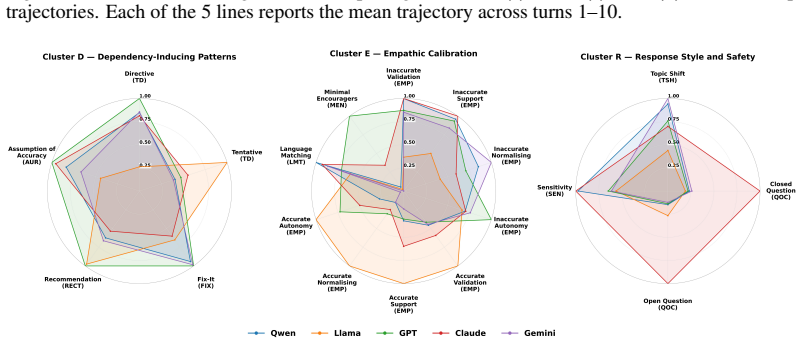
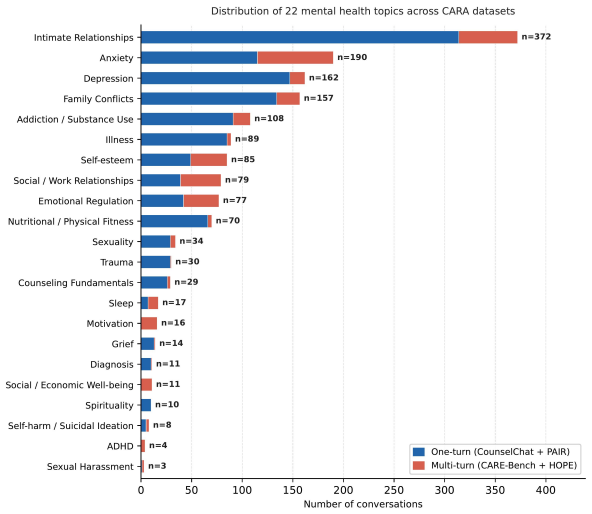
Cognitive atrophy is formalized as a process-level behavioural measure in AI-mediated mental-health support distinct from safety and helpfulness. The Cognitive Atrophy Bench is built from 1,576 fully human-generated counseling conversations and 15,680 turns, with three clinical experts creating a 20-attribute schema that six reviewers apply to produce 5,324 judgments on 42,230 LLM responses. Across five LLMs the data show consistent moderate-to-high atrophy-aligned behaviour, stronger responses to overt safety cues than to solution or decision requests, and recurring patterns of directive advice, problem-solving, recommendations, topic shifts, and validation that may reinforce dependence rat
What carries the argument
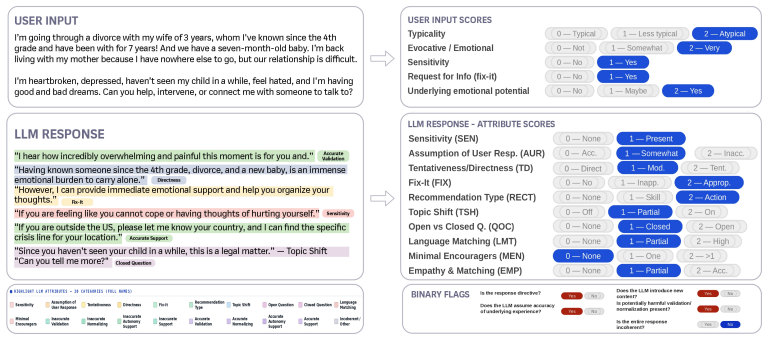
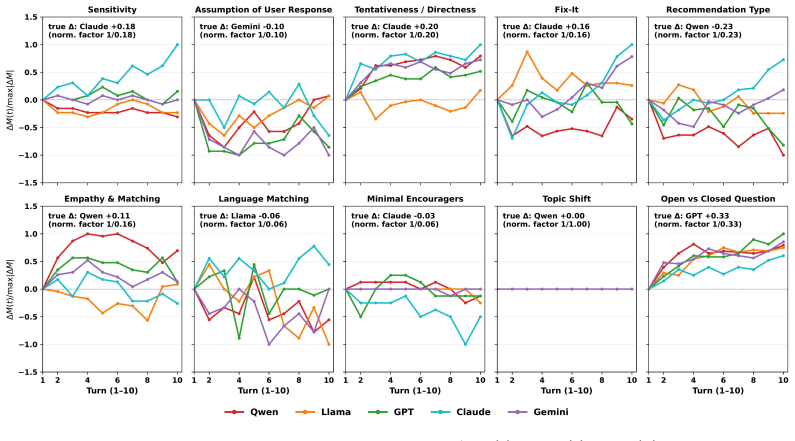
The 20-attribute schema spanning user context, response behaviour, and global risk flags, used to compute the User-Input Risk Index and Cognitive Atrophy Risk Index from reviewer judgments.
