Searching for Synergy in Shared Workspace Human-AI Collaboration
Pith reviewed 2026-06-27 00:24 UTC · model grok-4.3
The pith
Coordination structure determines whether adding collaborators improves team performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
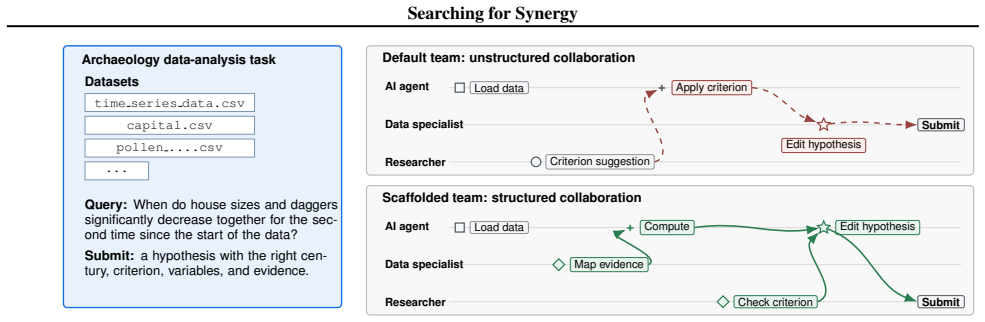
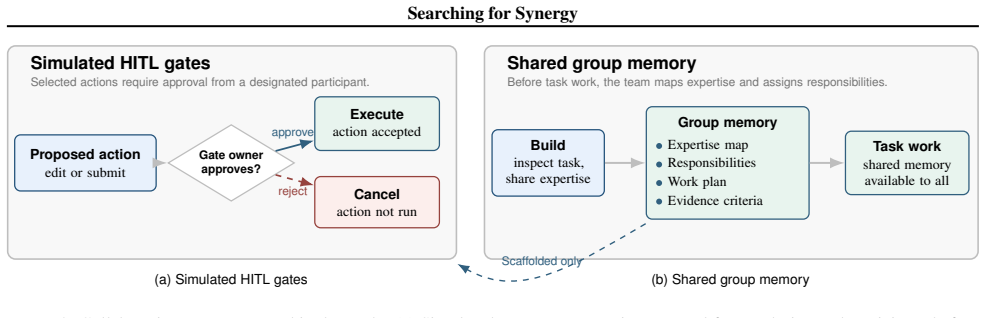
In 1,482 simulated sessions, team performance declined when additional collaborators joined without coordination structure, but improved with scaffolding that included shared group memory and simulated human-in-the-loop approval gates, with the clearest benefits in three-person teams through better responsibility signals and expertise routing.
What carries the argument
Collaboration scaffolding that combines shared group memory with simulated human-in-the-loop gates requiring approval for selected actions.
If this is right
- Three-person teams gain the most from the added scaffolding.
- Clearer responsibility signals appear once the structure is present.
- Expertise routes more effectively to specific team actions.
- Raw capability from extra members does not raise outcomes on its own.
Where Pith is reading between the lines
- Design of human-AI tools should prioritize coordination mechanisms over simply scaling the number of agents.
- The same scaffolding approach could be tested on tasks outside the current discovery benchmark to map its range.
- Real deployments might need adjustable approval gates that respond to observed team size.
Load-bearing premise
The simulated agents and tasks accurately stand in for real human judgment and contextual expertise.
What would settle it
Running identical team sizes and structures with actual human participants and checking whether the same performance drop without scaffolding and recovery with it appear.
