Knowledge Reutilization in Meta-Reinforcement Learning
Pith reviewed 2026-06-27 01:00 UTC · model grok-4.3
The pith
A meta-RL framework learns task knowledge on a simplified agent and reuses it on heterogeneous robots through a semantic interface and temporal adaptor.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By training task-level knowledge on a dynamics-simplified agent with a Bayesian non-parametric prior over latent modes and a high-level policy that produces magnitude guidance, then bridging to heterogeneous agents via a semantic-magnitude interface and lightweight temporal adaptor that produces temporally aligned subgoals, the framework reuses frozen meta-knowledge across embodiments and yields 94.75 to 99.79 percent lower final-step tracking error with comparable deployment performance using only about 23.8 percent of the interaction data required by recent baselines.
What carries the argument
The semantic-magnitude interface and lightweight temporal adaptor, which convert frozen meta-knowledge from the simplified agent into temporally aligned subgoals for embodiment-specific controllers.
If this is right
- Task semantics become reusable across agents whose dynamics and morphology differ from the training agent.
- Sample efficiency improves because only the low-level controller needs embodiment-specific training after the meta-knowledge is frozen.
- High-level magnitude guidance can be generated once and supplied to multiple low-level controllers without retraining the task model.
- Bayesian non-parametric organization of task modes supports open-ended addition of new tasks without fixed task counts.
Where Pith is reading between the lines
- The same interface pattern might allow transfer between simulation and real hardware if the adaptor can absorb sensor and actuator differences.
- Training the meta-knowledge on even simpler proxy dynamics could further reduce the cost of acquiring reusable task structure.
- The separation of task modes from control might make it easier to inspect or edit learned behaviors at the subgoal level.
Load-bearing premise
The semantic-magnitude interface and lightweight temporal adaptor can convert frozen meta-knowledge from a dynamics-simplified agent into temporally aligned subgoals that work effectively for heterogeneous agents without substantial information loss or performance degradation.
What would settle it
A replication on new locomotion agents in which the transferred subgoals produce final tracking error reduction below 50 percent or require more than 50 percent of baseline interaction data would falsify the central performance claim.
Figures



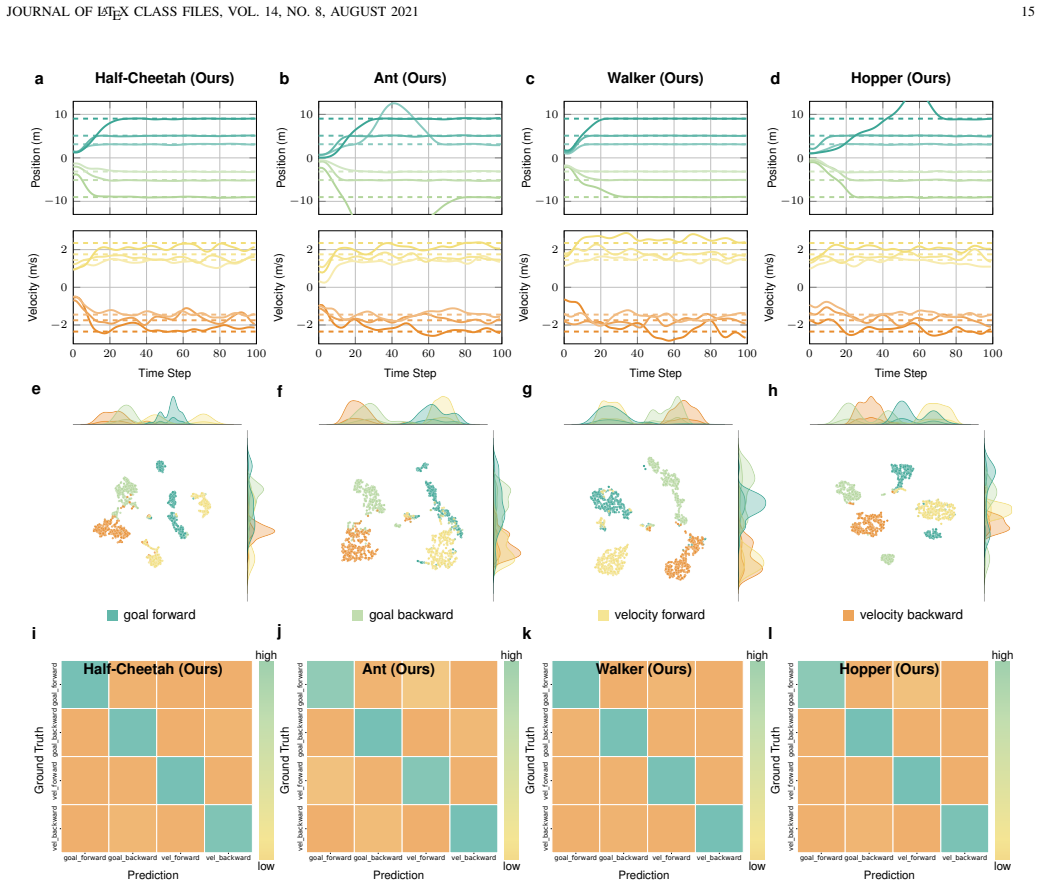
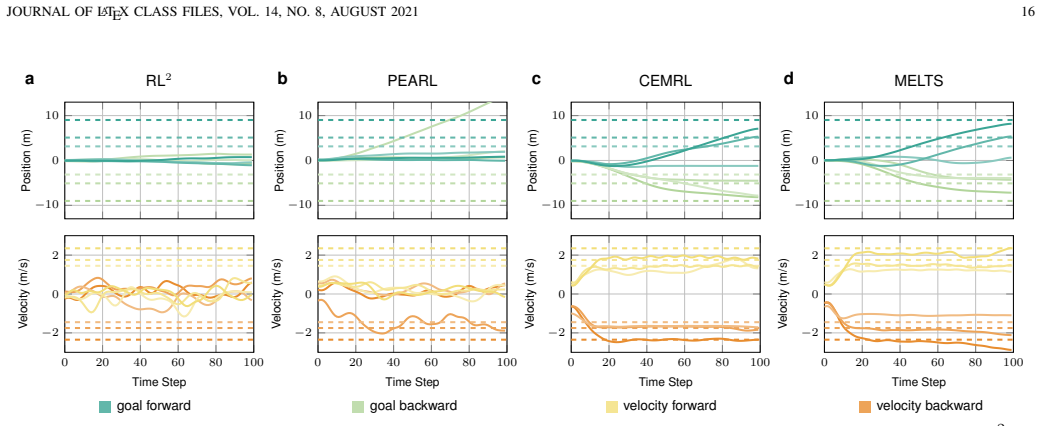
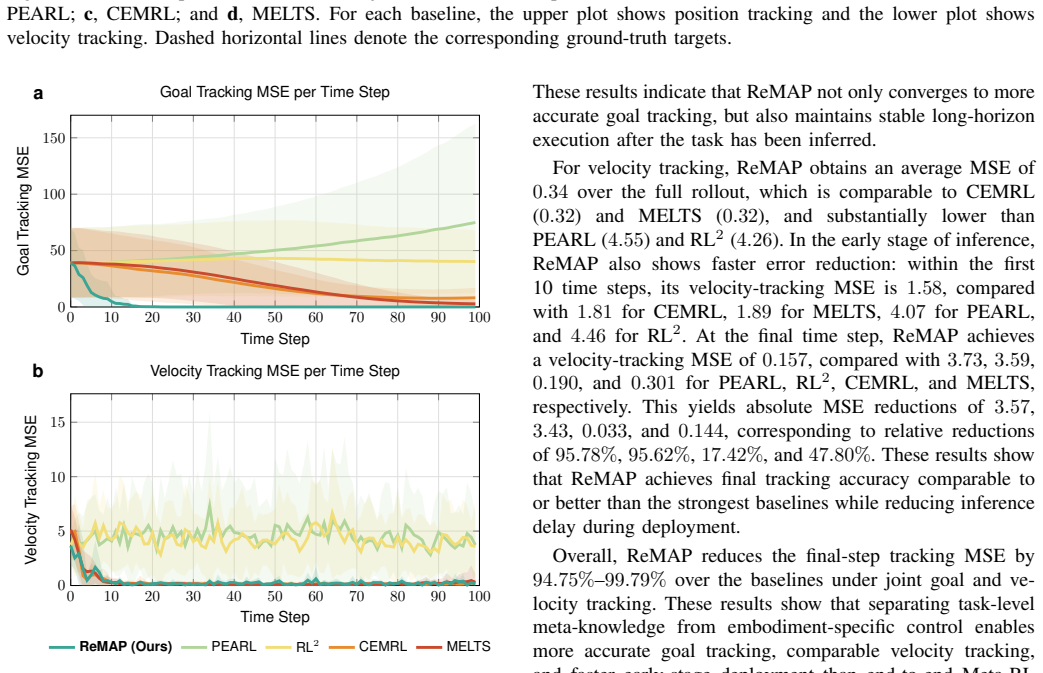
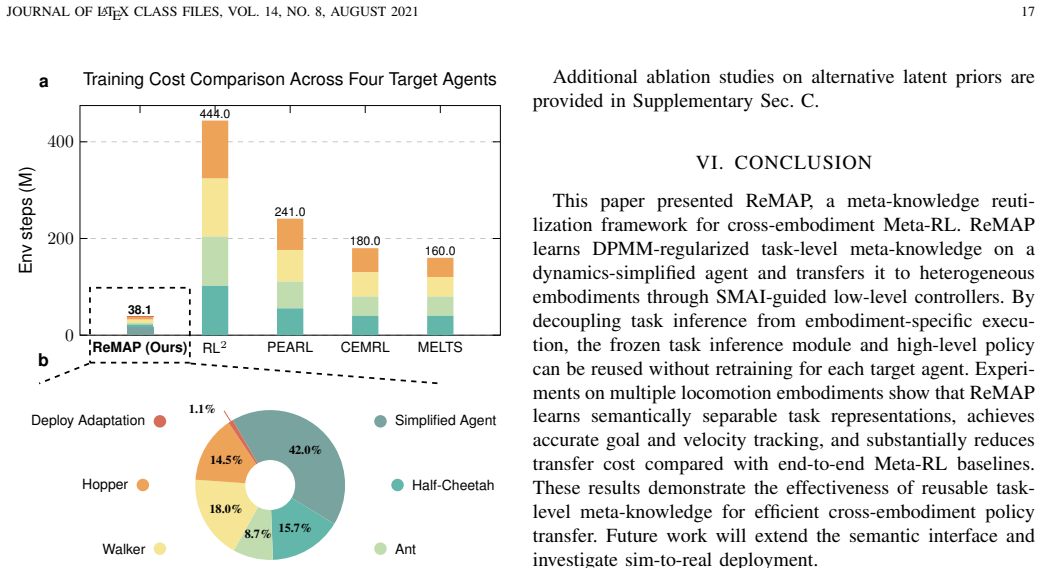
read the original abstract
Meta-reinforcement learning enables fast adaptation by extracting shared structure from related tasks, but existing end-to-end methods often couple task inference with embodiment-specific control. This coupling can obscure non-parametric task semantics, reduce sample efficiency, and limit cross-agent reuse. We propose a meta-knowledge reutilization framework that learns task-level knowledge on a dynamics-simplified agent and transfers it to heterogeneous agents. The framework uses a Bayesian non-parametric prior to organize latent task modes and a high-level policy to generate task-level magnitude guidance. To bridge reusable task knowledge with different embodiments, we introduce a semantic-magnitude interface and a lightweight temporal adaptor, which convert frozen meta-knowledge into temporally aligned subgoals for embodiment-specific low-level controllers. Experiments on multiple locomotion agents show that our framework reduces final-step tracking error by 94.75% -- 99.79% compared with recent state-of-the-art baselines and achieves comparable deployment performance with about 23.8% of their interaction data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a meta-knowledge reutilization framework for meta-reinforcement learning. Task-level knowledge is learned on a dynamics-simplified agent via a Bayesian non-parametric prior over latent task modes and a high-level policy that produces magnitude guidance. This frozen knowledge is transferred to heterogeneous agents through a semantic-magnitude interface and lightweight temporal adaptor that produce temporally aligned subgoals for embodiment-specific low-level controllers. On multiple locomotion agents the framework is reported to reduce final-step tracking error by 94.75%–99.79% relative to recent baselines while matching deployment performance with approximately 23.8% of the interaction data.
