Reliable Neural-Codec Text-to-Speech by ASR Self-Verification and Distillation: Near-Zero Catastrophic Failures Across Models and Codecs
Pith reviewed 2026-06-26 22:44 UTC · model grok-4.3
The pith
Best-of-N ASR self-verification reduces catastrophic failures in neural-codec TTS to near zero across four systems and three codecs, with distillation recovering most of the gain in single-shot decoding.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
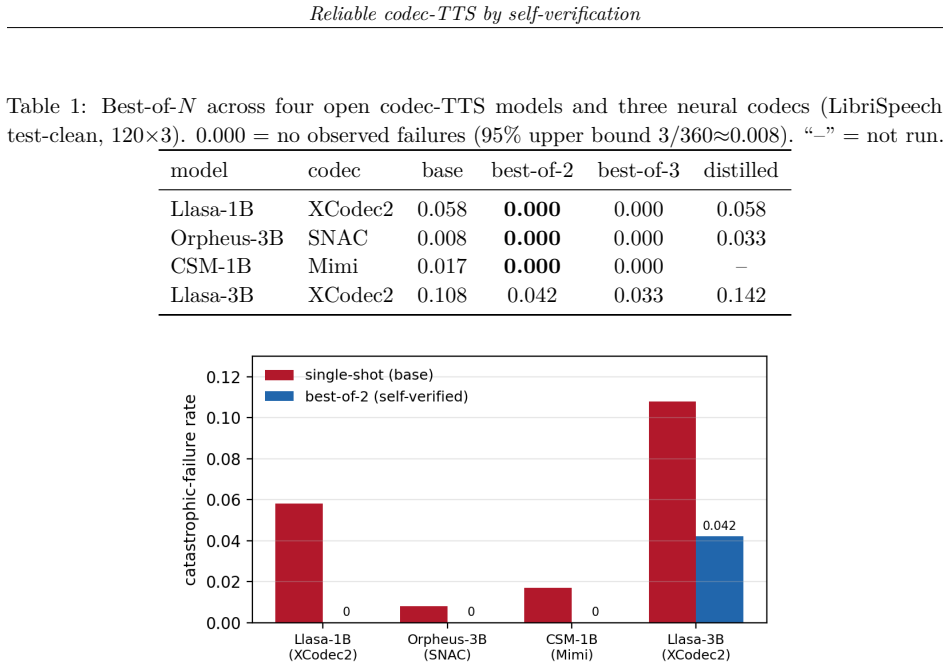
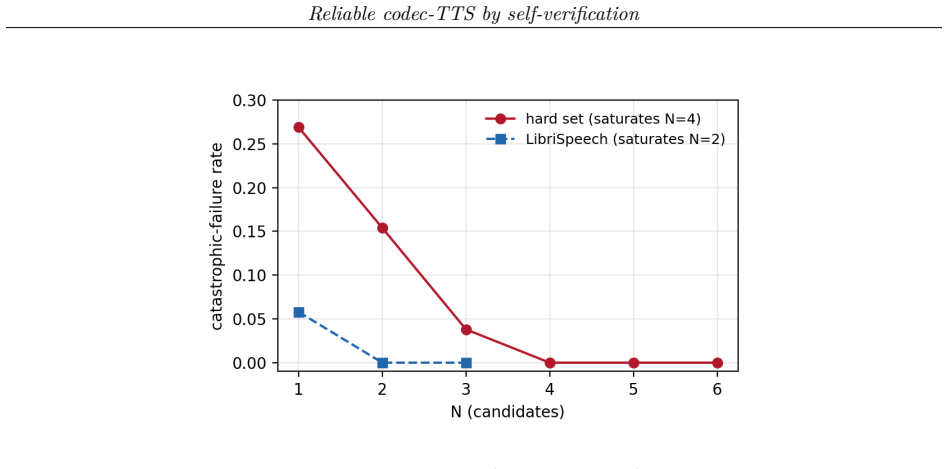
Under a single format-robust metric defined by ASR round-trip error rate, best-of-N ASR self-verification eliminates observed catastrophic failures by N=2 on LibriSpeech and by N=4 on a hard prompt set; the reduction holds across four open codec-TTS systems and three neural codecs. Distilling the self-verified outputs into the base model recovers 52-58 percent of the failure mass on hard inputs at single-shot inference cost, while offline DPO/IPO does not surpass plain supervised distillation and one larger model shows no benefit.
What carries the argument
ASR round-trip catastrophic-failure metric used for best-of-N selection, followed by distillation of the selected outputs into the base model.
If this is right
- The failure reduction replicates across four different open codec-TTS systems and three neural codecs.