Figures



read the original abstract
Automated AI agents are increasingly capable, yet many scientific and professional tasks require human judgment and contextual expertise. We use simulated shared-workspace human-AI teams as a controlled testbed for studying how collaboration structure shapes team behavior. Using the Collaborative Gym environment with tasks from DiscoveryBench, we vary team compositions and collaboration structures across 1,482 sessions. We find that adding additional collaborators can lower performance when coordination structure is absent. We then evaluate collaboration scaffolding that combines shared group memory with simulated human-in-the-loop (HITL) gates, where selected actions require approval from a designated simulated participant. This scaffolding improves performance, most clearly in three-person teams, with clearer responsibility signals and stronger routing of expertise to team actions. Overall, our results suggest that coordination structure is central to whether available capability improves team outcomes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports experiments using the Collaborative Gym environment and DiscoveryBench tasks across 1,482 simulated sessions of shared-workspace human-AI teams. It varies team compositions and collaboration structures, finding that adding collaborators without coordination can lower performance, while scaffolding via shared group memory combined with simulated human-in-the-loop (HITL) approval gates improves performance (most clearly in three-person teams) through clearer responsibility signals and expertise routing. The central claim is that coordination structure determines whether available capability improves team outcomes.
Significance. If the simulation results hold and generalize, the work would provide controlled evidence that coordination mechanisms such as shared memory and oversight gates are necessary to avoid performance degradation in multi-agent settings and to route expertise effectively, with direct implications for the design of collaborative AI systems in scientific and professional domains.
major comments (2)
- [Abstract] Abstract: the reported directional findings from 1,482 sessions supply no error bars, statistical tests, exclusion criteria, or baseline comparisons, making it impossible to assess whether the observed effects support the central claim about coordination structure.
- [Abstract] Abstract (and implied methods): the claim that results from simulated agents and tasks serve as a valid testbed for human-AI collaboration rests on the unvalidated assumption that simulated agents capture key dynamics of human judgment, contextual expertise, and response to responsibility signals; without calibration against real human participants this extrapolation is load-bearing for the headline conclusion.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our simulation study of coordination in shared-workspace human-AI teams. We address each major comment below and outline planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the reported directional findings from 1,482 sessions supply no error bars, statistical tests, exclusion criteria, or baseline comparisons, making it impossible to assess whether the observed effects support the central claim about coordination structure.
Authors: We agree that the abstract would be strengthened by including statistical details. The full manuscript reports results across 1,482 sessions with error bars, statistical tests, and baseline comparisons in the results section. We will revise the abstract to reference these elements (e.g., noting significant performance gains with scaffolding and p-values from the analyses) while keeping it concise. revision: yes
-
Referee: [Abstract] Abstract (and implied methods): the claim that results from simulated agents and tasks serve as a valid testbed for human-AI collaboration rests on the unvalidated assumption that simulated agents capture key dynamics of human judgment, contextual expertise, and response to responsibility signals; without calibration against real human participants this extrapolation is load-bearing for the headline conclusion.