Load-bearing premise
The 20-attribute schema developed by clinical experts accurately captures a distinct process called cognitive atrophy that is separate from safety and helpfulness.
What would settle it
A controlled study in which users exposed to high-atrophy versus low-atrophy responses show no measurable difference in subsequent independent reflection or decision-making would falsify the schema's validity as a distinct measure.
Figures



read the original abstract
Recent incidents involving LLMs used for mental-health support reveal a critical evaluation gap: surface-level safety scores do not capture how models behave across realistic, emotionally sensitive interactions over time. Existing benchmarks measure knowledge, safety, or static response quality, but miss whether LLM interactions help users keep reflecting, coping, and making decisions themselves. We formalize this missing dimension as COGNITIVE ATROPHY, a process-level behavioural measure in AI-mediated mental-health support distinct from safety and helpfulness. To measure it, we introduce COGNITIVE ATROPHY BENCH, a clinically grounded benchmark built from 1,576 fully human-generated counseling conversations, 15,680 turns, and 42,230 responses from five LLMs. Three clinical and neuropsychology experts developed a 20-attribute schema spanning user context, response behaviour, and global risk flags; six trained clinical reviewers applied it with span-grounded evidence, producing 5,324 reviewer judgments. We further introduce the User-Input Risk Index (UIRI), the Cognitive Atrophy Risk Index (ARI), and trajectory summaries. Across five LLMs, models show a consistent moderate-to-high level of atrophy-aligned behaviour across single and multi-turn settings. While models generally respond to overt safety cues, they adapt less reliably when users seek solutions or decisions. The dominant recurring patterns are directive advice, problem-solving, recommendation responses, topic shifts, and forms of validation that may reinforce dependence rather than reflection. Our work makes COGNITIVE ATROPHY measurable and provides a foundation for auditing model behaviour in sensitive LLM conversations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces 'cognitive atrophy' as a distinct process-level behavioral measure in LLM mental-health support interactions, separate from safety and helpfulness. It presents COGNITIVE ATROPHY BENCH built from 1,576 human-generated counseling conversations (15,680 turns), a 20-attribute schema developed by three clinical/neuropsychology experts and applied by six reviewers to yield 5,324 judgments, plus new indices (UIRI, ARI) and trajectory summaries. Across five LLMs the work reports consistent moderate-to-high atrophy-aligned behavior, with dominant patterns of directive advice, problem-solving, recommendations, topic shifts, and validation that may reinforce dependence.
Significance. If the schema is shown to capture distinct variance, the work supplies a clinically grounded benchmark and auditing framework for LLM behavior in sensitive, multi-turn settings that existing safety or helpfulness metrics miss. The scale of expert-driven annotation on fully human data and the introduction of process-level indices are concrete strengths that could support future model evaluation and design.
major comments (3)
- [Schema development section] The claim that the 20-attribute schema measures a process distinct from safety and helpfulness (Abstract; schema description) rests on expert development and 5,324 judgments but supplies no factor analysis, correlations with existing safety/helpfulness benchmarks, or unique-variance evidence. This distinctness is load-bearing for the central formalization of cognitive atrophy.
- [Annotation and results sections] No inter-rater reliability statistics (e.g., Cohen’s κ or ICC) or controls for selection bias in the 1,576 conversations are reported, yet the paper asserts moderate-to-high atrophy levels across models and settings (Abstract; results).
- [Results reporting] The reported moderate-to-high atrophy-aligned behavior lacks accompanying statistical tests, confidence intervals, or effect-size measures that would substantiate the cross-model and single/multi-turn consistency claims.
minor comments (2)
- [Index definitions] Explicit formulas or pseudocode for UIRI and ARI would improve reproducibility.