- Distillation transfers most of the reliability gain to single-shot decoding, with the improvement concentrated on hard inputs.
- Offline direct preference optimization does not outperform plain supervised distillation on this task.
- A larger model in the tested family shows no improvement from the procedure.
Where Pith is reading between the lines
- The same verification-plus-distillation pattern could be tested on other autoregressive audio or music generation tasks that exhibit stochastic collapse.
- If the hard prompt set captures real deployment edge cases, the method would directly improve production reliability without changing model architecture.
- An online iterative version of the distillation process might close the remaining failure gap if evaluated at larger scale.
Load-bearing premise
The ASR round-trip check identifies exactly the same outputs that a human listener would judge as catastrophic failures.
What would settle it
Human raters listening to the same outputs and counting failures at a rate comparable to the original model rather than near zero would falsify the central claim.
Figures
read the original abstract
Open autoregressive neural-codec text-to-speech (TTS) models sound excellent on typical inputs yet suffer stochastic catastrophic failures: on a meaningful fraction of utterances they emit silence, terminate early, or collapse into repetitive or hallucinated content. We show this failure mode is cheap to remove. Under a single format-robust metric (a catastrophic-failure rate via an ASR round-trip), best-of-N ASR self-verification drives failures to near-zero: no observed failures remain by N=2 on a standard corpus (LibriSpeech) and by N=4 on a hard prompt set. This is not an artifact of one model: the reduction replicates across four open codec-TTS systems and three neural codecs (XCodec2, SNAC, Mimi), reaching the near-zero floor by N=2 on three of the four. We then make the fix free at inference time by distilling the self-verified behaviour into the model, which recovers much of the robustness in single-shot decoding, closing ~52-58% of the failure mass on hard inputs at no test-time cost. The distillation gain concentrates where it is needed (hard inputs); on already-reliable prose there is no headroom and no detectable change. A controlled comparison adds a clean negative: offline direct preference optimization (DPO/IPO) does not beat plain supervised distillation, and an online iterative variant is promising but not statistically separable at our evaluation size. We report honestly the one model that resists (a larger Llasa where scale did not obviously help) and a rare-word capability ceiling that no self-distillation method overcomes
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that autoregressive neural-codec TTS models exhibit stochastic catastrophic failures (silence, early termination, repetition, hallucination) that can be driven to near-zero rates via best-of-N ASR self-verification under an ASR round-trip metric; this holds by N=2 on LibriSpeech and N=4 on a hard prompt set, replicates across four open codec-TTS systems and three neural codecs, and can be largely recovered at inference time by distilling the verified behavior into the base model (closing 52-58% of failure mass on hard inputs). A controlled comparison shows supervised distillation outperforms or matches DPO/IPO variants, with honest reporting of one resistant model and a rare-word ceiling.
Significance. If the ASR round-trip metric is validated against human perception, the work supplies a practical, model-agnostic, and low-cost route to reliable open neural-codec TTS, with the cross-system replication and the clean negative result on preference optimization constituting clear strengths. The distillation result is particularly useful because gains concentrate on hard inputs where they are needed.
major comments (2)
- [Abstract and evaluation section] Abstract and evaluation section: the central claim of 'near-zero catastrophic failures' and 'reliable' TTS rests on the ASR round-trip metric, yet no human listening study, inter-rater agreement statistic, or correlation coefficient between ASR-flagged failures and listener ratings of output quality is reported. This is load-bearing because ASR transcription errors or partial matches could misclassify subtle hallucinations or acceptable repetitions, undermining the perceptual reliability conclusion.
- [evaluation section] Hard prompt set construction (evaluation section): the claim that N=4 suffices on the hard set is central to the generality argument, but the manuscript provides no explicit criteria, sampling procedure, or statistics showing the set is representative of real deployment difficulties rather than an ad-hoc collection; without this, the replication across models cannot be fully assessed.
minor comments (2)
- [distillation section] The distillation procedure is described at a high level; adding the precise objective function or pseudocode would improve reproducibility without altering the central claim.
- [results tables] Table reporting failure rates should include per-model confidence intervals or exact counts to allow readers to judge whether the 'no observed failures' statement at N=2 is statistically robust given the corpus size.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on metric validation and prompt-set construction. We address each point below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract and evaluation section] Abstract and evaluation section: the central claim of 'near-zero catastrophic failures' and 'reliable' TTS rests on the ASR round-trip metric, yet no human listening study, inter-rater agreement statistic, or correlation coefficient between ASR-flagged failures and listener ratings of output quality is reported. This is load-bearing because ASR transcription errors or partial matches could misclassify subtle hallucinations or acceptable repetitions, undermining the perceptual reliability conclusion.