Significance. If the empirical claims are substantiated by properly controlled experiments, the separation of non-parametric task semantics from embodiment-specific control could meaningfully advance sample-efficient meta-RL and cross-agent reuse. The Bayesian non-parametric organization of task modes and the explicit interface/adaptor design are conceptually clean contributions that address a recognized coupling problem in end-to-end meta-RL.
major comments (2)
- [Abstract] Abstract: the central empirical claim (94.75%–99.79% error reduction and 23.8% data usage) is presented without any description of experimental controls, number of random seeds, variance or confidence intervals, baseline re-implementations, statistical tests, or data-exclusion criteria. These details are load-bearing for evaluating whether the reported gains support the framework.
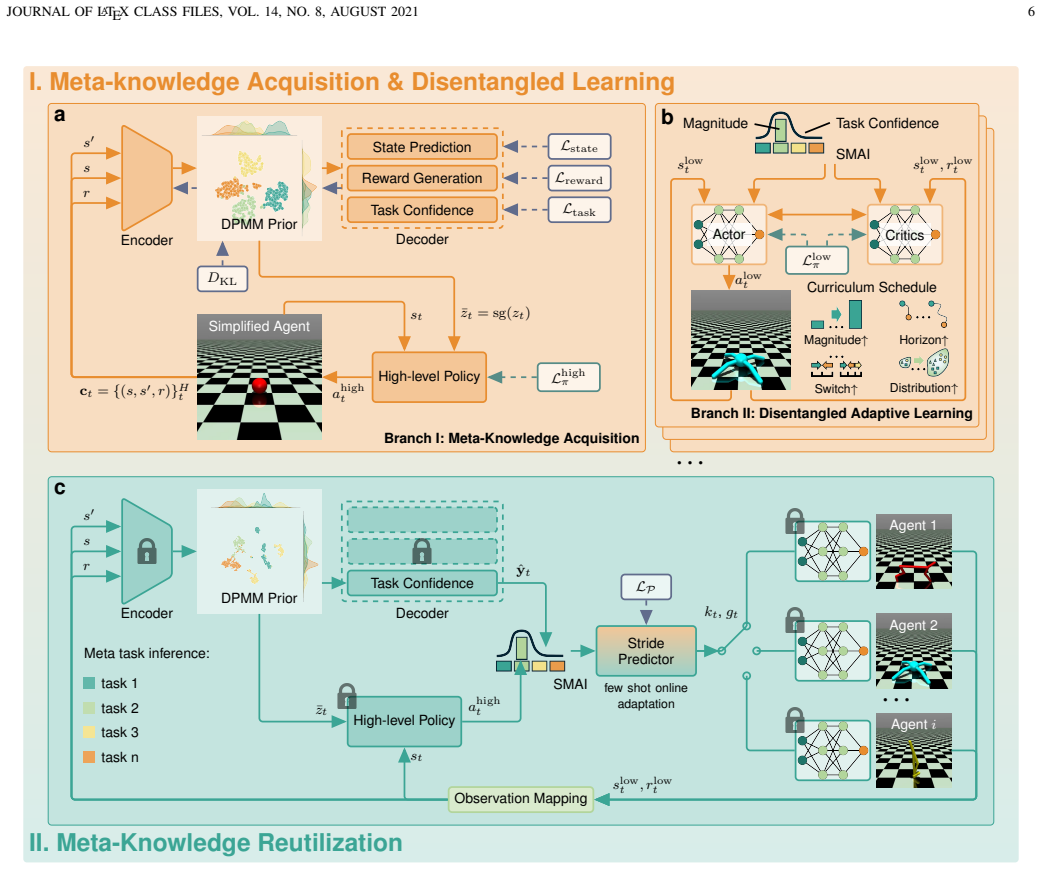
- [Abstract] Abstract: the semantic-magnitude interface and lightweight temporal adaptor are introduced as the mechanisms that convert frozen meta-knowledge into subgoals without substantial information loss, yet no equations, architectural diagrams, or ablation results are supplied to show how temporal alignment is achieved or to quantify information loss across embodiments.