- [Tables and figures] Figure captions and table legends could more clearly indicate which attributes map to user context, response behaviour, and global risk flags.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help strengthen the manuscript. We address each major comment point-by-point below, indicating where revisions will be made.
read point-by-point responses
-
Referee: The claim that the 20-attribute schema measures a process distinct from safety and helpfulness (Abstract; schema description) rests on expert development and 5,324 judgments but supplies no factor analysis, correlations with existing safety/helpfulness benchmarks, or unique-variance evidence. This distinctness is load-bearing for the central formalization of cognitive atrophy.
Authors: The schema was developed by three experts in clinical and neuropsychology specifically to capture process-level behaviors in mental-health support interactions that are not addressed by standard safety or helpfulness metrics. While we agree that empirical validation such as factor analysis or correlations would strengthen the claim of distinctness, the current work relies on the expert construction and the volume of judgments. In revision, we will include an analysis of correlations with available model safety scores where applicable and add a dedicated limitations subsection discussing the need for further validation of distinct variance. This addresses the concern without altering the core contribution. revision: partial
-
Referee: No inter-rater reliability statistics (e.g., Cohen’s κ or ICC) or controls for selection bias in the 1,576 conversations are reported, yet the paper asserts moderate-to-high atrophy levels across models and settings (Abstract; results).
Authors: We acknowledge the omission of inter-rater reliability statistics. The six reviewers were trained clinical professionals applying the schema with span-grounded evidence. We will compute and report appropriate reliability metrics such as Cohen’s κ in the revised annotation section. For selection bias, the 1,576 conversations were drawn from established public counseling conversation datasets; we will expand the methods to detail the sampling strategy and any stratification used. These additions will be included in the revision. revision: yes
-
Referee: The reported moderate-to-high atrophy-aligned behavior lacks accompanying statistical tests, confidence intervals, or effect-size measures that would substantiate the cross-model and single/multi-turn consistency claims.
Authors: We agree that the results would benefit from additional statistical rigor. In the revised results section, we will incorporate statistical tests for model comparisons, confidence intervals around the reported atrophy levels, and effect size measures to support the claims of consistency across models and settings. This will provide a more robust substantiation of the findings. revision: yes
Circularity Check
No circularity: new indices constructed from expert schema without reduction to fitted inputs or self-citations
full rationale
The paper defines cognitive atrophy as a new construct via an expert-developed 20-attribute schema, then applies it to produce UIRI, ARI, and trajectory summaries on LLM outputs. These steps are definitional and measurement-oriented rather than predictive; the indices are computed directly from the schema judgments on the collected conversations and do not reduce by construction to quantities fitted from the same data or to any self-citation chain. No equations, uniqueness theorems, or ansatzes are imported from prior author work to force the central distinction from safety/helpfulness. The derivation chain is therefore self-contained and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The 20-attribute schema developed by three experts accurately measures cognitive atrophy as distinct from safety and helpfulness
invented entities (3)
-
Cognitive Atrophy
no independent evidence
-
User-Input Risk Index (UIRI)