Authors: We agree a human correlation study would strengthen perceptual claims. The ASR round-trip metric is deliberately conservative (exact-match or high-WER threshold on the full transcript), targeting only the catastrophic modes (silence, early stop, repetition, hallucination) that produce unambiguous mismatches; these are not subtle and are unlikely to be misclassified by modern ASR. We will add a small-scale human listening study with correlation statistics in the revised evaluation section. revision: yes
-
Referee: [evaluation section] Hard prompt set construction (evaluation section): the claim that N=4 suffices on the hard set is central to the generality argument, but the manuscript provides no explicit criteria, sampling procedure, or statistics showing the set is representative of real deployment difficulties rather than an ad-hoc collection; without this, the replication across models cannot be fully assessed.
Authors: The hard set was built by selecting prompts that triggered elevated failure rates in preliminary runs on multiple models, emphasizing rare words, long/complex syntax, and out-of-domain content. We will revise the evaluation section to document the explicit selection criteria, sampling procedure, and supporting statistics (baseline failure rates vs. LibriSpeech) to clarify representativeness. revision: yes
Circularity Check
No circularity: empirical results use external ASR metric without self-referential reduction
full rationale
The paper reports experimental measurements of failure rates (silence, repetition, hallucination) via an independent ASR round-trip verifier applied to outputs from multiple codec-TTS systems. Best-of-N sampling and subsequent distillation are evaluated directly against this external metric on LibriSpeech and hard prompts. No derivation, equation, or central claim reduces by construction to a fitted parameter, self-citation chain, or renamed input; the metric is applied uniformly as an evaluation tool rather than being defined in terms of the claimed robustness gain. This is a standard empirical setup with no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
free parameters (1)
- N (number of candidates in best-of-N)
axioms (1)
- domain assumption ASR round-trip provides a reliable and format-robust proxy for detecting catastrophic failures in TTS outputs.
Reference graph
Works this paper leans on
-
[2]
URLhttps://arxiv.org/abs/2507.21138
-
[3]
Kaito Baba, Wataru Nakata, Yuki Saito, and Hiroshi Saruwatari. The T05 System for the VoiceMOS Challenge 2024: Transfer Learning from Deep Image Classifier to Naturalness MOS Prediction of High-Quality Synthetic Speech. arXiv:2409.09305 [cs.SD], 2024. URL https://arxiv.org/abs/2409.09305
arXiv 2024
-
[4]
Preference-Based Learning in Audio Applications: A Systematic Analysis
Aaron Broukhim, Yiran Shen, Prithviraj Ammanabrolu, and Nadir Weibel. Preference-Based Learning in Audio Applications: A Systematic Analysis. arXiv:2511.13936 [cs.SD], 2025. URL https://arxiv.org/abs/2511.13936
arXiv 2025
-
[5]
Orpheus: Towards Human-Sounding Speech (Orpheus-3B TTS)
Canopy Labs. Orpheus: Towards Human-Sounding Speech (Orpheus-3B TTS). Model re- lease, HuggingFacecanopylabs/orpheus-3b-0.1-ft; code https://github.com/canopyai/ Orpheus-TTS, 2025. URLhttps://huggingface.co/canopylabs/orpheus-3b-0.1-ft
2025
-
[6]
CosyVoice 2: Scalable Streaming Speech Synthesis with Large Language Models
Zhihao Du, Yuxuan Wang, Qian Chen, Xian Shi, Xiang Lv, Tianyu Zhao, Zhifu Gao, Yexin Yang, Changfeng Gao, Hui Wang, Fan Yu, Huadai Liu, Zhengyan Sheng, Yue Gu, Chong Deng, Wen Wang, Shiliang Zhang, Zhijie Yan, and Jingren Zhou. CosyVoice 2: Scalable Streaming Speech Synthesis with Large Language Models. arXiv:2412.10117 [cs.SD], 2024. URLhttps://arxiv.org...