minor comments (1)
- [Abstract] Abstract: the performance range is given as a single interval without mapping individual values to specific baselines or locomotion tasks.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract. We address each point below and will revise the manuscript to improve clarity on experimental reporting and component descriptions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim (94.75%–99.79% error reduction and 23.8% data usage) is presented without any description of experimental controls, number of random seeds, variance or confidence intervals, baseline re-implementations, statistical tests, or data-exclusion criteria. These details are load-bearing for evaluating whether the reported gains support the framework.
Authors: We agree that the abstract's brevity omits key experimental metadata. In the revised version we will append a concise clause noting that results are averaged over 5 random seeds with standard deviations reported, that baselines were re-implemented from original code following published protocols, and that full controls, confidence intervals, and statistical tests appear in Section 4. Data-exclusion criteria follow the standard locomotion benchmark preprocessing described in the same section. revision: yes
-
Referee: [Abstract] Abstract: the semantic-magnitude interface and lightweight temporal adaptor are introduced as the mechanisms that convert frozen meta-knowledge into subgoals without substantial information loss, yet no equations, architectural diagrams, or ablation results are supplied to show how temporal alignment is achieved or to quantify information loss across embodiments.
Authors: Equations defining the semantic-magnitude interface mapping and the temporal adaptor’s alignment loss appear in Sections 3.2–3.3; the system diagram is Figure 2; ablation results that quantify information loss and alignment fidelity across embodiments are in Section 4.4. Because abstract length constraints preclude including equations or figures, we will revise the abstract to explicitly reference these sections so readers can locate the supporting material immediately. revision: partial
Circularity Check
No significant circularity
full rationale
The provided abstract and description contain no equations, derivations, fitted parameters, or self-citations. All claims are presented as empirical experimental outcomes on locomotion agents rather than reductions of predictions to prior fitted quantities or self-referential definitions. The framework description (Bayesian prior, semantic-magnitude interface, temporal adaptor) is introduced as a proposal without any load-bearing step that collapses to its own inputs by construction. This matches the default expectation of a non-circular empirical paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Bayesian non-parametric prior organizes latent task modes independently of agent embodiment
invented entities (2)
-
semantic-magnitude interface
no independent evidence
-
lightweight temporal adaptor
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Rl 2: Fast reinforcement learning via slow reinforcement learning,
Y . Duan, J. Schulman, X. Chen, P. L. Bartlett, I. Sutskever, and P. Abbeel, “Rl 2: Fast reinforcement learning via slow reinforcement learning,”arXiv preprint arXiv:1611.02779, 2016
Pith/arXiv arXiv 2016
-
[2]
Recurrent hypernet- works are surprisingly strong in meta-rl,
J. Beck, R. Vuorio, Z. Xiong, and S. Whiteson, “Recurrent hypernet- works are surprisingly strong in meta-rl,”Advances in Neural Informa- tion Processing Systems, vol. 36, pp. 62 121–62 138, 2023
2023
-
[3]
Model-agnostic meta-learning for fast adaptation of deep networks,
C. Finn, P. Abbeel, and S. Levine, “Model-agnostic meta-learning for fast adaptation of deep networks,” inInternational conference on machine learning. PMLR, 2017, pp. 1126–1135
2017
-
[4]
Meta-reinforcement learn- ing in non-stationary and dynamic environments,