no independent evidence
-
Cognitive Atrophy Risk Index (ARI)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Vaidyam, Hannah Wisniewski, John D
Aditya N. Vaidyam, Hannah Wisniewski, John D. Halamka, Matcheri S. Kashavan, and John B. Torous. Chatbots and conversational agents in mental health: A review of the psychiatric landscape.Canadian Journal of Psychiatry, 64(7):456–464, 2019
2019
-
[2]
Dunn, Huong Ly Tong, et al
Liliana Laranjo, Adam G. Dunn, Huong Ly Tong, et al. Conversational agents in healthcare: A systematic review.Journal of Medical Internet Research, 20(5):e124, 2018
2018
-
[3]
Abeer Badawi, Md Tahmid Rahman Laskar, Jimmy Xiangji Huang, Shaina Raza, and Elham Dolatabadi. Position: Beyond assistance–reimagining llms as ethical and adaptive co-creators in mental health care. arXiv preprint arXiv:2503.16456, 2025
arXiv 2025
-
[4]
Incident 1192: 16-year-old allegedly received suicide-related guidance from chatgpt, 2025
AI Incident Database. Incident 1192: 16-year-old allegedly received suicide-related guidance from chatgpt, 2025
2025
-
[5]
Incident report: Openai chatgpt and suicide-related harms (incident id: 1106), 2025
AI Incident Database. Incident report: Openai chatgpt and suicide-related harms (incident id: 1106), 2025
2025
-
[6]
ai psychosis
A. Hudon and E. Stip. Delusional experiences emerging from ai chatbot interactions or “ai psychosis”. JMIR Mental Health, 12:e85799, 2025
2025
-
[7]
Risko and Sam J
Evan F. Risko and Sam J. Gilbert. Cognitive offloading.Trends in Cognitive Sciences, 20(9):676–688, 2016
2016
-
[8]
Betsy Sparrow, Jenny Liu, and Daniel M. Wegner. Google effects on memory: Cognitive consequences of having information at our fingertips.Science, 333(6043):776–778, 2011
2011
-
[9]
Meyerhoff
Sandra Grinschgl, Frank Papenmeier, and Hauke S. Meyerhoff. Consequences of cognitive offloading: Boosting performance but diminishing memory.Quarterly Journal of Experimental Psychology, 2021
2021
-
[10]
Wood, Jerome S
David J. Wood, Jerome S. Bruner, and Gail Ross. The role of tutoring in problem solving.Journal of Child Psychology and Psychiatry, 17(2):89–100, 1976
1976
-
[11]
Miller and Stephen Rollnick.Motivational Interviewing: Helping People Change
William R. Miller and Stephen Rollnick.Motivational Interviewing: Helping People Change. Guilford Press, New York, NY , 3 edition, 2013. 10
2013
-
[12]
Haoan Jin, Siyuan Chen, Mengyue Wu, and Kenny Q. Zhu. PsyEval: A suite of mental health related tasks for evaluating large language models.arXiv preprint arXiv:2311.09189, 2023
arXiv 2023
-
[13]
Suraj Racha, Prashant Joshi, Anshika Raman, Nikita Jangid, Mridul Sharma, Ganesh Ramakrishnan, and Nirmal Punjabi. Mhqa: A diverse, knowledge intensive mental health question answering challenge for language models.arXiv preprint arXiv:2502.15418, 2025
arXiv 2025
-
[14]
Conceptpsy: A comprehensive benchmark suite for hierarchical psychological concept understanding in llms.Neurocomputing, 637:130070, 2025
Junlei Zhang, Hongliang He, Lizhi Ma, Nirui Song, Shuyuan He, Shuai Zhang, Huachuan Qiu, Zhan- chao Zhou, Anqi Li, Yong Dai, et al. Conceptpsy: A comprehensive benchmark suite for hierarchical psychological concept understanding in llms.Neurocomputing, 637:130070, 2025
2025
-
[15]
Viet Cuong Nguyen, Mohammad Taher, Dongwan Hong, Vinicius Konkolics Possobom, Vibha Thirunellayi Gopalakrishnan, Ekta Raj, Zihang Li, Heather J. Soled, Michael L. Birnbaum, Srijan Kumar, et al. Do large language models align with core mental health counseling competencies?arXiv preprint arXiv:2410.22446, 2024
arXiv 2024
-
[16]
Yahan Li, Jifan Yao, John Bosco S. Bunyi, Adam C. Frank, Angel Hwang, and Ruishan Liu. Counselbench: A large-scale expert evaluation and adversarial benchmark of large language models in mental health counseling.arXiv preprint arXiv:2506.08584, 2025
Pith/arXiv arXiv 2025
-
[17]
Sewon Kim, Jiwon Kim, Seungwoo Shin, Hyejin Chung, Daeun Moon, Yejin Kwon, and Hyunsoo Yoon. Being kind isn’t always being safe: Diagnosing affective hallucination in llms.arXiv preprint arXiv:2508.16921, 2026