Pith/arXiv arXiv 2024
-
[7]
The Differences Between Direct Alignment Algorithms are a Blur
Alexey Gorbatovski, Boris Shaposhnikov, Viacheslav Sinii, Alexey Malakhov, and Daniil Gavrilov. The Differences Between Direct Alignment Algorithms are a Blur. arXiv:2502.01237 [cs.LG], 2025. URLhttps://arxiv.org/abs/2502.01237
Pith/arXiv arXiv 2025
-
[8]
Desta, Roy Fejgin, Rafael Valle, and Jason Li
Shehzeen Hussain, Paarth Neekhara, Xuesong Yang, Edresson Casanova, Subhankar Ghosh, Mikyas T. Desta, Roy Fejgin, Rafael Valle, and Jason Li. Koel-TTS: Enhancing LLM based Speech Generation with Preference Alignment and Classifier Free Guidance. arXiv:2502.05236 [cs.SD], 2025. URLhttps://arxiv.org/abs/2502.05236
arXiv 2025
-
[9]
Align2Speak: Improving TTS for Low Resource Languages via ASR-Guided Online Preference Optimization
Shehzeen Hussain, Paarth Neekhara, Xuesong Yang, Edresson Casanova, Subhankar Ghosh, Roy Fejgin, Ryan Langman, Mikyas Desta, Leili Tavabi, and Jason Li. Align2Speak: Improving TTS for Low Resource Languages via ASR-Guided Online Preference Optimization. arXiv:2509.21718 [cs.AI], 2025. URLhttps://arxiv.org/abs/2509.21718
arXiv 2025
-
[10]
MegaTTS 3: Sparse Alignment Enhanced Latent Diffusion Transformer for Zero-Shot Speech Synthesis
Ziyue Jiang, Yi Ren, Ruiqi Li, Shengpeng Ji, Boyang Zhang, Zhenhui Ye, Chen Zhang, Bai Jionghao, Xiaoda Yang, Jialong Zuo, Yu Zhang, Rui Liu, Xiang Yin, and Zhou Zhao. MegaTTS 3: Sparse Alignment Enhanced Latent Diffusion Transformer for Zero-Shot Speech Synthesis. arXiv:2502.18924 [eess.AS], 2025. URLhttps://arxiv.org/abs/2502.18924
arXiv 2025
-
[11]
A Survey of Direct Preference Optimization
Shunyu Liu, Wenkai Fang, Zetian Hu, Junjie Zhang, Yang Zhou, Kongcheng Zhang, Rongcheng Tu, Ting-En Lin, Fei Huang, Mingli Song, Yongbin Li, and Dacheng Tao. A Survey of Direct Preference Optimization. arXiv:2503.11701 [cs.LG], 2025. URL https://arxiv.org/abs/ 2503.11701
arXiv 2025
-
[12]
TTSDS – Text-to-Speech Distribution Score
Christoph Minixhofer, Ondřej Klejch, and Peter Bell. TTSDS – Text-to-Speech Distribution Score. arXiv:2407.12707 [eess.AS], 2024. URLhttps://arxiv.org/abs/2407.12707
arXiv 2024
-
[13]
CSM: A Conversational Speech Generation Model
Sesame AI. CSM: A Conversational Speech Generation Model. Model release, Hugging- Face sesame/csm-1b; code https://github.com/SesameAILabs/csm, 2025. URL https: //huggingface.co/sesame/csm-1b
2025
-
[14]
Metis: A Foundation Speech Generation Model with Masked Generative Pre-training
Yuancheng Wang, Jiachen Zheng, Junan Zhang, Xueyao Zhang, Huan Liao, and Zhizheng Wu. Metis: A Foundation Speech Generation Model with Masked Generative Pre-training. arXiv:2502.03128 [cs.SD], 2025. URLhttps://arxiv.org/abs/2502.03128
arXiv 2025
-
[15]
Wenyi Xiao, Zechuan Wang, Leilei Gan, Shuai Zhao, Zongrui Li, Ruirui Lei, Wanggui He, Luu Anh Tuan, Long Chen, Hao Jiang, Zhou Zhao, and Fei Wu. A Comprehensive Survey of Di- rect Preference Optimization: Datasets, Theories, Variants, and Applications. arXiv:2410.15595 [cs.AI], 2024. URLhttps://arxiv.org/abs/2410.15595
Pith/arXiv arXiv 2024
-
[16]
Llasa: Scaling Train-Time and Inference-Time Compute for Llama-based Speech Synthesis
Zhen Ye, Xinfa Zhu, Chi-Min Chan, Xinsheng Wang, Xu Tan, Jiahe Lei, Yi Peng, Haohe Liu, Yizhu Jin, Zheqi Dai, Hongzhan Lin, Jianyi Chen, Xingjian Du, Liumeng Xue, Yunlin Chen, Zhifei Li, Lei Xie, Qiuqiang Kong, Yike Guo, and Wei Xue. Llasa: Scaling Train-Time and Inference-Time Compute for Llama-based Speech Synthesis. arXiv:2502.04128 [eess.AS], 2025. UR...
arXiv 2025
-
[18]
URLhttps://arxiv.org/abs/2508.17229. 9
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.