Z. Bing, D. Lerch, K. Huang, and A. Knoll, “Meta-reinforcement learn- ing in non-stationary and dynamic environments,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 3, pp. 3476– 3491, 2022
2022
-
[5]
Efficient off- policy meta-reinforcement learning via probabilistic context variables,
K. Rakelly, A. Zhou, C. Finn, S. Levine, and D. Quillen, “Efficient off- policy meta-reinforcement learning via probabilistic context variables,” inInternational conference on machine learning. PMLR, 2019, pp. 5331–5340
2019
-
[6]
Meta-world: A benchmark and evaluation for multi-task and meta reinforcement learning,
T. Yu, D. Quillen, Z. He, R. Julian, K. Hausman, C. Finn, and S. Levine, “Meta-world: A benchmark and evaluation for multi-task and meta reinforcement learning,” inConference on robot learning. PMLR, 2020, pp. 1094–1100
2020
-
[7]
Context-based meta- reinforcement learning with bayesian nonparametric models,
Z. Bing, Y . Yun, K. Huang, and A. Knoll, “Context-based meta- reinforcement learning with bayesian nonparametric models,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 46, no. 10, pp. 6948–6965, 2024
2024
-
[8]
Memoized online variational inference for dirichlet process mixture models,
M. C. Hughes and E. Sudderth, “Memoized online variational inference for dirichlet process mixture models,”Advances in neural information processing systems, vol. 26, 2013
2013
-
[9]
On first-order meta-learning algorithms,
A. Nichol, J. Achiam, and J. Schulman, “On first-order meta-learning algorithms,”arXiv preprint arXiv:1803.02999, 2018
Pith/arXiv arXiv 2018
-
[10]
Ro- bust maml: Prioritization task buffer with adaptive learning process for model-agnostic meta-learning,
T. Nguyen, T. Luu, T. Pham, S. Rakhimkul, and C. D. Yoo, “Ro- bust maml: Prioritization task buffer with adaptive learning process for model-agnostic meta-learning,” inICASSP 2021-2021 IEEE In- ternational Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2021, pp. 3460–3464
2021
-
[11]
A simple neural attentive meta-learner,
N. Mishra, M. Rohaninejad, X. Chen, and P. Abbeel, “A simple neural attentive meta-learner,” inInternational Conference on Learning Representations, 2018
2018
-
[12]
Efficient cross-episode meta-rl,
G. Shala, A. Biedenkapp, P. Krack, F. Walter, and J. Grabocka, “Efficient cross-episode meta-rl,” inThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[13]
Varibad: a very good method for bayes-adaptive deep rl via meta-learning,
L. Zintgraf, K. Shiarlis, M. Igl, S. Schulze, Y . Gal, K. Hofmann, and S. Whiteson, “Varibad: a very good method for bayes-adaptive deep rl via meta-learning,”Proceedings of ICLR 2020, 2020. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 18
2020
-
[14]
Focal: Efficient fully-offline meta- reinforcement learning via distance metric learning and behavior reg- ularization,
L. Li, R. Yang, and D. Luo, “Focal: Efficient fully-offline meta- reinforcement learning via distance metric learning and behavior reg- ularization,” inInternational Conference on Learning Representations, 2020
2020
-
[15]
Meta-reinforcement learning based on self-supervised task representation learning,
M. Wang, Z. Bing, X. Yao, S. Wang, H. Kai, H. Su, C. Yang, and A. Knoll, “Meta-reinforcement learning based on self-supervised task representation learning,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 37, no. 8, 2023, pp. 10 157–10 165
2023
-
[16]
A survey on deep clustering: from the prior perspective,
Y . Lu, H. Li, Y . Li, Y . Lin, and X. Peng, “A survey on deep clustering: from the prior perspective,”Vicinagearth, vol. 1, no. 1, p. 4, 2024
2024
-
[17]
Variational deep embedding: An unsupervised and generative approach to clustering,
Z. Jiang, Y . Zheng, H. Tan, B. Tang, and H. Zhou, “Variational deep embedding: An unsupervised and generative approach to clustering,” arXiv preprint arXiv:1611.05148, 2016
Pith/arXiv arXiv 2016
-
[18]
Deep unsupervised clus- tering with gaussian mixture variational autoencoders,