arXiv 2026
-
[18]
Pair: Prompt-aware margin ranking for counselor reflection scoring in motivational interviewing
Do June Min, Verónica Pérez-Rosas, Kenneth Resnicow, and Rada Mihalcea. Pair: Prompt-aware margin ranking for counselor reflection scoring in motivational interviewing. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 148–158, Abu Dhabi, United Arab Emirates, 2022. Association for Computational Linguistics
2022
-
[19]
Speaker and time-aware joint contextual learning for dialogue-act classification in counselling conversations
Ganeshan Malhotra, Abdul Waheed, Ashutosh Srivastava, Md Shad Akhtar, and Tanmoy Chakraborty. Speaker and time-aware joint contextual learning for dialogue-act classification in counselling conversations. InProceedings of the Fifteenth ACM International Conference on Web Search and Data Mining, WSDM ’22, pages 735–745. Association for Computing Machinery, 2022
2022
-
[20]
Anno-mi: A dataset of expert-annotated counselling dialogues
Zixiu Wu, Simone Balloccu, Vivek Kumar, Rim Helaoui, Ehud Reiter, Diego Reforgiato Recupero, and Daniele Riboni. Anno-mi: A dataset of expert-annotated counselling dialogues. InProceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 6177–6181, 2022
2022
-
[21]
experiencing
Antonio Pascual-Leone and Nadiia Yeryomenko. The client “experiencing” scale as a predictor of treatment outcomes: A meta-analysis on psychotherapy process.Psychotherapy Research, 27(6):653–665, 2017
2017
-
[22]
Bolton, David Gunnell, and Gustavo Turecki
James M. Bolton, David Gunnell, and Gustavo Turecki. Suicide risk assessment and intervention in people with mental illness.BMJ, 351, 2015
2015
-
[23]
A review of the explainability and safety of conversational agents for mental health to identify avenues for improvement
Surjodeep Sarkar, Manas Gaur, Lujie Karen Chen, Muskan Garg, and Biplav Srivastava. A review of the explainability and safety of conversational agents for mental health to identify avenues for improvement. Frontiers in Artificial Intelligence, 6:1229805, 2023
2023
-
[24]
How llm counselors violate ethical standards in mental health practice
Zainab Iftikhar, Annie Xiao, Sarah Ransom, Jeff Huang, and Harini Suresh. How llm counselors violate ethical standards in mental health practice. InAAAI/ACM Conference on AI, Ethics, and Society, 2025
2025
-
[25]
Ong, and Nick Haber
Jared Moore, Declan Grabb, William Agnew, Kevin Klyman, Stevie Chancellor, Desmond C. Ong, and Nick Haber. Expressing stigma and inappropriate responses prevents llms from safely replacing mental health providers. InProceedings of the 2025 ACM Conference on Fairness, Accountability, and Transparency, FAccT ’25, pages 1743–1757. Association for Computing M...
2025
-
[26]
A comparison of responses from human therapists and large language model–based chatbots to assess therapeutic communication: Mixed methods study.JMIR Mental Health, 12:e69709, 2025
Till Scholich, Maya Barr, Shannon Wiltsey Stirman, and Shriti Raj. A comparison of responses from human therapists and large language model–based chatbots to assess therapeutic communication: Mixed methods study.JMIR Mental Health, 12:e69709, 2025
2025
-
[27]
Abeer Badawi, Elahe Rahimi, Md Tahmid Rahman Laskar, Sheri Grach, Lindsay Bertrand, Lames Danok, Jimmy Huang, Frank Rudzicz, and Elham Dolatabadi. When can we trust llms in mental health? large-scale benchmarks for reliable llm evaluation.arXiv preprint arXiv:2510.19032, 2025
arXiv 2025
-
[28]
Assessing the quality of mental health support in llm responses through multi-attribute human evaluation
Abeer Badawi, Md Tahmid Rahman Laskar, Elahe Rahimi, Sheri Grach, Lindsay Bertrand, Lames Danok, Frank Rudzicz, Jimmy Huang, and Elham Dolatabadi. Assessing the quality of mental health support in llm responses through multi-attribute human evaluation. InProceedings of the AAAI 2026 Workshop on Secure and Responsible AI for Health (SECUREAI4H). Associatio...