Authors: The manuscript frames the work explicitly as a controlled simulation testbed using Collaborative Gym and DiscoveryBench to isolate coordination effects, not as a calibrated model of human behavior. The central claim concerns how coordination structure affects outcomes within this simulated setting. We will revise the abstract and add a limitations section to more explicitly state the scope, the assumptions about simulated agents, and the value of future human-subject validation. revision: partial
Circularity Check
No circularity: experimental results from simulations with no derivation chain
full rationale
The paper reports empirical outcomes from 1,482 simulated sessions varying team compositions, coordination structures, and scaffolding in Collaborative Gym on DiscoveryBench tasks. No mathematical derivation, equations, fitted parameters renamed as predictions, or self-citation load-bearing premises are present in the provided text. The central claim follows directly from the simulation results without reducing to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Simulated agents and tasks in Collaborative Gym with DiscoveryBench accurately model real human-AI collaboration dynamics
Reference graph
Works this paper leans on
-
[1]
, title =
Vaccaro, Michelle and Almaatouq, Abdullah and Malone, Thomas W. , title =. Nature Human Behaviour , year =
-
[2]
Does the Whole Exceed its Parts? The Effect of
Gagan Bansal and others , Xauthor =. Does the Whole Exceed its Parts? The Effect of. Proceedings of the Conference on Human Factors in Computing Systems (CHI) , Xbooktitle =. 2021 , Xurl =
2021
-
[3]
2023 , Xmonth = jul, Xdoi =
Agarwal, Nikhil and Moehring, Alex and Rajpurkar, Pranav and Salz, Tobias , title =. 2023 , Xmonth = jul, Xdoi =
2023
-
[4]
Nature Medicine , year =
Yu, Feiyang and Moehring, Alex and Banerjee, Oishi and Salz, Tobias and Agarwal, Nikhil and Rajpurkar, Pranav , title =. Nature Medicine , year =
-
[5]
, title =
Steiner, Ivan D. , title =
-
[6]
Malone and Kevin Crowston , title =
Thomas W. Malone and Kevin Crowston , title =. 1994 , Xurl =
1994
-
[7]
Research in Organizational Behavior , year =
Heath, Chip and Staudenmayer, Nancy , title =. Research in Organizational Behavior , year =
-
[8]
Journal of Personality and Social Psychology , year =
Stasser, Garold and Titus, William , title =. Journal of Personality and Social Psychology , year =
-
[9]
Carl Gutwin and Saul Greenberg , title =. Comput. Support. Cooperative Work. , volume =. 2002 , Xurl =
2002
-
[10]
CoRR , volume =
Yijia Shao and Vinay Samuel and Yucheng Jiang and John Yang and Diyi Yang , title =. CoRR , volume =. 2024 , Xurl =
2024
-
[11]
Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP) , Xbooktitle =
Haochen Sun and others , Xauthor =. Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP) , Xbooktitle =. 2025 , Xurl =
2025
-
[12]
Proactive Agent Research Environment: Simulating Active Users to Evaluate Proactive Assistants , journal =
Deepak Nathani and others , Xauthor =. Proactive Agent Research Environment: Simulating Active Users to Evaluate Proactive Assistants , journal =. 2026 , Xurl =
2026
-
[13]
Robotouille: An Asynchronous Planning Benchmark for
Gonzalo Gonzalez. Robotouille: An Asynchronous Planning Benchmark for. Proceedings of the International Conference on Learning Representations (ICLR) , Xbooktitle =. 2025 , Xurl =
2025
-
[14]
Cohn and Janet B
Fangru Lin and Emanuele La Malfa and Valentin Hofmann and Elle Michelle Yang and Anthony G. Cohn and Janet B. Pierrehumbert , Xeditor =. Graph-enhanced Large Language Models in Asynchronous Plan Reasoning , booktitle =. 2024 , Xurl =
2024
-
[15]
CoRR , volume =
Shiqi Zhang and others , Xauthor =. CoRR , volume =. 2025 , Xurl =
2025
-
[16]
Orchestrating Human-
Charlie Masters and others , Xauthor =. Orchestrating Human-. CoRR , volume =. 2025 , Xurl =
2025
-
[17]
Proceedings of the International Conference on Learning Representations (ICLR) , Xbooktitle =