N. Dilokthanakul, P. A. Mediano, M. Garnelo, M. C. Lee, H. Salim- beni, K. Arulkumaran, and M. Shanahan, “Deep unsupervised clus- tering with gaussian mixture variational autoencoders,”arXiv preprint arXiv:1611.02648, 2016
Pith/arXiv arXiv 2016
-
[19]
Gaussian mixture models
D. A. Reynoldset al., “Gaussian mixture models.”Encyclopedia of biometrics, vol. 741, no. 659-663, p. 3, 2009
2009
-
[20]
Preserving and combining knowledge in robotic lifelong reinforcement learning,
Y . Meng, Z. Bing, X. Yao, K. Chen, K. Huang, Y . Gao, F. Sun, and A. Knoll, “Preserving and combining knowledge in robotic lifelong reinforcement learning,”Nature Machine Intelligence, vol. 7, no. 2, pp. 256–269, 2025
2025
-
[21]
Stick-breaking variational autoencoders,
E. Nalisnick and P. Smyth, “Stick-breaking variational autoencoders,” inInternational Conference on Learning Representations, 2017
2017
-
[22]
Nonparametric variational auto-encoders for hierarchical representation learning,
P. Goyal, Z. Hu, X. Liang, C. Wang, and E. P. Xing, “Nonparametric variational auto-encoders for hierarchical representation learning,” in Proceedings of the IEEE International Conference on Computer Vision, 2017, pp. 5094–5102
2017
-
[23]
Deepdpm: Deep clustering with an unknown number of clusters,
M. Ronen, S. E. Finder, and O. Freifeld, “Deepdpm: Deep clustering with an unknown number of clusters,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 9861–9870
2022
-
[24]
Variational inference for dirichlet process mixtures,
D. M. Blei and M. I. Jordan, “Variational inference for dirichlet process mixtures,”Bayesian Analysis, vol. 1, no. 1, pp. 121–144, 2006
2006
-
[25]
Hierarchically decoupled imitation for morphological transfer,
D. Hejna, L. Pinto, and P. Abbeel, “Hierarchically decoupled imitation for morphological transfer,” inInternational Conference on Machine Learning. PMLR, 2020, pp. 4159–4171
2020
-
[26]
Metamorph: Learning uni- versal controllers with transformers,
A. Gupta, L. Fan, S. Ganguli, and L. Fei-Fei, “Metamorph: Learning uni- versal controllers with transformers,”arXiv preprint arXiv:2203.11931, 2022
arXiv 2022
-
[27]
Between mdps and semi-mdps: A framework for temporal abstraction in reinforcement learning,
R. S. Sutton, D. Precup, and S. Singh, “Between mdps and semi-mdps: A framework for temporal abstraction in reinforcement learning,”Artificial intelligence, vol. 112, no. 1-2, pp. 181–211, 1999
1999
-
[28]
Auto-encoding variational bayes,
D. P. Kingma and M. Welling, “Auto-encoding variational bayes,”arXiv preprint arXiv:1312.6114, 2013
Pith/arXiv arXiv 2013
-
[29]
Soft actor-critic: Off- policy maximum entropy deep reinforcement learning with a stochastic actor,
T. Haarnoja, A. Zhou, P. Abbeel, and S. Levine, “Soft actor-critic: Off- policy maximum entropy deep reinforcement learning with a stochastic actor,” inInternational conference on machine learning. Pmlr, 2018, pp. 1861–1870
2018
-
[30]
Mujoco: A physics engine for model- based control,
E. Todorov, T. Erez, and Y . Tassa, “Mujoco: A physics engine for model- based control,” in2012 IEEE/RSJ international conference on intelligent robots and systems. IEEE, 2012, pp. 5026–5033. Yuan Meng(Student Member, IEEE) received the B.Sc. degree in mechanical engineering in 2020 from RWTH Aachen University, Aachen, Germany, and the M.Sc. degree in mec...
2012
-
[31]
He joined the University of Bielefeld, Germany, as a Full Professor and served as the Director of the Technical Informatics research group until 2001
He served on the Faculty of the Computer Science Department, TU Berlin, until 1993. He joined the University of Bielefeld, Germany, as a Full Professor and served as the Director of the Technical Informatics research group until 2001. Since 2001, he has been a Professor with the Department of Informatics, Technical University of Munich, Munich, Germany
1993
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.