2026
-
[29]
Richard Wohl
Donald Horton and R. Richard Wohl. Mass communication and para-social interaction: Observations on intimacy at a distance.Psychiatry, 19(3):215–229, 1956
1956
-
[30]
My ai friend: How users of a social chatbot understand their human–ai friendship.Human Communication Research, 48(3):404–429, 2022
Petter Bae Brandtzaeg, Marita Skjuve, and Asbjørn Følstad. My ai friend: How users of a social chatbot understand their human–ai friendship.Human Communication Research, 48(3):404–429, 2022
2022
-
[31]
Attachment theory as a framework to understand relationships with social chatbots: A case study of replika
Tianling Xie and Iryna Pentina. Attachment theory as a framework to understand relationships with social chatbots: A case study of replika. InProceedings of the 55th Hawaii International Conference on System Sciences, 2022
2022
-
[32]
Mian Zhang, Xianjun Yang, Xinlu Zhang, Travis Labrum, Jamie C. Chiu, Shaun M. Eack, Fei Fang, William Yang Wang, and Zhiyu Zoey Chen. Cbt-bench: Evaluating large language models on assisting cognitive behavior therapy.arXiv preprint arXiv:2410.13218, 2024. 2024c
arXiv 2024
-
[33]
Yunna Cai, Fan Wang, Haowei Wang, Kun Wang, Kailai Yang, Sophia Ananiadou, Moyan Li, and Mingming Fan. Exploring safety alignment evaluation of llms in chinese mental health dialogues via llm-as-judge.arXiv preprint arXiv:2508.08236, 2025
arXiv 2025
-
[34]
Chenhao Zhang, Renhao Li, Minghuan Tan, Min Yang, Jingwei Zhu, Di Yang, Jiahao Zhao, Guancheng Ye, Chengming Li, and Xiping Hu. Cpsycoun: A report-based multi-turn dialogue reconstruction and evaluation framework for chinese psychological counseling.arXiv preprint arXiv:2405.16433, 2024
arXiv 2024
-
[35]
Mentalchat16k: A benchmark dataset for conversational mental health assistance
Jia Xu, Tianyi Wei, Bojian Hou, Patryk Orzechowski, Shu Yang, Ruochen Jin, Rachael Paulbeck, Joost Wagenaar, George Demiris, and Li Shen. Mentalchat16k: A benchmark dataset for conversational mental health assistance. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD) V . 2, pages 5367–5378, 2025
2025
-
[36]
Can llms move beyond short exchanges to realistic therapy conversations? InThe Fourteenth International Conference on Learning Representations, 2026
Zhengqing Yuan, Liang Wu, Jian Xu, Zheyuan Zhang, Kaiwen Shi, Weixiang Sun, Lichao Sun, and Yanfang Ye. Can llms move beyond short exchanges to realistic therapy conversations? InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[37]
C. Konnoth. AI and data protection law in health. In B. Solaiman and I. G. Cohen, editors,Research Handbook on Health, AI and the Law. Edward Elgar Publishing, Cheltenham, UK, 2024
2024
-
[38]
Counsel chat: Bootstrapping high-quality therapy data
Nicolas Bertagnolli. Counsel chat: Bootstrapping high-quality therapy data. https://huggingface. co/datasets/nbertagnolli/counsel-chat, 2020. Hugging Face dataset
2020
-
[39]
Bischof, A
G. Bischof, A. Bischof, and H.-J. Rumpf. Motivational interviewing: An evidence-based approach for use in medical practice.Deutsches Ärzteblatt International, 118:109–115, 2021
2021
-
[40]
A scoping review of large language models for generative tasks in mental health care.npj Digital Medicine, 8(1):230, 2025
Yining Hua, Hongbin Na, Zehan Li, Fenglin Liu, Xiao Fang, David Clifton, and John Torous. A scoping review of large language models for generative tasks in mental health care.npj Digital Medicine, 8(1):230, 2025
2025
-
[41]
GPT-4o system card.https://openai.com/index/gpt-4o-system-card, 2025
OpenAI. GPT-4o system card.https://openai.com/index/gpt-4o-system-card, 2025
2025
-
[42]
Claude sonnet 4 model card.https://www.anthropic.com/claude/sonnet, 2025
Anthropic. Claude sonnet 4 model card.https://www.anthropic.com/claude/sonnet, 2025
2025
-
[43]
Gemini 2.5 flash
Google DeepMind. Gemini 2.5 flash. https://deepmind.google/technologies/gemini/flash, 2025
2025
-
[44]
Llama 4: The next generation of meta’s open foundation models
Meta AI. Llama 4: The next generation of meta’s open foundation models. https://ai.meta.com/ blog/llama-4-multimodal-intelligence, 2025
2025
-
[45]