Bodhisattwa Prasad Majumder and others , Xauthor =. Proceedings of the International Conference on Learning Representations (ICLR) , Xbooktitle =. 2025 , Xurl =
2025
-
[18]
CoRR , volume =
Philippe Laban and Hiroaki Hayashi and Yingbo Zhou and Jennifer Neville , title =. CoRR , volume =. 2025 , Xurl =
2025
-
[19]
Proceedings of the International Conference on Learning Representations (ICLR) , Xbooktitle =
Shunyu Yao and others , Xauthor =. Proceedings of the International Conference on Learning Representations (ICLR) , Xbooktitle =. 2023 , Xurl =
2023
-
[20]
Proceedings of the International Conference on Machine Learning (ICML) , Xbooktitle =
Shirley Wu and others , Xauthor =. Proceedings of the International Conference on Machine Learning (ICML) , Xbooktitle =. 2025 , Xurl =
2025
-
[21]
CoRR , volume =
Yifei Zhou and others , Xauthor =. CoRR , volume =. 2025 , Xurl =
2025
-
[22]
O'Brien and Carrie Jun Cai and Meredith Ringel Morris and Percy Liang and Michael S
Joon Sung Park and Joseph C. O'Brien and Carrie Jun Cai and Meredith Ringel Morris and Percy Liang and Michael S. Bernstein , Xeditor =. Generative Agents: Interactive Simulacra of Human Behavior , booktitle =. 2023 , Xurl =
2023
-
[23]
Proceedings of the International Conference on Learning Representations (ICLR) , Xbooktitle =
Xuhui Zhou and others , Xauthor =. Proceedings of the International Conference on Learning Representations (ICLR) , Xbooktitle =. 2024 , Xurl =
2024
-
[24]
, title =
Wegner, Daniel M. , title =. Theories of Group Behavior , Xeditor =. 1987 , Xdoi =
1987
-
[25]
Journal of Applied Psychology , volume =
Lewis, Kyle , title =. Journal of Applied Psychology , volume =. 2003 , Xdoi =
2003
-
[26]
Journal of Management Studies , volume =
Argote, Linda and Ren, Yuqing , title =. Journal of Management Studies , volume =. 2012 , Xdoi =
2012
-
[27]
Kyle Lewis and Benjamin Herndon , title =. Organ. Sci. , volume =. 2011 , Xurl =
2011
-
[28]
, title =
Moreland, Richard L. , title =. Shared Cognition in Organizations: The Management of Knowledge , Xeditor =. 1999 , Xdoi =
1999
-
[29]
and Heffner, Tonia S
Mathieu, John E. and Heffner, Tonia S. and Goodwin, Gerald F. and Salas, Eduardo and Cannon-Bowers, Janis A. , title =. Journal of Applied Psychology , volume =. 2000 , Xdoi =
2000
-
[30]
Andrews, R. W. and Lilly, J. M. and Srivastava, Divya K. and Feigh, Karen M. , title =. Theoretical Issues in Ergonomics Science , volume =. 2023 , Xdoi =
2023
-
[31]
Educational Psychologist , volume =
Fischer, Frank and Kollar, Ingo and Stegmann, Karsten and Wecker, Christof , title =. Educational Psychologist , volume =. 2013 , Xdoi =
2013
-
[32]
, title =
Kollar, Ingo and Fischer, Frank and Hesse, Friedrich W. , title =. Educational Psychology Review , volume =. 2006 , Xdoi =
2006
-
[33]
Principles of Mixed-Initiative User Interfaces , booktitle =
Eric Horvitz , Xeditor =. Principles of Mixed-Initiative User Interfaces , booktitle =. 1999 , Xurl =
1999
-
[34]
Sheridan and Christopher D
Raja Parasuraman and Thomas B. Sheridan and Christopher D. Wickens , title =. 2000 , Xurl =
2000
-
[35]
Guidelines for Human-
Saleema Amershi and others , Xauthor =. Guidelines for Human-. Proceedings of the Conference on Human Factors in Computing Systems (CHI) , Xbooktitle =. 2019 , Xurl =
2019
-
[36]
Measuring and Mitigating the Distributional Gap Between Real and Simulated User Behaviors , journal =
Shuhaib Mehri and others , Xauthor =. Measuring and Mitigating the Distributional Gap Between Real and Simulated User Behaviors , journal =. 2026 , Xurl =
2026
-
[37]
CoRR , volume =
Harshita Chopra and Kshitish Ghate and Aylin Caliskan and Tadayoshi Kohno and Chirag Shah and Natasha Jaques , title =. CoRR , volume =. 2026 , Xurl =
2026
-
[38]
CoRR , volume =
Jiaqi Liu and others , Xauthor =. CoRR , volume =. 2026 , Xurl =
2026
-
[39]
CoRR , volume =
Mohamed Elfeki and others , Xauthor =. CoRR , volume =. 2026 , Xurl =
2026
-
[40]
CoRR , volume =
Nishant Balepur and others , Xauthor =. CoRR , volume =. 2026 , Xurl =
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.