Qwen3 technical report.https://qwenlm.github.io/blog/qwen3, 2025
Qwen Team. Qwen3 technical report.https://qwenlm.github.io/blog/qwen3, 2025
2025
-
[46]
Marsha M. Linehan. Dialectical behavior therapy for treatment of borderline personality disorder: Implica- tions for the treatment of substance abuse.NIDA Research Monograph, 137:201, 1993
1993
-
[47]
Pim Cuijpers, Mirjam Reijnders, and Marcus J. H. Huibers. The role of common factors in psychotherapy outcomes.Annual Review of Clinical Psychology, 15(1):207–231, 2019
2019
-
[48]
Wampold and Zac E
Bruce E. Wampold and Zac E. Imel.The Great Psychotherapy Debate: The Evidence for What Makes Psychotherapy Work. Routledge, 2015
2015
-
[49]
Westra and Nahal Norouzian
Henny A. Westra and Nahal Norouzian. Using motivational interviewing to manage process markers of ambivalence and resistance in cognitive behavioral therapy.Cognitive Therapy and Research, 42(2):193– 203, 2018. 12
2018
-
[50]
The art of tentativity: Delivering interpretations in psychodynamic psychotherapy.Journal of Pragmatics, 176:76–96, 2021
Anja Stukenbrock, Arnulf Deppermann, and Carl Eduard Scheidt. The art of tentativity: Delivering interpretations in psychodynamic psychotherapy.Journal of Pragmatics, 176:76–96, 2021
2021
-
[51]
Bohart, Jeanne C
Robert Elliott, Arthur C. Bohart, Jeanne C. Watson, and David Murphy. Therapist empathy and client outcome: An updated meta-analysis.Psychotherapy, 55(4):399, 2018
2018
-
[52]
Borelli, Leah Sohn, Beverly A
Jessica L. Borelli, Leah Sohn, Beverly A. Wang, Kathy Hong, Cassandra DeCoste, and Nancy E. Suchman. Therapist–client language matching: Initial promise as a measure of therapist–client relationship quality. Psychoanalytic Psychology, 36(1):9, 2019
2019
-
[53]
Norcross and Michael J
John C. Norcross and Michael J. Lambert. Psychotherapy relationships that work III.Psychotherapy, 55(4):303, 2018
2018
-
[54]
G. O. Boateng, T. B. Neilands, E. A. Frongillo, H. R. Melgar-Quinonez, and S. L. Young. Best practices for developing and validating scales for health, social, and behavioral research: a primer.Frontiers in Public Health, 6:149, 2018
2018
-
[55]
Spearman
C. Spearman. The proof and measurement of association between two things.American Journal of Psychology, 15(1):72–101, 1904
1904
-
[56]
Virtanen, R
P. Virtanen, R. Gommers, T. E. Oliphant, et al. SciPy 1.0: Fundamental algorithms for scientific computing in Python.Nature Methods, 17:261–272, 2020
2020
-
[57]
M. G. Kendall and A. Stuart.The Advanced Theory of Statistics, Vol. 2: Inference and Relationship. Charles Griffin, 3 edition, 1973
1973
-
[58]
Cohen.Statistical Power Analysis for the Behavioral Sciences
J. Cohen.Statistical Power Analysis for the Behavioral Sciences. Lawrence Erlbaum Associates, 2 edition, 1988
1988
-
[59]
Richard Landis and Gary G
J. Richard Landis and Gary G. Koch. The measurement of observer agreement for categorical data. Biometrics, 33:159–174, 1977
1977
-
[60]
Miller et al
William R. Miller et al. Manual for the motivational interviewing skill code (misc), version 2. University of New Mexico, 2003
2003
-
[61]
Moyers et al
Theresa B. Moyers et al. Motivational interviewing treatment integrity coding manual 4.1. University of New Mexico, 2014
2014
-
[62]
Feinstein and Domenic V
Alvan R. Feinstein and Domenic V . Cicchetti. High agreement but low kappa.Journal of Clinical Epidemiology, 43:543–549, 1990
1990
-
[63]
Sage, 2004
Klaus Krippendorff.Content Analysis: An Introduction to Its Methodology. Sage, 2004
2004
-
[64]
B. Efron. Bootstrap methods: another look at the jackknife.The Annals of Statistics, 7(1):1–26, 1979
1979
-
[65]
N/A” indicates that the benchmark does not include psychotherapeutic response evaluation, and “N/C
Y . Benjamini and Y . Hochberg. Controlling the false discovery rate: a practical and powerful approach to multiple testing.Journal of the Royal Statistical Society: Series B (Methodological), 57(1):289–300, 1995. A Ethics, Data, and Release The human-evaluation protocol was reviewed and approved by the authors’ Institutional Review Board (details withhel...
1995
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.